---
tags: linux2022
---
# 2022q1 Homework6 (ktcp & khttpd)
contributed by < [`qwe661234`](https://github.com/qwe661234) >
> [作業要求](https://hackmd.io/@sysprog/linux2022-ktcp#K08-ktcp)
> [GitHub(kecho)](https://github.com/qwe661234/kecho)
> [GitHub(khttpd)](https://github.com/qwe661234/khttpd)
::: spoiler 實驗環境
```shell
$ gcc --version
gcc (Ubuntu 9.4.0-1ubuntu1~20.04) 9.4.0
$ lscpu
架構: x86_64
CPU 作業模式: 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
每核心執行緒數: 2
每通訊端核心數: 6
Socket(s): 1
NUMA 節點: 1
供應商識別號: GenuineIntel
CPU 家族: 6
型號: 158
Model name: Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz
製程: 10
CPU MHz: 2200.000
CPU max MHz: 4100.0000
CPU min MHz: 800.0000
BogoMIPS: 4399.99
虛擬: VT-x
L1d 快取: 192 KiB
L1i 快取: 192 KiB
L2 快取: 1.5 MiB
L3 快取: 9 MiB
NUMA node0 CPU(s): 0-11
```
:::
## CMWQ (Concurrency Managed Workqueue) 優勢和用法
### 舊有 workqueue
舊有的 workqueue 有兩種,single-thread 和 per-CPU thread。
* single-thread: kernel 會建立一個 kernel thread 用於執行 workqueue 中的任務,並且該 kernel thread 不會綁定到某個 CPU 上。
* per-CPU thread: kernel 會針對每個 CPU 上的 workqueue 建立一個kernel thread,每個 kthread 會綁定到一個CPU上。
### 舊有 workqueue 的缺點
1. kernel thread 數量過多導致原本用來儲存 PID 的 32k 空間不足
因為舊有的 workqueue 會綁定 kernel thread,如果使用者頻繁建立 workqueue,kernel thread 也會跟著建立,造成 kernel thread 數量過多的問題。
2. concurrency 程度不佳
舊有的 workqueue 會綁定 kernel thread,假如使用 per-CPU workqueue,當任務被加到屬於某一個 CPU 的 workqueue 時,該任務只能由綁定該 CPU 的 kernel thread 來執行。假設綁定 CPU0 的 kernel thread 正在執行的任務 block 住了,接在 CPU0 的 woekqueue 中的任務只能等待被 block 住的任務執行完才能被執行,即使其他 CPU 上的 kernel thread 是 idle 的。
3. dead lock
假設任務 A 和任務 B 被加到同一個 CPU 的 workqueue 上,任務 A 先被 kernel thread 執行了,但任務 A 的執行必須依賴任務 B 的結果,可是任務 B 必須等待任務 A 執行完才能執行,dead lock 因此而產生。
4. 缺乏彈性
使用者只能選擇建立一個 kernel thread 或是在每個 CPU 都建立一個 kernel thread,缺乏彈性。
### CMWQ

CMWQ 將 workqueue 和 kernel thread 拆開,使 kernel thread 不再由 workqueue 綁定,進而提出 thread pool 概念,並且這些 thread pool 是由所有 workqueue 共享。
* workqueue: 有兩種,一種是 default workqueue 由系統建立,另一種是由使用者自己建立的 user created workqueue。
* thread pool: 除了每個 CPU 都會有一個 thread pool,還有沒有綁定 CPU 的 unbounded thread pool。
1. 綁定 CPU 的 thread pool:
這種類型的 thread pool 又分為 normal thread pool 和 high priority thread pool,分別用來管理不在意優先權的 kernel thread 和高優先權的 kernel thread,而這兩種 kernel thread 分別用來處理不在意優先權的和高優先權的任務。此類型的 thread pool 數量是固定的,根據系統中的 CPU 數量,假設系統有 n 個 CPU 在運行,就會創建 2n 個 thread pool。
2. unbounded thread pool:
可以運行在任意 CPU 上。這種 thread pool 是動態建立的,和 thread pool 的屬性有關,包括該 thread pool 所建立的 worker thread 的優先權(nice value),以及可以運行的 CPU 列表等。如果系統中已經有了相同屬性的 thread pool,那麼不需要建立新的 thread pool,否則建立新的 thread pool。
### CMWQ 優點
1. 維持與舊有 workqueue 的相容性。
2. 使用者只需要知道 API 如何使用, 不需要知道實作細節, CMWQ 會自動調整 level of concurrency 和 worker pool。
3. 解決 kernel thread 數量過多問題
CMWQ 的策略是當 thread pool 中處於運行狀態的 kernel thread 為0,且有需要處理的任務時,thread pool 就會建立新的 kernel thread 當kernel thread 處於 idle 時,不會立刻銷毀,而是等待一段時間,如果此時有建立新的 kernel thread 的需求,那麼直接 wakeup 這個 idle 的 kernel thread 來處理任務。一段時間過去仍然沒有任務要處理,就銷毀這個 kernel thread。
4. 提升 concurrency 程度
因為 CMWQ 任務沒有綁定 CPU,因此某個 CPU 上的 kernel thread 正在執行的任務 block 住了,其他任務可以交由其他 CPU 上正在 idle 的 kernel thread 來執行,以此解決發生舊有 workqueue 中 concurrency 程度不佳以及 deadlock 的問題。
#### reference: [currency Managed Workqueue(CMWQ)概述](https://cloud.tencent.com/developer/article/1517995)
### CMWQ 用法
* `alloc_workqueue`: 建立 workqueue
第二個參數 flag 可以設定 workqueue feature, e.g. WQ_UNBOUND, 代表不綁定 cpu
* `destroy_workqueue`: 移除 workqueue
* `INIT_WORK`: 將 function 初始化成 `struct work_struct`
* `flush_work`: 等待 workqueue 上的最後一項任務執行完畢
* `queue_work`: 將任務加入到 workqueue 中進行排程
## 核心文件 [Concurrency Managed Workqueue (cmwq)](https://www.kernel.org/doc/html/latest/core-api/workqueue.html) 提到 "The original create_`*`workqueue() functions are deprecated and scheduled for removal",請參閱 Linux 核心的 git log,揣摩 Linux 核心開發者的考量
參考 commit [workqueue: s/__create_workqueue()/alloc_workqueue()/, and add system …](https://github.com/torvalds/linux/commit/d320c03830b17af64e4547075003b1eeb274bc6c), 內文提到
> *Now that workqueue is more featureful, there should be a public
workqueue creation function which takes paramters to control them.
Rename __create_workqueue() to alloc_workqueue() and make 0
max_active mean WQ_DFL_ACTIVE. In the long run, all
create_workqueue_*() will be converted over to alloc_workqueue().
關於作者寫道的第一句 "Now that workqueue is more featureful, there should be a public workqueue creation function which takes paramters to control them.", 我們可以參考 commit [workqueue: merge feature parameters into flags](https://github.com/torvalds/linux/commit/97e37d7b9e65), 推測作者考量到以後 workqueue 的 feature 會被擴充, 如果每增加一個 feature 就要加入一個 parameter, 需要更動到大量的程式碼, 因此作者將 parameter 改成 flag 的方式, 用特定的 bit 去控制 feature, 不過這邊看不出為何要更改 function name。
接著參考 [OscarShiang 的開發紀錄](https://hackmd.io/@oscarshiang/linux_kecho#%E6%94%B9%E4%BB%A5-alloc_workqueue-%E5%AF%A6%E4%BD%9C-workqueue-%E7%9A%84%E5%8E%9F%E5%9B%A0), 作者認為這個改動最主要的原因是為了簡化新增 workqueue 特徵的流程, 其中提到的一點是上述所說的作者將 parameter 改為 flag, 另外作者也提供 commit [workqueue: introduce create_rt_workqueue](https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/include/linux/workqueue.h?id=0d557dc97f4bb501f086a03d0f00b99a7855d794) 來舉例, 在這個 commit 中, 為了增加 real-time feature, 也就是加入了一個新的 parameter, 改動到了許多處的程式碼。
不過我們可以發現其實 commit [workqueue: merge feature parameters into flags](https://github.com/torvalds/linux/commit/97e37d7b9e65) 其實在更改 function name 的 commit 前提交, 因此其實就算不更改 function name 也可以, 推測另一個更改 function name 的原因是提醒使用舊版的使用者這項改動。
## 解釋 `user-echo-server` 運作原理,特別是 [epoll](http://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫的使用
### 建立連線
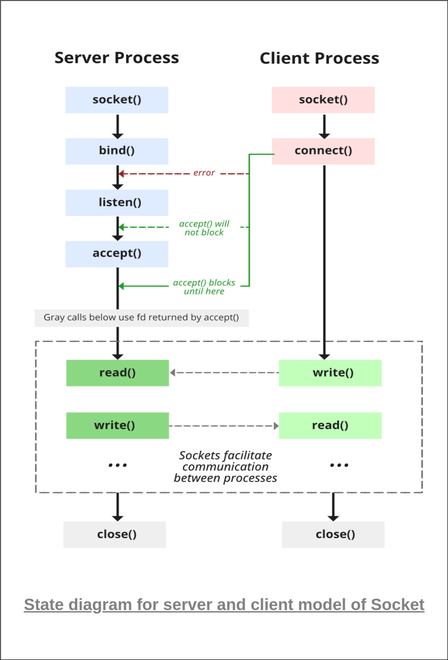
[圖片來源](https://www.geeksforgeeks.org/socket-programming-cc/)
`user-echo-server` 首先利用 `socket()` 建立 scoket, 將 socket 的 I/O event 行為設為 `nonblock`, 接著利用 `bind()` 綁定 socket 以及 localhost 與指定的 port, 接著 call `listen()` 來監聽 request
```c
struct sockaddr_in addr = {
.sin_family = PF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr.s_addr = htonl(INADDR_ANY),
};
socklen_t socklen = sizeof(addr);
int listener;
if ((listener = socket(PF_INET, SOCK_STREAM, 0)) < 0)
...
if (setnonblock(listener) == -1)
...
if (bind(listener, (struct sockaddr *) &addr, sizeof(addr)) < 0)
...
if (listen(listener, 128) < 0)
...
```
### epoll
epoll 為 I/O multiplexing model, 其實作利用兩個 queue, 一個是 interest queue, queue 上接的是被 epoll 監視且正在等待 I/O event ready 的 thread, 另一是 ready queue, 上面接的是 I/O event 已經 ready, 可以準備做 I/O 的 thread。
實作方面, 首先利用 `epoll_create` 建立 epoll instance, 接著利用 `epoll_ctl`, 這邊利用到 `EPOLL_CTL_ADD`, 這個 operator 是用來將剛剛建立的 socket listener 接在 epoll 的 interest queue 上, 讓 epoll 來 monitor 其 I/O event。
### struct epoll_event
* epoll_data: 保存該事件的 file discriptor
* events: the type of event
```c
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* epoll event */
epoll_data_t data; /* User data variable */
};
```
```c
int epoll_fd;
if ((epoll_fd = epoll_create(EPOLL_SIZE)) < 0)
...
static struct epoll_event ev = {.events = EPOLLIN | EPOLLET};
ev.data.fd = listener;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listener, &ev) < 0)
...
```
將 socket listener 交給 epoll monitor 後, 以 `epoll_wait` 等待 interest queue 上的 thread 的 I/O event 是否 ready, `epoll_wait` 的第二個參數是 event buffer, 用來存放回傳事件的 data, 而第四個參數 timeout 為等待時間, 這邊設為 -1, 其行為會是 ready queue 為空時一直 block 住, 當 ready queue 不為空時立刻回傳。
epoll_events_count 代表有多少 I/O event 已經 ready, 接著依照 epoll_events_count 的數量來處理 event, 這邊會收到的 event 分為兩種, 一種是 socket listener 接收到 client 端的 `connect` 請求, server 端會利用 `accept()`, 取出在 socket listener queue 上的第一個 `connect` 請求, 並為其建立新的 socket client。
建立新的 socket client 後將 socket client 的 I/O event 行為設為 `nonblock` 並利用 `epoll_ctl` 將 socket client 加入 epoll 的 interest queue, 交給 epoll monitor, 除了加到 epoll 外, 也會將 client 加到 client_list 中, 等到 client 端發送給 socket client 的 request, 例如: `send()` 被 epoll 加到 ready queue 時, 也就是第二種 event, 會將 event 交由 function `handle_message_from_client` 處理。
`if (events[i].data.fd == listener)` 為 `true` 表示第一種 event, 反之為第二種。
```c
while (1) {
struct sockaddr_in client_addr;
int epoll_events_count;
if ((epoll_events_count = epoll_wait(epoll_fd, events, EPOLL_SIZE,
EPOLL_RUN_TIMEOUT)) < 0)
...
for (int i = 0; i < epoll_events_count; i++) {
if (events[i].data.fd == listener) {
int client;
while (
(client = accept(listener, (struct sockaddr *) &client_addr,
&socklen)) > 0) {
...
setnonblock(client);
ev.data.fd = client;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client, &ev) < 0)
...
push_back_client(&list, client,
inet_ntoa(client_addr.sin_addr));
...
}
...
} else {
if (handle_message_from_client(events[i].data.fd, &list) < 0)
...
}
}
}
```
### client_list
client_list 主要是用來儲存 server 新建立的 socket client 資訊, 透過 `size_list` 可計算出剩餘多少由 server 建立的 client socket。
#### handle_message_from_client
利用 `recv()` 接收 client 端送出的 data, 並利用 `send()` 發送 request 給 client 端, 如果 `recv()` 的回傳為 0, 表示 client 端的 socket 已經關閉, 因此可以將 server 端新建立的 client socket 關閉, 並將其從 client_list 中 delete 掉。
## 是否理解 bench 原理,能否比較 kecho 和 user-echo-server 表現?佐以製圖
bench 是一個用來評估 server 回應速度的測量工具, 其運作原理是 create 1000(變數`MAX_THREAD`) 個 thread, 而每個 thread 的任務是連線到 echo_server, 並傳送一段 dummy message 給 echo server, 接著接收 echo_server 回傳的 message, 送出以及接收的字串必須是一樣的, 每個 thread 都會記錄送出訊息後到成功接收訊息這段時間。
bench 會重複做 10 次(變數`BENCH_COUNT`) 上述操作, 接著將 10 次的結果相加取平, 單位是微秒。
為了確保成功建立這 1000 個 thread 後, 才對 echo_server 進行連線以及收發訊息, `bench.c` 利用 condition variable `worker_wait`, 讓先建立好的 thread 等待, 等到第 1000 個 thread 建立成功, 再發通知喚醒等待的 thread。
```c
#define MAX_THREAD 1000
pthread_mutex_lock(&worker_lock);
if (++n_retry == MAX_THREAD) {
pthread_cond_broadcast(&worker_wait);
} else {
while (n_retry < MAX_THREAD) {
if (pthread_cond_wait(&worker_wait, &worker_lock)) {
puts("pthread_cond_wait failed");
exit(-1);
}
}
}
pthread_mutex_unlock(&worker_lock);
```
## 比較 kecho 和 user-echo-server 表現?佐以製圖
kecho 是架設在 kernel space 的 server, 而 user-echo-server 則架設在 user space
### kecho

### user-echo-server

由結果圖可看出 kecho 的效能比 user-echo-server 好非常多, 參考論文 [Analysis of Delivery of Web Contents for Kernel-mode and User-mode Web Servers](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.206.3959&rep=rep1&type=pdf) 的結論, 由於在 kernel space 的 server 可以避免 process scheduling 以及資料的複製, 引此在 kernel space 的 kecho 效能會比在 user space 的 user-echo-server 好。
## 若使用者層級的程式頻繁傳遞過長的字串給 kecho 核心模組,會發生什麼事?
當傳遞超過 kecho buffer_size 的字串時, 傳送訊息的行為會被拆分, 假如 buffer size 是 20, 而傳送的字串長度是 31, 那會被拆成長度為 20 與長度為 13 傳送(呼叫 send 兩次)。
當頻繁傳遞過長的字串給 kecho 核心模組時, 觀察發現會有遺漏訊息的現象, 如果有 1000 個 thread, printk 印出相同字串會是 2000 個, 因為有接收訊息以及發送訊息, 但當字串過長拆分成兩次發送時, 前半段訊息只印出 1834 個而後半段是 1835 個, 而不是正確的 2000 個, 因此當頻繁傳遞過長的字串給 kecho 核心模組時, 會有遺漏訊息的情況。
而傳遞超過 user-echo-server buffer_size 給 user-echo-server, 字串也會被拆成兩份並且呼叫 send 兩次, 但並不會有訊息遺漏的問題發生。
### TCP backlog
TCP 連線建立是透過三次握手(three-way handshake) 來建立練線, 當 client 呼叫 `connect()` 發出 SYN 號給 server 時, server 收到請求會變成 `SYN_RECV` 的狀態, 接著發送 SYN 以及 ACK(確認收到 client 端的 SYN 信號), 接著 client 發送 ACK, 通知 server 收到 server 端的 SYN 訊號, 完成後 client 和 server 都會變為 `ESTABLISH` 的狀態, 等待 server 呼叫 `accpet()`。
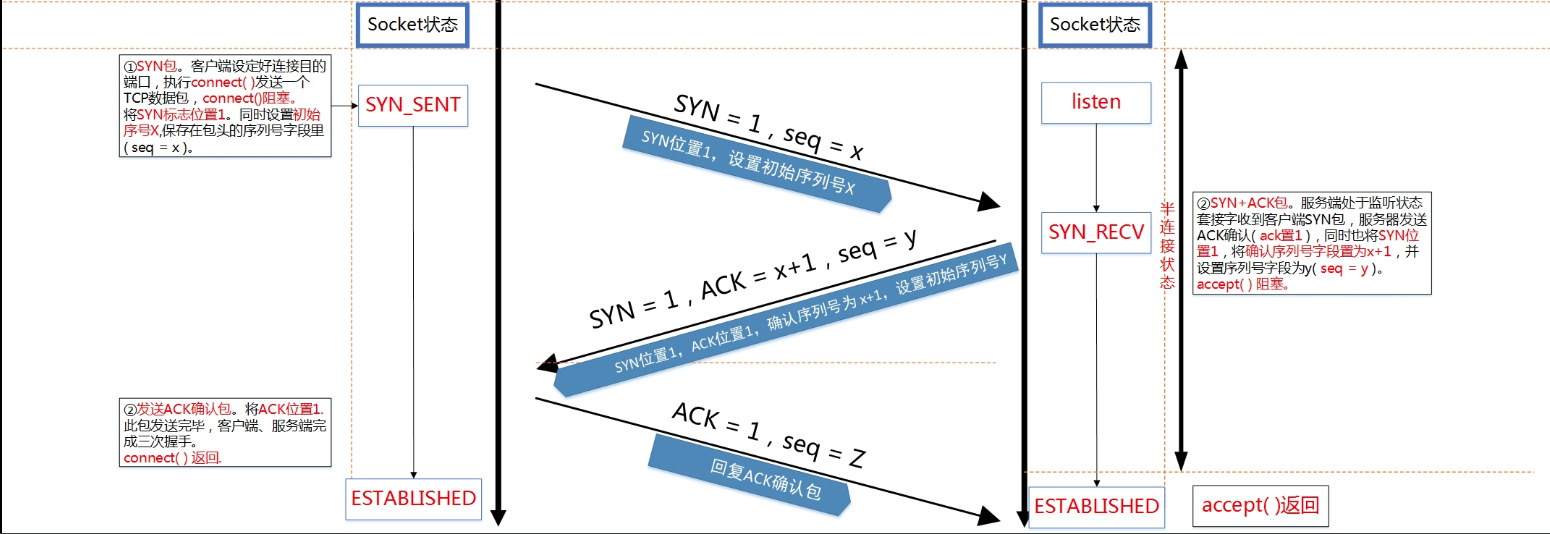
[圖片來源](https://blog.csdn.net/yangbodong22011/article/details/60399728)
而 backlog 參數是用來指定呈現 `ESTABLISHED` 狀態等待被 `accept()` 的 socket 有幾個, 而其他的 socket 則會那在 `SYN_RECV` 的狀態, 等待有 `ESTABLISHED` 狀態的 socket 被 accept 後, 才會有新的在 `SYN_RECV` 狀態的 socket 變成 `ESTABLISHED` 狀態。
backlog 的數量是用到系統限制的, 檔案 `/proc/sys/net/core/somaxconn` 中的值為 backlog 最大值, 如果 backlog 設定超過最大值則被設定為最大值。
我們可以透過指令 `# ss -ln | head -n1 ;ss -ln | grep {port}` 來確認 backlog, Recv-Q 表示已經佔用的 backlog, 也就是呈現 `ESTABLISHED` 狀態等待被 `accept()` 的 socket 有幾個, Send-Q 則表示 backlog 的大小。
```
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp LISTEN 5 4 0.0.0.0:8081 0.0.0.0:*
```
這邊我們設定 backlog 為 4, 但 Recv-Q 的個數卻是 5 個, 原因我們可以看到 [linux/include/net/sock.h](https://github.com/torvalds/linux/blob/169e77764adc041b1dacba84ea90516a895d43b2/include/net/sock.h)
```c
static inline bool sk_acceptq_is_full(const struct sock *sk)
{
return READ_ONCE(sk->sk_ack_backlog) > READ_ONCE(sk->sk_max_ack_backlog);
}
```
因為這邊判斷 accept queue 是否滿了是用大於, 所以我們設定最大值為 4, 當 accept queue 中的 socket 為 5 時才代表滿了。
## 參照 [CS:APP 第 11 章](https://hackmd.io/s/ByPlLNaTG),給定的 kHTTPd 和書中的 web 伺服器有哪些流程是一致?又有什麼是你認為 kHTTPd 可改進的部分?
kHTTPd 在建立伺服器時會先呼叫 `sock_create()` 來產生 socket, 接著呼叫 `kernel_bind()` 將 socket 綁定在我們給定的 IP 位置以及 port,最後呼叫 `kernel_listen()` 來監聽 client 端的連線。
監聽連線的 socket 完成後會進到 function `http_server_daemon()` 中等待 client 端連線, 收到 client 端連線後, 呼叫 `kernel_accept()` 確認連線並建立新的 socket, 交由 kthread 去接收 client 端的 request 並發送對應的 response, 最後當錯誤發生或關閉 server 時, 會呼叫 `close_listen_socket()` 來關閉 socket, 這一係建立伺服器流程與書中一致。
### wget error
```
wget localhost:8081
```
利用 wget 向 khttpd server 發出請求, 雖然成功得到 index.html, 不過 kernel 卻印出 error message
```
[84131.206885] khttpd: requested_url = /
[84131.208045] khttpd: recv error: -104
```
參考 [linux error code](https://www.thegeekstuff.com/2010/10/linux-error-codes/), error number 104 是 ECONNRESET, 代表 Connection reset by peer。
參考 [【TCP】Connection reset by peer 原因分析定位](https://blog.csdn.net/simonchi/article/details/105807660) 發現這個 error 跟我們將連線設定為 Keep-Alive 模式有關, 當使用Keep-Alive 模式時,client 與 server 的連接持續, 持續時間與系統設定有關
#### Keep-alive
TCP Keep-alive 機制是當 client 與 server 在一段時間無資料互動後, server 會 傳送 keep-alive probe 封包去探測連線是否以斷開
* /proc/sys/net/ipv4/tcp_keepalive_time (最後一個封包發送到發送 keep-alive probe 封包的時間間隔)
* /proc/sys/net/ipv4/tcp_keepalive_probes (發送 keep-alive probe 封包次數)
* /proc/sys/net/ipv4/tcp_keepalive_intvl (兩次 keep-alive probe 封包的時間間隔)
參考 [wget manual](https://www.gnu.org/software/wget/manual/wget.html), 在指令後面加上 `--no-http-keep-alive` 來關閉 Keep-alive feature, 這樣就不會跳出 error。
```
wget localhost:8081 --no-http-keep-alive
```
## 引入 Concurrency Managed Workqueue (cmwq),改寫 kHTTPd,分析效能表現和提出改進方案
引入 cmwq 後, 以效能分析工具 htstress 進行效能分析, 可發現在以入 cmwq 後, 效能有顯著的提升, 不過會發生 socker errors。
### with cmwq
```
requests: 100000
good requests: 100000 [100%]
bad requests: 0 [0%]
socker errors: 864 [0%]
seconds: 1.063
requests/sec: 94102.856
```
### without cmwq
```
requests: 100000
good requests: 100000 [100%]
bad requests: 0 [0%]
socker errors: 0 [0%]
seconds: 4.882
requests/sec: 20483.396
```
:::warning
TODO: 排除錯誤
:::
## 自我檢查清單
- [ ] 參照 [Linux 核心模組掛載機制](https://hackmd.io/@sysprog/linux-kernel-module),解釋 `$ sudo insmod khttpd.ko port=1999` 這命令是如何讓 `port=1999` 傳遞到核心,作為核心模組初始化的參數呢?
> 過程中也會參照到 [你所不知道的 C 語言:連結器和執行檔資訊](https://hackmd.io/@sysprog/c-linker-loader)
- [ ] 參照 [CS:APP 第 11 章](https://hackmd.io/s/ByPlLNaTG),給定的 kHTTPd 和書中的 web 伺服器有哪些流程是一致?又有什麼是你認為 kHTTPd 可改進的部分?
- [ ] `htstress.c` 用到 [epoll](http://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫,其作用為何?這樣的 HTTP 效能分析工具原理為何?
- [x] 給定的 `kecho` 已使用 CMWQ,請陳述其優勢和用法
- [x] 核心文件 [Concurrency Managed Workqueue (cmwq)](https://www.kernel.org/doc/html/latest/core-api/workqueue.html) 提到 "The original create_`*`workqueue() functions are deprecated and scheduled for removal",請參閱 Linux 核心的 git log (不要用 Google 搜尋!),揣摩 Linux 核心開發者的考量
- [x] 解釋 `user-echo-server` 運作原理,特別是 [epoll](http://man7.org/linux/man-pages/man7/epoll.7.html) 系統呼叫的使用
- [x] 是否理解 `bench` 原理,能否比較 `kecho` 和 `user-echo-server` 表現?佐以製圖
- [ ] 解釋 `drop-tcp-socket` 核心模組運作原理。`TIME-WAIT` sockets 又是什麼?