# Common Performance Pitfalls and how to avoid them
---
Common Pitfalls
* The N+1 query problem
* Overserialization
* Query complexity, unnecessary joins
* Lack of .iterator()
---
N+1 problem
The "N+1 queries" problem is a performance issue in which the application makes database queries in a loop, instead of making a single query that returns or modifies all the information at once.
---
Django queries do not bring in foreign-key relationship data, so accessing model instance(s) via a foreign-key reference will trigger a database query
Very easy to do when writing serializers for your model, e.g.
```python!
class TagSerializer:
collection = CollectionSerializer()
count = serializers.SerializerMethodField()
def get_count(self, obj):
return obj.ansible_collectionversion.count()
```
---
Solution:
* Use `select_related`, `prefetch_related`, and `annotate`
```python!
class TagViewSet:
def get_queryset(self):
qs = super().get_queryset().select_related("collection")
return qs.annotate(count=Count("ansible_collectionversion"))
```
---
Special case: If you only need the primary key value of the instance, use `$field_id`
Bad:
```python!
book.author.pk
```
Good:
```python!
book.author_id
```
---
Overserialization
* Django tries to load all the query data requested into memory on query execution
* Overload of data can hit the limits of your database, your memory, or request response time
* Solution: Less data by using `only`, `values/values_list`, `iterator`, & pagination/slicing
---
Common Migration Example
```python!
batch = []
for task in Task.objects.iterator():
task.enc_args = task.args
batch.append(task)
if len(batch) >= 500:
Task.bulk_update(batch, fields=["enc_args"])
batch.clear()
if batch:
Task.bulk_update(batch, fields=["enc_args"])
```
---
Caution - if you use .only(), and then subsequently use those fields anyway, you'll trigger "N+1 queries"
Performance will likely be worse, instead of better. This has bitten us in practice a number of times.
---
If you're using `select_related()` to avoid additional queries, consider using `.values()` or `.values_list()` to avoid fetching *all* of the fields from the joined table.
`.only()` in combination with `.select_related()` can be tricky.
---
Identifing Overserialization
* Really tough to do on developer machines with small databases
* Code inspection - be wary of each ORM call, especially for `for loops`
* Use profiling - ideally on a test machine with larger resources and a big database
---
Query complexity
* ORM is powerful, but it can easily hide the complexities of a query behind innocent looking code
* Be careful when or-ing queries together or combining multiple cross table lookups into one query, e.g:
```python!
qs = Artifacts.objects.filter(content__pk__in=content)
for tree in DistributionTree.objects.filter(pk__in=content):
qs |= tree.artifacts()
```
---
Solution: return to simplicity
```python!
pks = set(
Artifacts.objects.filter(content__pk__in=content)
.values_list("pk", flat=True)
)
for tree in DistributionTree.objects.filter(pk__in=content):
pks |= set(tree.artifacts().values_list("pk", flat=True))
return Artifacts.objects.filter(pk__in=pks)
```
---
### .iterator()
If you plan to iterate over a large dataset, or to use a queryset only once, it is important to call `.iterator()` on the queryset
```python!
nonmodular_rpms = models.Package.objects.filter(
pk__in=package_ids, is_modular=False
).values(*RPM_FIELDS)
for rpm in nonmodular_rpms.iterator(chunk_size=5000):
self._add_unit_to_solver(rpm_to_solvable, rpm, repo, libsolv_repo_name)
```
---
When a Django queryset is executed, the results are cached in memory, which makes subsequent accesses potentially cheaper.
However, Pulp often deals with large querysets, for which the caching overhead can be substantial. `.iterator()` prevents Django from caching the results.
---
Sometimes you can utilize all of these techniques at once
```python!
for ca in contentartifact_qs.iterator():
if package_checksum_type:
pkgid = ca.get(artifact_checksum, None)
if not package_checksum_type or not pkgid:
if ca["content__rpm_package__checksum_type"] not in settings.ALLOWED_CONTENT_CHECKSUMS:
# ...
package_checksum_type = ca["content__rpm_package__checksum_type"]
pkgid = ca["content__rpm_package__pkgId"]
```
---
How to log slow queries
* Use `.explain(analyze=True)` on the query and paste the result into [Depesz](https://explain.depesz.com/) to get a nice explanation of what postgres is doing
* Lookout for `seq scan` on large number of rows! Good sign that the query needs to be restructured or an index added
---
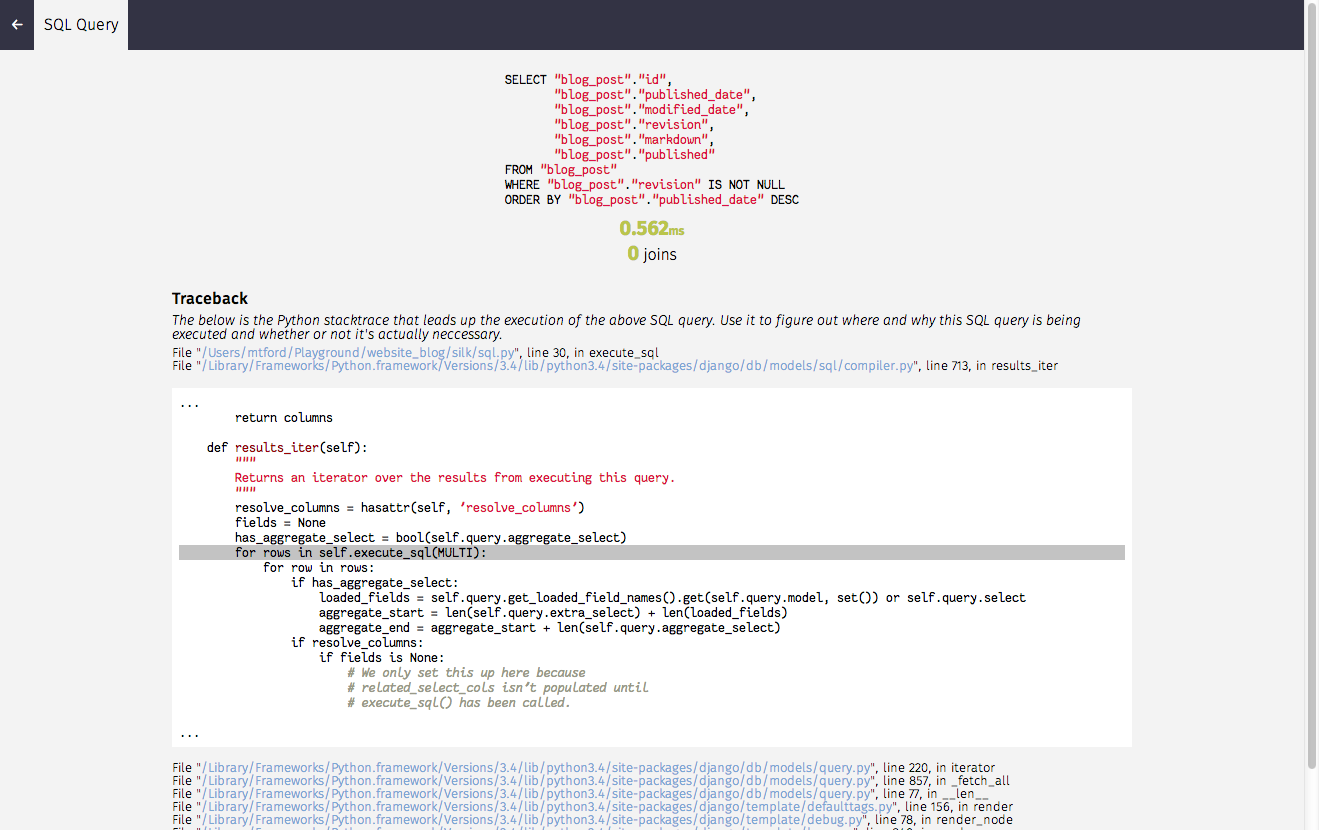
Helpful Tools
* [Django Debug toolbar](https://django-debug-toolbar.readthedocs.io/en/latest/) / [Silk](https://github.com/jazzband/django-silk)
* Profiling
* cprofile / pyinstrument
* [Py-Spy](https://github.com/benfred/py-spy)
---

---

---
---

---
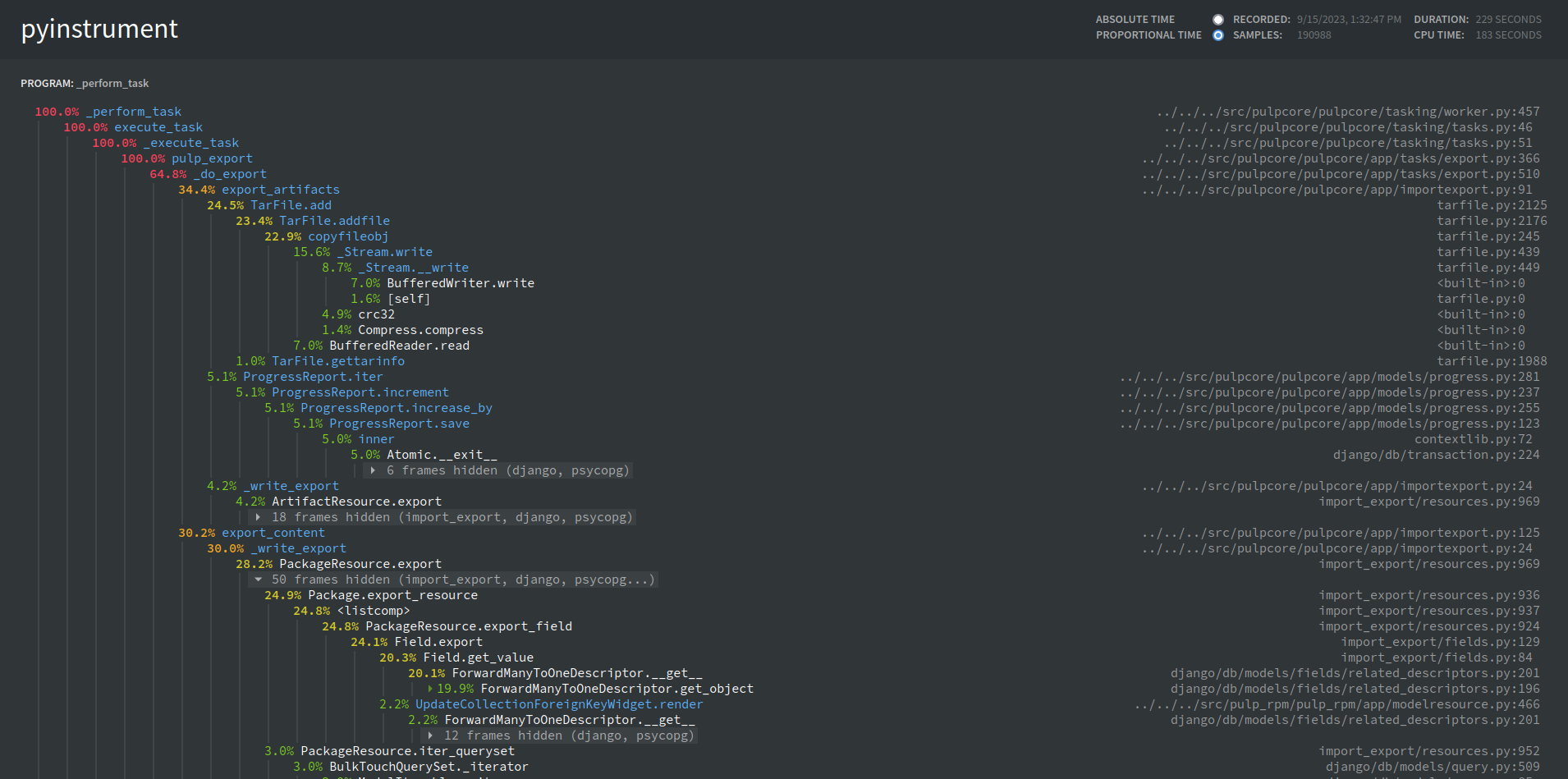
PyInstrument
Now available behind the TASK_DIAGNOSTICS flag
---
---
Caveats:
* Requires an additional package to be installed
* For very long-running tasks (20min+) there is a significant memory leak
* It invalidates the memory tracking we currently have in place
* Not working very well on sync tasks?
---
PySpy
PySpy is a sampling profiler, it attaches itself to the interpreter and takes regular snapshots of the call stack
---
Especially useful when a task is "stuck" and you're not sure why
`py-spy top --pid 12345`
`py-spy dump --pid 12345`
---
###### tags: `PulpCon 2023`
{"title":"Observability and the opentelemetry project","description":"slides: https://hackmd.io/@pulp/H1TXoJPBs#/","contributors":"[{\"id\":\"191376ae-ffab-4a37-b020-820f7bc62a81\",\"add\":5091,\"del\":1815},{\"id\":\"4b1152d2-c7d3-42a7-ae07-9821ff05bb92\",\"add\":3231,\"del\":246}]"}