---
title: Agenda
description:
duration: 60
card_type: cue_card
---
- **What is NLP?**
- **Overview of numerous applications of NLP in real-world scenarios**
- **Understanding of language from an NLP perspective and of why NLP is difficult**
- **Overview of heuristics, machine learning, and deep learning, then introduce a few commonly used algorithms in NLP.**
- **Introduction to use case**
- **Tokenization**
- **Regular expression**
- **Natural Language Toolkit (NLTK) package**
* **Preprocessing**:
> 1. Remove hyperlinks, hashtags etc.
> 2. Remove stopwords and punctuation
> 3. Stemming
* **Represent text in NLP**:
> 1. Sparse representation
> 2. Drawbacks of sparse representation
> 3. Frequency Dictionary
> 4. Extracting features from Frequency Dictionary
* **Training Logistic Regression**.
* **Training Logistic Regression with L1 Regularization**.
* **Performance on the test set**
---
title: NLP
description:
duration: 60
card_type: cue_card
---
### What is NLP?
We talk to these assistants not in a programming language, but in our **Natural Language — the language we all communicate in**.
#### So, how do computers make sense of it?
- Computers or these devices/machines can only process data in binary, i.e., 0s and 1s.
- While we can represent language data in binary, **how do we make machines understand the language?**
- This is where Natural Language Processing (NLP) comes in.
#### Definition:
**An area of computer science that deals with methods to analyze, model, and understand human language. Every intelligent application involving human language has some NLP behind it.**
---
title: NLP Applications
description:
duration: 60
card_type: cue_card
---
### Core application areas
- **Email platforms** --> Gmail, Outlook, etc.,
- use NLP extensively to provide a range of product features, such as spam classification, priority inbox, calendar event extraction, auto-complete, etc.
- **Voice-based assistants**, --> Apple Siri, Google Assistant, Microsoft Cortana, and Amazon Alexa
- rely on a range of NLP techniques to interact with the user, understand user commands, and respond accordingly.
- **Modern search engines** --> Google and Bing
- query understanding, query expansion, question answering, information retrieval, and ranking and grouping of the results, to name a few.
- **Machine translation services** --> Google Translate, Bing Microsoft Translator, and Amazon Translate
### Other industrial applications:
- Organizations across verticals analyze their **social media feeds** to build a better and deeper understanding of the voice of their customers.
- **E-commerce platforms like Amazon**: are **extracting relevant information** from product descriptions to understanding user reviews.

- Companies such as Arria are working to use NLP techniques to **automatically generate reports for various domains, from weather forecasting to financial services**.
- NLP forms the backbone of spelling and grammar-correction tools, such as **Grammarly and spell check in Microsoft Word and Google Docs**.
-
---
title: Quiz 1
description:
duration: 60
card_type: quiz_card
---
# Question
Which of the following is an example of NLP application ?
# Choices
- [x] Machine Translation
- [ ] Snapchat filter
- [ ] Excel Dashboard
- [ ] None
---
title: Quiz-1 Explanation
description:
duration: 40
card_type: cue_card
---
### Explanation
- Translation : This is the task of converting a piece of text from one language to another. Tools like Google Translate are common applications of this task.
---
title: NLP Perspective and why it is difficult ?
description:
duration: 600
card_type: cue_card
---
### To understand what complexity means, we need to understand - What does a Language consist of?
**Language is a structured system of communication that involves complex combinations of its constituent components, such as characters, words, sentences, etc.**
The systematic study of language is called **Linguistics**.
In order to study NLP, it is important to understand some concepts from linguistics about how language is structured.
Let's see how these components relate to some of the NLP tasks we have discussed today.
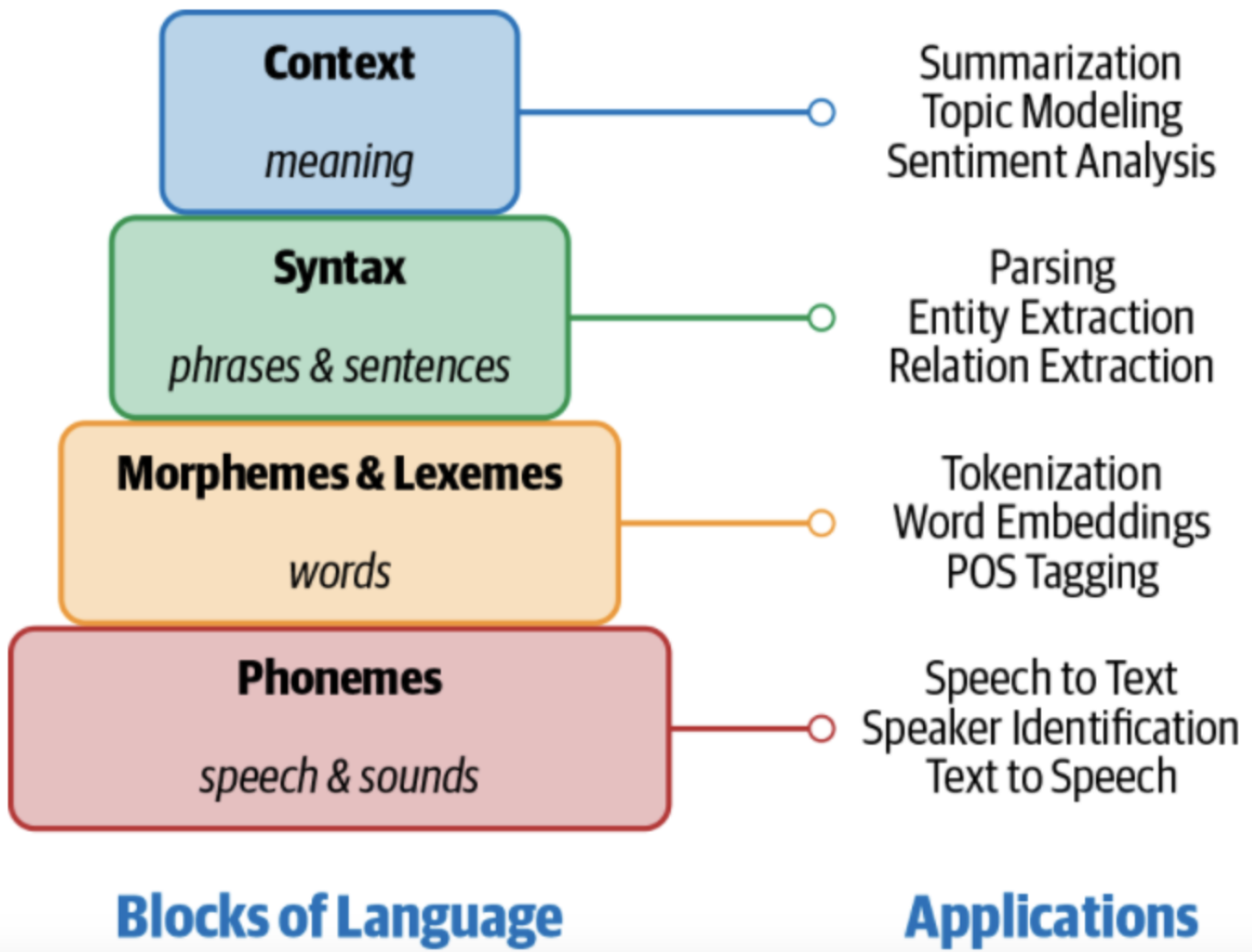
#### Four components of Language:
We can think of human language as composed of four major building blocks:
1. **Phonemes** - Phonemes are the smallest units of sound in a language. They may not have any meaning by themselves but can induce meanings when uttered in combination with other phonemes.
2. **Morphemes and Lexemes** - A **morpheme** is the smallest unit of language that has a meaning. It is formed by a combination of phonemes. Not all morphemes are words, but all prefixes and suffixes are morphemes. **Lexemes** are the structural variations of morphemes related to one another by meaning.,
3. **Syntax** - Syntax is a set of rules to construct grammatically correct sentences out of words and phrases in a language.
4. **Context** - Context is how various parts in a language come together to convey a particular meaning. Context includes long-term references, world knowledge, and common sense along with the literal meaning of words and phrases.
**NLP applications need knowledge of different levels of these building blocks, starting from the basic sounds of language (phonemes) to texts with some meaningful expressions (context).**
Let's see what each building block encompasses and which NLP applications would require that knowledge.
> ⚠️Some of the terms listed here that were not introduced earlier in this chapter (e.g., parsing, word embeddings, etc.) will be introduced later in these first three chapters.
#### Approaches to these problems
1. Heuristics-Based
2. Machine Learning
3. Deep Learning
---
title: Overview of heuristics, ML, and DL.
description:
duration: 300
card_type: cue_card
---
### Heuristics-Based NLP
Similar to other early AI systems, early attempts at designing NLP systems were based on building rules for the task at hand. This required that the developers had some expertise in the domain to formulate rules that could be incorporated into a program. Such systems also required resources like dictionaries and thesauruses, typically compiled and digitized over a period of time. An example of designing rules to solve an NLP problem using such resources is lexicon-based sentiment analysis. It uses counts of positive and negative words in the text to deduce the sentiment of the text.
### Machine Learning for NLP
Machine learning techniques are applied to textual data just as they’re used on other forms of data, such as images, speech, and structured data. Supervised machine learning techniques such as classification and regression methods are heavily used for various NLP tasks. As an example, an NLP classification task would be to classify news articles into a set of news topics like sports or politics. On the other hand, regression techniques, which give a numeric prediction, can be used to estimate the price of a stock based on processing the social media discussion about that stock. Similarly, unsupervised clustering algorithms can be used to club together text documents.
- Naive Bayes
- SVM
- Logistic Regression
- Hidden Markov Model
- Conditional Random Fields(CRFs)
### Deep Learning for NLP
We briefly touched on a couple of popular machine learning methods that are used heavily in various NLP tasks. In the last few years, we have seen a huge surge in using neural networks to deal with complex, unstructured data. Language is inherently complex and unstructured. Therefore, we need models with better representation and learning capability to understand and solve language tasks. Here are a few popular deep neural network architectures that have become the status quo in NLP.
- Recurrent Neural Network
- LSTM - Long Short Term Memory
- Convolutional Neural Network
- Transformers
- Autoencoders
---
title: Introduction to use case
description:
duration: 300
card_type: cue_card
---
### How are people reacting to the new COVID-19 strain?
`You are working as a Data Scientist for the Ministry of Health and Family Welfare`
**The government wants to learn the public sentiment on the new strain of COVID-19**
- When a new strain is detected, people might suddenly panic, so they might start hoarding essential supplies.
- The government wants to prepare well and warn people about the new strain.
#### How can we learn the public sentiment?
- Do surveys? - But that is too slow.
- Check what people are saying on Social Media.
#### Using Twitter for public sentiment
We can utilize Twitter feed to carry out the sentimental analysis.
> **Since most tweets are textual, we'll need to process this textual data to learn whether the general sentiment is positive or negative. - Aka : Sentiment Analysis**
**Note:** Sentiment Analysis is the process of categorizing opinions expressed in a text, primarily to determine whether the author's attitude towards a particular topic is Positive or Negative.
#### How will Sentiment Analysis help?
1. We can gauge the spread of the virus and the severity of it.
2. Govt. will be able educate people and avoid misinformation.
### 1.1 Understanding the Dataset
```python=
import os
import re
import random
import string # for string operations
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import plotly.express as px
# SetUp NLTK
!pip install --user -U nltk
import nltk
nltk.download('punkt')
```
```python=
!gdown 11LWo5nagSmC72hOJM9lm2l05sdQxt4rf
```
> Downloading...
From: https://drive.google.com/uc?id=11LWo5nagSmC72hOJM9lm2l05sdQxt4rf
To: /content/corona_tweets.csv
100% 1.00M/1.00M [00:00<00:00, 140MB/s]
```python=
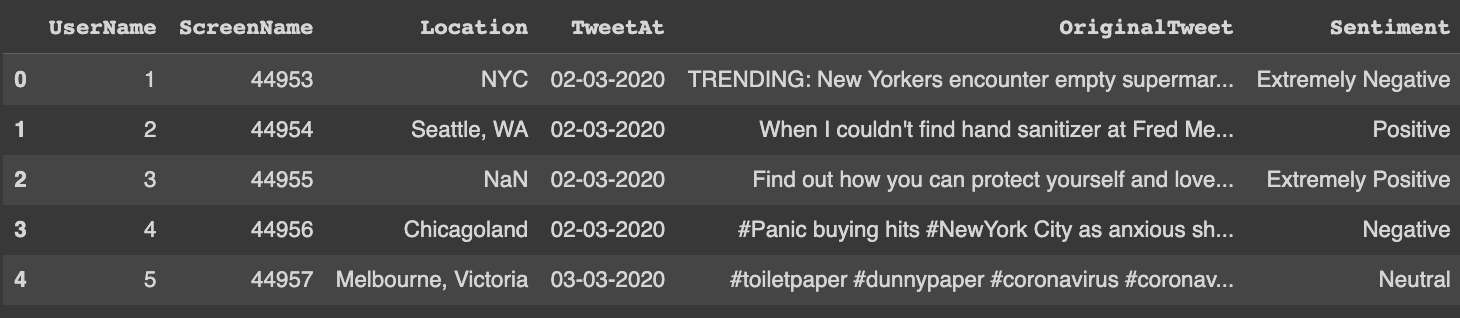
dataframe = pd.read_csv("./corona_tweets.csv")
dataframe.head()
```
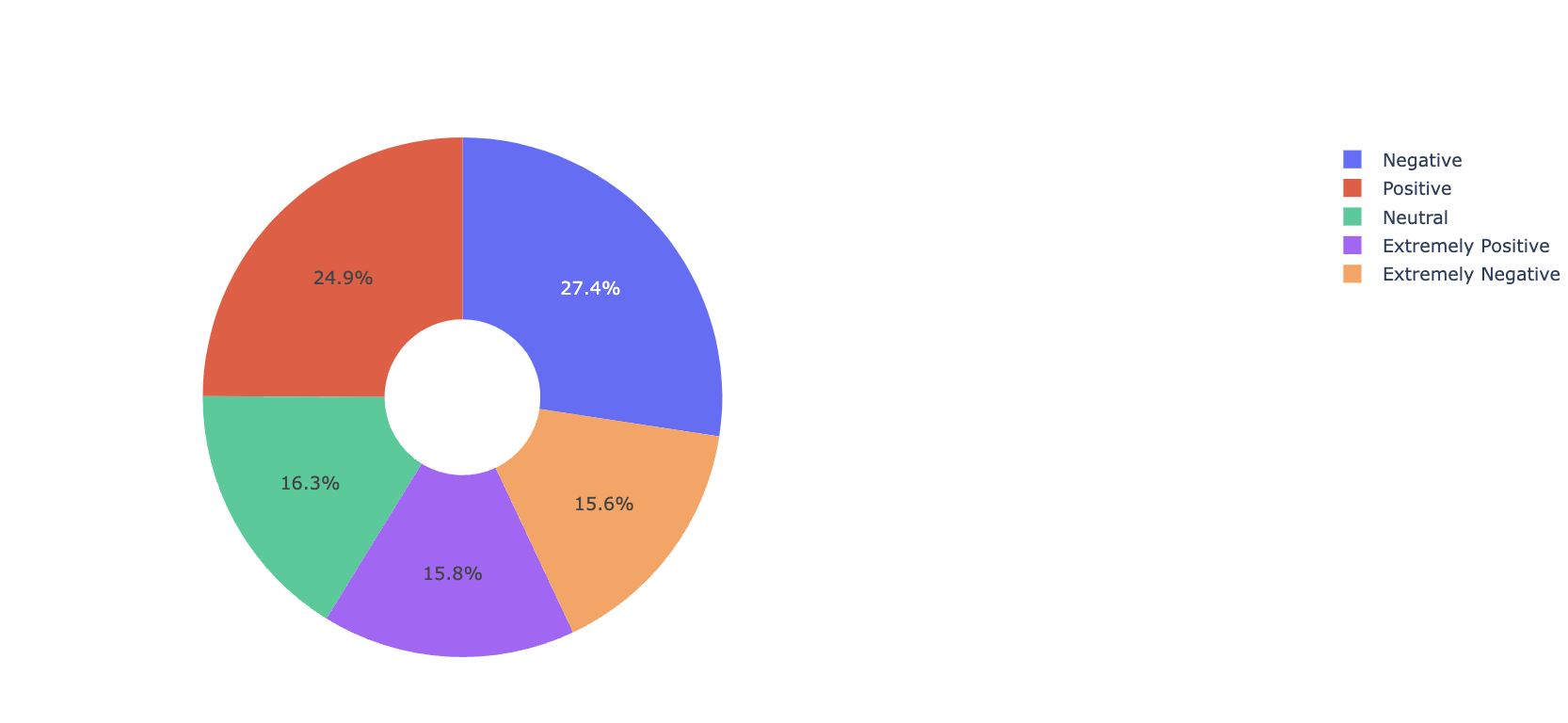
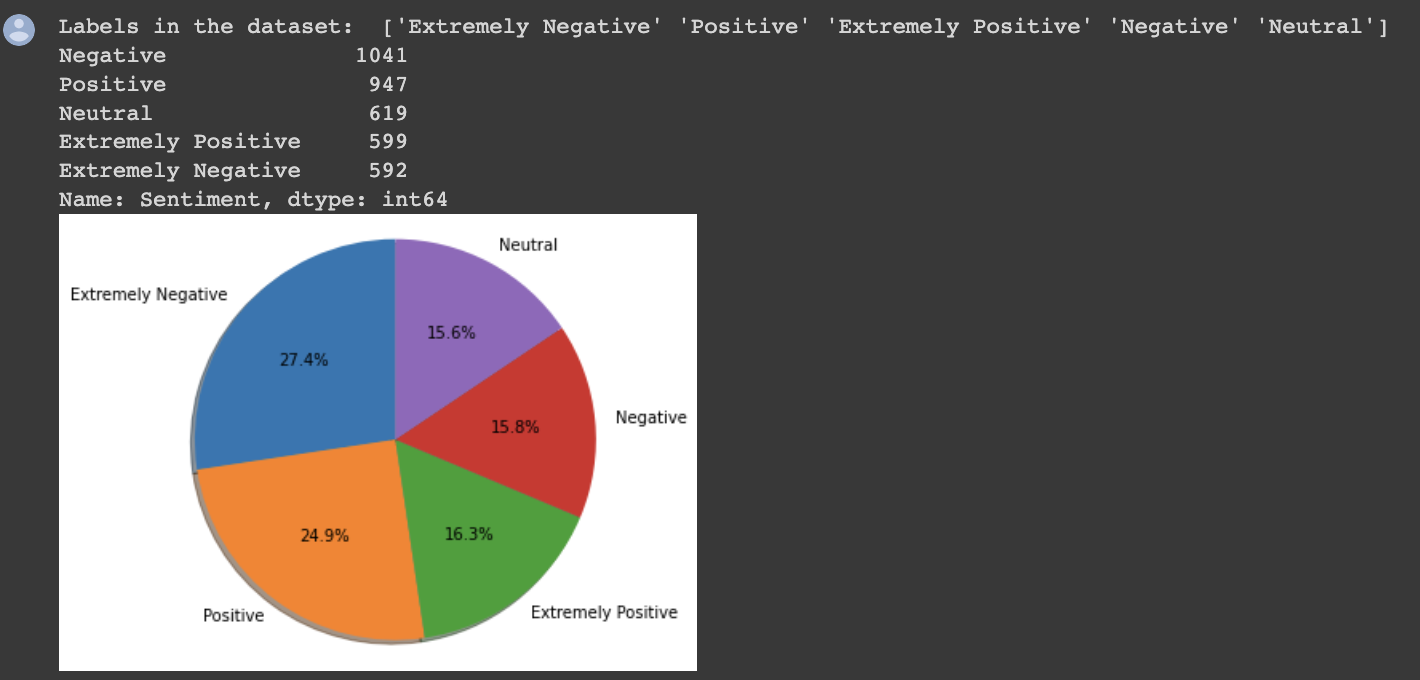
### Exploring the labels
```python=
fig = px.pie(dataframe, names='Sentiment',hole=0.3, title='Sentiment Pie Chart')
fig.show()
```
```python=
# Check tweets distribution
def pie_chart(dataframe):
# Converting pd object to list of string
label_types = dataframe.Sentiment.unique().astype(str)
# Count tweets for each label
label_counts = dataframe.Sentiment.value_counts()
print('Labels in the dataset: ', label_types)
print(label_counts)
# labels for the two classes
labels = label_types #'Positives', 'Negative'
# Sizes for each slide
sizes = [count for count in label_counts]
# Declare a figure with a custom size
fig = plt.figure(figsize=(5, 5))
# Declare pie chart, where the slices will be ordered and plotted counter-clockwise:
plt.pie(sizes, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
# Equal aspect ratio ensures that pie is drawn as a circle.
plt.axis('equal')
# Display the chart
plt.show()
pie_chart(dataframe)
```
```python=
dataframe[dataframe['Sentiment'] == 'Negative']['OriginalTweet'].shape
```
> (1041,)
### Splitting the dataset into training and testing
```python=
# Separating positive_tweets and negative_tweets
all_positive_tweets = list(dataframe[dataframe['Sentiment'] == 'Positive']['OriginalTweet'].astype(str)) # Making equal positive and negative tweet counts
all_negative_tweets = list(dataframe[dataframe['Sentiment'] == 'Negative']['OriginalTweet'].astype(str))[:947]
# Splitting training and testing set. 80/20 split
positive_train, positive_test = train_test_split(all_positive_tweets, test_size=0.2, random_state=42)
negative_train, negative_test = train_test_split(all_negative_tweets, test_size=0.2, random_state=42)
print("Size of training dataset: ",len(positive_train) + len(negative_train))
print("Size of testing dataset: ", len(positive_test) + len(negative_test))
# print positive in green
print('\033[92m' + '\npositive in green: ')
print('\033[92m' + all_positive_tweets[random.randint(0,947)])
print('\033[91m' + '\nnegative in red: ')
# print negative in red
print('\033[91m' + all_negative_tweets[random.randint(0,947)])
```

### 1.2 How can a machine understand a tweet?
* Yes by recognizing the words that constitute a string of characters before processing a natural language.
* Meaning of the text could be interpreted by analyzing the words.
> **This is where tokenization is essential to proceed with NLP (text data), which is used to break down the text into tokens (words).**
---
title: Tokenisation, Regex and NLTK
description:
duration: 900
card_type: cue_card
---
### What is tokenization?
* Word tokenization: split large text samples into words.
```python=
# Split on spaces
tweet = all_positive_tweets[12]
word = tweet.split() # space tokenizer
print('Using Split :',word)
```
> Using Split : ['Consumers', 'have', 'increased', 'their', 'online', 'shopping', 'due', 'to', 'coronavirus.', 'https://t.co/5mYfz3RAD0', '#retail']
**Note:** split() does not consider punctuation as a separate token.
### What is a regular expression and what makes it so important?
* A regular expression is a notation to represent standards in strings.
* Series of characters that define an abstract search pattern.
* It serves to search and extract information in texts.
Regex is used in Google analytics in URL matching in supporting search and replaced in most popular editors like Sublime, Notepad++, Google Docs, and Microsoft Word.
```
Example : Regular expression for an email address :
^([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
```
The above regular expression is used for checking if a given set of characters is an email address or not.
<details>
<summary>
<font size="4" color=""><b>How to write regular expression?</b></font>
</summary>
<p>
<ol>
<li>
Repeaters : *, + and { } symbols act as repeaters and tell the computer that the preceding character is to be used for more than just one time.
* The asterisk symbol ( * ): to match the preceding character (or set of characters) for 0 or more times (up to infinite).
* The Plus symbol ( + ): to repeat the preceding character (or set of characters) for at least one or more times(up to infinite).
* The curly braces {…}: to repeat the preceding character (or set of characters) as many times as the value inside this bracket.
</li>
<li>
Character Classes: matches any one of a set of characters. It is used to match the most basic element of a language like a letter, a digit, space, a symbol, etc.
* /s : matches any whitespace characters such as space and tab
* /S : matches any non-whitespace characters
* /d : matches any digit character
* /D : matches any non-digit characters
* /w : matches any word character (basically alpha-numeric)
* /W : matches any non-word character
* /b : matches any word boundary (this would include spaces, dashes, commas, semi-colons, etc)
</li>
<li>
Wildcard – ( . ): The dot symbol can take place of any other symbol.
</li>
<li>
Optional character – ( ? ): tells the computer that the preceding character may or may not be present in the string to be matched.
</li>
<li>
The caret ( ^ ) : tells the computer that the match must start at the beginning of the string or line.
</li>
<li>
The dollar ( $ ) tells the computer that the match must occur at the end of the string or before \n at the end of the line or string.
</li>
</ol>
</p>
</details>
Read More: [Link1](https://buildregex.com/), [Link2](https://regexr.com/), [regex-quickstart](http://www.rexegg.com/regex-quickstart.html), [How to write regular expression?](https://www.geeksforgeeks.org/write-regular-expressions/)
```python=
# Using 're' library to work with regular expression.
tokens = re.findall("[\w']+", tweet)
print('Using regexes :',tokens)
```
> Using regexes : ['Consumers', 'have', 'increased', 'their', 'online', 'shopping', 'due', 'to', 'coronavirus', 'https', 't', 'co', '5mYfz3RAD0', 'retail]
* The function **re.findall()** finds all the words that match the pattern passed and stores them in the list.
* The **“\w”** represents: “any word character,” which usually means alphanumeric (letters, numbers) and underscore (_).
* **‘+’** means any number of times.
* **[\w’]+** signals that the function should find all the alphanumeric characters until any other character is encountered.
#### Python already has modules for collecting, handling, and processing text data.
> **Using Natural Language Toolkit (NLTK) package.**
* NLTK contains a module called `tokenize`, which has the `word_tokenize()` method to split a sentence into tokens.
```python=
from nltk.tokenize import word_tokenize
words = word_tokenize(tweet)
print('Using NLTK :',words)
```
> Using NLTK : ['Consumers', 'have', 'increased', 'their', 'online', 'shopping', 'due', 'to', 'coronavirus', '.', 'https', ':', '//t.co/5mYfz3RAD0', '#', 'retail', '#', 'ecommerce', '#', 'study', '#', 'coronavirus', 'https', ':', '//t.co/Dz3H6zrWUT']
**Note:** `word_tokenize()` is considering punctuation as a token. Hence we need to remove the punctuations from the initial list.
### How to tokenize into a Sentence?
* A sentence usually ends with a full stop `.`, so we can use `.` as a separator to break the string:
```python=
# Splits at '.'
splits = tweet.split('. ')
print('Using Splits :',splits)
# Using Regular Expressions (RegEx)
sentence_splits = re.compile('[.!?] ').split(tweet)
print('Using regexes :',sentence_splits)
```
> Using Splits : ['Consumers have increased their online shopping due to coronavirus', 'https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT']
Using regexes : ['Consumers have increased their online shopping due to coronavirus', 'https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT']
**Note:** a drawback of using Python’s `split()` method is that we can use only one separator at a time.
* Using RegEx, we have an edge over the split() method as we can pass multiple separators simultaneously.
* We used the re.compile() function in the above code wherein we passed [.?!]. It means that sentences will split as soon as any of these characters are encountered.
<details>
<summary>
<font size="5" color=""><b>Python split() VS nltk sent_tokenize</b></font>
</summary>
<p>
**Cosider an example:**
```
eg_sentence = "Dr. A. P. J. Abdul Kalam was the Former President of India and a world-renowned Space Scientist."
Using split :
['Dr', 'A', 'P', 'J', 'Abdul Kalam was the Former President of India and a world-renowned Space Scientist']
Using NLTK sent_tokenize:
['Dr. A. P. J. Abdul Kalam was the Former President of India and a world-renowned Space Scientist.']
```
<ol>
<li>
Here, the python split() function made the mistake of tokenizing the name.
</li>
<li>
To properly tokenize such function we require a sequence of RegEx functions.
</li>
<li>
NLTK has pre-defined functions to handle such conditions.
</li>
</ol>
</p>
</details>
```python=
# Using NLTK
from nltk.tokenize import sent_tokenize
sentence_splits = sent_tokenize(tweet)
print('Using NLTK :',sentence_splits)
```
> Using NLTK : ['Consumers have increased their online shopping due to coronavirus.', 'https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT']
**Note:** A lot of unnecessary words like hashtags, hyperlinks are also tokenized.
---
title: Preprocessing
description:
duration: 600
card_type: cue_card
---
## 1.3 Can we reduce dataset size?
#### What are the unwanted textual data?
* Remove hashtags and hyperlinks before tokenization.
* Remove stopwords and punctuations.
```python=
import nltk # Python library for NLP
from nltk.corpus import twitter_samples # sample Twitter dataset from NLTK
from nltk.corpus import stopwords # module for stop words that come with NLTK
from nltk.stem import PorterStemmer # module for stemming
from nltk.stem import WordNetLemmatizer # module for Lemmatization
from nltk.tokenize import TweetTokenizer
nltk.download('wordnet')
nltk.download('omw-1.4')
```
```pyhton=
# Our selected sample. Complex enough to exemplify each step
tweet = all_positive_tweets[12]
tweet
```
> 'Consumers have increased their online shopping due to coronavirus. https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT'
```python=
# Removing hyperlinks and hashtags
print('\033[92m' + tweet)
print('\033[94m')
# remove old style retweet text "RT"
tweet2 = re.sub(r'^RT[\s]+', '', tweet)
# remove hyperlinks
tweet2 = re.sub(r'https?://[^\s\n\r]+', '', tweet2)
# remove hashtags
# only removing the hash # sign from the word
tweet2 = re.sub(r'#', '', tweet2)
print(tweet2)
```
> Consumers have increased their online shopping due to coronavirus. https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT
>Consumers have increased their online shopping due to coronavirus. retail ecommerce study coronavirus
```python=
# Tokenizing
print()
print('\033[92m' + tweet2)
print('\033[94m')
# instantiate tokenizer class
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True,
reduce_len=True)
# tokenize tweets
tweet_tokens = tokenizer.tokenize(tweet2)
print()
print('Tokenized string:')
print(tweet_tokens)
```
>Consumers have increased their online shopping due to coronavirus. retail ecommerce study coronavirus
>Tokenized string:
['consumers', 'have', 'increased', 'their', 'online', 'shopping', 'due', 'to', 'coronavirus', '.', 'retail', 'ecommerce', 'study', 'coronavirus']
```python=
# Import the english stop words list from NLTK
nltk.download("stopwords")
stopwords_english = stopwords.words('english')
print('Stop words\n')
print(stopwords_english)
print('\nPunctuation\n')
print(string.punctuation)
```
> Stop words
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
>Punctuation
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
```python=
print()
print('\033[92m')
print(tweet_tokens)
print('\033[94m')
tweets_clean = []
for word in tweet_tokens: # Go through every word in your tokens list
if (word not in stopwords_english and # remove stopwords
word not in string.punctuation): # remove punctuation
tweets_clean.append(word)
print('removed stop words and punctuation:')
print(tweets_clean)
```
>['consumers', 'have', 'increased', 'their', 'online', 'shopping', 'due', 'to', 'coronavirus', '.', 'retail', 'ecommerce', 'study', 'coronavirus']
>removed stop words and punctuation:
['consumers', 'increased', 'online', 'shopping', 'due', 'coronavirus', 'retail', 'ecommerce', 'study', 'coronavirus']
---
title: Stemming & Lemmatization
description:
duration: 600
card_type: cue_card
---
### Are there different words that mean the same?
Stemming & Lemmatization are different word normalization techniques, that helps us convert the inflection words into the base forms.
For example -
> *have, having, had --> have*
> *playing, plays, played --> play*
> *good, better, best --> good*
##### Why is it important to convert inflection words to the base forms?
* There are scenarios, where different forms of a word conveys related meaning.
* Example "toy" and "toys" have identical meaning. In a search engine, the objective between a search for "toy" and a search for "toys" is probably the same.
* Different ways of writing the same word causes various problems in understanding queries.
* Converting inflection words to the base words is a common practice in NLP domain.
```python=
print()
print('\033[92m')
print(tweets_clean)
print('\033[94m')
# Instantiate stemming class
stemmer = PorterStemmer()
# Create an empty list to store the stems
tweets_stem = []
for word in tweets_clean:
stem_word = stemmer.stem(word) # stemming word
tweets_stem.append(stem_word) # append to the list
print('stemmed words:')
print(tweets_stem)
```
> ['consumers', 'increased', 'online', 'shopping', 'due', 'coronavirus', 'retail', 'ecommerce', 'study', 'coronavirus']
> stemmed words:
['consum', 'increas', 'onlin', 'shop', 'due', 'coronaviru', 'retail', 'ecommerc', 'studi', 'coronaviru']
### REVISE

#### Lemmatization
* Lemmatization reduces the words properly such that the reduced word also belongs to the language.
* The output of lemmatization is the root lemma and not the root stem (as in stemming).
* Example: 'runs', 'running', 'ran' are all formed from the same word 'run' hence their lemma is 'run'.
#### Stemming
* Stemming does not generate actual words where as lemmatization does generate actual words.
* Stemming is a rule based technique and is applied step by step on words without any additional context, it is much faster as compared to lemmatization which needs the entire text or POS tag to generate the root lemma correctly.
* If you need speed then stemming can be preffered else lemmatization is better in most cases.
#### Putting everything together
1. Remove hyperlinks, hashtags etc.
2. Tokenizing
3. Remove stopwords and punctuation
4. Stemming
```python=
def process_tweet(tweet):
lemmatizer = WordNetLemmatizer()
stopwords_english = stopwords.words('english')
# remove stock market tickers like $GE
tweet = re.sub(r'\$\w*', '', tweet)
# remove old style retweet text "RT"
tweet = re.sub(r'^RT[\s]+', '', tweet)
# remove hyperlinks
tweet = re.sub(r'https?://[^\s\n\r]+', '', tweet)
# remove hashtags
# only removing the hash # sign from the word
tweet = re.sub(r'#', '', tweet)
# tokenize tweets
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True,
reduce_len=True)
tweet_tokens = tokenizer.tokenize(tweet)
tweets_clean = []
for word in tweet_tokens:
if (word not in stopwords_english and # remove stopwords
word not in string.punctuation): # remove punctuation
# tweets_clean.append(word)
lemma_word = lemmatizer.lemmatize(word) # stemming word
tweets_clean.append(lemma_word)
return tweets_clean
```
```python=
# choose the same tweet
tweet = all_positive_tweets[12]
print()
print('\033[92m')
print(tweet)
print('\033[94m')
# call the imported function
tweets_stem = process_tweet(tweet); # Preprocess a given tweet
print('preprocessed tweet:')
print(tweets_stem) # Print the result
```
>Consumers have increased their online shopping due to coronavirus. https://t.co/5mYfz3RAD0 #retail #ecommerce #study #coronavirus https://t.co/Dz3H6zrWUT
>preprocessed tweet:
['consumer', 'increased', 'online', 'shopping', 'due', 'coronavirus', 'retail', 'ecommerce', 'study', 'coronavirus']
---
title: Representation of text in NLP
description:
duration: 900
card_type: cue_card
---
#### 1.4 How to use preprocessed tweet to train a model?
In order to do so, build a vocabulary that will be used to encode any text or tweet as an array of numbers.
#### How do you represent text in NLP?
Sparse representation (Representing a text as a vector)
1. Picture a list of tweets. Then your vocabulary, V, would be the list of unique words from your list of tweets.
2. To get that list, you will have to go through all the words from the tweets and save every new word that appears in the search.
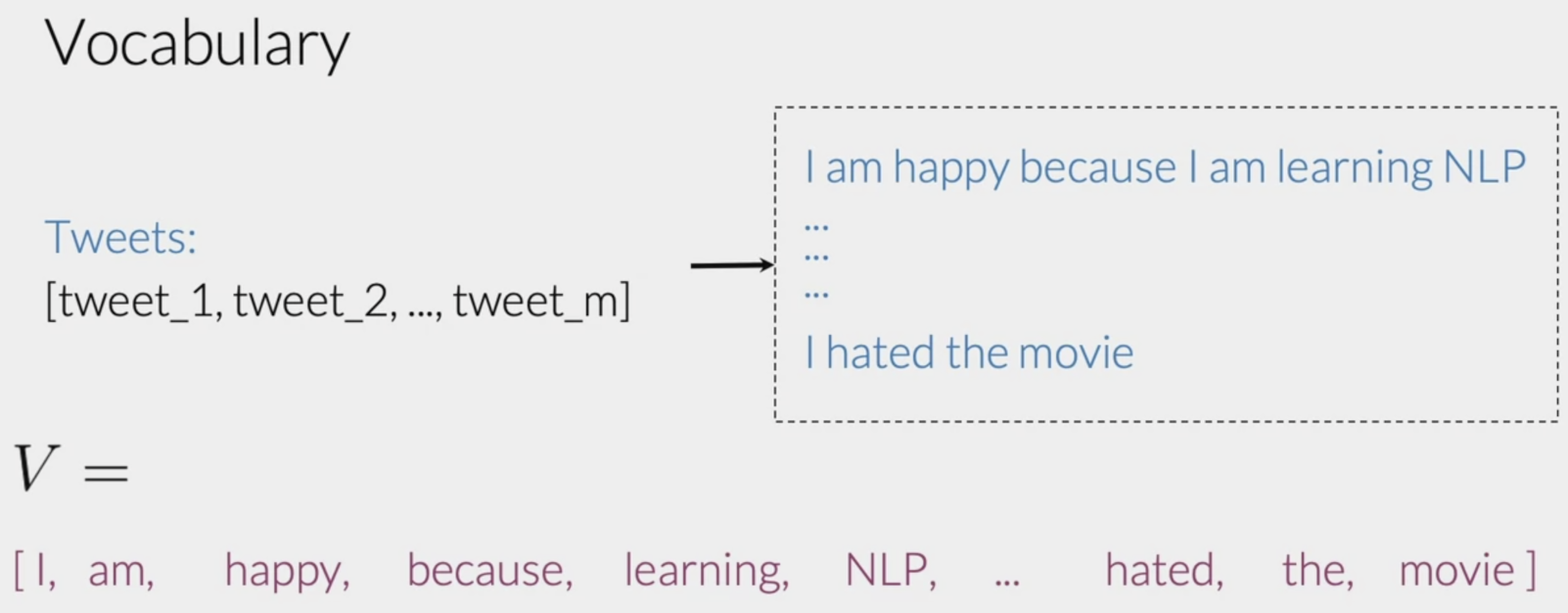

Drawbacks of sparse representation
1. A lot of features are equal to 0.
2. Logistic regression model would have to learn `n + 1` parameters, where `n = size of the vocabulary`
3. For large vocabulary sizes, this would be problematic.
What problems will it cause?
* Excessive amount of time to train a model and more time to make predictions.
#### Instructors Note (ask this questions) :
- Can we use BOW + PCA to overcome sparsity of input vectors ?
- If we are using BOW lets assume there will be 2000 data points and 10000 dimensional data. How can we make BOW + logistic regression effective ?
#### 1.5 How can we reduce the dimension?
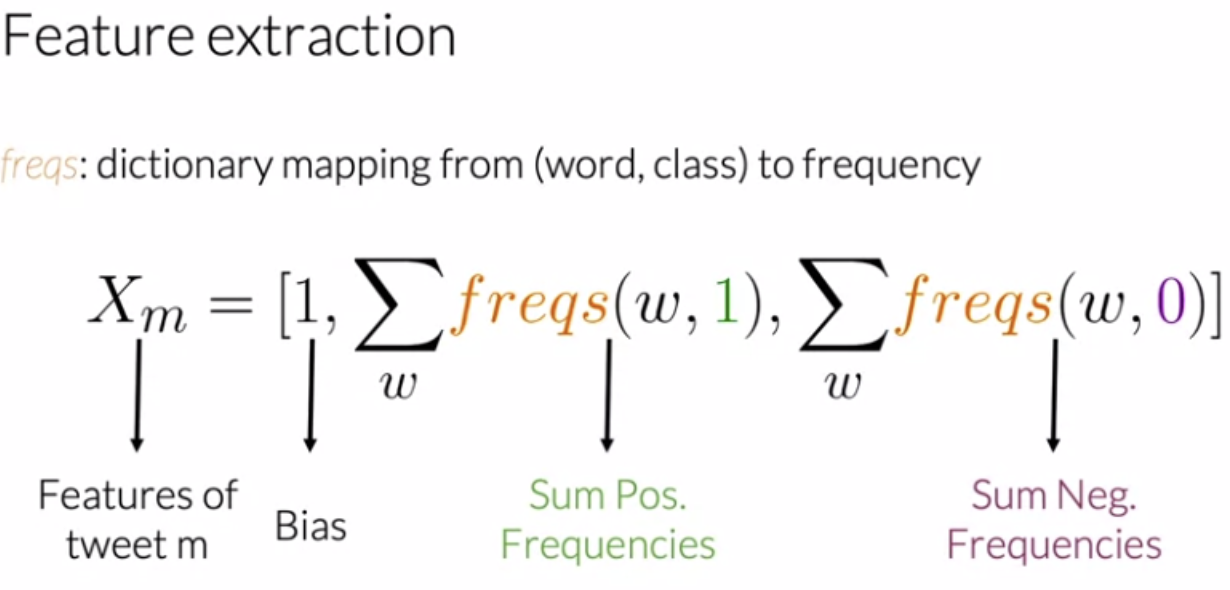
* Previously, the word vector was of dimension `V`. Now, we will represent it with a vector of dimension `3`
* To do so, create a dictionary to map the word, and the class it appeared in (positive or negative) to the number of times that word appeared in its corresponding class.
* We call this dictionary `freqs`
* ```feature vector of a tweet m = [ Bias, sum of positive frequency, sum of negative frequency]```
Frequency Dictionary:
Text represented as a vector of dimension 3.
### Build Frequency Dictionary:
```python=
def build_freqs(tweets, ys):
"""
tweets: a list of tweets
ys: an m x 1 array with the sentiment label of each tweet
(either 0 or 1)
freqs: a dictionary mapping each (word, sentiment) pair (=key) to its frequency (=value)
"""
# Convert np array to list since zip needs an iterable.
# The squeeze is necessary or the list ends up with one element.
# Also note that this is just a NOP if ys is already a list.
yslist = np.squeeze(ys).tolist()
# Start with an empty dictionary and populate it by looping over all tweets
# and over all processed words in each tweet.
freqs = {}
for y, tweet in zip(yslist, tweets):
for word in process_tweet(tweet):
pair = (word, y)
if pair in freqs:
freqs[pair] += 1
else:
freqs[pair] = 1
return freqs
```
```python=
training_tweets = positive_train + negative_train
# make a numpy array representing labels of the tweets
labels = np.append(np.ones((len(positive_train))), np.zeros((len(negative_train))))
```
```python=
# create frequency dictionary
freqs = build_freqs(training_tweets, labels)
# check data type
print(f'type(freqs) = {type(freqs)}')
# check length of the dictionary
print(f'len(freqs) = {len(freqs)}')
```
>type(freqs) = <class 'dict'>
len(freqs) = 7985
---
title: Feature Extraction
description:
duration: 1200
card_type: cue_card
---
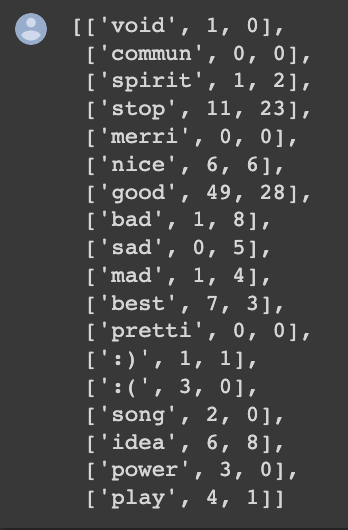
### Extracting features from Frequency Dictionary
```python=
# select some words to appear in the report.
keys = ['void', 'commun', 'spirit', 'stop', 'merri', 'nice', 'good', 'bad', 'sad', 'mad', 'best', 'pretti',
':)', ':(', 'song', 'idea', 'power', 'play']
# list representing our table of word counts.
# each element consist of a sublist with this pattern: [<word>, <positive_count>, <negative_count>]
data = []
# loop through our selected words
for word in keys:
# initialize positive and negative counts
pos = 0
neg = 0
# retrieve number of positive counts
if (word, 1) in freqs:
pos = freqs[(word, 1)]
# retrieve number of negative counts
if (word, 0) in freqs:
neg = freqs[(word, 0)]
# append the word counts to the table
data.append([word, pos, neg])
data
```
```python=
# df = pd.DataFrame(data, columns =['Word', 'pos_log', 'neg_log'])
# df['pos_log'] = np.log(df['pos_log']+1)
# df['neg_log'] = np.log(df['neg_log']+1)
# df
```
```python=
# fig = px.scatter(df, x="pos_log", y="neg_log", hover_data=['Word'])
# fig.show()
```
```python=
fig, ax = plt.subplots(figsize = (13, 13))
# convert positive raw counts to logarithmic scale. we add 1 to avoid log(0)
x = np.log([x[1] + 1 for x in data])
# do the same for the negative counts
y = np.log([x[2] + 1 for x in data])
# Plot a dot for each pair of words
ax.scatter(x, y)
# assign axis labels
plt.xlabel("Log Positive count")
plt.ylabel("Log Negative count")
# Add the word as the label at the same position as you added the points just before
for i in range(0, len(data)):
ax.annotate(data[i][0], (x[i], y[i]), fontsize=10)
ax.plot([0, 4], [0, 4], color = 'brown') # Plot the red line that divides the 2 areas.
plt.show()
```
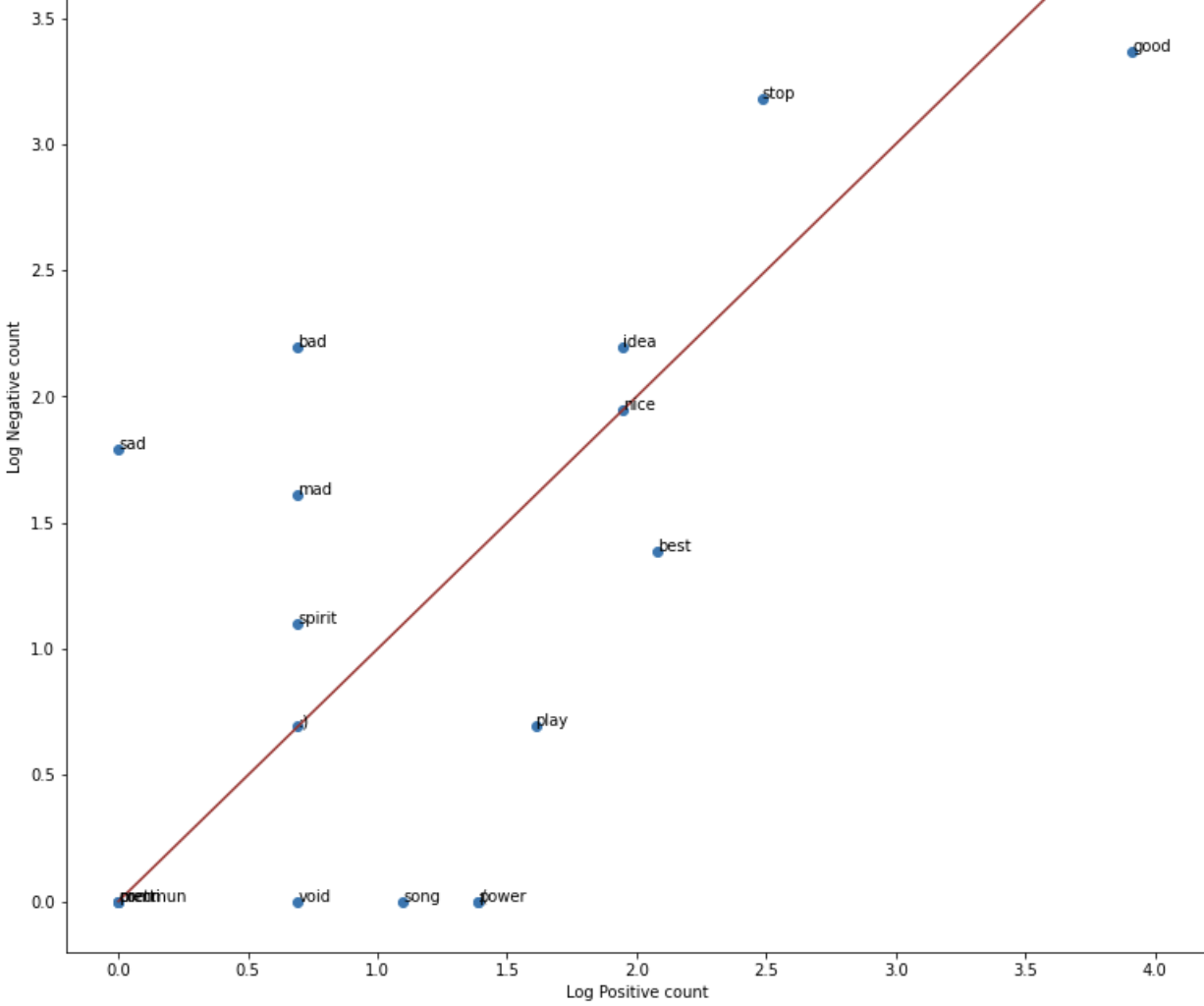
#### Log Positive Count VS Log Negative Count
- This is the scatter chart to show which occur more on the positive sentiment and which word occur more on the negative sentiment.<br>
- We have positive and negative counts of words and to scale it we have done log operation in the counts. The brown line is not a classifier. It is a 45 degree straight line.<br>
- The words lying below the line have more positive sentiment and the words lying above it has more negative sentiment.
#### BOW VS Rule-based NLP methods
In Rule based NLP method lets assume we have made a dictionary of all positive and negative words and give some score to each word and using this dictionary we will classify a tweet whether it is a positive or negative tweet.
#### Can we generalize this idea using BOW + Logistic Regression ? (ask learners)
- So in the BOW we make sparse vector for each data point and in this sparse vector words from the corpus which are present in the data point have value 1 and rest 0
- So when we apply Logistic Regression then at the end of the training we can say the weights saved is like the manual score given to the each word(here we are not saying both are same as obviously dimensions are different)
- So rather than having fixed value score of each word, neural network will calculate the best weight dynamically according to the corpus and data points.
### Extracting features function.
```python=
def extract_features(tweet, freqs):
'''
tweet: a list of words for one tweet
freqs: a dictionary corresponding to the frequencies of each tuple (word, label)
x: a feature vector of dimension (1,3)
'''
# process_tweet tokenizes, stems, and removes stopwords
word_l = process_tweet(tweet)
# 3 elements in the form of a 1 x 3 vector
x = np.zeros((1, 3))
#bias term is set to 1
x[0,0] = 1
# loop through each word in the list of words
for word in word_l:
# increment the word count for the positive label 1
x[0,1] += freqs.get((word, 1.0),0)
# increment the word count for the negative label 0
x[0,2] += freqs.get((word, 0.0),0)
assert(x.shape == (1, 3))
return x
```
#### Example 1: feature extraction for a tweet
```python=
train_x = training_tweets
tmp1 = extract_features(train_x[0], freqs)
print(tmp1)
```
> [[1.00e+00 2.26e+03 2.44e+03]]
#### Example 2: feature extraction for a random string
```python=
tmp2 = extract_features('This batch is the best batch', freqs)
print(tmp2)
```
> [[ 1. 11. 3.]]
---
title: Logistic Regression
description:
duration: 900
card_type: cue_card
---
### Preparing training data
```python=
# collect the features 'x' and stack them into a matrix 'X'
X = np.zeros((len(train_x), 3))
for i in range(len(train_x)):
X[i, :]= extract_features(train_x[i], freqs)
# training labels corresponding to X
train_y = np.append(np.ones((len(positive_train), 1)), np.zeros((len(negative_train), 1)), axis=0)
Y = np.ravel(train_y,order='C')
```
#### 1.6 Using the most LR to classify
```python=
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression().fit(X, Y)
print("Training Accuracy: ",clf.score(X, Y))
```
> Training Accuracy: 0.6743725231175693
#### Logistic Regression with L1 Regularization
```python=
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(C = 0.1,solver= 'saga', penalty= 'l1', max_iter = 500).fit(X, Y)
print("Training Accuracy: ",clf.score(X, Y))
```
> Training Accuracy: 0.6829590488771466
**Solver:** It is an algorithm to use in optimization problem.
- For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones;
- For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss;
- ‘liblinear’ is limited to one-versus-rest schemes.
- L1 penalty is only possible with 'saga' and 'liblinear' solver
- ‘sag’ and ‘saga’ fast convergence is only guaranteed on features with approximately the same scale.
**Penalty:** We can add 'l1', 'l2', 'elasticnet' regularization term to the problem.
**C:** It is an inverse of Regularization Strength.
### Check performance on test set
```python=
# Testing
testing_tweets = positive_test + negative_test
test_X = np.zeros((len(testing_tweets), 3))
for i in range(len(testing_tweets)):
test_X[i, :]= extract_features(testing_tweets[i], freqs)
# training labels corresponding to X
test_y = np.append(np.ones((len(positive_test), 1)), np.zeros((len(negative_test), 1)), axis=0)
test_Y = np.ravel(test_y,order='C')
print("Testing Accuracy: ",clf.score(test_X, test_Y))
```
### Predict whether a tweet is positive or negative.
**Note:** classify 1, for a positive sentiment, and 0, for a negative sentiment.
```python=
def predict_custom_tweet(tweet, freqs):
x = extract_features(tweet,freqs)
y_pred = clf.predict(x)
return y_pred
# test your function
list_of_tweets = ['\033[92m'+'Thank God coronovirus is over',
'\033[91m'+'This is seriously ridiculous. Stop hoarding',
'\033[92m'+'Government efforts are great.',
'\033[93m'+'Nonsense', #anomaly in classification
'\033[91m'+'Panic-buying is pushing up prices.#coronavirus',
'\033[92m'+'THANK YOU to make hand sanitizer in distillery amid outbreak']
for tweet in list_of_tweets:
print( '%s -> %f' % (tweet, predict_custom_tweet(tweet, freqs)))
```
> Thank God coronovirus is over -> 1.000000
This is seriously ridiculous. Stop hoarding -> 0.000000
Government efforts are great. -> 1.000000
Nonsense -> 1.000000
Panic-buying is pushing up prices.#coronavirus -> 0.000000
THANK YOU to make hand sanitizer in distillery amid outbreak -> 1.000000
### Conclusion
**Aim:** To utilize Twitter feed to carry out the sentimental analysis on the new strain of COVID-19.
**Made machine understand textual data**
* Tokenization
* Regular expression
* Natural Language Toolkit (NLTK) package
* Preprocessing:
> 1. Remove hyperlinks, hashtags etc.
> 2. Remove stopwords and punctuation
> 3. Stemming
* Represent text in NLP:
> 1. Sparse representation
> 2. Drawbacks of sparse representation
> 3. Frequency Dictionary
> 4. Extracting features from Frequency Dictionary
* Training Logistic Regression.
* Performance on the test set
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet