[toc]
## sed命令
1. sed命令执行时包含了若干个循环(cycle),而每个循环又包含若干个命令(command),完整的执行流程图为([图片来源](https://linux.cn/article-10232-1.html)):

2. **tips:** 如果sed语法的第一个字符是“/”,那么表示这是一个正则表达式的地址定位方式。(细品)
3. sed使用场景示例:
> ``` bash
> echo 'line 1\nline 2\nline 3' | sed 's/line/"&"/g' #将所有的line加上双引号
> echo 'line\t1\nline\t2\nline\t3' | sed -n 'l' #显示文本中的控制字符
> echo 'line 1\nline 2\nline 3' | sed -n '/1/=' #显示包含1的行的行号,输出:1
> echo 'line 1\nline 1\nline 2\nline 3' | sed -n '$=' #显示总行数,输出:3
>
> #删除某几行文字(可以延伸到保留某几行,或删除或保留匹配的行)
> echo 'line 1\nline 2\nline 3' | sed '1d' #删除第1行
> echo 'line 1\nline 2\nline 3' | sed -n '1!p' #功能同上
>
> #sed默认会将pattern space中的数据输出到屏幕,如果使用FLAG p,还会每次额外把current pattern space输出到屏幕,举例
> echo 'line 1\nline 2\nline 3' | sed '/.*/p' #匹配所有的字符,并且会把pattern space和current pattern space中的内容都输出到屏幕上,因此每一行文字都会重复输出两次
> echo 'line 1\nline 2\nline 3' | sed -n '/1/p' #匹配包含“1”的行,但是-n选项会禁止pattern space输出到屏幕,而FLAG p又会把current pattern space中的内容都输出到屏幕上,因此屏幕上显示的是:line 1,也即实现了grep的功能。记住:option -n和command p是一家。
>
> #在日常工作中,经常需要使用sed进行替换(例如部署服务器时,进行模板变量的替换),而需求是屏幕上只输出被修改的行,可以使用FLAG w将修改内容输出的stdout,如下所示:
> ☺ cat 1.txt
> 123
> 456
> 789
> zhengtongshan@DESKTOP-R7DT0R0 /mnt/e/Tetris/src/1_Branches/rtm_tetris_zhugan
> ☺ sed -i 's/1/s/gw /dev/stdout' 1.txt
> s23
> zhengtongshan@DESKTOP-R7DT0R0 /mnt/e/Tetris/src/1_Branches/rtm_tetris_zhugan
> ☺ cat 1.txt
> s23
> 456
> 789
>
> #在日常工作中,会遇到将制定的两行合并为一行的情况,情景为:如果发现某行包含某个字符,则将下面一行和本行合并,如下面的例子,如果行的第一个字符为a,则将后面的一行合并过来
> ☺ echo 'a\nb\nc\na\nb' |sed -e '/^a/N' -e 's/\n//'
> ab
> c
> ab
>
> #下面两个语句是等效的:(细品)
> man cp | sed 's/copy/{&}/w cp.txt' #将man page中的〝copy〞字串加上大括号〝{}〞,并将current pattern space写入“cp.txt”
> man cp | sed -n 's/copy/{&}/p' > cp.txt
>
> #多个FLAG可以叠加使用,但是和其他Linux指令一样,与文件有关的FLAG要放在最后
> man cp | sed 's/copy/{&}/Igpw cp.txt' #不区分大小写(FLAG I)将每行 (FLAG g)的“copy”加上大括号(Command s),将pattern space输出到屏幕(FLAG p),并将current pattern space写入文件“cp.txt”(FLAG w)
> echo 'line 1\n\nline 2\nline 3' | sed '/^$/d' #删除空白行
> echo 'line 1\nline 2\nline 3\nline 4' | sed -e 'N' -e 'N' -e 's/\n/+/g' #用两次N连续读取两个下一行(此时pattern space里有三行),然后把换行符都换成+,执行完毕后,输出为:
> line 1+line 2+line 3
> line 4
> ```
4. 使用t label可以实现事务性的修改,比如两个替换要么同时进行,要么就都不做。
5. command n命令的流程是:1、如果没有配置地址或匹配则输出pattern space(如果不满足则跳过下一步);2、然后读取下一行到pattern space。详情参考:[Sed 命令完全指南](https://linux.cn/article-10232-1.html)中的**次行命令**一节,例如:
``` bash
echo 'line 1\nline 2\nline 3\nline 4\nline 5\nline 6' | sed -e 'n' -e 'n' -ne 'p' #当第1个n执行后,pattern space变成:line 2,当第2个n执行后,pattern space变成:line 3,然后执行p后,打印current pattern space:line 3,然后进入下一个循环,打印出:line 6,上述sed可以简写成:sed -ne 'n;n;p',此外我们发现p命令的n选项是一个全局选项,它对整个sed语句生效而不仅限于p命令自己
```
6. command N、D可以实现联合多行条件判断(例如:满足某一行有ID字符串,且下面两行分别包含NAME和ADDRESS字符串,则执行删除ID行的操作),实现更复杂的操作,如果不使用command N、D,那么sed的操作仅限于行内。
7. command D为删除current pattern space的第一个字符到换行,而command P类似,只是将删除变为打印。
8. command c和s的区别在于,前者是整行替换,后者还需要指定要替换的pattern。
## VIM
* 跳转到某行:**:数字**
* 不区分大小写查找:**/待查找字符串\c**
* 跳转到旧的跳转表位置:**CTRL-O**
* 跳转到新的跳转表位置:**TAB或CTRL-I**
* 滚动半屏:**CTRL-U或CTRL-DOWN**
* 跳转到上一个相同单词:**#**
* 跳转到下一个相同单词:*****
* 括号匹配:**%**
* surround.vim插件用[]括号包裹:
* 光标定位到要包裹的单词块(例如:“InterruptedException”代表一个单词快)
* ysiw](iw代表一个单词块,)
## WSL
1. WSL虚拟磁盘压缩,使用powershell:<code>Optimize-VHD -Path c:\path\to\data.vhdx -Mode Full</code>
2. wsl下进行端口转发,指令:<code>netsh interface portproxy add v4tov4 listenport=5601 connectaddress=localhost connectport=5601</code> 如果发现没有解决问题,可以把localhost改成wsl的地址
3. wsl上删除端口转发的指令:<code>netsh interface portproxy delete v4tov4 listenport=5601</code>
4. 安装某些vpn后,wsl启动时提示:`参考的对象类型不支持尝试的操作`,解决方案:[知乎](https://zhuanlan.zhihu.com/p/151392411)
## Git
1. 使用git自带的ssh或scp命令使如果想使用socks代理,可以在<code>%USERPROFILE%/.ssh/config</code>内增加ProxyCommand命令行进行代理,命令如下:<code>ProxyCommand connect -S 10.12.28.114:1080 %h %p</code> 如果要是用http代理,需要把**-S**改为**-H**
2. 查看本地仓库和远程仓库的关联信息:<code>git remote show origin</code>
3. 修改本地仓库到远程仓库的关联:<code>git branch --set-upstream-to origin/分支名</code>
4. JetBrains IDE上的git工作流
* IDE上安装.ignore插件
* 创建工程:java、nodejs、unity等
* Project视图下空白处右键-->New-->.ignore file-->.gitignore file,在Ignore File Generator窗口下选择User templates和所选语言的模板,填充.gitignore
* VCS菜单下,开启git版本控制,并进行首次提交
* 关联本地仓库到一个远程仓库,方法有两个,方法一:
* 远程仓库初始化:<code>mkdir demo.git && cd demo.git && git init --bare</code>
* 本机添加远程仓库:<code>git remote add origin ssh://git@tingyu.fun:27455/volume2/git/fangshan.git</code>
* 关联本机分支到远程分支:<code>git branch --set-upstream-to=origin/master master</code>
* 推送到远程分支:<code>git push</code>,如果没有关联到
* 方法二(参考文档:[StackOverflow](https://stackoverflow.com/a/20987150)):
* 将本地仓库克隆为原始仓库:<code>git clone --bare fangshan fangshan.git</code>
* 拷贝原始仓库到远程:<code>scp -r -P 27455 ./fangshan.git admin@tingyu.fun:/volume2/git</code>,注意:此处的用户是admin,而非群晖中的用户:git,因为用户git的的shell只有git命令的读权限。
* 按照方法一为本地仓库添加远程仓库,并删除本地的原始仓库。
5. 将本地normal仓库变成原始bare仓库(假设git参考文件夹为repo,参考:[StackOverflow](https://stackoverflow.com/questions/2199897/how-to-convert-a-normal-git-repository-to-a-bare-one))
``` bash
cd repo
mv .git ../repo.git # renaming just for clarity
cd ..
rm -fr repo
cd repo.git
git config --bool core.bare true
```
## Windows上搭建SOCKS代理
问题的提出:驻厂深圳后,办公地点的网络不再是专线,因此IP不再是固定的,而是由运营商动态分配,而线上某些业务都开启了IP白名单,如果仍然通过添加白名单的方式,那么将会非常麻烦。总结一下受限的业务场景,包括:
1. ssh连接腾讯云服务器
2. http访问蓝鲸运维平台
3. jenkins slave(windows 7)服务器拷贝服务器版本到腾讯云
问题的解决:考虑到ssh提供了socks代理,因此可以在北京公司部署一台固定IP且已经加入IP白名单的服务器(假设为HostA,IP为:10.12.28.114,OS为Windows 10),然后开启socks代理,受限业务的流量都通过socks代理。
方案的实施:
1. 安装OpenSSH(windows 10 version 1803及以后的版本已经集成),在HostA上:设置-->应用-->应用和功能-->可选功能-->添加功能-->OpenSSH服务器
2. 开启sshd服务:在HostA上,控制面板-->系统和安全->管理工具-->服务-->OpenSSH SSH Server
3. 开启socks代理:ssh -f -N -D 0.0.0.0:1080 win10@127.0.0.1,此命令会在1080端口上开启sockets代理(关于如何使用ssh-key登录,可以参考这篇文章:[Configuring SSH Key-Based Authentication on Windows 10/ Server 2019](http://woshub.com/using-ssh-key-based-authentication-on-windows/),并着重关注:**How to Login Windows Using SSH Key Under Local Admin?**)
问题解决:
1. 受限场景1:SSH连接工具上设置socks代理,如图所示:
[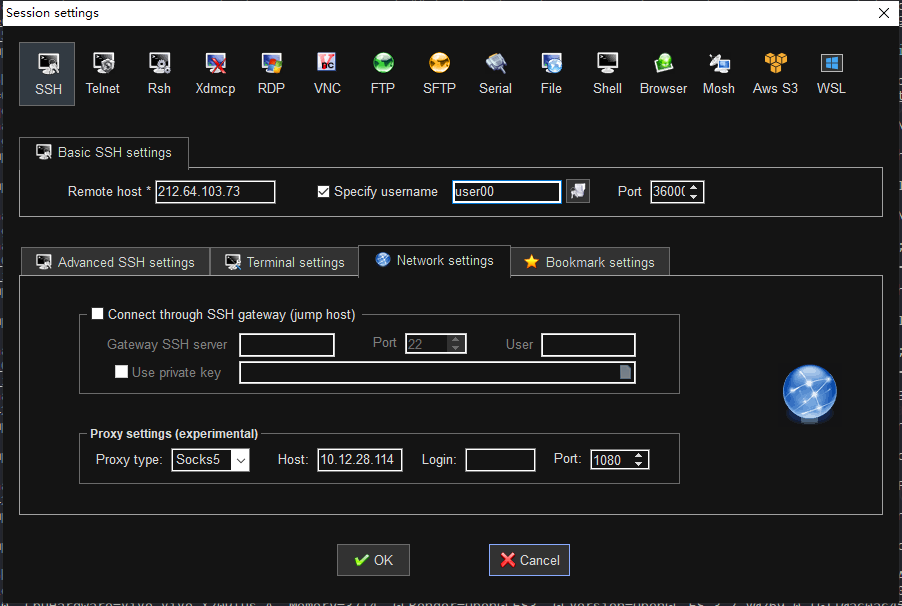](https://imgtu.com/i/6QUzVI)
2. 受限场景2:到**控制面板-->Internet选项-->连接-->局域网设置-->代理服务器-->高级** 里设置socks代理,然后使用IE或Edge浏览器访问蓝鲸运维平台
[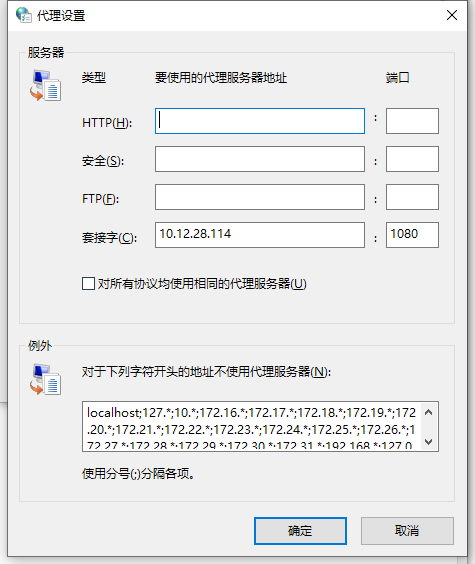](https://imgtu.com/i/6QUvqA)
3. 受限场景3:由于jenkins slave机器是windows 7系统,本身没有集成OpenSSH Client组件,因此考虑在slave上安装ssh客户端,最终考虑使用git附带的Unix tools中的ssh功能(安装时需要把Unix tools加入环境变量),在<code>%USERPROFILE%/.ssh/config</code>内增加ProxyCommand命令行进行代理,命令如下:<code>ProxyCommand connect -S 10.12.28.114:1080 %h %p</code> 如果要是用http代理,需要把**-S**改为**-H**,回到jenkins配置界面,配置scp命令拷贝版本即可。
## ELK
1. 常用指令:
> ``` bash
> curl --user elastic:changeme -XDELETE "http://localhost:9200/*" #清空所有index
> curl -H "Content-Type: application/json" --user elastic:changeme -XGET "http://localhost:9200/_cluster/health" |json_pp #健康检查
> ```
2. 单机状态下,分片数量设置为1即可,因为技术上来说,一个主分片最大能够存储 Integer.MAX_VALUE - 128 个文档([ElasticSearch权威指南](https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html)),且副本数量设置为0,例如
> ``` bash
> curl -H "Content-Type: application/json" --user elastic:changeme -XPUT "http://localhost:9200/_template/template_tlog" -d '{"index_patterns":["logstash-tlog-*"],"settings":{"number_of_shards":1,"number_of_replicas":0}}'
> ```
## 软件设置
1. Discord设置代理:
* Update.exe的同目录增加Update.exe.config,内容为:
``` xml
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
</configSections>
<system.net>
<!--Configure fiddler local proxy-->
<defaultProxy>
<proxy autoDetect="false" bypassonlocal="false" proxyaddress="http://127.0.0.1:7890" usesystemdefault="false" />
</defaultProxy>
</system.net>
</configuration>
```
* 桌面快捷方式调整,增加代理参数:<code>C:\Users\zhengtongshan\AppData\Local\Discord\Update.exe --processStart Discord.exe --a=--proxy-server=http://127.0.0.1:7890</code>
2. 群晖设置免密登录后仍然要求输入密码,解决方案:
``` shell
cd ~/../ && sudo chmod 755 * && sudo chmod -R 755 ~/.ssh
```
3. vps性能测试:`wget -qO- bench.sh | bash`
4. 华硕路由器ssh下开启远程web管理([来源](https://www.snbforums.com/threads/enable-wan-access-to-webui-through-ssh.35047/)):
``` bash
nvram set misc_http_x=1 // set to allow the web access from wan
nvram set misc_httpport_x=80 // set the port for http protocol, change it for your own
nvram set misc_httpsport_x=443 // set the port for https protocol, change it for your own
nvram commit
reboot
```
## AQS
1. Doug Lea在他的[论文](http://gee.cs.oswego.edu/dl/papers/aqs.pdf)中写道:
* JUC同步器框架的主要性能目标是实现可伸缩性,也即:当发生锁竞争时,可预测地保持效率。在理想的情况下,无论多少线程尝试通过同步点,所需的开销都是常量。(更确切的讲)其中一个主要目标是:某一线程被允许通过同步点但还没有通过的情况下,使其耗费的总时间最少。
* 实现同步器的上述目标包含了两种不同的使用类型。大部分应用程序是最大化其总的吞吐量,容错性,并且最好保证尽量减少饥饿的情况(非公平锁)。然而,对于那些控制资源分配的程序来说,更重要是去维持多线程读取的公平性,可以接受较差的总吞吐量(公平锁)。没有任何框架可以代表用户去决定应该选择哪一个方式,因此,应该提供不同的公平策略。
2. AQS队列的head node很特殊,它属于一个**占位node**,其成员变量pre、next、thread都为null,也就是说队列中第2个node才是真正排队的队首。
3. 对于AbstractQueuedSyncchronizer的入队函数:enq,当第一次调用(也即初始化队列)时,内部的for循环至少循环2次,第一次设置head、第二次设置tail。
4. AQS的公平锁实现FairSync中,获取锁的流程为(假定请求锁的线程名为t2):
* 首先尝试获取锁(FairSync::tryAcquire):
* 如果发现state == 0(没有人拿到锁),并且有资格拿锁(也即hasQueuedPredecessors返回false,从字面意思讲,这个函数代表是否有线程在当前线程前面排队中,返回true的条件需要同时满足两个:1、队列已经初始化,2、队列中只有一个占位node(前面有一个node在enq一半时会出现这种情况)**或者**首个排队node的线程不是本线程),则尝试CAS设置state为0,如果设置成功,则获取锁成功并返回。
* 如果发现state != 0,并且当前线程获取了锁,则增加锁的数量,并且获取锁成功并返回。
* 如果没有获取到锁:先CAS入队(AbstractQueuedSynchronizer::addWaiter,重点1),其流程为:
* 检查队列是否已经初始化(tail != null),如果已经初始化则CAS设置当前node为队尾
* 如果队列已经初始化或者上一步CAS设置队尾失败,则自旋进行入队操作(AbstractQueuedSynchronizer::enq)。
* 入队后,开始自旋(AbstractQueuedSynchronizer::acquireQueued),其流程为:
* 先再一次检测能否获取锁(设计思路是:t2入队后,可能前面的线程正好释放了锁,此时t2虽然在队中,但是可能就是队首(也即是队列的第2个node),那就不需要排队)
* 如果还是拿不到;检测是否需要park,检测条件为:pre.waitState == 0(并且前前一个node的waitState是由当前节点修改为0的,为什么呢?因为前一个node已经睡眠中,无法修改自己,有意思!),如果需要(第一次自旋时必然不成立,乐观锁的天性:尽量不park),则调用LockSupport.park阻塞当前线程。
* 如果拿到锁直接返回
4. 一个线程尝试获取ReentrantLock公平锁时,最多会尝试3次获取锁,发生的场景是锁已经被其他线程占有,但是该请求线程是队列的队首,该请求首先会尝试获取,获取失败后,在入队park前会自旋2次尝试获取。最少会1次尝试锁,发生的场景是锁已经被其他线程占有,且该请求线程入队后也不是队首。
## 多线程并发
1. 当一个线程被LockSupport.park挂起后,如果被中断,只是会改变线程内部的终端状态,而不会抛出`InterruptedException`异常,而如果是通过wait或sleep挂起,那么被中断后,会抛出`InterruptedException`异常。
2. <a name="spuriousWakeUp">由于唤醒现象(spurious wakeup)的存在,在执行`Object.wait()`时,应该将其放在while循环中(而非if条件中),例如:(这个例子来源于《Java并发编程之美》,不过看起来是有bug的,因为私自吞掉了InterrupttedException后)</a>
``` java
//生产线程
synchronized(queue) {
//消费队列满,等待队列空闲
while(queue.size() == MAX_SIZE) {
try {
//挂起当前线程,释放queue的对象锁
queue.wait()
} catch(Exception e) {}
}
//空闲则继续生产
queue.add(element);
//通知消费者线程
queue.notifyAll();
}
//消费者线程
synchronized(queue.size() == 0) {
//消费队列为空
try {
//挂起当前线程,释放queue的对象锁
queue.wait();
} catch(Exception e) {}
//消费元素
queue.tak();
//唤醒生产者线程
queue.notifyAll();
}
```
3. 某线程M下调用某个对象A的`Object.wait()`时,线程M进入Waiting状态,同时释放线程M对于对象A的对象锁,但是并不会释放线程M拥有的其他对象的对象锁,因此调用`Object.wait()`时,需要确保该线程M当时没有拥有其他对象锁,否则可能导致死锁的发生。
4. 某线程M下调用某个对象A的`Object.wait()`后,线程M进入Waiting状态,如果在其他线程N下中断线程M:`m.interrupt()`,线程M会抛出`InterruptedException`,也就是说当调用`Object.wait()`后,记得捕获`InterruptedException`异常,这是基本常识。
5. 当`Thread.interrupt()`被调用时:
1. 如果线程因为调用了Object的wait()、wait(long)、wait(long, int)或者调用Thread的join()、join(long)、join(long, int)、sleep(long)、sleep(long、int)而进入`WAITING`或`TIMED_WAITING`的阻塞状态,则**清空**interrupted状态,同时被调用线程抛出`InterruptedException`;
2. 如果线程没有被中断(除了第1条的阻塞外,还包括被`InterruptibleChannel`以及被`java.nio.channels.Selector`阻塞,此处省略不表),则只是简单地**设置**Thread内部的interrupted标记。也就是说,当调用`Thread.interrupt()`时,如果线程没有被阻塞,那么只执行第2条而不会执行第1条,只是简单得给被调用线程发送了一个信号。因此当一个Runable以Thread的形式封装运行过程中,如果run函数是一个while循环,需要随时检测`Thread.isInterrupted`,并决定是否退出,同时要捕获`InterruptedException`,处理在阻塞状态下被中断的情况。更进一步讲,如果线程自己调用了`Thread.interrupt()`,它必定只会执行第2条,而不会执行第1条。([详细说明](https://stackoverflow.com/a/49077093/9878940))。
6. 当捕获到`InterruptedException`时,不要私自吞掉该异常,按照《Java并发编程实战》的建议,要么继续向上传递该异常或者干脆不不捕获该异常,要么重新恢复中断:`Thread.currentThread().interrupt();`
7. 某线程M下调用某个对象A的`Object.wait()`后,线程M进入Waiting状态,当其他线程N拿到对象A的对象锁并调用了`Object.notify()`后,线程M会首先常识获取A的对象锁,如果获取到则从wait出继续执行,否则进入Blocked状态([详细说明](https://javaconceptoftheday.com/difference-between-blocked-vs-waiting-states-in-java/))。
8. Waiting和Blocked状态的区别([详细说明](https://javaconceptoftheday.com/difference-between-blocked-vs-waiting-states-in-java/)):
* 进入条件:当调用`Object.wait()`、`Thread.join()`、`LockSupport.park()`时,进入Waiting状态,当等待对象锁时,进入Blocked状态
* 离开条件:`Object.notify()`、`Object.notifyAll()`时,离开Waiting状态,其他线程释放对象锁时,离开Blocked状态
* 中断条件:Waiting状态可以被中断:`Thread.interrupt()`,Blocked状态不可以被中断(从这个角度讲,Waiting状态更倾向于面对开发人员使用,而Blocked更倾向于面向为JVM使用(个人总结))
8. 线程死锁的4个必备条件:互斥条件、请求并持有条件、不可剥夺条件、环路等待条件。这4个条件中只有请求并持有条件和环路等待条件是可也被破坏的。对于破坏环路等待条件的最佳实践就是所有的线程都使用相同的获取锁的链路,例如获取锁A-->获取锁B-->获取锁C,或者更加暴力地做法就是认人为规定 :同一个线程最多只获取一把锁(这个比较难实现,因为在整个线程堆栈里会调用很多函数,很难确定哪个函数是带锁的调用)。
9. 当`synchronized`升级为重量级锁时,线程会进入Blocked状态而挂起,而由于java的线程模型是用户线程一一对应于内核线程,那么此时需要从用户态切换到内核态执行挂起操作,这会导致非常耗时的CPU上下文切换。这也是之所以java本身提供了语言级的`synchronized`锁后,还会有AQS的出现,后者就是尽量通过CAS自旋避免线程挂起的情况,而随着java版本的不断更新迭代,`synchronized`的性能也逐渐改进。(可以回答为什么有synchronized后还会有AQS,当然这只是基于性能的角度,AQS还有灵活性上的优势)
## 《Java并发编程实战》阅读笔记
1. (2.2.1 竞态条件)静态条件的两种场景类型:“先检查后执行(Check-Then-Act)”和“读取-修改-写入”,例如对于线程安全的Vector,当执行如下代码时:
``` java
if(!vector.contains(element))
vector.add(element);
```
就存在“先检查后执行”的竞态条件。
2. (2.4 用锁来保护状态)一种常见的加锁约定是,将所有的可变状态都封装在对象内部,并通过对象的内置锁对所有访问可变状态的代码路径进行同步,使得在该对象上不会发生并发访问。换一个方式解读就是:如果存在的可变状态多于一个,并且要保证这些可变状态的修改是原子的,那么约定做法就是封装在一个类中,并且对该类进行操作时,都要先获取该类对象的内置锁。
3. (2.5 活跃性与性能)如果只有一个变量需要原子操作,那么使用**Atomic***是很有用的,但是如果多个变量需要原子性操作,那么就比较适合使用同步代码块,并且取消**Atomic***的使用。
4. (3.1.3 加锁与可见性)这一节有一个重要的结论:
> **加锁的含义不仅仅局限于互斥行为,还包括内存可见性**。为了确保所有线程都能看到共享变量的最新值,所有执行读操作或者写操作的线程都必须在同一个锁上同步。
换句话说,加锁有两层用途:互斥排他和内存可见性。而后者是大家很容易忽视的。那内存可见性的一个应用场景就是:某一个线程写,其他线程读,这种情况下不存在并发竞争,而值存在内存可见性的问题。而这种情况下,大部分都是使用**volatile**,这也是为什么加锁的内存可见性的用途被忽视的另外一个原因。
5. (3.2 发布与逸出)构造函数中this逸出的三种场景:
* 在构造函数中new了内部匿名类,那么匿名类中就包含this指针
* 在构造函数中启用了新的线程,并且构造后直接启动
* 在构造函数中调用一个可改写的实例方法时(既不是私有方法,也不是终结方法)
6. (3.3.1 Ad-hoc线程封闭)只要你能确保只有单个线程对共享的volatile变量执行写入操作,那么就可以安全地在这些共享的volatile变量上执行“读取-修改-写入”的操作。在这种情况下,相当于将修改操作封闭在单个线程中以防止发生竞态条件,并且volatile变量的可见性保证还确保了其他线程能看到最新的值。
7. (3.5.1 不正确的发布:正确的对象被破坏)本节中的`AssertionError`异常的例子的简单解释:1、JMM规范中并没有要求对象字段的初始化要happens before与另一个线程对该对象的可见性;2、`if(n != n)`并非一个原子性操作,而需要3步操作,因此会出现第一次读取的n值和第二次读取的n值不相同的情况。而如果将对象的字段改成volatile后就能避免`AssertionError`,这是因为JMM有规范要求:volatile sore要可见于其他线程。关于本节例子的两个很好的补充解释:[知乎](https://www.zhihu.com/question/264579989)、[StackOverflow](https://stackoverflow.com/questions/16107683/improper-publication-of-java-object-reference)
> 由`if(n != n)`这行代码可以联想到一种并发编程易出错场景:某个函数里引用一个会被并发修改的字段,那么可能会出现在函数逻辑过程中发生变化的情况。这就引入了`4.1.2 依赖状态的操作`的内容,已经并发编程的一个基本思想:但在并发程序中,先验条件可能会由于其他线程执行的操作而变成真。在并发程序中要一直等到先验条件为真,然后再执行该操作(死循环加CAS?)。
8. (4.3.3 当委托失效时)虽然AtomicInteger是线程安全的,但经过组合得到的类却不是。也就是说,如果一个类中的字段即使都是线程安全的,但是这个类也不一定是线程安全的。当这些字段之间存在某些不变性条件时,就会导致“先检查后执行”操作的出现。而这是前面所讲的竞态条件的一种常见场景。
9. (4.3.5 示例:发布状态的车辆追踪器)注意本节的批注[1],很重要但是很容易忽视的一个并发编程错误场景!
10. (5.1.3 隐藏迭代器)Synchronized\*容器的`toString`、`hashCode`、`equals`函数会调用迭代器,因此在调用这些方法时,记得加锁,例如记录日志时或者将这些容器作为另一个容器的key或value时。这都是很容易忽视的!否则在迭代的过程中如果其他线程执行了并发增删操作,很有可能抛出`ConcurrentModificationException`。另外Synchronized*容器没有`putIfAbsent`之类的函数,如果要实现类似的**检查并执行**的操作,需要自己加锁!或者使用专用的并发容器,例如:ConcurrentMap
11. (5.4 阻塞方法与中断方法)当捕获到`InterruptedException`时,不要私自吞掉该异常,要么继续向上传递该异常或者干脆不不捕获该异常,要么重新恢复中断:`Thread.currentThread().interrupt();`
12. (5.5 同步工具类)闭锁(CountDownLatch):属于消耗性的只减不增的递减计数器,计时器为零时解锁;FutureTask:属于特殊的二元闭锁,运行中时阻塞,运行结束时解锁;信号量(Semaphore):属于池化的计数器,可赠可减,当池中计数器为0时阻塞,可以用任何容器加Semphore组合为有界容器。栅栏(CyclicBarrier):可以复用的递增计数器,初始化时,计数器为0,计数器未满时阻塞,计时器满时解锁,并且重置计数器。Exchanger:特殊的两方栅栏,任何一方都先发起交换请求,等待另一方响应后,交换达成,适用于读写线程进行无GC的缓冲交换(示例:[baeldung](https://www.baeldung.com/java-exchanger))。
13. (7.1.1 中断)对中断的正确理解是:它并不会真正地中断一个正在运行的线程,而是发出中断请求,然后由线程(自己决定)在下一个合适的时刻中断自己。**通常,中断是实现取消的最合理方式。**这句话的意思是,程序不需要自己顶一个类似volatile的cancelled的状态,并轮询检测该状态,已决定是否取消。如果采用中断的方式,那么可以调用:inerrupt(),如果线程处于阻塞中,会收到`InterruptedException`,如果处于非阻塞中,其interrupted状态会被标记。因此完整的程序框架类似于:
``` java
class MyThread extends Thread {
public void run() {
try {
while(!Thread.currentThread().isInterrupted()) {
//执行业务逻辑
}
}
catch(InterruptedException e) {
//线程退出
}
}
public void cancel() {interrupt();}
}
```
14. (7.1.2 中断策略)这一节有时间再继续消化!
15. (7.1.5 通过Future来实现取消)`Future.get(long, TimeUnit)`会返回4种异常,需要对这4种异常进行进行处理,特别是`InterruptedException`,不要私自吞掉!当一个Future已经完成后,再次调用cancel也不会有什么影响。
16. (7.1.7 通过newTaskFor来封装非标准的取消)这一节主要讲了一件事:如果想在执行`Future.cancel`时执行额外的操作,那么:1、集成Callable接口,实现自己的Callable;2、继承`ThreadPoolExecutor`,重写newTaskFor函数,如果发现不是自己实现的Callable,那么调用super,否则返回一个自己实现的FutureTask,这个FutureTask的cancel函数先执行自己的一些操作,然后再调用super。
17. (7.2 停止基于线程的服务)一个重要的概念:只有线程的所有者有权关闭线程,而线程池是其工作线程的所有者。
18. (8.1.1 线程饥饿死锁)在单线程的Executor中,如果任务一将任务二提交到同一个Executor,那么会导致饥饿死锁!而在多线程的Executor中,如果这种现象比较多,也可能发生死锁。因此有一条规则:不要在同一个Executor中递归提交任务。当Executor A依赖Executor B时,A的有效线程数量(有可能)实际上隐式地依赖于B的线程数量。例如某逻辑线程池使用了包含10个连接的JDBC线程池。
19. (8.2 设置线程池的大小)对于计算密集型任务,线程池的大小为**CPU数量 + 1**时,能实现最优利用率。而对于IO密集型线程池大小的评估公式为:**CPU数量 \* CPU利用率(大于等于0且小于等于1)\* ( 1 + IO等待时间 / 计算时间)**
20. (12.3.5 无用代码的消除)在性能测试过程中,有一些技巧可以避免编译器对某些无用的代码进行消除,大致思路就是保证计算结果被使用,但是不要引入IO操作,而导致了性能偏差。下面的例子是一个很好的技巧:
``` java
if(foo.x.hashCode() == System.nanoTime())
System.out.print(" ");
```
这段代码绝大数情况下不会成功,即使成功,也只是输出一个空字符。
21. (14.2.2 过早唤醒)Object的内置对象锁存在一个条件队列,而唤醒这个条件队列的**条件谓词**可能不止一个,也就是说导致唤醒一个Object线程的条件不止是一个,因此当Object在wait后被唤醒时,仍然需要继续检测当时导致wait的同一个条件谓词,这也从另外一个角度说明了为什么要循环检测条件谓词(另外一个条件是:[唤醒现象的发生](#spuriousWakeUp))
22. (14.2.4 通知)**每当在等待一个条件时,一定要确保在条件谓词变为真时通过某种方式发出通知。**换句话说:wait和notify(notifyAll)一般都是在同一个函数内成对出现?另外由于同一个条件队列可以对应于多个条件谓词,因此尽量使用notifyAll而非notify(如果非得使用notify,需要满足两个条件:1、唯一条件谓词:条件谓词只有一个;2、单进单出:最多只能唤醒一个线程来执行,换句话说就是唤醒后,只有一个线程可以继续工作,剩下的线程会竞争失败而继续wait),否则会面临信号丢失的风险。
23. (14.2.5 示例:阀门类)这一节的例子中,generation字段可以理解为批次,用一个形象的比喻就是这个Gate前可以等待一批又一批的线程,在await函数里,当线程被notifyAll后,当且仅当门是关闭状态并且当前的批次还是自己等待时的批次,才会再次wait(如果门已经开启,或者已经换了批次,那就证明gate肯定是开过,那我必须过去!)。
24. (14.3 显示的Condition对象)与内置锁和条件队列一样,当使用显示的Lock和Condition时,也必须满足锁、条件谓词和条件变量之间的三元关系。在条件谓词中包含的变量必须有Lock来保护,并且在检查条件谓词以及调用await和signal时,必须持有Lock对象。
25. (15.3 原子变量类)原子标量类(AtomicInteg、AtomicLong、AtomicBoolean、AtomicReference)没有重新定义hashCode和equals方法,因此每一个实例都是不同的,因此也不适用于做散列容器的键值。
## 《深入理解Java虚拟机》阅读笔记
1. (2.2 运行时数据区域)jvm内存划分为5个区域,简单说就是2个堆(堆和非堆(方法区的别称))、2个栈(虚拟机栈和本地方法栈)、1个程序计数器
2. (2.2.5 方法区)方法区和永久代的区别在于(JDK 8以前),前者是java虚拟机规范的定义,而永久代是HotSpot虚拟机下特有的实现,且属于方法区的一部分,这么设计的目的就是为了垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的 工作。
3. (2.3.1 对象的创建)本节讲到:**由字节码流中new指令后面是否跟随invokespecial指令所决定,Java编译器会在遇到new关键字的地方同时生成 这两条字节码指令**,验证测试代码如下所示:
``` java
package com.example.demo.test;
public class Test2 {
public static void main(String[] args) {
final Test2 test2 = new Test2();
System.out.println(test2);
}
}
```
执行:<code>javac Test2.java</code>,然后执行:<code>javap -v Test2.class</code>查看字节码文件,输出内容为:
``` bash
Classfile /mnt/f/Develop/Project/demo/src/main/java/com/example/demo/test/Test2.class
Last modified Dec 14, 2020; size 436 bytes
MD5 checksum b6b5fa11a474d65891c6991ba0d7143a
Compiled from "Test2.java"
public class com.example.demo.test.Test2
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Class #16 // com/example/demo/test/Test2
#3 = Methodref #2.#15 // com/example/demo/test/Test2."<init>":()V
#4 = Fieldref #17.#18 // java/lang/System.out:Ljava/io/PrintStream;
#5 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/Object;)V
#6 = Class #21 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 Test2.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Utf8 com/example/demo/test/Test2
#17 = Class #22 // java/lang/System
#18 = NameAndType #23:#24 // out:Ljava/io/PrintStream;
#19 = Class #25 // java/io/PrintStream
#20 = NameAndType #26:#27 // println:(Ljava/lang/Object;)V
#21 = Utf8 java/lang/Object
#22 = Utf8 java/lang/System
#23 = Utf8 out
#24 = Utf8 Ljava/io/PrintStream;
#25 = Utf8 java/io/PrintStream
#26 = Utf8 println
#27 = Utf8 (Ljava/lang/Object;)V
{
public com.example.demo.test.Test2();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: new #2 // class com/example/demo/test/Test2
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
11: aload_1
12: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/Object;)V
15: return
LineNumberTable:
line 6: 0
line 7: 8
line 8: 15
}
SourceFile: "Test2.java"
```
上述输出中,第54行为源码第6行的<code>final Test2 test2 = new Test2();</code>,第56行就是文中说的invokespecial。
4. (2.3.2 对象的内存布局)源码地址:[jdk8](http://hg.openjdk.java.net/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/oops/markOop.hpp)
| Mark Word(64 bits) | 锁状态 |
| -----------------------------------------------------------: | :------: |
| unused:25 \| hash:31 \| unused:1 \| age:4 \| biased_lock:0 \| lock:01 | 正常 |
| thread:54 \| epoch:2 \| unused:1 \| age:4 \| biased_lock:1 \| lock:01 | 偏向锁 |
| ptr_to_lock_record:62 \| lock:00 | 轻量级锁 |
| ptr_to_heavyweight_monitor:62 \| lock:10 | 重量级索 |
| \| lock:11 | GC标记 |
当开启指针压缩(UseCompressdOops)时,正常状态和偏向锁状态下的两个unused字段会变成:cms_free,具体参考:[stackoverflow](https://stackoverflow.com/questions/60985782/details-about-mark-word-of-java-object-header)
5. (2.3.3 对象的访问定位)句柄访问和直接指针访问的本质区别在于:前者是间接引用(相当于中间又增加了一层,从而带来了更好的灵活性),后者是直接引用。
6. (2.4.2 虚拟机栈和本地方法栈溢出)经测试64位Linux下Xss最小值为:228k,默认值为:1024K(64位Windows 10下,两个值分别为:108K和0)
``` bash
java -Xss128K com.example.demo.test.Test2
The stack size specified is too small, Specify at least 228k
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
java -XX:+PrintFlagsFinal -version | grep ThreadStackSize
intx CompilerThreadStackSize = 0 {pd product}
intx ThreadStackSize = 1024 {pd product}
intx VMThreadStackSize = 1024 {pd product}
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (build 1.8.0_275-8u275-b01-0ubuntu1~18.04-b01)
OpenJDK 64-Bit Server VM (build 25.275-b01, mixed mode)
```
> TIPS:
>
> * 如果运行程序出现了OutOfMemoryError异常,发生的区域很小的几率发生在虚拟机栈(主要发生区域是堆),理由是:HotSpot虚拟机不支持栈的动态扩展,所以线程运行期间不会申请内存扩展,从而不会导致OOM,那么只会出现在创建线程申请内存时出现OOM,有3种措施会可以促进这种OOM:1、虚拟机栈空间尽量小;2、每个线程的栈内存尽量大(Xss);3、创建的线程足够多。更详细地说,如果是在32位Windows系统下,由于单个进程最大内存限制是2G,那么排除掉Xmx的堆最大容量、直接内存、jvm本身消耗内存以及程序计数器(可以忽略不计)内存,剩下的内存才是虚拟机栈和本地方法栈的可用内存,如果虚拟机栈内存足够小,而且Xss配置得又偏大,那么,如果创建非常多线程的情况下,是有可能出现创建线程时导致虚拟机栈OOM的。
> * 如果允许程序出现了StackOverflowError异常,比较大的可能性是递归调用导致了栈溢出,比较小的可能性是因为调用堆栈过深导致栈溢出,因为对于后者来说,默认Xss的大小为1024k,是很难导致溢出的。
7. (2.4.3 方法区和运行时常量池溢出)自JDK 7起,原本存放在永久代的字符串常量池被移至Java堆之中
8. (2.4.4 本机直接内存溢出)OOM后,dump文件比较小,而且又使用的Direct Memory,那么就要考虑是否是直接内存OOM
9. (3.2.3 再谈引用)强引用:打死也不能回收;软引用(SoftReference):OOM前回收;弱引用(WeakReference):下次GC时回收;虚引用(PhantomReference):根本不算引用,因为无法获得引用对象,应用场景:为了能在这个对象被收集器回收时收到一个系统通知。
10. (3.3.1 分代收集理论)
* 垃圾分代收集的本质在于对象的年龄。朝生夕灭的小鲜肉放在一起管理(称之为年轻代),相亲无数(也就是躲过了多次垃圾回收)的大龄青年(称之为老年代)放在一起管理,这可真够现实的。
* 除了CMS收集器,其他都不存在只针对老年代的收集
11. (3.3.2 标记-清除算法(Mark-Sweep))原理:标记处房间内的垃圾,然后直接清理掉,缺点:房间还是很乱(内存碎片),因为只清理了垃圾,而没有整理房间
12. (3.3.3 标记-复制算法(Mark-Copy))多用于年轻代垃圾收集器,原理:
* 基础版:房间分成两部分,每次只用其中一部分,每次回收时,清理垃圾,并将物品搬到另一个房间,缺点:浪费空间。
* 进阶版:房间分成三部分,一大两小(8:1:1),每次只用一大和一小,每次回收时,清理垃圾,并将物品搬到另一个房间
13. (3.3.4 标记-整理算法(Mark-Compact))多用于老年代垃圾收集器,原理:在标记-清除算法的基础上,额外增加整理(更形象的说,是“压缩整理”,从标记-整理算法的英文名:Mark-Compact就能看出来)的功能。
> TIPS:
>
> * 对于CMS收集器,平时多数时间都采用(并发)标记-清除算法,这也应对CMS的全称:Concurrent Mark Sweep,当空间碎片过多时采用标记-整理算法。这也对应CMS算法的缺点:1、容易产生内存碎片;2、一旦由于碎片过多触发了标记整理算法,就会导致长时间的STW
14. (3.4.2 安全点)安全点停顿:几乎所有虚拟机不再采用抢先式中断(Preemptive Suspension)而是采用主动式中断(Voluntary Suspension),也即虚拟机负责设置标记位,各个线程负责轮询检查标记位,然后运行到安全点上(有点类似于游戏服务器的某个全局模块设置标记位,在线玩家心跳逻辑里轮询检测这个标记位)。
15. (3.4.4 记忆集与卡表)通俗地讲,从垃圾收集区域来看,Remembered Set指的是谁指向了我的集合(如果有人指向了我,那么这个“我”就不能当做垃圾被回收)!这是一个抽象的逻辑概念模型。从具体实现的角度来看,最原始的Remembered Set就是存储对方所有跨带引用对象的集合,但是这是非常低效的,因此可以把这个“我”的区域(也即垃圾收集区域)划分成若干子区域(每个区域称之为卡页:Card Page),然后用一个数组标记该区域是否含有跨代引用指针(这个数组就是卡表:Card Table),在GC时将Card Table中存在跨代引用的Card Page进行扫描,从而减少GC Roots的扫描的范围(这种分组的思想是不是很熟悉,想一下武汉市在医疗资源紧缺时采取的新冠核酸筛的混检模式,就是讲每10人混合成一个样本,筛查效率理论上可以提升到原来的10倍)。
16. (3.4.5 写屏障)这一节讲了两件事:
* 卡表的状态维护机制:写屏障,通俗讲就是虚拟机层面的AOP
* 当多线程写同一块内存时,如果这块内存被同一个缓存行的卡表对应,那么意味着这个位于同一个缓存行的卡表会被多个线程修改,导致性能降低,优化机制为:不要无条件修改卡表,而是加一个判断(额,这个优化真的非常非常初级啊)
17. (3.4.6 并发的可达性分析)
* 三色标记:白色:还未过安检;黑色:已经过安检,安全;灰色:安检中
* 两种条件同时满足时,会出现白色误判为垃圾:1、扫描期间某黑色新指向了白色对象;2、同时某灰色到该白色的直接或间接引用也恰巧删除。这就导致了该白色对象仅被黑色对象引用,而黑色对象是安全的,不会再次扫描,这就导致错过扫描而被误判为垃圾。举一个形象的例子:三个包过机场的安检仪:黑包--灰包--白包这3个包用绳子相继连着,此时黑包已过安检,灰包安检中,白包等待安检,突然风雨突变,灰包和白包的绳子莫名断掉,同时有一股神秘力量将黑包和小白连起来(来自用户线程),但是这个连线却没穿过安检仪,那这种情况下白包就会错过安检(这个例子真是绝,我真是大聪明!)
* 消除白色误判的两种策略:1、破除上述条件一,也即增量更新(Incremental Update):如果黑色在扫描期间指向了白色,那就让它变灰;2、破除上述条件二,也即原始快照(Snapshot At The Beginning, SATB):先拍个照,当进行扫描时,不管灰色是否删除了白色的指向,都按照这个快照扫描。CMS是基于增量更新,G1、Shenandoah则是用原始快照。
18. (3.5.6 CMS收集器)
* 收集过程分成4个阶段:
1. 初始标记(CMS initial mark):标记GC Roots能直接关联到的对象,会引发短暂的STW
2. 并发标记(CMS concurrent mark):也即三色标记阶段,会导致某些白色被误判垃圾,也会导致漏过某些白色而产生浮动垃圾
3. 重新标记(CMS remark):采用增量更新策略,重新标记,会引发STW
4. 并发清除(CMS concurrent sweep):这也是CMS名称的由来,并发清除(concurrent sweep)
* 缺点:
1. 并发标记对CPU敏感(默认GC线程数=处理器核心数量 +3)/ 4):CPU核心数大于等于4个时,并发标记线程数不超过25%,当并发线程数小于4个时,有一半运算能力执行GC,因此CPU敏感。
2. 由于GC过程中浮动垃圾无法收集(要留到下一次),因此需要为老年代预留出一部分空闲空间(-XX:CMSInitiatingOccupancyFraction,JDK 6以后该默认值从JDK 5的68%提升至92%),防止并发失败(Concurrent Mode Failure)导致临时启用Serial Old。
3. CMS正如它的名字所示,属于标记清除算法,因此在GC结束后会导致大量内存碎片。当申请大对象内存时,可能会出现内存碎片过多无法分配,导致提前触发Full GC(有两个参数:-XX:+UseCMSCompactAtFullCollection和-XX:CMSFullGCsBeforeCompaction可以相对改善,具体细节可以使用时查看相关资料)。
> TIPS:
>
> * 所有收集器中只有CMS有针对老年代的Old GC
19. (3.5.7 Garbage First收集器)
* JDK 7 Update 4时,G1的”Experimental“的标识被移除,到JDK 8 Update 40,提供类卸载的支持,变成了Oracle官方称为“全功能的垃圾收集 器”(Fully-Featured Garbage Collector)
* G1的Remembered Set结构:由于存在多个Region,而每个Region都要维护的Remembered Set都需要存储谁引用了我,因此Remembered本质上是哈希表,key为其他Region的起始地址,value为一个集合,存储的是该Region中卡表的索引号。这存在两个问题:1、Remembered Set是一个双向索引,这维护起来就麻烦了;2、Remembered Set比较多,因此要消耗额外的堆内存,大约在10%~20%之间。
* Region中有一部分内存用于GC并发回收中的对象分配,这个区域都位于TAMS(Top at Mark Start)指针之上。G1默认TAMS地址以上的对象都是存活的,不进行GC。
* G 1停顿预测模型一句话总结:每个Region进行回收统计,包括:回收耗时、Remember Set中脏卡数量等,G1根据每个Region的统计状态的新旧评价回收价值,并预测哪些Region集合可以在-XX:MaxGCPauseMillis内回收时获得最高收益。
* 收集过程同样(相对于CMS)分成4个阶段:
1. 初始标记(Initial Marking):标记GC Roots能直接关联到的对象,还要额外(相对于CMS)修改TAMS指针的值,会引发短暂的**STW**
2. 并发标记(Concurrent Marking):也即三色标记阶段,还要额外重新处理SATB记录上并发标记期间引用改动的对象。
3. 最终标记(Final Marking):短暂的**STW**,处理上一步中遗留的少量的SATB记录。
4. 筛选回收(Live Data Counting and Evacuation):1、更新Region的统计数据,并根据统计价值和成本进行排序;2、筛选Region回收集合;3、把回收Region集合中的存活对象移动到空的Region中,然后清空所有回收集合Region全部空间,由于需要移动存活对象,因此会引发**STW**,但是会多线程并行完成。
* 从G1开始,垃圾收集器的设计导向发生变化:追求全堆清理转向追赶内存分配速率(Allocation Rate)。我个人把这个新原则称之为遇熊逃命原则,也即不追求跑得最快,只要求不是最慢即可,换到GC角度上,那就是只要应付得了内存分配的速率即可。只要我打扫垃圾的速度比你制造垃圾的速度足够快,足以。这个理念非常牛B啊,所以才说G1是收集器的一个里程碑。
> TIPS:
>
> * 按理来说,G1是全堆回收的,那为什么仍然存在年轻代和老年代?个人推测是因为仍然沿用了HotSopt垃圾分代框架,而书中也多次用了“扮演新生代”或“扮演老年代”的说法,这也可以证明这个推测。
>
> * 书中没讲到的G1的思想:G1实际上采取的是分治算法的思想,将大问题分解成小问题,逐个击破。从整体上讲,它属于标记-整理算法(根据前文内容,整理算法是让所有存活对象移动到内存一端,如果按照这个标准,那G1整体上并非严格意义上的标记-整理算法),而从局部上讲,又属于标记复制算法(Region A移动到Region B)。
20. (3.6 低延迟垃圾收集器)
* Shenandoah和G1的3个不同之处:
* 支持并发整理算法,G1在第4个阶段进行筛选回收时,是多线程并行处理,但是不会并发。
* 默认不使用分代收集,不存在新生代和老年代的Region
* 将G1的Remembered Set改为连接矩阵(Connection Matrix):降低维护成本,也降低伪共享的发生概率。
* Shenandoah收集过程:
* 初始标记(Initial Marking),标记GC Roots能直接关联到的对象,会引发短暂的与堆大小无关的**STW**
* 并发标记(Concurrent Marking):与G1一样,并发且并行
* 最终标记(Final Marking):与G1一样,处理剩余的SATB扫描,引发短暂的**STW**
* 并发清理(Concurrent Cleanup):清理连一个存活对象都没有找到的Region
* 并发回收(Concurrent Evacuation):这是Shenandoah的核心改进,通过读屏障和Brooks Pointers转发指针实现并发回收。
* 初始引用更新(Initial Update Reference):确保上一个并发回收阶段的线程都已经完成对象移动任务,会引发**STW**。
* 最终引用更新(Final Update Reference):修正存在于GC Roots 中的引用,最后一次引发**STW**,停顿时间只与GC Roots数量有关。
* 并发清理(Concurrent Cleanup):清理Immediate Garbage Regions。
> TIPS:
>
> * 本节开头提了:内存占用(Footprint)、吞吐量(Throughput)、延迟(Latency)组成了三元悖论,意指三者只能得其二,类似的三元悖论还有很多,例如分布式系统中著名的CAP定理:一致性(**C**onsistency)、可用性(**A**vailability)、分区容忍性(**P**artition Tolerance)。详情可以参考:周大的另外一本[开源书籍](https://icyfenix.cn/architect-perspective/general-architecture/transaction/distributed.html#cap%E4%B8%8Eacid)或[IBM Cloud Learn Hub](https://www.ibm.com/cloud/learn/cap-theorem)
> * Shenandoah将Remembered Set改为连接矩阵,从数据管理的视角上来看,实际上是把数据分散处理调整为全局集中处理,这也符合数据驱动开发的思想。例如在游戏开发领域,双向游戏好友是比较常见的社交功能,相比于把好友数据存储到每个玩家身上,维护一系列全局的好友关系数据将是更好的选择。因为如果使用前一个方案,那么在分布式环境下,单就数据一致性的这个问题,就会要求架构底层需要很好的支持,功能逻辑的复杂性也会大大增加。
> * Brooks Pointer通过CAS操作保证并发时对象访问的正确性,CAS真是并发编程一大神器啊!
21. (3.6.2 ZGC收集器):
* Region分成3种:Small Region(2MB,存储<256KB对象)、Medium Region(32MB,存储>=256KB&&<4MB 对象)、Large Region(2MB的整数倍,最小为4MB,存储>=4MB对象)
* Shenandoah收集过程:
* 并发标记(Concurrent Mark):操作与G1、Shenandoah类似,也会引发**STW**,区别在于标记是在指针上而不是在对象上进行的,标记阶段会更新染色指针中的Marked 0、Marked 1标志 位。
* 并发预备重分配(Concurrent Prepare for Relocate):1、根据特定的查询条件统计得出 本次收集过程要清理哪些Region,将这些Region组成重分配集(Relocation Set);2、类卸载和弱引用处理(从JDK 12开始支持)。
* 并发重分配(Concurrent Relocate):复制Relocation Set中的存活对象到新Region,每个Region维护转发表(Forward Table),记录转发关系。并发期间,如果对象访问,由于染色指针的存在,ZGC知道该对象是否处于Reloaction Set,因此会被内存屏障截获,转发到新Region上,并同时更新引用(指针自愈)。
* 并发重映射(Concurrent Remap):重映射所做的就是修正整个堆中指向重分配集中旧对象的所 有引用。实际上即使没有这一步,这些对象也可以在之后的访问时,通过指针自愈实现重映射。ZGC将此工作合并到下一次垃圾收集循环的并发标记阶段中,从而更加节省了一次对象图的遍历。
> TIPS:
>
> * 在上述第3个“并发重分配”过程,当复制Relocation Set中的存活对象到新Region时,周大没有详述实现细节,推测应该有类似的CAS操作来更新对象指针的染色指针,这是一个小遗憾。
> * 根据上述第4个“并发重映射”过程的描述,其过程被合并到下一次GC中,那ZGC岂不是只有3个大的过程?这是一个不太大的疑惑点。
22. (3.8.5 空间分配担保)在JDK 6 Update 24以前,当老年代最大连续可用空间小于新生代所有对象总和时,两种情况下会触发Full GC:
* -XX:+HandlePromotionFailure允许担保失败,但是老年代最大可用的连续空间是否小于历次晋升到老年代对象容量的平均大小
* -XX:-HandlePromotionFailure不允许担保失败
> TIPS:
>
> 在JDK 6 Update 24之后,HandlePromotionFailure参数已经被去掉,测试代码:
>
> ``` bash
> ☺ java -XX:+PrintFlagsFinal -XX:+HandlePromotionFailure -version
> Unrecognized VM option 'HandlePromotionFailure'
> Did you mean '(+/-)PromotionFailureALot'?
> Error: Could not create the Java Virtual Machine.
> Error: A fatal exception has occurred. Program will exit.
> ```
>
> 上述规则调整为:只要老年代的连续空间大于等于新生代对象总大小或者历次晋升的平均大小,就会进行 Minor GC,否则将进行Full GC,换言之只有这两个条件同时满足,蔡楚发Full GC。
23. (4.2.2 jstat:虚拟机统计信息监视工具):远程虚拟机进程的VMID为:\[protocol:\]\[//\]lvmid[@hostname[:port]/servername]
24. (7.3.5 初始化)关于代码清单7-6中,字段B的值将会是2而不是1:
``` java
static class Parent {
public static int A = 1;
static {
A = 2;
}
}
static class Sub extends Parent {
public static int B = A;
}
public static void main(String[] args) {
System.out.println(Sub.B);
}
```
书中的解释并不是很彻底,可以使用javac编译,然后借助<code>javap -v</code> 命令得到更清新的答案,其Parent的javap命令解析如下:
``` bash
javap -v StaticMethod\$Parent master ✗
Warning: Binary file StaticMethod$Parent contains com.example.demo.test.StaticMethod$Parent
Classfile /mnt/f/Develop/Project/demo/src/main/java/com/example/demo/test/StaticMethod$Parent.class
Last modified Dec 24, 2020; size 399 bytes
MD5 checksum 0f4fdfb9857a60ee769dbb6b4a2f3a0d
Compiled from "StaticMethod.java"
class com.example.demo.test.StaticMethod$Parent
minor version: 0
major version: 52
flags: ACC_SUPER
Constant pool:
#1 = Methodref #4.#14 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#15 // com/example/demo/test/StaticMethod$Parent.A:I
#3 = Class #17 // com/example/demo/test/StaticMethod$Parent
省略……
{
省略……
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: iconst_1
1: putstatic #2 // Field A:I
4: iconst_2
5: putstatic #2 // Field A:I
8: return
LineNumberTable:
line 6: 0
line 8: 4
line 9: 8
}
SourceFile: "StaticMethod.java"
InnerClasses:
static #18= #3 of #16; //Parent=class com/example/demo/test/StaticMethod$Parent of class com/example/demo/test/StaticMethod
```
通过上述代码可以发现,Line 54-55应对与源码中的类变量的定义:<code>public static int A = 1;</code>,而Line 56-57应对与有静态语句块中的赋值:<code>A = 2;</code>,也就是说:**编译后的static静态语句块除了包含程序员的逻辑代码,还额外插入了编译器自动生成的对静态变量初始化的代码**,且这些插入代码的位置符合如下原则:**如果静态变量定义在static静态语句块上面,那么在程序员逻辑代码上面按照声明顺序插入,否则在程序员的逻辑代码下面按照声明顺序插入**。当Parent类完成**初始化**后,成员变量A的值为2,当Sub类进行初始化时,要调用自己的<code>\<clinit\>()</code>,按照文中所述:**Java虚拟机会保证在子类的()方法执行前,父类的()方法已经执行 完毕。**Sub进行初始化时A的值已经是2,因此赋值给B后就是2了。
25. (7.4.2 双亲委派模型)
> “双亲委派”这个术语实在是翻译得败笔,根据[知乎](https://www.zhihu.com/question/24923480)上一个比较形象的回答,翻译为“啃老模式”更为形象。也就是说遇到类加载请求时,先让父加载器去加载,父加载器加载不了了自己才去加载。
26. (8.3.1 解析)静态方法、私有方法、实例构造器、父类以及final方法(由于历史设计的原因,final方法是使用invokevirtual指令来调用)在类加载的时候就可以把符号引 用解析为该方法的直接引用。这些方法统称为“非虚方法”(Non-Virtual Method)
27. (8.3.2 分派)
> * 静态分派对应的是方法的重载(Overload),动态分配对应的是类的重写(Override)。
> * 当子类声明了与父类同名的字段时,虽然在子类的内存中两 个字段都会存在,但是子类的字段会遮蔽父类的同名字段
28. (8.4.3 java.lang.invoke包)一句话解释Reflection和MethodHandle的区别:Reflection是重量级,而MethodHandle 是轻量级。
29. 主内存与工作内存之间具体的交互协议:
[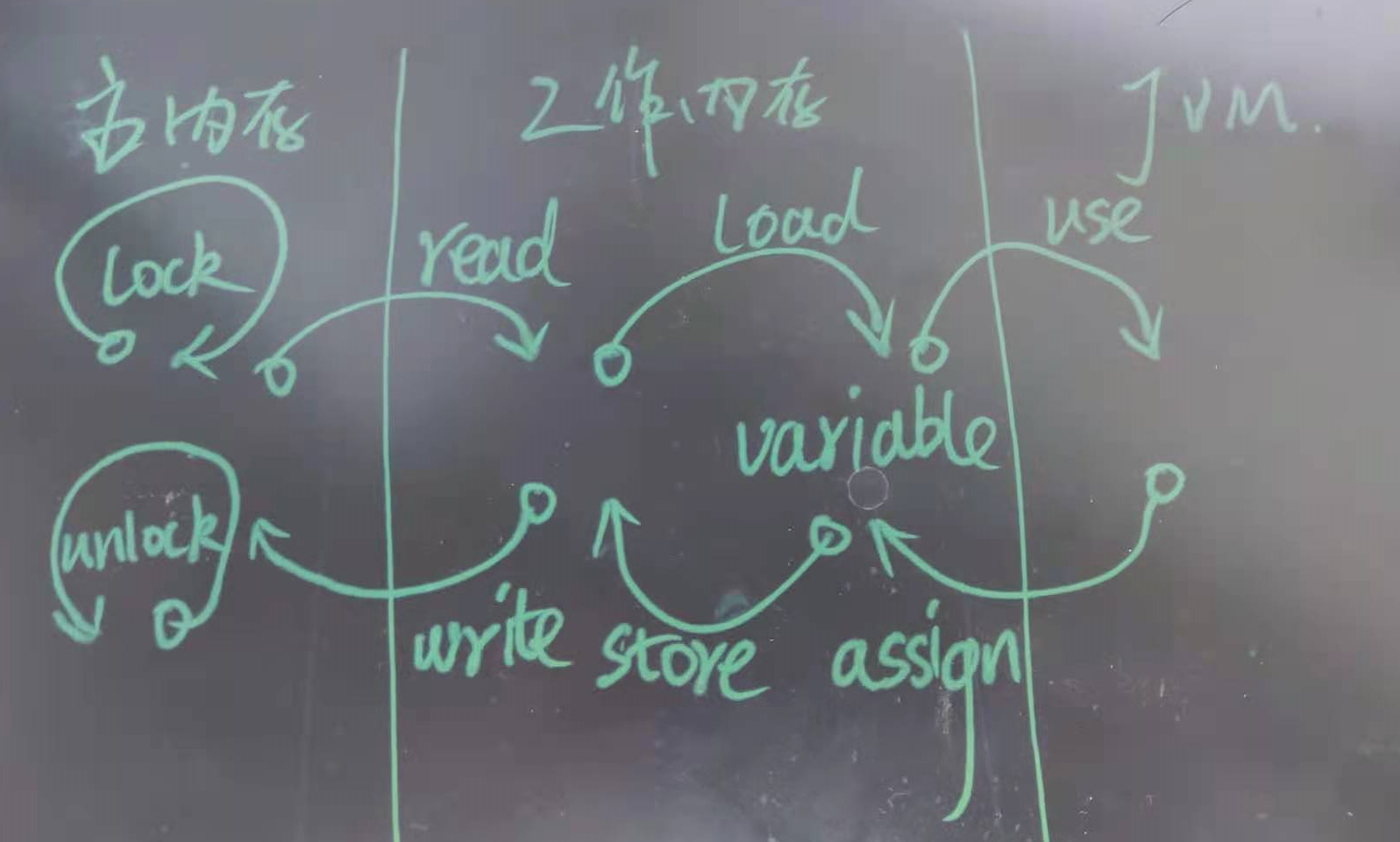](https://imgtu.com/i/6QaSat)
15. 对于普通变量(相对于volatile变量):要求read/load、write/store**成对**、**顺序**出现,但是允许不连续出现(也即中间可以插入其他指令)。
16. 对于volatile变量:
* 只有当前一个指令是load时,才允许执行use;且只有后一个动作是use时,才能执行load动作。换句话说:额外要求load和use是**连续成对**出现的,结合上面第2条,那就是use/load/read一条龙。这条规则要求在工作内存中,每次使用volatile变量前都必须先从主内存刷新最新的值,保证能看见其他线程对该变量的修改。
* 只有当前一个指令是assign时,才允许执行store;且只有后一个动作是store时才能执行assign动作。换句话说:额外要求assign和store是**连续成对**出现,结合上面第2条,那就是assign/store/write一条龙。这条规则要求在工作内存中,每次修改volatile变量后都必须立刻同步回主内存中,用于保证其他线程可以看到自己对该变量所做的修改。
* 对于任意两条龙A和B,如果A的龙头(assign或use)发生在B的龙头之前,那么A的龙尾要在B的龙尾之前(我这个解释真是太牛了!)
17. 关于互斥量(mutex)和信号量(semaphore)的区别:
* 正如他们的名字一样,前者的使用场景是保护资源的独占性,注重的是竞争关系;而后者的场景是等待“信号”的发生,更倾向于生产者/消费者模型中的消费者,注重的是供需关系。[知乎回答](semaphore和mutex的区别? - 人马座的回答 - 知乎 https://www.zhihu.com/question/47704079/answer/528324049)
* 对于mutex,只有上锁的线程才有资格解锁;而对于semaphore,它可以被任意的线程获取和释放。
18. 简述java的synchronized关键字:
* 它是java中最基本的互斥同步的手段,属于一种块结构的同步语法。
* 被javac编译后,会在同步块的前后分别形成moniterenter和moniterexit两个字节码指令
* 这两个字节码都需要一个reference类型参数指明要锁定的和解锁的对象。如果没有指明,那么就根据synchronized修饰的方法类型决定是锁对象实例还是Class对象。
* 在执行monitorenter指令时,首先要去尝试获取对象的锁,并且锁计数器加一,执行 monitorexit指令时会将锁计数器的值减一。计数器清零时,锁被释放。并且可以推论出:对于同一个线程来说,synchronized是可重入的。
19. 简述java的并发机制(或者同步机制)
* 同步的定义:同步是指在多个线程并发访问共享数据时,保证共享数据在同一个时刻只被一条(或者是一些, 当使用信号量的时候)线程使用。
* 基于同步的定义或者目的,有两种实现思路:1、互斥同步,其基本思想是对于共享资源的获取是悲观的(也即悲观锁),因此在访问资源时,都进行加锁操作,例如java语言层面提供的synchronized关键字。2、非阻塞同步,其基本思想是对于共享资源的获取时保持乐观的。不管风险,先进行操作,如果没有其他线程争用共享数据,那操作就直接成功了;如果共享的数 据的确被争用,产生了冲突,那再进行其他的补偿措施。
20. 关于JDK 6引入的自适应自旋锁的机制
* 自旋时间不再固定,而是由同一把锁前一次的自旋时间以及锁拥有者的状态决定。
* 假如刚刚自旋等待获取过**同一把锁**,并且持有锁的线程正在运行中,虚拟机会认为很可能再次成功,就会增加自旋次数
* 假如很少成功获得过锁,那么可能直接省略掉自旋,避免浪费CPU资源。
## 《Redis深度历险:核心原理与应用》读书笔记
1. (1.11.3 scan遍历顺序)scan的变量顺序是采用高位加法的方式(也就是低位加法的水平镜像),之所以这么操作是因为遍历过程中可能会出现扩容或者缩容导致了rehash,而高位加法可以大大减少槽位遍历过程中的重复和遗漏。
2. (1.11.4 字典扩容)当字典数组翻倍后,xxx槽位会被rehash到0xxx和1xxx(也即xxx + 8),例如3号槽位的值在rehash后会分布到3号和11号槽位,而这正好是高位加法的遍历顺序(妙哉!);对于遍历中缩容的情况,也能保证已经遍历的槽位不会再次被遍历。
3. (5.1 丝分缕析——探索“字符串”内部)所有的Redis对象都有一个RedisObject对象头,它占用大小:(4(类型,4bit)+4(存储形式,4bit)+24(lru信息,24bit)) / 8 + 4 (引用数量)+ 8(void*) = 16字节,而对于字符串STS来说,它占用:1(容量) + 1(实际长度) + 1(标记位)+ 1(空串 + \0) = 4字节,因此一个STS最小为:16 + 4 = 20字节,而对于jemalloc内存分配器,内存分配单位为2的n次方。当分配内存超过64字节时,Redis认为这是一个大的字符串,而此时留给STS.content的最小超度就是44字节,因此当长度超过44字节时,就抛弃embstr格式而改用raw格式。
4. (5.1.2 扩容策略)当字符串长度小于1MB时,每次扩容都是加倍,当超过1MB后,每次扩容增加1MB。
## MongoDb
1. spring-data-mongodb向mongodb-driver执行find指令时,后者解析后返回一个BsonDocument,BsonDocument继承自BsonValue,并且implements了Map<String, Bsonvalue>接口(内部通过LinkedHashMap实现),其成员如下,可以参考[mongodb API](https://docs.mongodb.com/manual/reference/command/find/index.html#output):
```
waitedMS --> BsonInt64
cursor --> BsonDocument
firstBatch --> BsonArrayWrapper //第一批读取到的document列表(ArrayList<Document>),当decode后被wrapper到BsonArrayWrapper里
id --> BsonInt64 //游标的Id,
ns --> BsonString //NameSpace的缩写,组成为:数据库名.文档名,例如:test.Bag
ok --> bsonDouble //标明命令是否执行成功:1:成功;0:失败
```
2. spring-data-mongodb的基础事件:`org.springframework.data.mongodb.core.mapping.event.MongoMappingEvent`,可以继承`AbstractMongoEventListener`,当执行document在进行删除前、删除后、存储前、存储后、转换前、转换后、加载后时,可以执行自定义操作。
3. MongoDb生成唯一Id最佳实践([来源](https://www.baeldung.com/spring-boot-mongodb-auto-generated-field)):
* 定义生成唯一Id的java类:
``` java
@Document(collection = "database_sequences")
@Data
public class DatabaseSequence {
@Id
private String id;
private long seq;
}
```
* 定义生成唯一Id的函数:
``` java
public long generateSequence(String seqName) {
DatabaseSequence counter = mongoOperations.findAndModify(query(where("_id").is(seqName)),
new Update().inc("seq",1), options().returnNew(true).upsert(true),
DatabaseSequence.class);
return !Objects.isNull(counter) ? counter.getSeq() : 1;
}
```
* 可以使用`AbstractMongoEventListener`实现自动化设置,例如:
``` java
User user = new User();
user.setId(sequenceGenerator.generateSequence(User.SEQUENCE_NAME)); //User.SEQUENCE_NAME为static string类型
user.setEmail("john.doe@example.com");
```
4. spring-data-mongodb实例化entity的算法如下所示:
* 如果包含无参构造参数,则使用该构造函数,其他有参构造函数被忽视
* 如果只有一个含有参数的构造函数,将该构造函数将会被使用
* 如果有多个有参构造函数,那么含有`@PersistenceConstructor`注解的构造函数将会被使用。
实例化过程中,
## FrameWork
1. 一种高性能可并发的持久化方案
* 要持久化的对象定义为JavaBean,并且进行如下限制:
* java原始类型(int/long/short等)使用`volatile`修饰
* 对于容器类型,如果是List或Set,使用`SynchronizedList`或SynchronizedSet,如果是Map,使用`ConcurrentHashMap`或`SynchronizedMap`(根据测试,当读取线程的次数低于10%的写入线程的写次数时,优先使用`SynchronizedMap`),并且这些容器类需要增加`final`修饰
* 手动创建全参构造函数,对于容器类型的字段,使用线程安全的容器进行初始化,例如:
``` java
@Data
@Accessors(chain = true)
@Document(collection = "PlayerBag")
public class PlayerBag {
private final ObjectId id;
private volatile long playerId;
private final Map<Integer, Integer> itemMap;
public PlayerBag(ObjectId id, long playerId, Map<Integer, Integer> itemMap) {
this.id = id == null ? new ObjectId() : id;
this.playerId = playerId;
this.itemMap = new ConcurrentHashMap<>(itemMap == null ? Collections.emptyMap() : itemMap);
}
}
```
* 如果JavaBean之内还包含自定义的JavaBean,那么也同样递归遵守上述3条规则。
* 上面4条限制可以保证当JavaBean在业务逻辑线程修改后,可以做到:对其他线程(主要是db存储线程)立即可见,这样可以实现数据安全发布!
* 数据落地:
* 方案一:使用Spring的异步框架,示例代码如下:
``` java
@EnableAsync
@Configuration
@Slf4j
public class Configuration
{
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix("taskExecutor");
executor.initialize();
return executor;
}
@Async
public <T> CompletableFuture<T> save(final MongoTemplate mongoTemplate, final T data) {
log.info("begin save:{}", data);
return CompletableFuture.supplyAsync(() -> mongoTemplate.save(data));
}
}
@Component
@Order(1)
@Slf4j
public class TestRunner implements ApplicationRunner {
private final MongoTemplate mongoTemplate;
private final ApplicationContext context;
public TestRunner(MongoTemplate mongoTemplate, ApplicationContext context) {
this.mongoTemplate = mongoTemplate;
this.context = context;
}
public void run(ApplicationArguments args) throws Exception {
log.info("run, thread:{}", Thread.currentThread().getName());
final PlayerBag playerBag = new PlayerBag(null, 0, null);
final Configuration configuration = context.getBean(SpringDataBean.class);
final CompletableFuture<PlayerBag> future = configuration.save(mongoTemplate, playerBag);
future.whenCompleteAsync((playerBag1, throwable) -> {
if (Objects.nonNull(throwable)) {
log.error("exception caught.", throwable);
}
else {
log.info("save finish.{}", playerBag1);
}
}, configuration.taskExecutor());
}
}
```
上述逻辑中,第41行的代码是在`TaskExecutor`线程执行的,而由于上述JavaBean的4个限制,因此`PlayerBag`的属性对于`TaskExecutor`来说是线程安全的(因为对于`PlayerBag`来说,`TaskExecutor`线程是只读线程,只要保持可见性即可,并不会出现并发写竞争),输出日志如下所示:
``` shell
2021-01-04 15:59:50.418 INFO 37012 --- [ main] com.example.demo.runner.TestRunner : run, thread:main
2021-01-04 15:59:50.423 INFO 37012 --- [ taskExecutor1] com.example.demo.config.SpringDataBean : begin save:PlayerBag(id=5ff2caf6d7e4a428e3dd9a36, playerId=0, itemMap={})
2021-01-04 15:59:50.516 INFO 37012 --- [nPool-worker-19] org.mongodb.driver.connection : Opened connection [connectionId{localValue:2, serverValue:273}] to 127.0.0.1:27017
2021-01-04 15:59:50.527 INFO 37012 --- [ taskExecutor1] com.example.demo.runner.TestRunner : save finish.PlayerBag(id=5ff2caf6d7e4a428e3dd9a36, playerId=0, itemMap={})
```
* 方案二:使用自定义的异步方案,该方案相当于方案一只有非常小的改动,查看代码第19行,由于使用了`CompletableFuture`,而它非常好的支持自定义线程池,因此只需要将第19行的改成另一个重载实现即可:`supplyAsync(Supplier<U> supplier, Executor executor)`
* 该持久化方案有一个缺点:
* 由于对于JavaBean的容器类型进行了限制:要求使用线程安全且不会抛出`ConcurrentModificationException`异常的容器,比如:`CopyOnWriteArrayList`、`CopyOnWriteArraySet`、`ConcurrentHashMap`,这要求容器的内的元素不能太多,否则性能将会急剧衰减([CopyOnWriteArraySet的官方doc说明](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/concurrent/CopyOnWriteArraySet.html))。
* 优化改进方案:从业务的角度来看,无论是进行序列化还是反序列化,都是只有一个线程写,另外一个线程读,并不会存在写竞争,那么只要从根本上解决内存可见性的问题即可满足业务需求。对于Java原生类型,使用volatile关键字修饰是一个可行的,且性能影响很小的方案,而对于容器类型,只要保证:1、从线程A移交到线程B的容器元素对于线程B都是可见的即可;2、线程A遍历容器时,不会抛出`ConcurrentModificationException`,基于这两点,可以考虑如下改进:1、容器变量去掉final关键字,增加volatile关键字;2、在业务逻辑线程下采用普通非线程安全的容器,而当进行存盘时,将其转换为线程安全的CopyOnWrite*、ConcurrentHashMap。存盘结束后,再将其转换为普通非线程安全的容器。
## Unity
1. 拖拽物体到场景中时,按下v会自动吸附一个顶点,从而可以方便的讲鼠标上的物体,吸附到另外的物体上。
2. Ctrl+Shift+F将Game窗口的摄像机设置为当前Scene场景中的位置。类似于Blender里的:Ctrl+Alt+小键盘 0
## C#
1. Conditional("条件") 可以优雅地替代宏定义
2. 泛型类中的static字段和非泛型类的字段有所区别,后者中该static字段属于该类,而前者中该static字段仅属于该泛型类,例如`Generic<A>.staticField`和`Generic<B>.staticField`是不同的。对于这个特性,可以有比较进阶的用法,例如:
``` c#
public class Foo {
public static int lastId;
}
public class Foo<T> : Foo {
public static int id = ++lastId;
}
```
那么对于每一个`Foo<T>`的子类,启id都是唯一的,从而实现id自我管理(而这里的泛型T只是被借壳而已,没有任何用处)
3. 使用`Type.MakeGenericType`,可以在运行时生成泛型类,这是一个java不具备的特性,举例:
``` c#
var type = typeof(Dictionary<,>);
Type[] typeArgs = {typeof(string), typeof(int)};
var genericType = type.MakeGenericType(typeArgs)
```
4. default关键字:在泛型类和泛型方法中产生的一个问题,给定参数化类型 T 的一个变量 t,只有当 T 为引用类型时,语句 t = null 才有效;只有当 T 为数值类型而不是结构时,语句 t = 0 才能正常使用。 解决方案是使用default 关键字,此关键字对于引用类型会返回 null,对于数值类型会返回零
5. 对于`ManualResetEvent`
1. 可以通过构造函数初始化为有信号或无信号状态。
2. 当且仅当`ManualResetEvent`处于无信号状态时(也即Set没有被调用或者初始化为无信号状态),其他线程调用了`ManualResetEvent.WaitOne`才会被阻塞。
3. 调用`ManualResetEvent.Reset`可以阻塞所有其他调用了`ManualResetEvent.WaitOne`的线程
4. 应用场景:工作A和B需要并发执行,但是需要A执行完毕后再执行B。最佳实践:a、A线程(称之为`ManualResetEvent`控制线程)调用`ManualResetEvent.Reset`使之进入非信号状态;b、B线程(称之为被控制线程或等待线程?阻塞线程?)在适当位置调用`ManualResetEvent.WaitOne`等待信号;c、A线程调用ManualResetEvent.Set通知B线程继续执行。
6. 可以通过实现一个public的无参的返回`IEnumerator`的`GetEnumerator()`为一个类扩展foreach语法,例如([详情](https://youtu.be/94ZElZQhu88?t=1782)):
``` c#
public IEnumerator<Tile> GetEnumerator() {
for(int x = 0; x < this.size.x; x++) {
for(int y = 0; y < this.size.y; y++) {
yield return this[x, y];
}
}
}
```
{"metaMigratedAt":"2023-06-15T20:48:24.805Z","metaMigratedFrom":"Content","title":"Untitled","breaks":true,"contributors":"[{\"id\":\"f6f150f7-d1d6-4ff6-be52-d4ac71827f37\",\"add\":47047,\"del\":0}]"}