# [論文筆記] UNet: Convolutional Network for Biomedical Image Segmantation
###### tags: `UNet` `Segmentation` `Biomedical Image` `Tensorflow`
對於醫學影像切割十分有助益的model: **UNet**。
最早arXiv的發表時間是在**2015**年,也被MICCAI收錄。
## 摘要
深度學習的進步帶動許多領域的蓬勃發展,而本篇則專注於醫學影像的應用。
一個完善的深度網路需要大量已經label的training set使網路學習特徵,
然而這同時是醫學影像的缺點:
1. 精確標註醫學影像成本過高
2. 醫學影像取得不易,數量稀少
在本次介紹的論文,提出一個**全新的網路架構和訓練策略**。
- Data Augmentation
- 使用一個contraction path來抓取訊息以及一個對稱的expanding path來達到精確的定位
## 引言
在2013-2014年間,深度卷積網路(Deep Convolutional Network)的表現超越了當時許多用於視覺辨識任務的技術,雖然深度卷積網路已行之有年,但他的成功受限於"**數量龐大的訓練集**"、"**網路本身規模的大小**"。
Krizhevsky等人運用ImageNet數據集上的100萬張訓練圖像,實作了一個8層的網路和數百萬個參數的網路,也正式帶起運用更大更深網路的風潮。
卷積網路通常用於**分類任務**,然而醫學影像應具備可定位的消息(每個pixel都能被分配到一個類別的label);也因此,Ciresan等人提出以滑動窗格對每個pixel的類別進行分割任務,卻有**兩個致命的缺點**:
1. 因為網路需要針對每個patch分別運行且圖塊都有所重疊,運算量龐大以至於速度緩慢。
2. 在定位精準度和上下文信息的使用上形成tradeoff : 若使用小的圖塊只能看到相當少的上下文信息,但若使用大的圖塊則需要更多最大池化層,間接導致降低定位精準度。
本文基於更為巧妙的架構:"**全卷積網路**"(FCN)去作修改,不僅以少量訓練圖片即可運作,且達到更高的分割準確率。
## 架構

可以看到整體架構為對稱呈現U型,左側為Downsampling,負責壓縮圖片尺寸及特徵萃取;右側為upsampling,負責增加分辨率並插值到原圖尺寸,以利提高定位精準度。
>上圖展示了網絡結構,它由contracting path 和expansive path組成。
contracting path是典型的捲積網絡架構:
架構中含有著一種重複結構,每次重複中都有2個3x3 卷積層(無padding)、非線性ReLU層和一個2x2 max pooling層(stride為2)。(圖中的藍箭頭、紅箭頭,沒畫ReLu)
每一次下採樣後我們都把特徵通道的數量加倍。
expansive path也使用了一種相同的排列模式:
每一步都首先使用反捲積(up-convolution),每次使用反捲積都將特徵通道數量減半,特徵圖大小加倍。(圖中綠箭頭)
反捲積過後,將反捲積的結果與contracting path中對應步驟的特徵圖拼接起來。(白/藍塊)
contracting path中的特徵圖尺寸稍大,將其修剪過後進行拼接。(左邊深藍虛線)
對拼接後的map再進行2次3x3的捲積。(右側藍箭頭)
最後一層的捲積核大小為1x1,將64通道的特徵圖轉化為特定類別數量(分類數量,二分類為2)的結果。(圖中青色箭頭)
網絡總共23層。
FCN與CNN不同的地方在於:**CNN會在網路的最後加入全連結層(Fully-Connected Layer),經softmax函數後可以得到類別的機率訊息(一維),僅能標示整張圖片的類別,而不能標示每個pixel的類別;FCN則將全連接層換成捲積層,如此以來可得到二維的特徵圖**。
修改的部份:
1. 在Upsampling的部分仍保有大量的特徵通道,可使上下文訊息傳到更高的分辨率層。
2. 分割圖只包含pixel,在輸入圖像中可獲得全部的上下文訊息。
3. 為了預測邊緣的pixel,使用鏡像去補足缺失的環境像素。

## 訓練
1. 使用Data Augmentation技術擴充訓練資料,可以讓model學習到"**形變不變性(deformation invariance)**",因為組織形變是非常常見的狀況,其重要性可由Dosovitskiy等人的研究窺見一斑。因為平移與旋轉不變性的需求,作者使用一個粗糙的3*3網格的隨機位移向量來產生平滑形變,來增加強健性(robustness)。
3. 使用帶有權重的loss,其中相互碰觸之細胞間的分離背景標籤在損失函數中獲得較大的權重,為使同類別但有相互碰觸到的目標分割出來。

- 交叉熵函數

為了凸顯某些pixel更為重要,在公式中引入了$w(x)$,為每張ground truth預先計算權重圖,來補償訓練圖片中每類pixel的不同頻率,目的是讓網路能更注重學習相互碰觸之細胞間的小分割邊界。
使用形態學運算分割邊界,公式如下:

$w_c$:用於平衡類別出現頻率的權重
$d_1$:與最近細胞之邊界的距離
$d_2$:與第二近細胞之邊界的距離
當$d_1$、$d_2$距離小,$exp$則會大(意即邊緣的像素得到較大的權重)
根據經驗法則,設定 $\sigma$: 5 pixels 、$w_0$: 10
- 評估指標
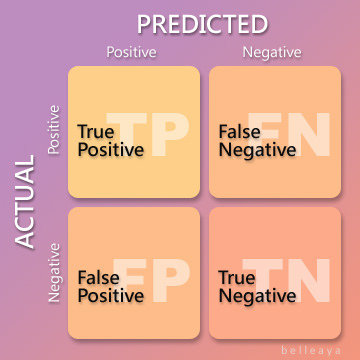
- accuracy: $\frac{TP+TN}{TP+TN+FP+FN}$
- IOU(intersection over union): $\frac{TP}{TP+FP+FN}$
亦稱為Jaccard index,為兩集合"交集大小"、"聯集大小"之間的比例: $J(A,B)=\frac{|A \cap B|}{|A \cup B|}$
## 實作




