---
tags: concurrency
---
# [並行程式設計](https://hackmd.io/@sysprog/concurrency): POSIX Thread
## Process vs. Thread vs. Coroutines
* With threads, the operating system switches running tasks **preemptively** according to its scheduling algorithm.
* With coroutines, the programmer chooses, meaning tasks are cooperatively multitasked by pausing and resuming functions at set points.
* coroutine switches are cooperative, meaning the programmer controls when a switch will happen.
* The kernel is not involved in coroutine switches.
一圖勝千語:

將函式呼叫從原本的面貌: [ [source](http://www.csl.mtu.edu/cs4411.ck/www/NOTES/non-local-goto/coroutine.html) ]
轉換成以下:
C 程式實作 coroutines 的手法相當多,像是:
* [setjmp / longjmp](http://descent-incoming.blogspot.tw/2014/02/coroutine.html)
### Thread & Process
取自[Programming Parallel Machines Spring 2019](https://engineering.purdue.edu/~smidkiff/ece563/)第7周教材


A thread can possess an independent flow of control and be schedulable because it maintains its own:
- Stack pointer
- Registers
- Scheduling properties (such as policy or priority)
- Set of pending and blocked signals
- Thread specific data.
### PThread (POSIX threads)

#### Example
```c
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void printMsg(char *msg)
{
int *status = malloc(sizeof(int));
*status = 1;
printf("%s\n", msg);
pthread_exit(status);
}
int main(int argc, char **argv)
{
pthread_t thrdID;
int *status = malloc(sizeof(int));
printf("creating a new thread\n");
pthread_create(&thrdID, NULL, (void *) printMsg, argv[1]);
printf("created thread %lu\n", thrdID);
pthread_join(thrdID, (void**) &status);
printf("Thread %lu exited with status %d\n", thrdID, *status);
return 0;
}
```
執行結果
```shell
$ ./a.out "Hello world!"
creating a new thread
created thread 219465472
Hello world!
Thread 219465472 exited with status 1
```
延伸閱讀: [POSIX Threads Programming](https://hpc-tutorials.llnl.gov/posix/)
### Synchronizing Threads
3 basic synchronization primitives
- mutex locks
- condition variables
- semaphores
取自 Ching-Kuang Shene (冼鏡光) 教授的教材:[Part IV Other Systems: IIIPthreads: A Brief Review](http://pages.mtu.edu/~shene/FORUM/Taiwan-Forum/ComputerScience/004-Concurrency/WWW/SLIDES/15-Pthreads.pdf)
:::info
「[冼](https://zh.wikipedia.org/wiki/%E5%86%BC%E5%A7%93)」音同「顯」
:::
### mutex locks
```cpp
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int pthread_mutex_init(pthread_mutex_t *mutex, pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
```

- Only the ==owner== can unlock a mutex. Since mutexes cannot be copied, use pointers.
- If `pthread_mutex_trylock()` returns `EBUSY`, the lock is already locked. Otherwise, the calling thread becomes the owner of this lock.
- With `pthread_mutexattr_settype()`, the type of a mutex can be set to allow recursive locking or report deadlock if the owner locks again
```cpp
pthread_mutex_t bufLock;
void producer(char* buf1) {
char* buf = (char*) buf1;
for(;;) {
while(count == MAX_SIZE);
pthread_mutex_lock(&bufLock);
buf[count] = (char) ((int)('a')+count);
count++;
printf("%d ", count);
pthread_mutex_unlock(&bufLock);
}
}
void consumer(void* buf1) {
char* buf = (char*) buf1;
for(;;) {
while(count == 0);
pthread_mutex_lock(&bufLock);
count--;
printf("%d ", count);
pthread_mutex_unlock(&bufLock);
}
}
```
### condition variables
```cpp
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond); // all threads waiting on a condition need to be woken up
```
- Condition variables allow a thread to block until a specific condition becomes true
- blocked thread goes to wait queue for condition
- When the condition becomes true, some other thread signals the blocked thread(s)

- Conditions in Pthreads are usually used with a mutex to enforce mutual exclusion.
- the `wait` call should occur under the protection of a mutex
```cpp
pthread_mutex_t *lock;
pthread_cond_t *notFull, *notEmpty;
void consumer(char* buf) {
for(;;) {
pthread_mutex_lock(lock);
while(count == 0)
pthread_cond_wait(notEmpty, lock);
useChar(buf[count-1]);
count--;
pthread_cond_signal(notFull);
pthread_mutex_unlock(lock);
}
}
```
### semaphores
```cpp
sem_t semaphore;
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
```
- Can do increments and decrements of semaphore value
- Semaphore can be initialized to any value
- Thread blocks if semaphore value is less than or equal to zero when a decrement is attempted
- As soon as semaphore value is greater than zero, one of the blocked threads wakes up and continues
- no guarantees as to which thread this might be
```cpp
sem_t empty, full;
void producer(char* buf) {
int in = 0;
for(;;) {
sem_wait(&empty);
buf[in] = getChar();
in = (in + 1) % MAX_SIZE;
sem_post(&full);
}
}
void consumer(char* buf) {
int out = 0;
for(;;) {
sem_wait(&full);
useChar(buf[out]);
out = (out + 1) % MAX_SIZE;
sem_post(&empty);
}
}
```
## POSIX Threads
## POSIX Thread 實例: 光線追蹤
[2016q1:Homework2](http://wiki.csie.ncku.edu.tw/embedded/2016q1h2) 提到 raytracing 程式,[UCLA Computer Science 35L, Winter 2016 Software Construction](http://web.cs.ucla.edu/classes/winter16/cs35L/) 課程有個作業值得參考:**[S35L_Assign8_Multithreading](https://github.com/maxwyb/CS35L_Assign8_Multithreading)**
編譯與測試
```shell
$ git clone https://github.com/maxwyb/CS35L_Assign8_Multithreading.git raytracing-threads
$ cd raytracing-threads
$ make clean all
$ ./srt 4 > out.ppm
$ diff -u out.ppm baseline.ppm
```
預期會得到下圖:

將 `srt` 後面的數字換成 1, 2, 4, 8 來測試執行時間
[ [main.c](https://github.com/maxwyb/CS35L_Assign8_Multithreading/blob/master/main.c) ]
```Cpp
#include <pthread.h>
pthread_t* threadID = malloc(nthreads * sizeof(pthread_t));
int res = pthread_create(&threadID[t], 0, pixelProcessing, (void *)&intervals[t]);
int res = pthread_join(threadID[t], &retVal);
```
## POSIX Thread
- [ ] [POSIX Threads Programming](https://hpc-tutorials.llnl.gov/posix/)
* Condition variables provide yet another way for threads to synchronize. While mutexes implement synchronization by controlling thread access to data, ==condition variables allow threads to synchronize based upon the actual value of data.==
* Condition Variable
* 當有兩個執行緒 A 跟 B。其中 A 需要等到一個變數的狀態轉爲 true 時,才能繼續執行,而這個變數狀態卻掌握在 B 的手中,那 B 將變數狀態改爲 true 後,就能用 signal 來喚醒在等待中的 A
* 如果不這樣做,那麼 A 就會需要一直判斷變數狀態是否改爲true 了,這會損失很多效能成本,且不能保證狀態是否還掌握在其它執行緒手中
* condition variable 總是搭配 mutex lock 使用

Condition variables must be declared with type pthread_cond_t, and must be initialized before they can be used. There are two ways to initialize a condition variable:
1. Statically, when it is declared. For example:
**pthread_cond_t myconvar = PTHREAD_COND_INITIALIZER;**
1. Dynamically, with the pthread_cond_init() routine. The ID of the created condition variable is returned to the calling thread through the _condition_ parameter. This method permits setting condition variable object attributes, _attr_.
## Synchronization
[Introduction to Computer Systems](http://www.cs.cmu.edu/~213/schedule.html) 對應的教科書 CS:APP [Concurrent Programming](https://www.cs.cmu.edu/~213/lectures/23-concprog.pdf), Page 40-56

CS:APP [Synchronization: Advanced](https://www.cs.cmu.edu/~213/lectures/25-sync-advanced.pdf), Page 40-49

計數器的程式範例:
```cpp
// 全域變數
volatile long cnt = 0; // 計數器
void *thread(void *vargp) {
long niters = *((long *)vargp);
for (long i = 0; i < niters; i++)
cnt++;
return NULL;
}
int main(int argc, char **argv) {
long niters;
pthread_t tid1, tid2;
niters = atoi(argv[1]);
pthread_create(&tid1, NULL, thread, &niters);
pthread_create(&tid2, NULL, thread, &niters);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
if (cnt != (2 * niters))
printf("Wrong! cnt=%ld\n", cnt);
else
printf("Correct! cnt=%ld\n", cnt);
exit(0);
}
```
運行的結果每次不一樣:
```
$ ./badcnt 10000
Correct! cnt=20000
$ ./badcnt 10000
Wrong! cnt=10458
```
把 `cnt` 變數操作的部分抽出來看:
執行緒函式的迴圈程式碼:
```cpp
for (long i = 0; i < niters; i++)
cnt++;
```
對應的組合語言程式碼:
```
# 以下四句為 Head 部分,記為 H
movq (%rdi), %rcx
testq %rcx, %rcx
jle .L2
movl $0, %eax
.L3:
movq cnt(%rip), %rdx # 讀取 cnt,記為 L
addq $1, %rdx # 更新 cnt,記為 U
movq %rdx, cnt(%rip) # 寫入 cnt,記為 S
# 以下為 Tail 部分,記為 T
addq $1, %rax
cmpq %rcx, %rax
jne .L3
.L2:
```
cnt 使用 `volatile` 關鍵字聲明,意思是避免編譯器產生的程式碼中,透過暫存器來保存數值,無論是讀取還是寫入,都在主記憶體操作。
細部的步驟分成 5 步:`H` -> `L` -> `U` -> `S` -> `T`,尤其要注意 LUS 這三個操作,這三個操作必須在一次執行中完成,一旦次序打亂,就會出現問題,不同執行緒拿到的值就不一定是最新的。
也就是說該函式的正確執行和指令的執行順序有關

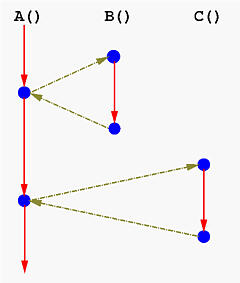
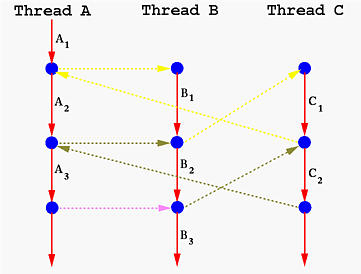
將 n 個 concurrent 執行緒的執行模型描述為 n 維空間中的軌跡線,每條軸 k 對應 k 的進度。下圖展示對於 H1, L1, U1, H2, L2, S1, T1, U2, S2, T2 的軌跡線的進度圖:

對於執行緒編號 `i`,操作共享變數 `cnt` 內含值的指令 (,Li,Ui,Si) 構成了一個 CS,每個 CS 不應該和其他執行緒的 CS 交替執行。換言之,需要對共享變數進行互斥的存取:
* 當執行緒繞過不安全區,叫做安全軌跡線;
* 反之,為不安全軌跡線;

mutual exclusion ([互斥](http://terms.naer.edu.tw/detail/50571/)) 手段的選擇,不是根據 CS 的大小,而是根據 CS 的性質,以及有哪些部分的程式碼,也就是,仰賴於核心內部的執行路徑。
semaphore 和 spinlock 屬於不同層次的互斥手段,前者的實現仰賴於後者,可類比於 HTTP 和 TCP/IP 的關係,儘管都算是網路通訊協定,但層次截然不同:
* [POSIX semaphore](http://www.csc.villanova.edu/~mdamian/threads/posixsem.html) 用於多個 process 之間對資源的互斥
* 雖然也是在核心中,但是該核心執行路徑是以 process 的身份,代表 process 來爭奪資源
* 如果 競爭不上,會有 context switch,process 可以去sleep,但 CPU 不會停下來,會接著運作其他的執行路徑
* 從概念上說,這和單核 CPU 或多核 CPU 沒有直接的關係,只是在
semaphore 本身的實作層面上,為了保證 semaphore 的 atomics,在多核 CPU 中需要 spinlock 來互斥
* 在多核 CPU 中, 加上了其他 CPU 的干擾,因此需要 spinlock 來幫助。一旦 CPU 進入 spinlock,就不會做別的事,直到鎖定成功為止。因此,這就決定了被 spinlock 鎖住的 CS 不能停
spinlock 的本意和目的就是保證資料修改的 atomics,因此也沒有理由在 spinlock 鎖住的 CS 中停留。
+ [Part 1: Mutex Locks](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-1:-Mutex-Locks)
+ [Part 2: Counting Semaphores](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-2:-Counting-Semaphores)
+ [Part 3: Working with Mutexes And Semaphores](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-3:-Working-with-Mutexes-And-Semaphores)
+ [Part 4: The Critical Section Problem](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-4:-The-Critical-Section-Problem)
+ [Part 5: Condition Variables](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-5:-Condition-Variables)
+ [Part 6: Implementing a barrier](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-6:-Implementing-a-barrier)
+ [Part 7: The Reader Writer Problem](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-7:-The-Reader-Writer-Problem)
+ [Part 8: Ring Buffer Example](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-8:-Ring-Buffer-Example)
+ [Part 9: Synchronization Across Processes](https://github.com/angrave/SystemProgramming/wiki/Synchronization,-Part-9:-Synchronization-Across-Processes)
案例: [Mutex and Semaphore](https://hackmd.io/@nKngvyhpQdGagg1V6GKLwA/Skh9Z2DpX) (你今天用對 mutex 了嗎?)
[Priority Inversion on Mars](http://wiki.csie.ncku.edu.tw/embedded/priority-inversion-on-Mars.pdf)

> 優先權: Task~1~(H) > Task~2~(M) > Task ~3~(L)
* 針對上圖解析
* `(1)` Task~3~ 正在執行,而 Task~1~ 和 Task~2~ 正等待特定事件發生,例如 timer interrupt
* `(2)` Task~3~ 為了存取共用資源,必須先獲取 lock
* `(3)` Task~3~ 使用共用資源 (灰色區域)。
* `(4)` Task~1~ 等待的事件發生 (可以是 "delay n ticks",此時 delay 結束),作業系統核心暫停 Task~3~ 改執行 Task~1~,因為 Task~1~ 有更高的優先權
* `(5)` `(6)` Task~1~ 執行一段時間直到試圖存取與 Task~3~ 共用的資源,但 lock 已被 Task~3~ 取走了,Task~1~ 只能等待 Task~3~ 釋出 lock
* `(7)` `(8)` Task~3~ 恢復執行,直到 Task~2~ 因特定事件被喚醒,如上述 `(4)` 的 Task~3~
* `(9)` `(10)` Task~2~ 執行結束後,將 CPU 資源讓給 Task~3~
* `(11)` `(12)` Task~3~ 用完共享資源後釋放 lock。作業系統核心知道尚有個更高優先權的任務 (即 Task~1~) 正在等待此 lock,執行 context switch 切換到 Task~1~
* `(13)` Task~1~ 取得 lock,開始存取共用資源。
Task~1~ 原本該有最高優先權,但現在卻降到 Task~3~ 的等級,於是反到是 Task~2 和 Task~3~ 有較高的優先權,優先權順序跟預期不同,這就是 Priority Inversion(優先權反轉)。
priority inheritance (PI) 是其中一種 Priority Inversion 解法:

* 針對上圖解析
* `(1)` `(2)` 同上例,Task~3~ 取得 lock
* `(3)` `(4)` `(5)` Task~3~ 存取資源時被 Task ~1~ 搶佔
* `(6)` Task~1~ 試圖取得 lock。作業系統核心發現 Task~3~ 持有 lock,但 Task~3~ 優先權卻低於 Task~1~,於是作業系統核心將 Task~3~ 優先權提升到與 Task~1~ 的等級
* `(7)` 作業系統核心讓 Task~3~ 恢復執行,Task~1~ 則繼續等待
* `(8)` Task~3~ 用畢資源,釋放 lock,作業系統核心將 Task~3~ 恢復成原本的優先權,恢復 Task~1~ 的執行
* `(9)` `(10)` Task~1~ 用畢資源,釋放 lock
* `(11)` Task~1~ 釋出 CPU,Task~2~ 取得 CPU 控制權。在這個解法中,Task~2~ 不會導致 priority inversion
* [Mutex vs. Semaphores – Part 1: Semaphores](https://blog.feabhas.com/2009/09/mutex-vs-semaphores-%E2%80%93-part-1-semaphores/)
* [Edsger Dijkstra](https://en.wikipedia.org/wiki/Edsger_W._Dijkstra) 在 1965 年提出 binary semaphore 的構想,嘗試去解決在 concurrent programs 中可能發生的 race conditions。想法便是透過兩個 function calls 存取系統資源 Semaphore,來標明要進入或離開 critical region。
* 使用 Semaphore 擁有的風險
* Accidental release
* This problem arises mainly due to a bug fix, product enhancement or cut-and-paste mistake.
* Recursive deadlock
* 某一個 task 重複地想要 lock 它自己已經鎖住的 Semaphore,通常發生在 libraries 或 recursive functions。
* 某一個 task 其持有的 Semaphore 已經被終止或發生錯誤。
* Priority inversion
* Semaphore as a signal
* **Synchronization** between tasks is where, typically, one task waits to be notified by another task before it can continue execution (unilateral rendezvous). A variant of this is either task may wait, called the bidirectional rendezvous. **Quite different to mutual exclusion, which is a protection mechanism.**
* 使用 Semaphore 作為處理 Synchronization 的方法容易造成 Debug 困難及增加 "accidental release" 類性的問題。
* [Mutex vs. Semaphores – Part 2: The Mutex](https://blog.feabhas.com/2009/09/mutex-vs-semaphores-%E2%80%93-part-2-the-mutex/)
* 作業系統實作中,需要引入的機制。"The major use of the term mutex appears to have been driven through the development of the common programming specification for UNIX based systems."
* 儘管 Mutex 及 Binary Semaphore 的概念極為相似,但有一個最重要的差異:**the principle of ownership**。
* 而 Ownership 的概念可以解決上一章所討論的五個風險
* Accidental release
* Mutex 若遭遇 Accidental release 將會直接發出 Error Message,因為它在當下並不是 owner。
* Recursive Deadlock
* 由於 Ownership,Mutex 可以支援 relocking 相同的 Mutex 多次,只要它被 released 相同的次數。
* Priority Inversion
* Priority Inheritance Protocol
* [Priority Ceiling Protocol](https://en.wikipedia.org/wiki/Priority_ceiling_protocol)
* [投影片](https://tams.informatik.uni-hamburg.de/lehre/2016ss/vorlesung/es/doc/cs.lth.se-RTP-F6b.pdf): 介紹 PCP,並實際推導兩個例子。
* Death Detection
* 如果某 task 因為某些原因而中止,則 RTOS 會去檢查此 task 是否擁有 Mutex ;若有, RTOS 則會負責通知所有 waiting 此 Mutex 的 tasks 們。最後再依據這些 tasks 們的情況,有不同的處理方式。
* All tasks readied with error condition
* 所有 tasks 假設 critical region 為未定義狀態,必需重新初始化。
* Only one task readied
* Ownership 交給此 readied task,並確保 the integrity of critical region,之後便正常執行。
* Semaphore as a signal
* Mutex 不會用來處理 Synchronization。
* [Mutex vs. Semaphores – Part 3: Mutual Exclusion Problems](https://blog.feabhas.com/2009/10/mutex-vs-semaphores-%E2%80%93-part-3-final-part-mutual-exclusion-problems/)
* 但還是有一些問題是無法使用 mutex 解決的。
* Circular deadlock
* One task is blocked waiting on a mutex owned by another task. That other task is also block waiting on a mutex held by the first task.
* Necessary Conditions
* Mutual Exclusion
* Hold and Wait
* Circular Waiting
* No preemption
* Solution: Priority Ceiling Protocol
* PCP 的設計可以讓低優先權的 task 提升至 ceiling value,讓其中一個必要條件 "Hold and Wait" 不會成立。
* Non-cooperation
* Most important aspect of mutual exclusion covered in these ramblings relies on one founding principle: **we have to rely on all tasks to access critical regions using mutual exclusion primitives**.
* Unfortunately this is dependent on the design of the software and cannot be detected by the run-time system.
* Solution: Monitor
* Not typically supplied by the RTOS
* A monitor simply encapsulates the shared resource and the locking mechanism into a single construct.
* Access to the shared resource is through a controlled interface which cannot be bypassed.
* [Mutexes and Semaphores Demystified](http://www.barrgroup.com/Embedded-Systems/How-To/RTOS-Mutex-Semaphore)
* Myth: Mutexes and Semaphores are Interchangeable
* Reality: 即使 Mutexes 跟 Semaphores 在實作上有極為相似的地方,但他們通常被用在不同的情境。
* The correct use of a semaphore is for **signaling** from one task to another.
* A mutex is meant to be taken and released, always in that order, by each task that uses the shared resource it protects.
* 還有一個重要的差別在於,即便是正確地使用 mutex 去存取共用資源,仍有可能造成危險的副作用。
* 任兩個擁有不同優先權的 RTOS task 存取同一個 mutex,可能會創造 **Priority Inversion**。
* Definition: The real trouble arises at run-time, when a medium-priority task preempts a lower-priority task using a shared resource on which the higher-priority task is pending. If the higher-priority task is otherwise ready to run, but a medium-priority task is currently running instead, a priority inversion is said to occur. [[Source]](https://barrgroup.com/Embedded-Systems/How-To/RTOS-Priority-Inversion)
* 但幸運的是,Priority Inversion 的風險可以透過修改作業系統裡 mutex 的實作而減少,其中會增加 acquiring and releasing muetexs 時的 overhead。
* 當 Semaphores 被用作 signaling 時,是不會造成 Priority Inversion 的,也因此是沒有必要去跟 Mutexes 一樣去更改 Semaphores 的實作。
* This is a second important reason for having distinct APIs for these two very different RTOS primitives.