# Efficient Net
Efficient Net is a neural network structure released by Google for CNN's that have been desgined to optimize accuracy while saving in terms of computational cost.
Effcient Net can be used for classification task and object detection.
## Model Scalling
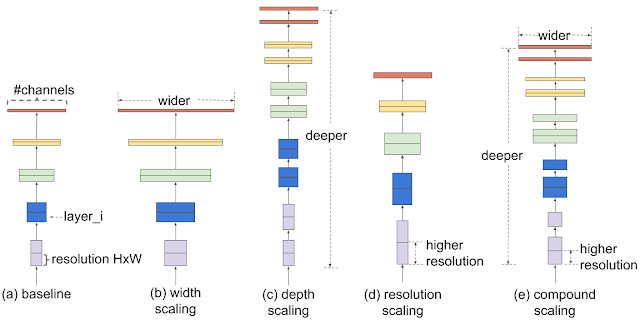
Model Scalling refers to modifying an architecture in common architects (such as resnet) in the following:
- Model Depth
- Convolution layers learn image features from the input image
- The more number of layers the more details extracted (Shallow network -less number of layers)
- For example resnet 50 is more accurate than resent 18 but in terms of speed its slower
- However there are a few problems with adding more layers
- Vanishing gradient problem occurs here
- Saturate after a certain depth
- Model Width
- CNN's learn from other features such as image channel which include RGB.
- Networks with wider channels per layer is considered wider than a network with fewer channels
- WideReset are not deep but are wide, its easier to train but still suffer from the following problems
- Still it saturates after a certain width
- Extremely wide and shallow network have difficulty capturing higher-level features
- Input image resolution
- CNN's take fixed image resolution as input
- An image with higher resolution tends to be more accurate due to more information
- A 256x256 image is less accurate than an 512x512 image
- However like the above saturates after a certain image resolution
The author of the paper made the following observations:
1) Scalling up any dimension of network width, depth or resolution improves accuract, but the accuracy gain diminishes for bigger models
2) In order to gain better accuracy and efficientcy, it's critical to balance all dimensions of network width, depth and resolution during ConvNet scaling
NOTE:
Whats not stated is that how to choose the depth, width and reolution in order to in accuracy and efficency. Searching in one dimension, for example depth itself is difficult add the other 2, it becomes increasingly difficult. However adding more increases FLOPs (Floating Point Operations).

## Compound Scaling
So as stated above in order to tune said dimensions it requires all three at once.
Such as the author said:
> high resolution images should require deeper networks, so that larger receptive fields can capture similar features that include more pixel in bigger images
In order to combat this the author proposed a scalling technique which uses a compound coefficient ɸ to uniformly scale a networks: width, depth and resolution:

ɸ is a user-specified coefficient that controls resources (e.g. Floating Point Operations (FLOPs)) available for model scaling.
α, β, and γ specify how to assign these resources to the nework depth, width and resolution
In a CNN, Conv layers are the most compuational expensive part of a network. FLOPs of a regular convolution op its almost propotional to d, w², r², i.e. doubling the depth will double the FLOPS while doubling width or resolution increases FLOPS almost by four times. Hence in order to make sure that the total FLOPS dont exceed 2^ϕ, the constraint applied is that (α * β² * γ²) ≈ 2
## How efficient net works

- Depthwise Convolution + Pointwise Convolution:
- Divides the orginal convolution into two stages to significantly reduce the cost of caluclation, with minimum loss of accuracy (Normally found in mobilenet, 2D Depthwise convolution)
- Inverse Res:
- Originally resnet blocks consist of a layer that squeezes the channels, then a layer that extends the channels (skip connection). In MBConv, however blocks consist of a layer that first extends a channels then compress them so that layer with fewer channels are skip connected.
- Linear bottleneck
- Use linear activation in the last layer in each block to prevent loss of information from RELU
The main building block for efficientnet is MBConv, n inverted bottleneck conv, originally known as MobileNetV2. Using shortcuts between bottlenecks by connecting a much smaller number of channels (compared to expansion layers), it was combined with an in-depth separable convolution, which reduced the calculation by almost k² compared to traditional layers. Where k denotes the kernel size, it specifies the height and width of the 2-dimensional convolution window.

### EfficienetNet Family

EfficientNet has whole familty of pretrained weights starting from B0 to B7 each number represents a networks size, and the processing power double with each increment
EfficientNet B0 is the first and hast on accuracy on par with other networks while being ridiculously fast to run and train.
Some sites suggest use the bigger size efficient net to train data to get a better accuracy.
### Recommendations
When using the EfficientNet snippets you should consider the following things:
Input block: use image augmentation.
Last Dense block: change the number of nodes to match the number of classes you have.
Target block: set the loss function to Categorical Crossentropy.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet