# 算法比赛套路
## leetcode得进阶套路
### 如何判断出当前是第多少个case
```angular2html
import math
math.a=0
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
math.a+=1
print(math.a)
n = len(nums)
for i in range(n):
for j in range(i + 1, n):
if nums[i] + nums[j] == target:
return [i, j]
return []
```
## python 常见语法,常用函数
### 字符串篇
```
a = 'Aaaaa'
print(a.count('a')) #统计某个字符串的次数
print(a.lower())
print(a.upper())
b= a.replace('a', 'b') # 进行替换
print(b)
```
**正则表达式**
```
import re #引入正则表达式包
s = "abcadffiwef/sdfsdf"
b = re.match('abc.*', s)
print(b[0])
c= re.search('c.*', s)
print(c[0])
out:
abcadffiwef/sdfsdf
cadffiwef/sdfsdf
```
**format 格式化**

```
s = 'asdf{},adfsdf{}'
print(s.format(2,1))
print('asdf{0},adfsdf{2}'.format(1,2,3)) #利用下标进行索引
print('asdf{name},adfsdf{pwd}'.format(name = 1, pwd = 32)) # 利用字符串进行替换,参数
print('{:.2f}'.format(2.339))
```
### eval() NB
```
x = 10
ans = eval('x + 2')
print(ans)
ans = eval('pow(2,x)')
print(ans)
out:
12
1024
```
### 上下界的查询
使用python的库bisect
```
import bisect
a = [1,2,3]
tmp = bisect.bisect_right(a, 3) #查询到右边
print(tmp)
```
### 位运算

### 保留小数位
```
x = 1.512187
print(round(x,4)) # 四舍五入保留几位
print(round(x,100)) # 但是不能强制输出多位
print('%.4f'%x)
print('%.10f'%x) #可以强制输出
import math
print(math.floor(x)) # 向下取整
print(math.ceil(x)) #向上取整
```
### 队列List
删除操作,添加操作
```
只是有这些操作而已,不过效率低下
nums = ['a', 'b', 'c', 'd']
nums.__delitem__(0)根据下标 # 类似的 {}集合也有这个方法
print(nums)
nums.append('a')
nums.append('b') # 添加
nums.insert(1,'F') # 往下标所在位置插入
print(nums)
nums.remove('b')
print(nums)
nums.remove('b') #删除看到的第一个元素
print(nums)
nums.extend([1,1])这个比加法运算符效率稍微高点
```
### 进制转换
```
x =14
print(bin(x))# 2进制
'{:018b}'.format(i) # 这样可以转化为进制后补0。 这里b代表二进制, 18 代表18位
print(oct(x)) # 8进制
print(hex(x))# 16进制
print(int(x))# 10进制
#将10 进制转化为N进制
def TentoN(num, N):
num = int(num)
ans =[]
while num !=0:
rest = num % N
num = num // N
ans.append(rest)
ans.reverse()
return ans
# 将N进制转化为10进制
def NtoTen(num, N):
ans =0
num = str(num)
for i in num:
ans= ans * N + int(i)
return ans
```
### 数学排列组合
```
import math
def factorial_(n):
result=1
for i in range(2,n+1):
result=result*i
return result
def comb_1(n,m):
return math.factorial(n)//(math.factorial(n-m)*math.factorial(m)) #直接使用math里的阶乘函数计算组合数
def comb_2(n,m):
return factorial_(n)//(factorial_(n-m)*factorial_(m)) #使用自己的阶乘函数计算组合数
def perm_1(n,m):
return math.factorial(n)//math.factorial(n-m) #直接使用math里的阶乘函数计算排列数
def perm_2(n,m):
return math.factorial(n)//math.factorial(n-m) #使用自己的阶乘函数计算排列数
if __name__=='__main__':
print(comb_1(3,2))
print(comb_2(3,2))
print(perm_1(3,2))
print(perm_2(3,2))
```
## 数据结构篇
### 常规的树
```
class node:
def __init__(self):
self.parent =None
self.children =[]
self.deep = None # 层级
self.tag = None
self.id = None
self.index =None
def show(self):
print('.' * self.deep*2, end='')
# print(self.id, end=' ')
print(self.tag + ' ')
for i in self.children:
i.show()
```
### 并查集
判断元素是否同集合以及合并
```
class BQSet():
def __init__(self):
self.f = {} # f[i]代表i的父节点
# #init
# for i in range(10):
# f[i] = i
def getFather(self,origin):
a = origin
while self.f[a] != a:
a = self.f[a]
self.f[origin] = a
return a
# 只需要看a, b 是否 有共同父节点
def judge(self,a, b):
a = self.getFather(a)
b = self.getFather(b)
if self.f[a] == self.f[b]:
return True
else:
return False
def Union(self,source, a):
a = self.getFather(a)
sF = self.getFather(source)
self.f[a] = sF
if __name__ == '__main__':
bq = BQSet()
for i in range(10):
bq.f[i] =i
bq.f[2] =1
a= bq.judge(1,2)
bq.Union(2,3)
print(a)
```
### 最小生成树 Kruskal
边权值和最小
```
n, m = input().split(' ')
n = int(n)
# print(n)
m = int(m)
edges = []
for i in range(m):
s = input().split(' ')
edges.append((int(s[0]), int(s[1]), int(s[2])))
# 并查集
class BQSet():
def __init__(self):
self.f = {}
# #init
# for i in range(10):
# f[i] = i
def getFather(self, origin):
a = origin
while self.f[a] != a:
a = self.f[a]
self.f[origin] = a
return a
# 只需要看a, b 是否 有共同父节点
def judge(self, a, b):
a = self.getFather(a)
b = self.getFather(b)
if self.f[a] == self.f[b]:
return True
else:
return False
def Union(self, source, a):
a = self.getFather(a)
sF = self.getFather(source)
self.f[a] = sF
# Kruskal 关键是判断是不是同一个集合里面
def kruskal(edges):
bq = BQSet()
# 初始化并查集
for i in range(1, n + 1):
bq.f[i] = i
# 先进行排序
edges = sorted(edges, key=lambda x: x[2])
# print(edges)
arried = {}
# finalE =[]
sum = 0
count = 0
for u, v, w in edges:
if bq.judge(u, v):
pass
else: # 如果边不在同一个集合,就加入
bq.Union(u, v)
sum += w
count += 1
if count == n - 1:
print(sum)
else:
print('orz')
# print(count)
kruskal(edges)
```
## 算法板子
### 快排板子
```
# 可以自定义比较函数,决定排序方式
def cmp(a,b):
return a>b
class quiteSort:
def __init__(self):
self.cmp = lambda a, b:a< b
# 设置比较函数
def setCmp(self, cmp):
self.cmp =cmp
# 随机找一个中间基准值,将数据分成左右两堆
def randomized_partition(self, nums, l, r):
import random
pivot = random.randint(l, r)
nums[pivot], nums[r] = nums[r], nums[pivot]
i = l - 1
for j in range(l, r):
if self.cmp(nums[j],nums[r]):
i += 1
nums[j], nums[i] = nums[i], nums[j]
i += 1
nums[i], nums[r] = nums[r], nums[i]
return i
# 不断进行细分
def randomized_quicksort(self, nums, l, r):
if r - l <= 0:
return
mid = self.randomized_partition(nums, l, r)
self.randomized_quicksort(nums, l, mid - 1)
self.randomized_quicksort(nums, mid + 1, r)
def sortArray(self, nums):
self.randomized_quicksort(nums, 0, len(nums) - 1)
return nums
```
### 自定义二分查找
```
class DichotomousSearch():
def __init__(self):
pass
# 查找k在有序数组nums 中得位置。 nums是升序得
#return index, flag flag是代表是否有和k匹配得数得bool。
def search(self, nums, k):
l = 0
r = len(nums)-1
while l<r:
mid = (l + r) // 2
if nums[mid]> k: # 向左边找
r = mid - 1
elif nums[mid] <k: # 向右边找
l = mid +1
elif nums[mid] == k:
l = r = mid
break
if nums[l] == k:
return l, True
else:
return l, False
```
### Dijstra 最短路径
```
import collections
INF =float('inf')
import heapq
class Solution(object):
def networkDelayTime(self, times, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
adj ={} # 邻接表
for i in range(1,N+1):
adj[i] ={}
for u, v, w in times:
adj[u][v] =w
def dijkstra(adj, K): #K是出发的点, 这里默认到达所有点
arrived ={} # 已经到的点
pq = [(0, K)]# 存储需要到的点的最短值
while pq:
d, node = heapq.heappop(pq)
if node in arrived: # 如果已经到达,
continue
arrived[node] = d
# print(node)
for nei in adj[node]:
if nei not in arrived:
heapq.heappush(pq, (d + adj[node][nei], nei))
return arrived
print(dijkstra(adj, K))
Solution.networkDelayTime(None,times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2)
```
### SPFA最短路
```
# 总结一下,SPFA是如何做到“只更新可能更新的点”的?
#
# 只让当前点能到达的点入队
# 如果一个点已经在队列里,便不重复入队
# 如果一条边未被更新,那么它的终点不入队
INF =float('inf')
class SPFA(object):
def networkDelayTime(self, edges, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
times =edges
arrived ={} # 已经到的点
for i in range(1, N + 1):
arrived[i] = INF
arrived[K] = 0
adj ={} # 邻接表
for i in range(1,N+1):
adj[i] ={}
for u, v, w in times:
adj[u][v] =w
q = [K] # 优化队列
vis ={} # 是否正在队列里
count = {} # 统计在队列里出现多少次
for i in range(1,N+1):
vis[i] = False
count[i] = 0
vis[K] = True # 代表在队列里面
count[K] +=1
while q:
now = q.pop()
vis[now] = False
for i in adj[now]:
to = i
# 进行了松弛的点
if arrived[to]> arrived[now] + adj[now][to]:
arrived[to] = arrived[now] + adj[now][to]
if not vis[to]:
vis[to] = True
count[to] +=1
q.append(to)
if count[to] > N+1: # //判断负环
return False
return arrived
a = SPFA.networkDelayTime(None,[[1,2,1],[2,3,7],[1,3,4],[2,1,2]],
3,
2)
print(a)
```
### floyd最短路
```
# 2、Floyd算法可以解决多源最短路径;
# k 前k个点代表在前k个的前提下的最短路径
import collections
INF =float('inf')
class Solution(object):
def networkDelayTime(self, times, N, K):
"""
:type times: List[List[int]]
:type N: int
:type K: int
:rtype: int
"""
adj ={} # 邻接表
# 初始化邻接表
for i in range(1,N+1):
adj[i]={}
for j in range(1,N+1):
adj[i][j] = INF
if i ==j:
adj[i][j] = 0
for u, v, w in times:
adj[u][v] =w
def floyd(adj):
for k in range(1, N+1):
for i in range(1, N + 1):
for j in range(1, N + 1):
adj[i][j] = min(adj[i][j], adj[i][k] + adj[k][j])
return adj
adj = floyd(adj)
if max(adj[K].values()) == INF:
return -1
return max(adj[K].values())
a = Solution.networkDelayTime(None,times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2)
print(a)
```
### 拓补排序
- 不断找入度为0的点
### 线段树
```
```
### 回溯全排列
```
arr = [i+1 for i in range(5)]
visit = [True for i in range(len(arr))]
temp = ["" for x in range(0, len(arr))]
# 回溯记录
def dfs(position):
if position == len(arr):
print(temp)
return None
for index in range(0, len(arr)):
if visit[index] == True:
temp[position] = arr[index]
visit[index] = False
dfs(position + 1)
visit[index] = True
dfs(0)
```
### 查分约束
转化为图的问题
### KMP字符串匹配
自动状态机
```
class Solution(object):
def strStr(self, haystack, needle):
"""
:type haystack: str
:type needle: str
:rtype: int
"""
if haystack == '':
if needle =='':
return 0
else:
return -1
elif needle =='':
return 0
# 计算next数组, next[i]代表前i个字符串的最长子串
def getnext(s):
n = len(s)
next = [0,0] # 第一个0代表空字符串
for i in range(2, n+1):
# print(next, s, i-1)
if s[next[i-1]] == s[i-1]:
next.append(next[i-1] +1)
else:
j = next[next[i-1]]
while j > 0:
if s[j] == s[i-1]:
next.append(j+1)
break
j = next[j]
if j ==0:
if s[i-1] == s[0]:
next.append(1)
else:
next.append(0)
return next
next =getnext(needle)
print(next)
# 构造有限状态机
def kmp(s, next): # 一个状态机
n = len(s)
state = {'other':True}
for i in s:
state[i] = True
matrix = [{} for i in range(n+1)]
#初始化
for i in state:
matrix[0][i] = 0
matrix[0][s[0]] =1
# 归纳法进行递推
for i in range(1, n+1):
j = i
while j> 0:
if j >= n:
j = next[j]
continue
char = s[j]
if char not in matrix[i]:
matrix[i][char] = j+1
j = next[j]
if j ==0:
if s[0] not in matrix[i]:
matrix[i][s[0]] =1
for k in state:
if k not in matrix[i]:
matrix[i][k] = 0
return matrix, state
m,state = kmp(needle, next)
for i in range(len(m)):
print(i, m[i])
print(m)
def search(txt):
N = len(txt)
l = len(needle)
stateNow = 0
for i in range(N):
char = txt[i]
if char in state:
stateNow = m[stateNow][char]
else:
stateNow = m[stateNow]['other']
if stateNow == l:
return i- l+1
return -1
print(search(haystack))
return search(haystack)
Solution.strStr(None,"ababcaababcaabc",
"ababcaabc")
```
```
from PIL import Image
im = Image.open('./../image/lena.png')
```
存储
```
# 把图像用png格式保存:
im.save('thumbnail.png', 'png')
```
转换成**numpy**形式
```
img = np.array(im) # image类 转 numpy
```
将**numpy**格式数组用图片显示
```
from matplotlib import pyplot as plt
plt.imshow(img)
plt.show()
```

分为不同得**通道**显示
```
b = img[:,:,0:1]
plt.imshow(img, 'Blues')
```

## 关于图像平滑处理
### 首先对图像添加噪声
我们这里添加白色小点得噪声

**白色得噪声是(255,255,255)**
得到噪声图

### 定义
图像平滑是一种区域增强的算法,平滑算法有**邻域平均法、中指滤波、边界保持类滤波**等。在图像产生、传输和复制过程中,常常会因为多方面原因而**被噪声干扰或出现数据丢失,降低了图像的质量**(某一像素,如果它与周围像素点相比有明显的不同,则该点被噪声所感染)。这就需要**对图像进行一定的增强处理以减小这些缺陷带来的影响**。
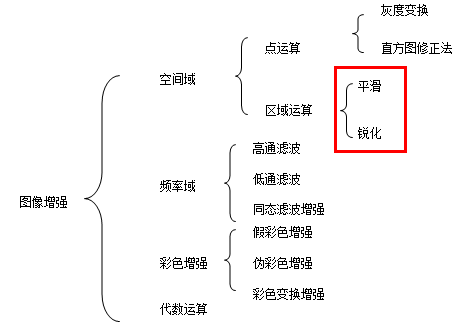
### 邻域平均法和均值滤波
其实就是一个**卷积运算**
可以类比一下卷积神经网络
$$g(x,y)= 1/M \sum_{(x,y)∈S} f(x,y)$$

**如图**

- 我们这里先写一个单通道单核得卷积

- 初始化一个卷积核
```
# filterKernel = np.array([
# [1, 1, 1],
# [1, 1, 1],
# [1, 1, 1]
# ])
filterKernel = np.ones((6,6))
```
- 查看结果

- **很明显有效果, 然后就是变单通道为多通道,单核为多核**

**success**
### 高斯平滑
为了克服简单局部平均法的弊端(图像模糊),目前已提出许多保持边缘、细节的局部平滑算法。它们的出发点都集中在如何选择邻域的大小、形状和方向、参数加平均及邻域各店的权重系数等。
**图像高斯平滑也是邻域平均的思想对图像进行平滑的一种方法**,在图像高斯平滑中,对图像进行平均时,不同位置的像素被赋予了不同的权重。高斯平滑与简单平滑不同,它在对邻域内像素进行平均时,给予不同位置的像素不同的权值,下图的所示的 3 * 3 和 5 * 5 领域的高斯模板。
**其实就是用二维高斯去生成一个卷积核**

### 总结
到这里,一些基本得卷积算法就已经剖析完毕,剩下得就只是对这些卷积核做一定处理。
### **引申滤波的概念**
滤波的目的主要两个:
1.通过滤波来提取图像特征,简化图像所带的信息作为后续其它的图像处理
2.为适应图像处理的需求,通过滤波消除图像数字化时所混入的噪声
**其中第一点就是边缘检测中所使用的基本思想,即简化图像信息,使用边缘线代表图像所携带信息**
**滤波可理解为滤波器(通常为3*3、5*5矩阵)在图像上进行从上到下,从左到右的遍历,计算滤波器与对应像素的值并根据滤波目的进行数值计算返回值到当前像素点**,实际就是卷积
## 图像几何变换(缩放、图像旋转、图像翻转与图像平移)
主要知识:**线性代数**
### 提前概念
对于一个图像,我们可以表达成一个**二维函数**
$$f(x, y) = 色值 $$
**而几何变换,并不改变色值,仅仅改变x,y得位置。**
也就是说
$$f(x^{`}, y^{`}) = f(x, y)$$
**是一个映射**
**(以下得图转载)**
### 平移

### 缩放

### 旋转

### 镜像变换

### 插值算法
关于以上变换有个要注意得问题。
**变换后得坐标,定义域不一定和值域完全重合。**
也就是说,变换后得点可能落不到整数上(一种情况。)
**那么就需要插值算法了。** (简单起见,这里只讲线性插值算法)
先讲一下整体得套路:

#### 邻近插值算法
简单来说就是,直接对x和y进行取整。
按照上述思路实现。

不难看出,效果还行。
试试旋转矩阵

#### 双线性插值
**双线性插值是线性插值在二维时的推广,在两个方向上共做了三次线性插值。**定义了一个双曲抛物面与四个已知点拟合。
具体操作为在X方向上进行两次线性插值计算,然后在Y方向上进行一次插值计算

**具体得公式**

**(我这里踩了坑,原有的图像数据的大小是8位的,最大255)所以在上述运算中很容易就溢出了。**
结果

**success**
## 仿射变换与透视变换
### 提前概念(二维为例子)
- 什么是线性变换?
$$x^{,}= A \cdot x_{0}$$
原点不变,且原有的平行关系和倍数关系都不变
### 仿射变换
在线性变换的基础上,**原点可以发生变换**。
仿射变换是单纯对图片进行平移,缩放,倾斜和旋转,而这几个操作都不会改变图片线之间的平行关系。
$$x^{,}= A \cdot x_{0} + b$$
如果用三维去线性表达,那么就是:
$$
\begin{bmatrix}
x^{,}\\
y^{,}\\
1
\end{bmatrix}
=
\begin{bmatrix}
a11 &a12 &b1 \\
a21 & a22& b2\\
0&0 & 1
\end{bmatrix}
\cdot
\begin{bmatrix}
x\\
y\\
1
\end{bmatrix}
$$
### 什么是透视变换
如果说仿射变换是在二维空间中的旋转,平移和缩放。**那么透视变换则是在三维空间中视角的变化。**
**相对于仿射。透视变换能保持“直线性”,即原图像里面的直线,经透视变换后仍为直线**

这里讲一下,如果说,仿射变化是三维空间中对某个平面的一些二维变化。
那么透视变化就是对这个平面进行变换,并且利用视觉原理将图像进行一定处理(近大,远小)。

**也就是说,先将图像旋转到$A^{,}B^{,}C^{,}$**
**然后投影到平面$ABC$**
**这里有一下假设,假设我们人是远点,从我们的眼睛去看,垂直与我们的目光的这个轴是$z$轴.**
**在离我们一定距离的地方选一个画布$ABC$,其他所有画像都投影到这个画布上。**
**那么假设平面$z$轴的距离是1.**
**从$A^{,}B^{,}C^{,}$投影到画布$ABC$,计算公式为**
$$
\begin{bmatrix}
x\\
y\\
1
\end{bmatrix}
=
(1/z^{,}) \cdot
\begin{bmatrix}
x^{,}\\
y^{,}\\
z^{,}
\end{bmatrix}
$$
有了以上概念,**我们来最后计算一遍**

**先进行旋转变换。**
**然后进行投影变换。**

然后就是繁琐的解方程过程,**这里是非齐次线性方程组求解**

让我们来看一下最后效果。

右边是我们手动实现的。
具体的思路是仿照**opencv**,不过代码是手动用**numpy**实现的,有助于理解。
**核心代码**
```
#根据四个顶点设置图像透视变换矩阵
pos1 = np.float32([[114, 82], [287, 156], [8, 322], [216, 333]]) # 原来的坐标
pos2 = np.float32([[0, 0], [188, 0], [0, 262], [188, 262]]) # 变换后的坐标
# 实际肉眼看上去的x,y和数组的存储是有区别的
def exchangeXY(pos):
for i in range(len(pos)):
pos[i] = [pos[i][1], pos[i][0]]
exchangeXY(pos1)
exchangeXY(pos2)
# 计算透视变换矩阵
def getPerspectiveTransform(pos1, pos2):
length = len(pos1)
tmpMatrix = []
b = []
for i in range(length):
x0, y0 = pos1[i]
xn, yn = pos2[i]
tmpMatrix.append(
[x0, y0,1,0,0,0,-1 * x0 * xn, -1 * y0 * xn]
)
tmpMatrix.append(
[0,0,0,x0, y0,1,-1 * x0 * yn, -1 * y0 * yn]
)
b.append(xn)
b.append(yn)
tmpMatrix= np.array(tmpMatrix)
b = np.array(b)
ans =np.dot(np.linalg.inv(tmpMatrix), b)
finalMatrix = [
[ans[0], ans[1], ans[2]],
[ans[3], ans[4], ans[5]],
[ans[6], ans[7], 1]
]
return np.array(finalMatrix)
M = getPerspectiveTransform(pos1, pos2)
```
## 图像阈值化
图像的二值化或阈值化(Binarization)旨在提取图像中的目标物体,将背景以及噪声区分开来。通常会设定一个阈值T,通过T将图像的像素划分为两类:大于T的像素群和小于T的像素群。

**二进制阈值化**

所谓其他阈值化,其实也就是不断在基础形式上都不同的类进行一定处理。
## 灰度直方图
### 前置概念
**RGB图像:**
RGB的值分别为0,0,0 表示的是黑色。
RGB的值为255,255,255表示的是白色。
**灰度图像:**
灰度值为0表示黑色。
灰度值为255表示白色。
### 定义
灰度直方图(histogram)是灰度级的函数,描述的是图像中每种灰度级像素的个数,反映图像中每种灰度出现的频率。横坐标是灰度级,纵坐标是灰度级出现的频率。

**用处:**
在使用轮廓线确定物体边界时,通过直方图更好的选择边界阈值,进行阈值化处理;对物体与背景有较强对比的景物的分割特别有用;简单物体的面积和综合光密度IOD可以通过图像的直方图求得。
### 直方图修正
图像的直方图修正方法主要有直方图均衡化和直方图规定化直方图修正的目的是,**使修正后的图像的灰度间距拉开或者是图像灰度分布均匀,从而增大反差,使图像细节清晰,从而达到图像增强的目的**
我们这里主要**直方图均衡化**。
算法原理,把原有的概率乘以一个数(通常是色值的大小,取整)。这样就可以把一些较为相近的值给化到一起了。
## 灰度值处理
**rbg如何变为灰度值图像呢?**
一种常见的方法是将RGB三个分量求和再取平均值,但更为准确的方法是设置不同的权重,将RGB分量按不同的比例进行灰度划分。比如人类的眼睛感官蓝色的敏感度最低,敏感最高的是绿色,因此将RGB按照0.299、0.587、0.144比例加权平均能得到较合理的灰度图像,

## 图像灰度线性变换
图像的灰度线性变换是通过建立灰度映射来调整原始图像的灰度,从而改善图像的质量,凸显图像的细节,**提高图像的对比度**
$$f(D) = S \cdot D + b$$
**图像灰度非线性变换**
- 例如什么一元二次函数
- 对数变换
- 伽玛变换又称为指数变换或幂次变换,是另一种常用的灰度非线性变换。就是指数函数
## 图像锐化
展图像锐化和边缘检测处理,加强原图像的高频部分。锐化突出图像的边缘细节,改善图像的对比度,使模糊的图像变得更清晰。
图像锐化和边缘提取技术可以消除图像中的噪声,**提取图像信息中用来表征图像的一些变量**,为图像识别提供基础。
通常使用**灰度差分法**对图像的边缘、轮廓进行处理,将其凸显。
**如果把每一种算法都用卷积核来表示成矩阵的乘法,那么实际上就是一种卷积运算了**
### Roberts算子(梯度法)
**通过计算梯度从而凸显轮廓**
对于图像 ![[公式]](https://www.zhihu.com/equation?tex=f%28x%2Cy%29) ,在点 ![[公式]](https://www.zhihu.com/equation?tex=%28x%2Cy%29) 处的梯度是一个矢量,定义为![[公式]](https://www.zhihu.com/equation?tex=+G%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%09%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%7D%5C%5C+%09%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+y%7D%5C%5C+%5Cend%7Barray%7D+%5Cright%5D+++)。
梯度的幅度表示为 ![[公式]](https://www.zhihu.com/equation?tex=G%5Bf%28x%2Cy%29%5D%3D%5B%28%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%7D%29%5E2%2B%28%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+y%7D%29%5E2%5D%5E%7B1%2F2%7D)
对于数字图像而言, ![[公式]](https://www.zhihu.com/equation?tex=+G%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%3D%5Cleft%5C%7B+%5Cleft%5B+f%5Cleft%28+i%2Cj+%5Cright%29+-f%5Cleft%28+i%2B1%2Cj+%5Cright%29+%5Cright%5D+%5E2%2B%5Cleft%5B+f%5Cleft%28+i%2Cj+%5Cright%29+-f%5Cleft%28+i%2Cj%2B1+%5Cright%29+%5Cright%5D+%5E2+%5Cright%5C%7D+%5E%7B1%2F2%7D+) ,
该式可以简化成 ![[公式]](https://www.zhihu.com/equation?tex=+G%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%3D%5Cleft%7C+f%5Cleft%28+i%2Cj+%5Cright%29+-f%5Cleft%28+i%2B1%2Cj+%5Cright%29+%5Cright%7C%2B%5Cleft%7C+f%5Cleft%28+i%2Cj+%5Cright%29+-f%5Cleft%28+i%2Cj%2B1+%5Cright%29+%5Cright%7C+)
**当梯度计算完之后,可以根据需要生成不同的梯度增强图像,**
1)第一种, ![[公式]](https://www.zhihu.com/equation?tex=+g%5Cleft%28+x%2Cy+%5Cright%29+%3DG%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+++) ,只显示灰度变化大的边缘轮廓,灰度变化平缓的呈黑色。
2)第二种, ![[公式]](https://www.zhihu.com/equation?tex=g%5Cleft%28+x%2Cy+%5Cright%29+%3D%5Cleft%5C%7B+%5Cbegin%7Barray%7D%7Bc%7D+%09G%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%26%2CG%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%5Cge+thresh%5C%5C+%09f%5Cleft%28+x%2Cy+%5Cright%29+%26%2C+otherwise%5C%5C+%5Cend%7Barray%7D+%5Cright.+)
可以显示出非常明显的边缘轮廓,又不会破坏原灰度变化平缓的背景。
3)第三种, ![[公式]](https://www.zhihu.com/equation?tex=+g%5Cleft%28+x%2Cy+%5Cright%29+%3D%5Cleft%5C%7B+%5Cbegin%7Bmatrix%7D+%09L_G%26%09%09%2CG%5Cleft%5B+f%5Cleft%28+x%2Cy+%5Cright%29+%5Cright%5D+%5Cge+thresh%5C%5C+%09f%5Cleft%28+x%2Cy+%5Cright%29%26%09%09%2Cotherwise%5C%5C+%5Cend%7Bmatrix%7D+%5Cright.+++)
。。。。还有很多类似的
### **Sobel算子**
采用梯度微分锐化图像,会让噪声、条纹得到增强,Sobel算子在一定程度上解决了这个问题, ![[公式]](https://www.zhihu.com/equation?tex=+S_x%3D%5Cleft%5B+f%5Cleft%28+i%2B1%2Cj-1+%5Cright%29+%2B2f%5Cleft%28+i%2B1%2Cj+%5Cright%29+%2Bf%5Cleft%28+i%2B1%2Cj%2B1+%5Cright%29+%5Cright%5D++%5C%5C+-%5Cleft%5B+f%5Cleft%28+i-1%2Cj-1+%5Cright%29+%2B2f%5Cleft%28+i-1%2Cj+%5Cright%29+%2Bf%5Cleft%28+i-1%2Cj%2B1+%5Cright%29+%5Cright%5D++%5C%5C+S_y%3D%5Cleft%5B+f%5Cleft%28+i-1%2Cj%2B1+%5Cright%29+%2B2f%5Cleft%28+i%2Cj%2B1+%5Cright%29+%2Bf%5Cleft%28+i%2B1%2Cj%2B1+%5Cright%29+%5Cright%5D++%5C%5C+-%5Cleft%5B+f%5Cleft%28+i-1%2Cj-1+%5Cright%29+%2B2f%5Cleft%28+i%2Cj-1+%5Cright%29+%2Bf%5Cleft%28+i%2B1%2Cj-1+%5Cright%29+%5Cright%5D++)
从这个式子中,可以得到两个性质,
- Sobel引入了平均的因素,因此对噪声有一定的平滑作用
- Sobel算子的操作就是相隔两个行(列)的差分,所以边缘两侧元素的得到了增强,因此边缘显得粗而亮。
- Sobel算子表示形式为:
![[公式]](https://www.zhihu.com/equation?tex=+H_1%3D%5Cleft%5B+%5Cbegin%7Bmatrix%7D+%09-1%26%09%090%26%09%091%5C%5C+%09-2%26%09%090%2A%26%09%092%5C%5C+%09-1%26%09%090%26%09%091%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+%5C%2C%5C%2C+++H_2%3D%5Cleft%5B+%5Cbegin%7Bmatrix%7D+%09-1%26%09%09-2%26%09%09-1%5C%5C+%090%26%09%090%2A%26%09%090%5C%5C+%091%26%09%092%26%09%091%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+)
### **拉普拉斯算子(二阶微分)**
拉普拉斯运算也是各向同性的线性运算。拉普拉斯算子为: ![[公式]](https://www.zhihu.com/equation?tex=+%5Cnabla+%5E2f%3D%5Cfrac%7B%5Cpartial+%5E2f%7D%7B%5Cpartial+x%5E2%7D%2B%5Cfrac%7B%5Cpartial+%5E2f%7D%7B%5Cpartial+y%5E2%7D++) ,锐化之后的图像 ![[公式]](https://www.zhihu.com/equation?tex=g%3Df-k+%5Cnabla+%5E2f)
![[公式]](https://www.zhihu.com/equation?tex=k) 为扩散效应的系数。
![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Balign%2A%7D+++%5Cfrac%7B%5Cpartial+%5E2f%5Cleft%28+x%2Cy+%5Cright%29%7D%7B%5Cpartial+x%5E2%7D+%26%3D+%5Cnabla+_xf%5Cleft%28+i%2B1%2Cj+%5Cright%29+-%5Cnabla+_xf%5Cleft%28+i%2Cj+%5Cright%29+%5C%5C+%26%3D+%5Cleft%5B+f%5Cleft%28+i%2B1%2Cj+%5Cright%29+-f%5Cleft%28+i%2Cj+%5Cright%29+%5Cright%5D+-%5Cleft%5B+f%5Cleft%28+i%2Cj+%5Cright%29+-f%5Cleft%28+i-1%2Cj+%5Cright%29+%5Cright%5D+%5C%5C+%26%3D+f%5Cleft%28+i%2B1%2Cj+%5Cright%29+%2Bf%5Cleft%28+i-1%2Cj+%5Cright%29+-2f%5Cleft%28+i%2Cj+%5Cright%29+%5C%5C+%5Cfrac%7B%5Cpartial+%5E2f%5Cleft%28+x%2Cy+%5Cright%29%7D%7B%5Cpartial+y%5E2%7D%26%3Df%5Cleft%28+i%2Cj-1+%5Cright%29+%2Bf%5Cleft%28+i%2Cj%2B1+%5Cright%29+-2f%5Cleft%28+i%2Cj+%5Cright%29%5C%5C+%5Cend%7Balign%2A%7D)
![[公式]](https://www.zhihu.com/equation?tex=%5Cbegin%7Balign%7D+%5Cnabla+%5E2f+%26%3D%5Cfrac%7B%5Cpartial+%5E2f%5Cleft%28+x%2Cy+%5Cright%29%7D%7B%5Cpartial+x%5E2%7D%2B%5Cfrac%7B%5Cpartial+%5E2f%5Cleft%28+x%2Cy+%5Cright%29%7D%7B%5Cpartial+y%5E2%7D+%5C%5C+%26%3D-5%5Cleft%5C%7B+f%5Cleft%28+i%2Cj+%5Cright%29+-%5Cfrac%7B1%7D%7B5%7D%5Cleft%5B+f%5Cleft%28+i%2B1%2Cj+%5Cright%29+%2Bf%5Cleft%28+i-1%2Cj+%5Cright%29+%2Bf%5Cleft%28+i-1%2Cj-1+%5Cright%29+%2Bf%5Cleft%28+i%2B1.j%2B1+%5Cright%29+%2Bf%5Cleft%28+i%2Cj+%5Cright%29+%5Cright%5D+%5Cright%5C%7D++%5Cend%7Balign%7D)
由此式可知,数字图像在 ![[公式]](https://www.zhihu.com/equation?tex=%28i%2Cj%29) 点的拉普拉斯算子,可以由该点的灰度值减去该点及其邻域四个点的平均灰度值求得。
### Canny算子
**1.使用高斯平滑(如公式所示)去除噪声。**

**2.按照Sobel滤波器步骤计算梯度幅值和方向,寻找图像的强度梯度。先将卷积模板分别作用x和y方向,再计算梯度幅值和方向,其公式如下所示。梯度方向一般取0度、45度、90度和135度四个方向。**

**3.通过非极大值抑制(Non-maximum Suppression)过滤掉非边缘像素,将模糊的边界变得清晰。该过程保留了每个像素点上梯度强度的极大值,过滤掉其他的值。**
**4.利用滞后技术来跟踪边界。若某一像素位置和强边界相连的弱边界认为是边界,其他的弱边界则被删除。**
## 边缘线检测
边缘检测算法主要是基于图像强度的一阶和二阶导数,但**导数通常对噪声很敏感,**因此需要采用**滤波器来过滤噪声**,并**调用图像增强或阈值化算法进行处理**,**最后再进行边缘检测**。
而所谓边缘检测,其实是用锐化算法算出边缘,然后通过一些细节处理捕捉边缘。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet