---
title: Nivelamento - Data Science
---

----------
<center> <font size="+3"><b> Prova Nivelamento</b></font></center>
<center> <font size="+2"><b> Data Science</b></font></center>
----------
## Crimes em São Francisco
Utilizando o dataset de [crimes em São Francisco](https://s3-sa-east-1.amazonaws.com/lcpi/54f2b05b-1fe0-44f9-ae75-5e84fb3da81f.csv), mostre 4 gráficos que indicam as localidades dos crimes (dispersão), reproduzindo a imagem a seguir. Faça com suplots, de tal forma que exista 1 gráfico para cada período do dia (manhã, tarde, noite e madrugada). Além disso, mostre para cada categoria do crime uma cor diferente. Realize os processamentos necessários para criação dos gráficos.
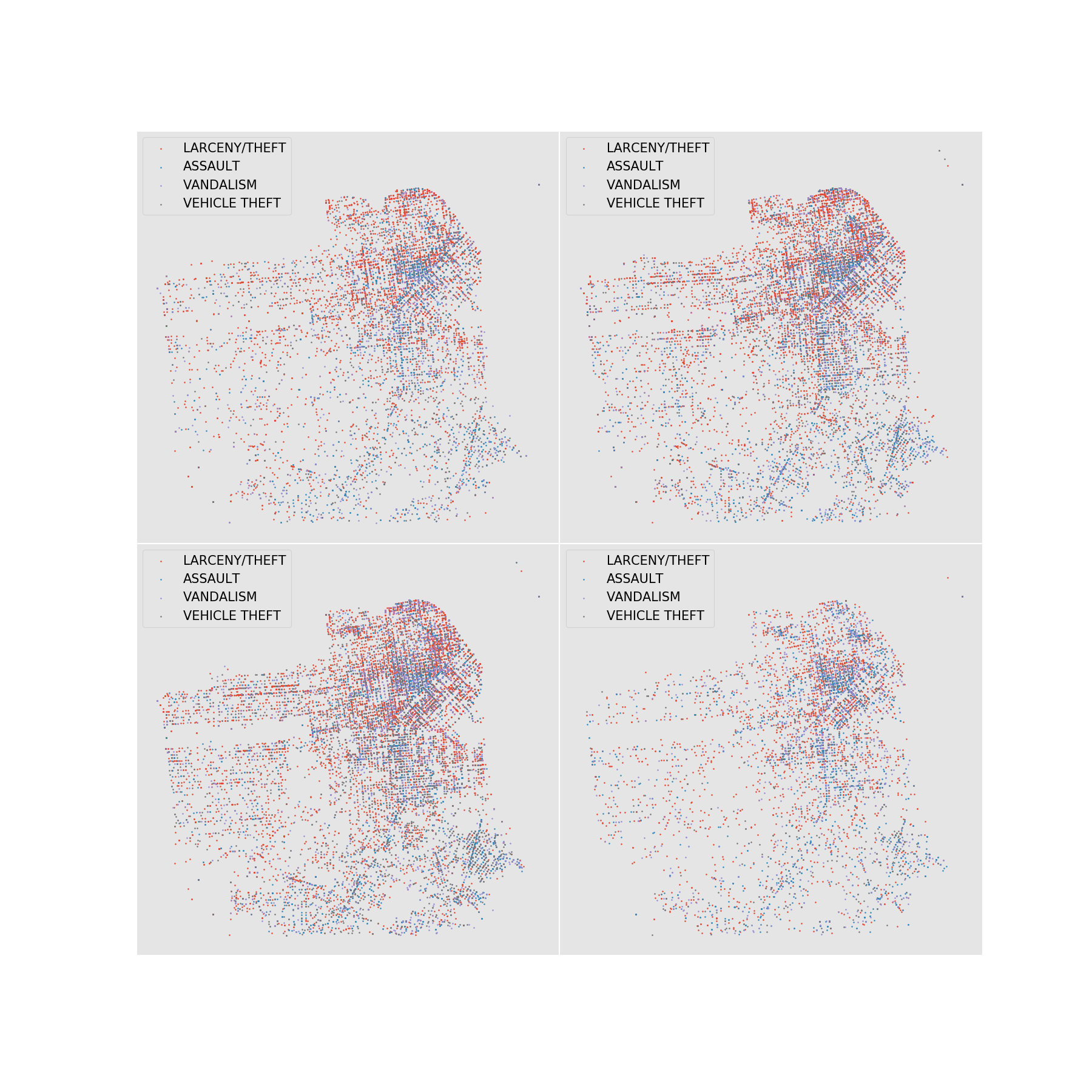
## Vencedor
Baseado nas tabelas, assinale a alternativa com o resultado da query descrita.
<center><img src="https://s3-sa-east-1.amazonaws.com/lcpi/7dbafb1c-863b-405f-b602-ca67d927cd17.png" width="50%"/></center>
```sql
SELECT id FROM runners
WHERE id NOT IN (SELECT winner_id FROM races)
```
a) 1 4 5
b) 2 3 2
c) Null
d) John Doe; Alice Jones; Bobby Louis.
e) 1 2 3
## Regressão Linear
Ajuste uma regressão linear, sem regularização e sem pré-processamento, usando o dataset disponível no [link](https://s3-sa-east-1.amazonaws.com/lcpi/3fbeab8b-1b87-4f2b-9c9d-c6d2b5f02564.csv), tomando as colunas EXPL_X como variáveis explicativas e a coluna RESP como variável resposta. Em seguida, assinale qual das alternativas a seguir denota as 3 variáveis que mais impactam o resultado do modelo.
a) EXPL_10, EXPL_9, EXPL_11
b) EXPL_15, EXPL_23, EXPL_7
c) EXPL_10, EXPL_7, EXPL_9
d) EXPL_12, EXPL_14, EXPL_13
e) EXPL_9, EXPL_11, EXPL_4
## PLN
Um dos processos de extração de features de um texto consiste em converter um documento, como o apresentado abaixo:
```
"Eu acho que ela acha que ele não acha, mas ele achou."
```
em um vetor, como:
```
(acha, acho, achou, ela, ele, eu, mas, não, que)
[2 1 1 1 2 1 1 1 2]
```
Qual é o nome desse processo?
a) POS
b) BOW
c) TF-IDF
d) Tokenization
e) Term Frequency
## Dados Categóricos
Não é recomendável aplicar algoritmos de clusterização em conjuntos de dados que possuem apenas variáveis categóricas por não existirem métricas confiáveis de similaridade entre esses tipos de atributos.
Verdadeiro ou falso? Justifique.
## Bagging
Bagging é uma técnica sequencial para melhorar o desempenho de algoritmos baseada no acerto de cada submodelo.
Verdadeiro ou falso? Justifique.
## Perceptron
Uma rede neural do tipo perceptron consegue classificar todo e qualquer conjunto de dados não-lineares.
Verdadeiro ou falso? Justifique.
## Dados Não Estruturados
Ao utilizar redes neurais para dados não estruturadados, como texto ou imagens, não precisamos nos preocupar com feature engineering ou feature pre-processing.
Verdadeiro ou falso? Justifique.
## Cores
O espaço de cores, em processamento de imagem, é um sistema de coordenadas cartesianas, composta por 3 componentes, como o RGB ou o HSV, que são descritas valor por valores que estão [0, 255].
Verdadeiro ou falso? Justifique.
## Árvores
Algoritmos de árvores só são utilizados para previsão, seja de variável categórica (classificação) ou contínua (regressão).
Verdadeiro ou falso? Justifique.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet