# Python Dictionaries and Frequency Tables
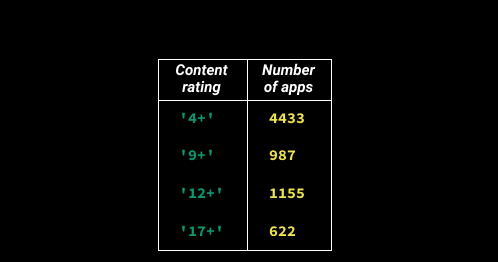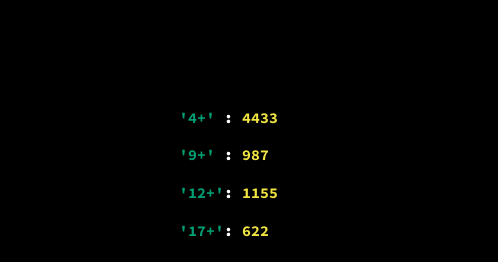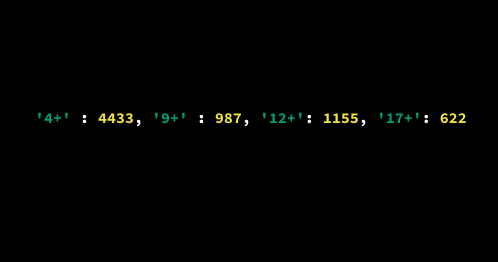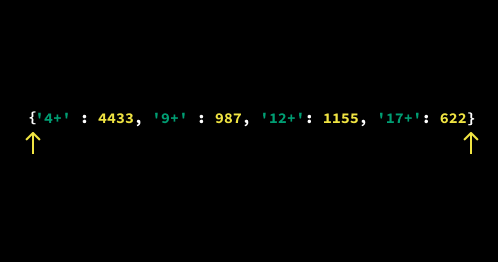
Alternatively, we can create a dictionary and populate it with values by following these steps:
1. We create an empty dictionary.
2. We add values one by one to that empty dictionary.
Adding a value to a dictionary follows the pattern dictionary_name[index] = value. To add a value 4433 with an index '4+' to a dictionary named content_ratings, we need to use the code content_ratings['4+'] = 4433.

When we populate a dictionary, we also need to make sure each key in that dictionary is unique.
If we use an identical key for two or more different values, Python keeps only the last key-value pair in the dictionary and removes the others
— this means that we'll lose data. We illustrate this in the diagram below, where we highlighted the identical keys with a distinct color:

An odd "gotcha" is when we mix integers with Booleans as dictionary keys. The hash() command converts the Boolean True to 1, and the Boolean False to 0. This means the Booleans True and False will conflict with the integers 0 and 1. The dictionary keys won't be unique anymore, and Python will only keep the last key-value pair in cases like that.

Once we've created a dictionary, we can check whether a certain value exists in the dictionary as a key. We can check, for instance, whether the value '12+' exists as a key in the dictionary {'4+': 4433, '9+': 987, '12+': 1155, '17+': 622}. To do that, we use the in operator.


Checking whether 4433 or 987 exists in content_ratings also returns False because the search is done only over the dictionary's keys (4433 and 987 exist as dictionary values in content_ratings).

Once we've created and populated a dictionary, we can update (change) the dictionary values. To update a dictionary value, we need to reference it by its corresponding dictionary key and then perform the updating operation we want. In the code example below, we:

To get a better understanding of how this works, we'll print the content_rating dictionary inside the for loop to see how it changes with every iteration:

You might wonder why we initialized (created) each dictionary key with a dictionary value of 1 instead of 0. When we encounter a content rating, we need to count it, no matter if it already exists or not as a dictionary key. When a rating that is not yet in the dictionary comes in, we need to both initialize it and count it. We need to initialize it with a value of 1 to mark the fact that this rating has already occurred once. If we initialized the dictionary key with a value of 0, we'd succeed in doing the initializing part, but fail to do the counting part.
To get a better understanding of what we did above, we'll print the content_rating dictionary inside the for loop to see how it changes with every iteration:

* test
```python=
opened_file = open('AppleStore.csv')
from csv import reader
read_file = reader(opened_file)
apps_data = list(read_file)
content_ratings = {}
for row in apps_data[1:]:
c_rating = row[10]
if c_rating in content_ratings:
content_ratings[c_rating] += 1
else:
content_ratings[c_rating] = 1
print(content_ratings)
```
The number of times a unique value occurs is also called frequency. For this reason, tables like the one below are called frequency tables.
```python=
opened_file = open('AppleStore.csv')
from csv import reader
read_file = reader(opened_file)
apps_data = list(read_file)
genre_counting = {}
for row in apps_data[1:]:
genre = row[11]
if genre in genre_counting:
genre_counting[genre] += 1
else:
genre_counting[genre] = 1
print (genre_counting)
```
When we transform frequencies to proportions, we can create a new dictionary instead of overwriting the values in the initial dictionary. To do that, we can create a new empty dictionary and populate it within the loop:

To find out the minimum and the maximum values of a column, we can use the min() and the max() commands. These two commands will find out the minimum and the maximum values for any list of integers or floats.

test
```python=
opened_file = open('AppleStore.csv')
from csv import reader
read_file = reader(opened_file)
apps_data = list(read_file)
rating_count_tot = []
for row in apps_data[1:]:
rating_count_tot.append(int(row[5]))
ratings_max = max(rating_count_tot)
ratings_min = min(rating_count_tot)
user_ratings_freq = {'0 - 10000': 0, '10000 - 100000': 0, '100000 - 500000': 0,
'500000 - 1000000': 0, '1000000+': 0}
for row in apps_data[1:]:
user_ratings = int(row[5])
if user_ratings <= 10000:
user_ratings_freq['0 - 10000'] += 1
elif 10000 < user_ratings <= 100000:
user_ratings_freq['10000 - 100000'] += 1
elif 100000 < user_ratings <= 500000:
user_ratings_freq['100000 - 500000'] += 1
elif 500000 < user_ratings <= 1000000:
user_ratings_freq['500000 - 1000000'] += 1
elif 10000 < user_ratings > 1000000:
user_ratings_freq['1000000+'] += 1
print(user_ratings_freq)
```
###### tags: `python`
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet