# [論文筆記] Fully Convolutional Networks for Semantic Segmentation
###### tags: `FCN` `Segmentation`
在本篇論文中,回顧了用於語意分割的全卷積網路(FCN),和分類、檢測任務相比而言,「分割」是一項更有挑戰性的任務。
- 影像分類(Image Classification): 目標是能辨別出影像中的物體,在下圖的左上方可以看到,透過哪種動物的機率,進而判斷該張影像為該類動物(深度學習中的CNN為經典例子)
- 物件偵測(Object Detection/Localization): 當影像中有許多不同物體,我們需要使用bounding boxes的方框標示出每種物體所屬的類別,在下圖左下角可辨識出不同的三隻羊和落單的一隻狗,這同時意味著我們需要清楚知道每個物件的類別、位置、大小(Faster R-CNN, SSD, YOLO)
- 語意切割(Semantic Segmentation): 將影像中的每一個像素分類,意味著每個像素都有一個標籤(label),同一類物件會被劃分在一起,如下圖中右上角。
- 實例切割(Instance Segmentation): 由語意切割的例子可以看見,三隻不同的羊被劃分為同一類別,不能很好地區分他們個別的形體。將Semantic segmentation和Object detection/localization融合得出Instance segmentation(Mask R-CNN)

## 從影像辨識到語意切割
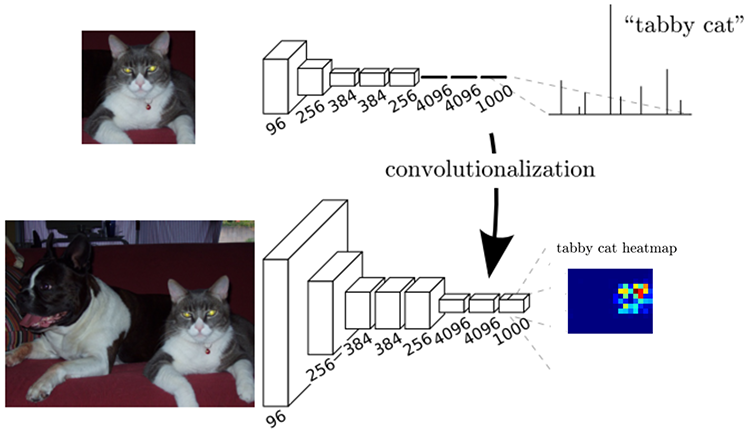
傳統上來說,在分類任務中,輸入影像的尺寸會被縮小,並通過卷積層和全連接層,得到一個能預估輸入影像類別的輸出,如下圖。
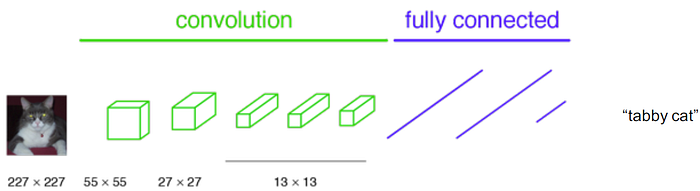
接著想像一下,將全連接層換成1x1卷積層:

因為max pooling的原因,輸出影像的尺寸一定比輸入影像小
所以如果上採樣這些輸出,我們可以計算出逐一像素的標籤(label map):


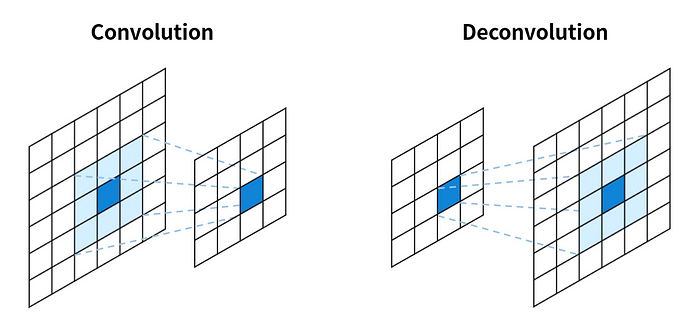
## 透過反卷積進行上採樣(upsampling)
卷積是可使影像輸出尺寸縮小的過程,因此,「**反卷積**」的名稱來自於我們需要藉由上採樣(upsampling)放大影像輸出尺寸的時候。(**切記,反卷積並不是卷積的逆過程**)
同時反卷積也被稱作**上卷積(up convolution)**或**轉置卷積(transposed convolution)**

(藍色:輸入/綠色:輸出)
利用填充(padding)來放大需做反卷積的影像
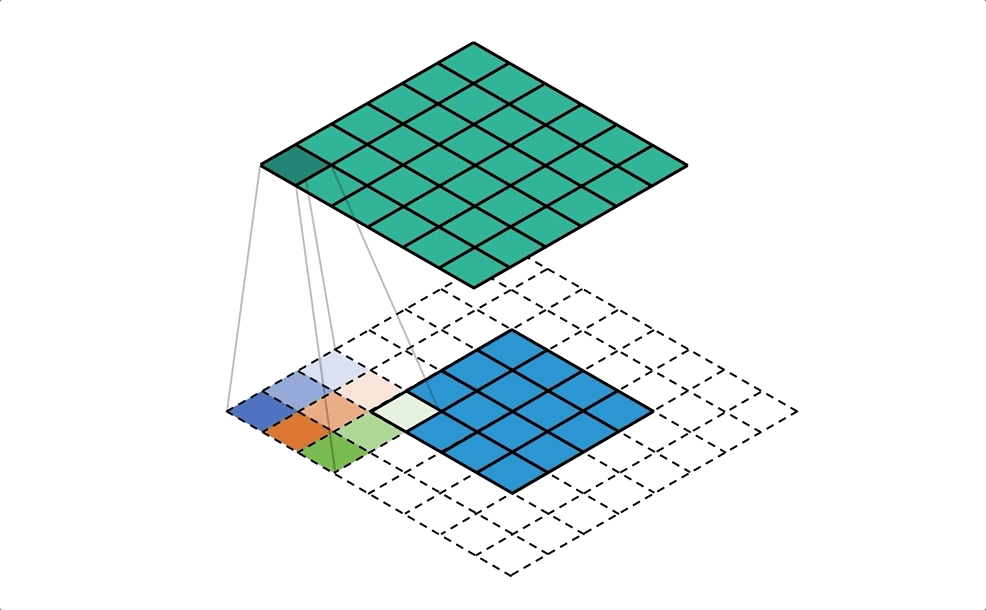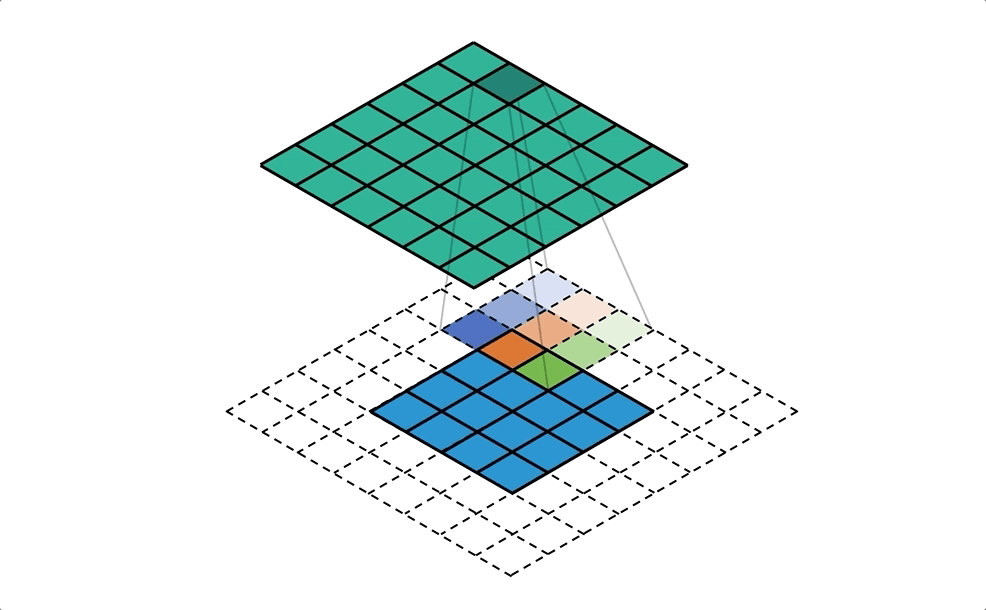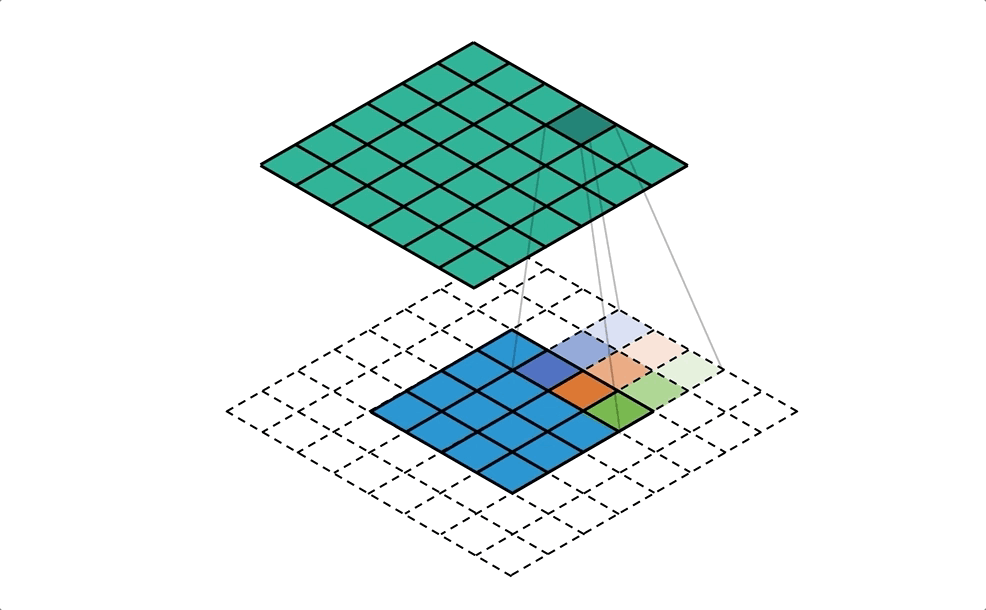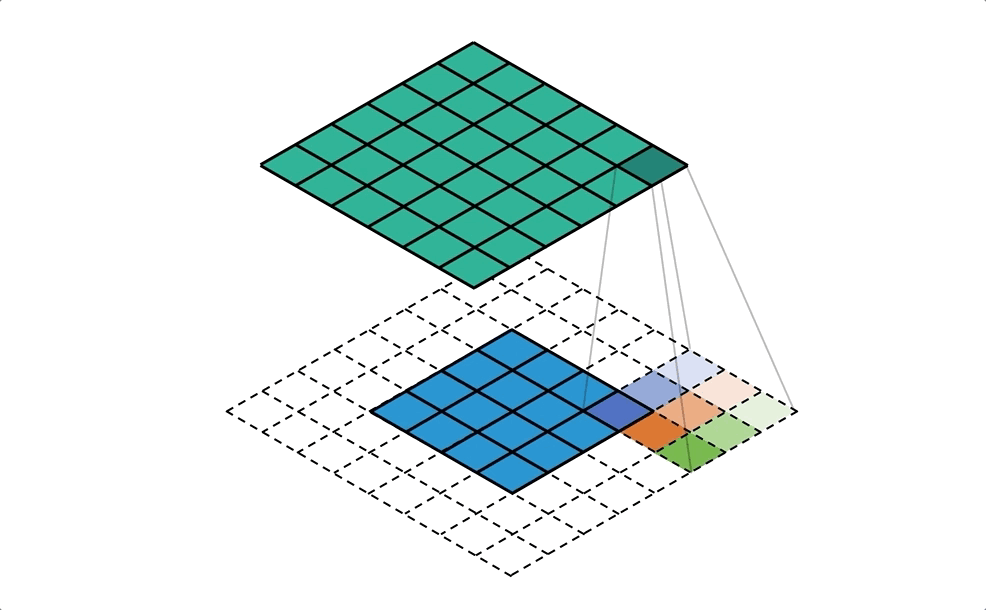
## 結合所有輸出
經過下圖所示的conv7層,影像輸出尺寸較小,接著進行32倍的上採樣,進而和最初的輸入影像有相同的尺寸大小,這也導致輸出標籤圖(label map)顯得粗糙,被稱為**FCN-32s**。
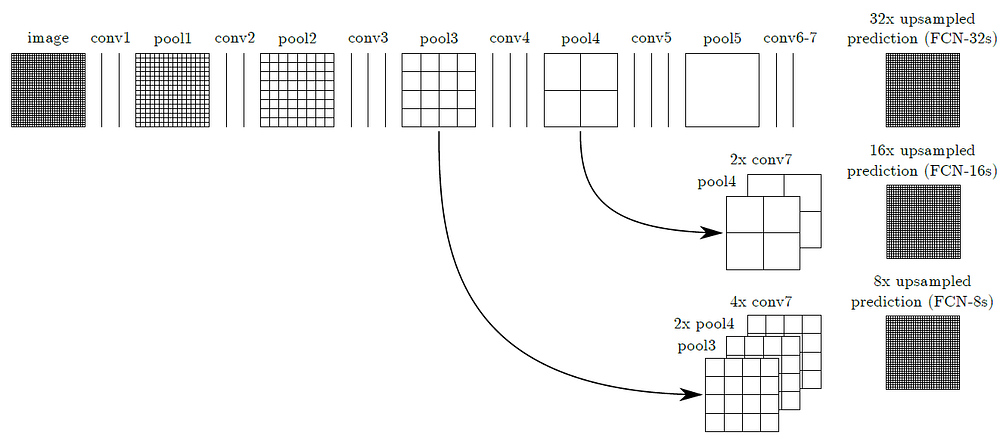
會有此現象的主因:當神經網路深入時可以得到較深的特徵,卻也會遺漏空間、位置的資訊。
利用淺層輸出具有較多空間和位置資訊的特性,結合起來,可以提升performance。
結合所有輸出(透過**逐項元素加法(element-wise addition)**):
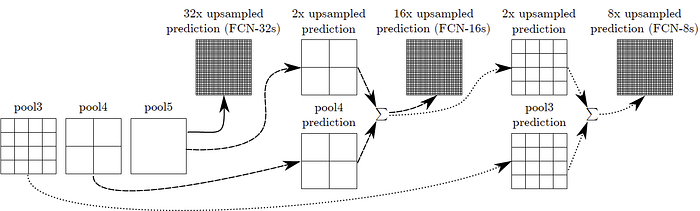
**FCN-16s**:pool5的輸出進行2倍上採樣,在和pool4結合執行16倍上採樣。
**FCN-8s**:將16s執行16倍上採樣前的圖再執行2倍上採樣,和pool3結合執行8倍上採樣。

由上圖看出,因為空間、位置資訊在神經網路傳遞時遺漏,導致FCN-32s的結果較粗糙,而FCN-8s較好。
實際上,這種「結合」的方式和AlexNet、VGGNet中使用的增強(boosting)/合成(ensemble)技術相似,透過多種模型將結果相加,來達到預測準確率的提升。
## 實驗結果
Semantic Segmentation的label map如下圖:
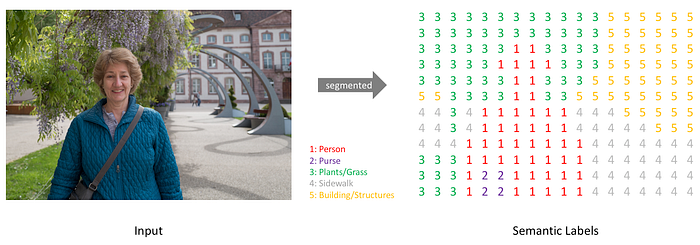
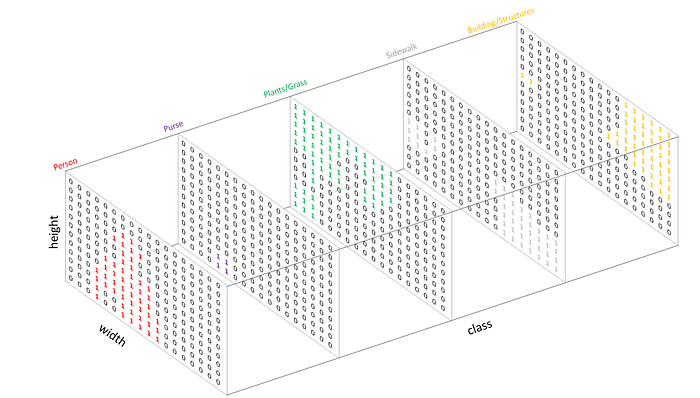
可以將每個channel分別拆解(像本論文做的PASCAL有20+1個channels)
FCN利用softmax函數得出各個像素所屬類別的機率,並標示該channel的位置資訊,和其他channel(不同類)的圖疊加在一起。

- FCN-8s在Pascal VOC 2011表現最好
- FCN-16s在NYUDv2中表現最好。
- FCN-16s在SIFT Flow中表現最好。
## 參考資料
https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1
https://ivan-eng-murmur.medium.com/%E7%89%A9%E4%BB%B6%E5%81%B5%E6%B8%AC-s7-fcn-for-semantic-segmentation%E7%B0%A1%E4%BB%8B-29814b07f96a
http://www.piginzoo.com/machine-learning/2020/04/23/fcn-unet