# Novel AI 部署与开发文档
本文旨在描述如何从头部署一个社区版 Novel AI 原生的前后端(即 NAIFU),并进行后续定制开发。请按需从目录跳转到对应章节。
## 部署前后端
> **参考:[Google Colab 文档](https://colab.research.google.com/drive/1_Ma71L6uGbtt6UQyA3FjqW2lcZ5Bjck-)**
本方案实测可在任何 Ubuntu 版云计算机(华为云ECS、阿里云ECS)迅速安装完成 NAIFU,非常好用。
### 软硬件要求
- 系统:Linux。理论上支持 Windows,但需要手动执行安装脚本。本文先不写了。
- 显卡:16GB 显存及以上。因为渲染图片会占用 9G 显存,所以理论上 8G 显存的显卡(如 3070)就不太行。
### 安装方法
```bash=
#!/bin/bash
sudo apt-get update -y
sudo apt-get upgrade -y
# install python
sudo apt-get install python3 python-is-python3 python3-virtualenv
# install naifu
sudo apt install -y -qq aria2 python3 python3-pip
aria2c --summary-interval=5 -x 3 --allow-overwrite=true -Z https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/naifu.tar
tar xf naifu.tar && rm naifu.tar
cd naifu
bash ./setup.sh
sed -i 's/$PYTHON -m uvicorn --host 0.0.0.0 --port=6969 main:app & bore local 6969 --to bore.pub/$PYTHON -m uvicorn --host 0.0.0.0 --port=6969 main:app/g' run.sh
# install caddy
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt-get update -y
sudo apt install -y caddy
# add systemd service
cat << EOF | sudo tee << EOF > /etc/systemd/system/naifu.service
[Unit]
Description=Naifu Web Service
[Service]
WorkingDirectory=/root/naifu
ExecStart=/root/naifu/run.sh
Restart=always
RestartSec=10
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=autodeploy
[Install]
WantedBy=multi-user.target
EOF
```
建议直接跑这个脚本。它轮流做了几件事:
1. 在当前目录下,下载解压 naifu 项目(约9gb)。并自动安装创建 python 环境和安装依赖。
2. 安装 caddy 以进行反向代理,如果不需要 Web 服务器可删掉 12~17 行的代码。
3. 创建一个 systemd service 来持续 + 自动重启 naifu 服务。
如果不需要,可以删掉相关部分。
### 启动 naifu
直接启动
```bash
$ bash run.sh
```
等待提示完成,然后访问 http://127.0.0.1:6969/ 应该能看到页面并正常使用,说明部署完成。
### 持久化运行
配置一下 Caddy, 修改 `/ect/caddy/Caddyfile` 文件为:
```
<your-domain> {
reverse_proxy 127.0.0.1:6969
}
```
然后,重启 caddy 并持续化运行 naifu。
```bash
sudo systemctl enable --now naifu
# 等上面那行启动完成,建议2分钟后再执行下面
sudo systemctl restart caddy
```
可以用 `systemctl status naifu` 查看 naifu 的状态。
## 部署 DeepDanbooru
### 安装
```bash
cd ~
git clone https://github.com/KichangKim/DeepDanbooru.git
mkdir DeepDanbooru/model
cd DeepDanbooru/model
wget https://github.com/KichangKim/DeepDanbooru/releases/download/v3-20211112-sgd-e28/deepdanbooru-v3-20211112-sgd-e28.zip
apt install unzip -y
unzip deepdanbooru-v3-20211112-sgd-e28.zip
rm deepdanbooru-v3-20211112-sgd-e28.zip
```
### 修改文件
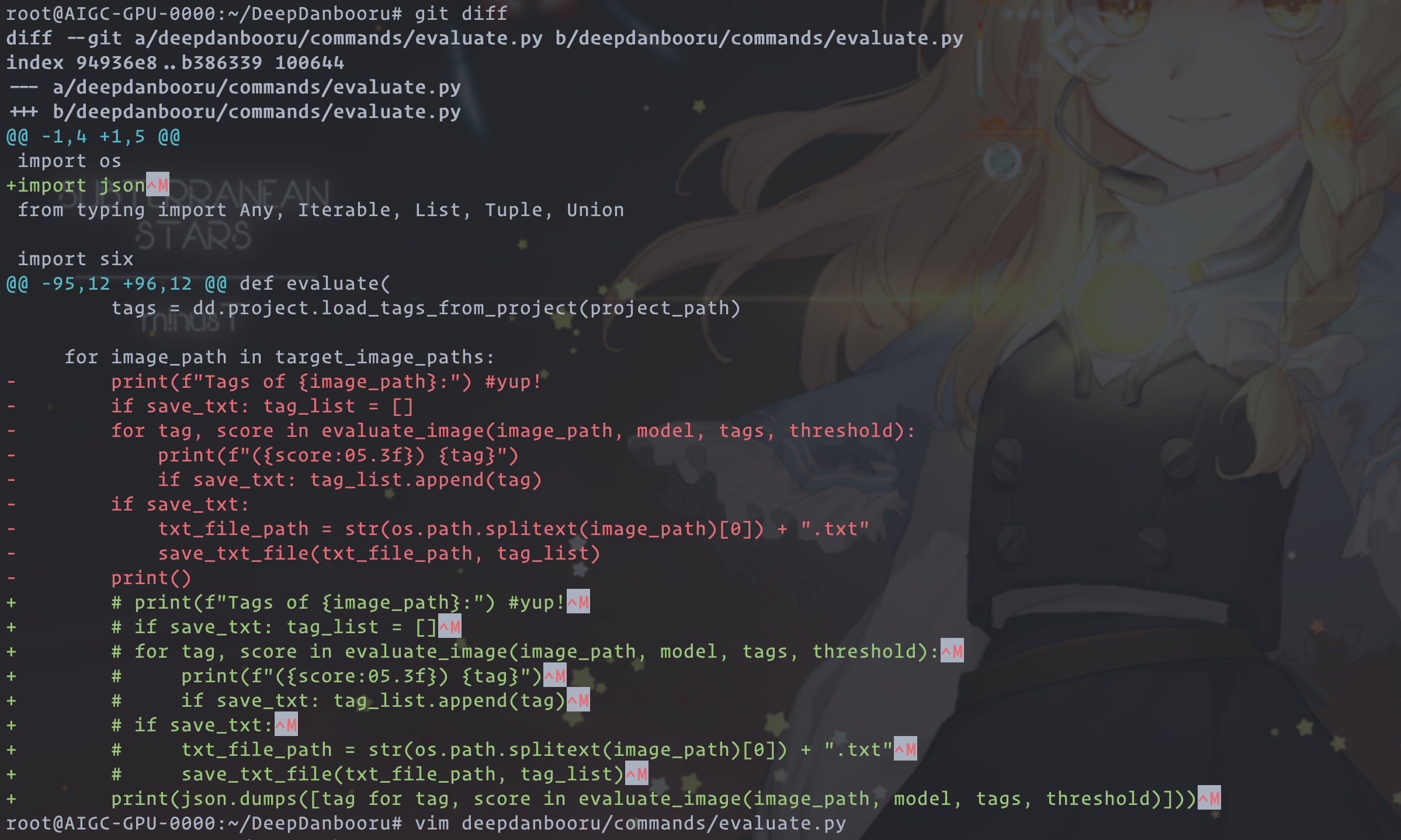
`deepdanbooru/commands/evaluate.py` 文件需要注释掉最下面的一个 for 循环的一些代码。改为:
```python=98
for image_path in target_image_paths:
# print(f"Tags of {image_path}:") #yup!
# if save_txt: tag_list = []
# for tag, score in evaluate_image(image_path, model, tags, threshold):
# print(f"({score:05.3f}) {tag}")
# if save_txt: tag_list.append(tag)
# if save_txt:
# txt_file_path = str(os.path.splitext(image_path)[0]) + ".txt"
# save_txt_file(txt_file_path, tag_list)
print(json.dumps([tag for tag, score in evaluate_image(image_path, model, tags, threshold)]))
```
***然后,还需要在开头加上 `import json`***
可以对照一下下图:
最后安装:
```bash!
ubuntu@ip-172-31-22-171:~/DeepDanbooru$ pip install .
```
## 部署 Deppdanbooru-backend
部署我自己写的 [deepdanbooru-backend](https://git.starblazer.cn/gululu/deepdanbooru-backend),步骤:
1. 装 node 依赖
2. 配置 `.env` 文件如下,按需更改文件路径:
```bash
PORT=3002
PROJECT_PATH=/root/deepdanbooru-backend
DEEPDANBOORU_PROJECT_PATH=/root/DeepDanbooru/model
```
3. 运行
## 对外映射 API
- 反向代理 **`/generate` 到 `NAIFU`** (默认 `127.0.0.1:6969`)
- 反向代理 **`/tag` 到 `deepdanbooru-backend`** (默认 `127.0.0.1:3002`,如上 `.env` 所示)
## NAIFU 二次开发(对部署不重要)
如果要自己实现一个前端或者聊天平台机器人,建议直接调用这个版本的后端接口。该版本后端接口为 REST 接口,和请求标准的后端服务一样就行。
### 例子
👇 下面是一个 TypeScript 的例子:
```typescript=
import axios from 'axios';
async function text2image(prompt: string): Promise<string> {
const { data: response } = axios.post(
'<your-server-domain>/generate',
{
prompt: `masterpiece, best quality, ${prompt}`,
width: 512,
height: 768,
scale: 12,
sampler: 'ddim',
steps: 40,
seed: Math.floor(Math.random() * 2 ** 32),
n_samples: 2,
ucPreset: 3,
uc:
'nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped,' +
' worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry',
},
{
headers: {
'Content-Type': 'application/json',
},
},
);
const base64 = response.output?.[0] || '';
return 'data:image/png;base64,' + base64;
}
```
请替换上面代码的 `your-server-domain` 为你的服务器地址。
这个函数如果正常执行,会返回一张基于 `prompt` 的图片地址。地址以 base64 编码并加上了 `data:image/png;` 的 URL 前缀,可以直接被 HTML 渲染。
比如说:
```javascript=
// make an API request
const url = await text2image('a cat');
// convert this base64 url to blob to open it in your webbrowser
const blob = await (await fetch(url)).blob();
// log the url
console.log(window.URL.createObjectURL(blob));
// and open the url in a new tab
window.open(window.URL.createObjectURL(blob), '__blank');
```
### 接口分析
*服从度* 等用词,见[**术语解释文档**](https://bot.novelai.dev/usage.html#%E9%AB%98%E7%BA%A7%E5%8A%9F%E8%83%BD)。
```javascript
{
prompt: 关键词,
width: 图片宽度,
height: 图片高度,
scale: 服从度,
sampler: 采样器,
steps: 步骤,
n_samples: 生成图片数量,
seed: 可不传,种子,建议随机生成,
image: 可不传,基于这张图片来生成一个图片(图片生成模版),格式为图片的 base64 字符串,
ucPreset: NovelAI 默认提供过滤图片的规则列表,按顺序比如传0是默认,传3是第4个,在0的基础上多 ban 了 nsfw,
uc: ban掉的词的列表,用逗号分隔,俗称反咒,
}
```
像上面我的例子那样,拼一个这样的 JSON object 用 POST 请求发到你的后端的 `/generate` 接口。你会得到
```json=
{
"output": [
"图片1(格式:base64 文本)",
]
}
```
如果还有图片2,那就是 `response.output[1]` 以此类推。
另外关于支持中文关键词,就在请求接口之前机翻关键词(可网上查询如何对接翻译 API)。效果很好的。