# 2018q3 Homework1
contributed by <`posutsai`>
>固定格式,請注意
>[name=課程助教][color=red]
## [指標篇](https://hackmd.io/s/HyBPr9WGl)
### 心得
#### Signal Function prototype
`void ( *signal(int sig, void (*handler)(int)) ) (int);`
從上述 signal function 可以解析出:
* 本體上 signal function 是一個有兩個輸入和一個輸出的函數
* input:
* int
* function pointer 所指向的函數沒有輸出而且只有一個 int 輸入
* output:
* 輸出的 function pointer 所指向的函數沒有輸出而且也是只有一個輸入
* 在 [man page](http://man7.org/linux/man-pages/man2/signal.2.html) 中透過一個 `typedef` 就可以用更清楚的方式表達
```C=
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
```
我想,就像老師說的這樣的函數宣告存在 linux kernel 的意義從來都不會是故意刁難開發者能不能一眼看出函數的輸入輸出,會這樣定義勢必有其原因,進一步從 signal 函數的用途分析,他是類似 JavaScript 內部對事件處理的機制 event handler 的方式對不定時會出現的 signal 做出響應。
### Question
:::warning
:question:
* 以下是從 [man page](http://man7.org/linux/man-pages/man2/signal.2.html) 節錄下來關於 signal function 輸出的描述。
> RETURN VALUE
> signal() returns the previous value of the signal handler, or SIG_ERR
> on error. In the event of an error, errno is set to indicate the cause.
想問老師的是 "previous value" 指的是指向哪一個 stack 內的 function嗎?
:::
## [前置處理器應用篇](https://hackmd.io/s/S1maxCXMl)
### 心得
#### Macro 技巧 (文字處理)
* Stringnize, Concatenate & Previous experience:
想比較這次在影片中有看到的技巧,以及過往閱讀過的 source code 的應用場景。自己曾經參考 [openslide](https://github.com/openslide/openslide) 實作過多媒體檔案描述格式 (MRXS, MDS) 的讀寫其中就有[部分程式碼](https://github.com/openslide/openslide/blob/master/src/openslide-vendor-mirax.c)用到相關技巧,列在下方並加上註解作為比較。
```C
#define READ_KEY_OR_FAIL(TARGET, KEYFILE, GROUP, KEY, TYPE) \
do { \
GError *tmp_err = NULL; \
TARGET = g_key_file_get_ ## TYPE(KEYFILE, GROUP, KEY, &tmp_err); \
if (tmp_err != NULL) { \
g_propagate_error(err, tmp_err); \
goto FAIL; \
} \
} while(0)
```
上面這段程式碼是用來讀取多媒體資料相關的 metadata 用的,在 mrxs 檔中這類資訊是以 Key-Value 型式儲存於檔案中,這類資訊很可能是不同類型的變數,用 `unsigned int` 紀錄多媒體資料長寬,用 `char *` 紀錄實際多媒體資料內容被 encode 在哪個檔案中 .... 若是針對不同 value 型態都去定義一個介面,會顯得很費工耗時,又想做到針對不同的 `TYPE` 參數呼叫 GLib 內不同的函數 `g_key_file_get_xxx` 於是便用了 concate operator 達到這樣的目的。
```C++
#define POSITIVE_OR_FAIL(N) \
do { \
if (N <= 0) { \
g_set_error(err, OPENSLIDE_ERROR, \
OPENSLIDE_ERROR_FAILED, #N " <= 0: %d", N); \
goto FAIL; \
} \
} while(0)
```
這是 Openslide 中另一段程式碼,在這裡用到了 Stringnize 的技巧,為了在錯誤處理時方便的紀錄是哪個 key 值讀取時<s>噴出</s> 產生的 error 把 `N` 轉為字串。
:::success
「噴出」這詞很怪,改為「輸出」或「產生」都好得多
:notes: jserv
:::
* do-while loop:
影片中並沒有提到這類技巧,但就如在 Previous Experience 中的程式碼片段,常常在其他 repository 中看到,在這裡做個紀錄,以我的經驗平常在寫程式並不常用到 `do while` ,以邏輯來看這樣的一個 while loop 並沒有什麼特別 `while(0)` 只保證了 `do` block 會被執行了一次,不僅沒必要更顯得多此一舉,但其實這樣寫的用意是為了更好的避免不必要的 macro function syntax error 。
```C=
// test.c
#define foo() printf("1st func\n"); printf("2nd func");
int main() {
if (1)
foo();
else
return 0;
}
```
```
GCC compile error
test.c: In function ‘main’:
test.c:7:5: error: ‘else’ without a previous ‘if’
else
^
```
從編譯器中吐出來的錯誤可以看到,有文法上的錯誤但單純以肉眼很難發現到底哪裡有錯,進一步以 `gcc -E -P` 觀察 preprocessor 輸出的結果可以看到有一個地方有問題
```C=
# 4 "test.c"
int main() {
if (1)
printf("1st func\n"); printf("2nd func\n");;
else
return 0;
}
```
在這裡,就可以看到 line 4 多了一個 `;` 導致文法上的錯誤,當然我們也可以把 test.c 中的 `foo();` 改為 `foo()` 把 `;` 拿掉,但這會導致程式碼上的不一致,進一步,若是我們改以 do-while 改寫,經過 preprocess 之後會是這樣的結果。
```C=
# 8 "test_do_while.c"
int main() {
if (1)
do { printf("1st func\n"); printf("2nd func\n"); } while(0);
else
return 0;
}
```
可以看到這時 `;` 還是會有但放在 while 的條件之後,不再會有文法上的錯誤,更可以讓 macro function 有自己的 scope。
:::info
主要用意是避免 [Dangling else](https://en.wikipedia.org/wiki/Dangling_else),而 `do { } while (0)` 整個敘述中若有 `break`,可達到形同 goto 的動作
:notes: jserv
:::
#### Macro 技巧 (Template-like)
* `_Generic` keyword
影片中 ray-tracing 那個例子 concatenate operator 是用在以同一個介面作為 constructor 宣告不同 type 的變數,而上面 openslide 的例子卻是以同一個效果呈現類似 template 的效果,以下想做個不同實現方式的比較
```C
#include <stdio.h>
#define PRINT_CONCAT(VALUE, TYPE) \
do { \
print_ ## TYPE(VALUE); \
} while(0)
#define PRINT_GENERIC(VALUE) \
_Generic((VALUE), \
float: print_float, \
int: print_int \
)(VALUE)
void print_float(float v) {
printf("float value is %f\n", v);
}
void print_int(int v) {
printf("int value is %d\n", v);
}
int main() {
float f = 10.;
int i = 10;
// use concatenate
PRINT_CONCAT(f, float);
PRINT_CONCAT(i, int);
// use _Generic
PRINT_GENERIC(f);
PRINT_GENERIC(i);
}
```
從上面的實作可以看到,在 C99 或是 C11 都可以做到這樣的效果,但是在 `##` 操作下就必須讓函數命名有特定的格式,反之在 `_Generic` 仍有很大的命名自由度,再者以 concatenate 方式實作必須另外傳一個相對的類型參數,顯得有些累贅。
另外,不管在影片中或是網路上的教學,`_Generic` 的使用都是針對單一參數,我在 [stackoverflow](https://stackoverflow.com/questions/17302913/generics-for-multiparameter-c-functions-in-c11) 上有發現類似多參數的使用。
## [linked list 和非連續記憶體操作](https://hackmd.io/s/SkE33UTHf)
### 心得
#### Linus "Good taste" implementation
```C
// Bad taste
void remove_list_node_v1(List* list, Node* target)
{
Node* prev = NULL;
Node* current = list->head;
// Walk the list
while (current != target) {
prev = current;
current = current->next;
}
// Remove the target by updating the head or the previous node.
if (!prev)
list->head = target->next;
else
prev->next = target->next;
}
```
```C
// Good taste
void remove_list_node_v3(List* list, Node* target)
{
// The "indirect" pointer points to the *address*
// of the thing we'll update.
Node** indirect = &list->head;
// Walk the list, looking for the thing that
// points to the node we want to remove.
while (*indirect != target)
indirect = &(*indirect)->next;
*indirect = target->next;
}
```
* 首先比較所謂好壞品味的程式碼差異:
比較兩者差異可以看到根本差異在於最後的 if-else ,仔細分析 Linus 版本可以發現它提供了更好的抽象化,用一樣的手法處理例外的狀況 (若是想刪除的節點是起始節點),以往寫程式的想法總是很直覺的,為了滿足特定條件,而寫了 if-else 甚至用了很多的 switch-case 曾經在網路上有看過一些[文章](https://stackoverflow.com/questions/3951931/c-design-pattern-to-get-rid-of-if-then-else),透過減少程式撰寫中使用的 if-else 和 switch-case 用多型這類的技巧作為替換,就可以達到整個程式碼品質的提升,更好的抽象化出具有一般性的表現形式。
#### Lock-free and Lock-based
之前其實在試著實作 single producer multiple consumer threadpool 的時候就有想過後來要改為 lock-free 版本,在找資料的時候就有看到 Herb Sutter 在 CppCon 2014 [Lock-Free Programming (or, Juggling Razor Blades)](https://www.youtube.com/watch?v=c1gO9aB9nbs) 關於以 C++ atomic 搭配 CAS 實作 threadpool 的效果,不過他在這份[投影片](https://github.com/CppCon/CppCon2014/blob/master/Presentations/Lock-Free%20Programming%20(or%2C%20Juggling%20Razor%20Blades)/Lock-Free%20Programming%20(or%2C%20Juggling%20Razor%20Blades)%20-%20Herb%20Sutter%20-%20CppCon%202014.pdf)第12頁提出了 Mail Slot 的 pattern 去實作這樣的效果。比較之前曾在 Github 上看過類似的 [ThreadPool](https://github.com/lzpong/threadpool) 實作和 Herb 所以提出的 pattern 的差異是:
* 在 maintain 一個 thread-safe queue 的時候,傳統上是採取 Mutex 的實作,保障每個 thread 在存取 queue 的時候會是同一個狀態,透過以下的程式碼片段可以看到把 task push 進到 queue 上鎖解鎖的過程。
```C++=
auto commit(F&& f, Args&&... args) ->future<decltype(f(args...))> {
using RetType = decltype(f(args...));
auto task = make_shared<packaged_task<RetType()>>(
bind(forward<F>(f), forward<Args>(args)...)
);
future<RetType> future = task->get_future();
{
// 在這個 block 內上 Mutex,透過額外的 block
// 使得 mutex 可以自動在出這個 scope 的同時
// 解鎖
lock_guard<mutex> lock{ _lock };
// _tasks 是 class 內部自己定義的 vector
_tasks.emplace([task](){
(*task)();
});
}
_task_cv.notify_one();
return future;
}
```
* 個人認為在 Herb 所提出的架構中最高竿的地方在於它完全跳脫了 Queue 在這個 pattern 中扮演的腳色,主要的應用場景可能是 Main thread 是 producer,其他在 ThreadPool constructor 階段就建構出來的 thread 是 consumer,每個 consumer 擁有自己的郵箱,我們只要保有這個郵箱狀態的 atomicity,當 producer 把任務放入郵箱時,改變此 consumer 狀態為 busy,當 consumer 完成任務時在轉換為 idle ,這樣不僅可以保持 critical section 的簡潔,CAS 和 mutex 的效能差異在於,CAS 在處理 race condition 的狀況可能不是每次都有,或許只有 20% 甚至更少,但 mutex 是假設每一次都會發生 race condition。
而在第二部分的[演講](https://github.com/CppCon/CppCon2014/blob/master/Presentations/Lock-Free%20Programming%20(or%2C%20Juggling%20Razor%20Blades)/Lock-Free%20Programming%20(or%2C%20Juggling%20Razor%20Blades)%20-%20Herb%20Sutter%20-%20CppCon%202014.pdf)投影片中第15頁也提到了以 lock-free 去實作 singly-linked list,相比於演講前半段的 Multi-consumer single producer pattern 而言就顯得難上許多,需要考量的狀況更多,甚至提到了 ABA problem,這部分和老師在參考資料下方的 [mergesort-concurrent](https://hackmd.io/s/r12FM-MeW) 相互呼應。我想當逐漸追求 performance 時就會面臨 scability 的問題,而 linked list 就是很好的練習題目。另一個我從 Herb 的演講學到最大的是如何測量在多執行緒狀況下的效能分析。
### Question
:::warning
:question:
* 想請問老師連結中 Linux kernel [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h#L464) 提到的這段程式碼,不太懂為何每一個 head pointer 都要先加上`()` 似乎沒有優先權上需要額外加上這個小括號的原因?
```C
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
```
:::
:::info
考慮 `head` 帶入到巨集 `list_for_each_prev` 的輸入可能是 `*ptr` 的形式,然後就會致使 `*ptr->prev` 成為被處理的程式碼,你可以繼續想,這有什麼問題?
:notes: jserv
:::
> 若是沒有小括號的話 for loop 起始條件會變成 pos = *ptr->prev,根據 [C operator precedence](https://en.cppreference.com/w/c/language/operator_precedence) 可以知道會先執行 arrow operator 再作 dereference,而這和我們所希望表現的行為就不一樣了。我想若是由我來寫的話一定不會加上這個小括號就預設這個 macro 的輸入是怎樣的型態,也就使得我的 macro 不夠一般,或許這只是一個小細節,但我想這就是表現抽象化精神的一個很好例子。
## [編譯器和最佳化原理篇](https://hackmd.io/s/Hy72937Me)
### 心得
#### hello.c 在 Linux 上的執行
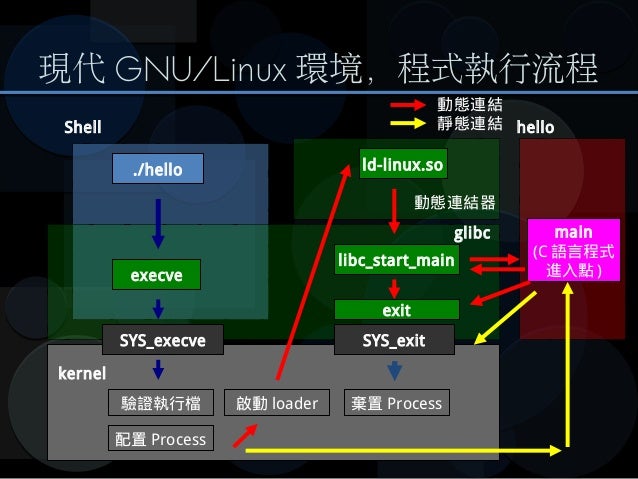
上圖為 linux 上執行一個執行檔的必要流程,我在[程序員的自我修養](https://www.books.com.tw/products/0010456858),這本書中曾經看過可以在 main 進入點前執行另外的函數,在當時並沒有深刻理解這個機制存在的意義,透過這個示意圖可以了解到 linux 整個核心的運作,進一步會讓我好奇 GDB 這類 debugger 實際運作的機制,以往也曾經因為作業需求,自己需要寫 so 檔,並用 ld link 在一起,但當時其實對 gcc 所下的參數型式很不了解。
#### LLVM Compiler Infrastructure
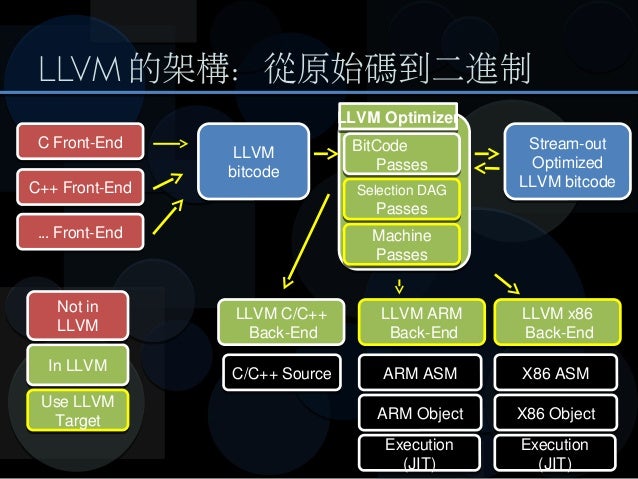
在影片後段介紹 LLVM 的那個部分感受特別深刻,因為本身用過 tensorflow 實作過部分模型,但一直對 tensorflow 底層的運作機制很感興趣,尤其是近期面對模型在訓練階段速度十分緩慢,又或者是在預測階段輸出效率不高,就會想要加速。後來在 tensorflow 裡面其實發現有針對線性運算的 DSL 這樣的 IR 叫做 HLO 配合的編譯器是 [XLA](https://www.tensorflow.org/performance/xla/) ,本來在看影片前對文件上的敘述其實不太了解,但看完影片後就有了基本的認知,我想從這個切入,應該會有很多手段可以對 ML 模型做加速。
另外影片的最後有提到 Directed Acyclic Graph 在編譯器中的重要性,我想 tensorflow computation graph 可以用這樣的方法做到加速,也是因為本質上也是一系列 computation node 所組合而成的。或許僅僅透過兩部影片並不能對 compiler 有太多深入的理解,但確實讓我對編譯器之於整個電腦科學的重要性,有了很大的改觀,我想在現今大家一窩蜂追求以 Python 這類更高階的語言開發新的演算法的同時,大家似乎都忘了,編譯器這類最佳化工具在 machine learning platform 中扮演的加速腳色,或許這是一條很少有人看到的不錯選項。
### Question
:::warning
:question:
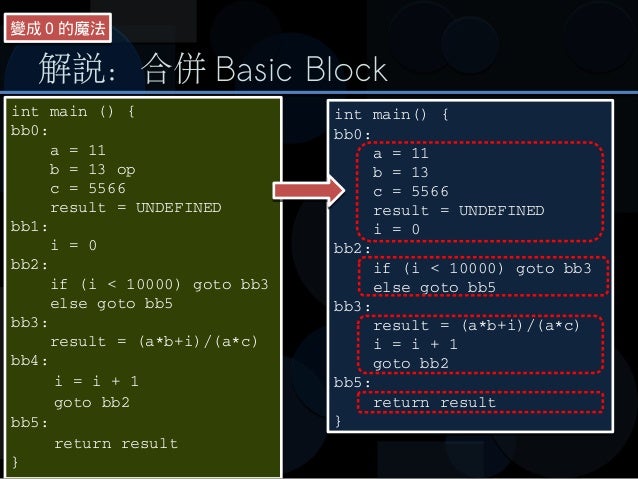
* 在投影片中,如下截圖, bb2 包含兩個 goto 這似乎不符合之前對於 basic block 的定義,單一進入點且單一出口點?
:::info
The code in a [basic block](https://en.wikipedia.org/wiki/Basic_block) has:
* One entry point, meaning no code within it is the destination of a jump instruction anywhere in the program.
* One exit point, meaning only the last instruction can cause the program to begin executing code in a different basic block.
關鍵是 entry/exit,最後一個指令是跳躍,無論變數 `i` 的值為何。
另外,提問時應該列出投影片的頁碼或者參照的材料章節。
:notes: jserv
:::
:::warning
* 在 [How A Compiler Works: GNU Toolchain](https://www.slideshare.net/jserv/how-a-compiler-works-gnu-toolchain) 第 39 張投影片中,Static Single Assignment (SSA) Form 定義中有提到該表示法中,每個被 assign 的變數都只會出現一次,那 SSA Form 怎麼處理每個 scope 中同樣變數命名的狀況呢? 具體程式碼如下。
進一步想知道,若是 SSA Form optimization 是根據 scope 不同,分開處理,那是不是在 AST 階段就已經把 scope 標註在樹上了?如果是的話,AST 又是怎麼處理 scope 的?
```C=
int main() {
int a = 0; // external scope
for (int i = 0; i < 5; i++) {
int a = 0; // internal scope
// do some operation on internal a
// ....
}
return 0;
}
```
* 在[How A Compiler Works: GNU Toolchain](https://www.slideshare.net/jserv/how-a-compiler-works-gnu-toolchain)第 25 張投影片中提及,現今的最佳化處理手段,很大程度是 based on CFG 這樣的 directed graph 結構,也就是可以把圖論或是其他以往用在這樣資料結構的手法在這個階段實現。想請問是不是有一定的最佳化順序,像是先做 code motion 或是 DCE 這類,又或者是同樣的 CFG 在經過不同的 optimization order 之後的結果會不一樣? 如果不一樣的話,compiler 本身又是怎麼決定這些手段的順序呢?
會有這樣的疑問是因為我有找到一篇[論文](https://arxiv.org/pdf/1801.04405.pdf),試圖以 ML 的手法去決定該先做哪個最佳化手段該先做,哪個又該比較晚做。
* 影片中,有提到 [OpenCl](https://www.khronos.org/opencl/) 和 [C++AMP](https://msdn.microsoft.com/zh-tw/library/hh265137.aspx) 就我的了解使用這類的 lib 經由廠商提供的編譯器,可以達到很大程度的異質平行計算,而 [CUDA](https://zh.wikipedia.org/wiki/CUDA) 是 Nvidia 開發的類似產品,不過並沒有開源,如果想駕馭這類的工具,該怎麼著手呢? 具體的來說,當我使用 tensorflow 時,我按照官方網站上面的教學,可能透過 Opencl 或是 CUDA 編譯了 tensorflow [computation graph](https://github.com/tensorflow/tensorflow/issues/22),完全不知道 OpenCl 或是 CUDA 內部到底幫我們做了哪一些事情,有什麼比較好的方式具體的了解 OpenCl 為我們做了什麼嗎?
* 如同我在心得中有提到關於 tensorflow [XLA](https://www.tensorflow.org/performance/xla/) 的部分,在文件中有提到目前 XLA 還是一個實驗性的產品,用 JIT mode 的執行效率不一定會比較好,而且希望社群開發者可以貢獻支援更多的語言後端,基於自己也是一個愛好開源軟體和 tensorflow 的使用者,其實蠻想自己試試看的,或許可以用 CSAPP 內那套簡單的指令集 [Y86](https://github.com/oyzh/CSAPP-Y86)實作看看,想請問老師的是,這樣的想法是有可能可以做到的嗎? 如果是的話,老師會給我什麼樣的建議呢?
:::