# Modul 2: Intro to NLP & Transformers
## Objektif
Setelah menyelesaikan modul ini, peserta diharapkan dapat:
1. Memahami bidang NLP secara umum
2. Memahami keterbatasan arsitektur LSTM dan RNN sehingga digantikan oleh Transformer
3. Memahami overall architecture dari Transformer
4. Memahami dan mampu melakukan tokenization dengan python
5. Memahami dan mampu melakukan embedding vector dengan python
## Dasar Teori
### *Natural Language Processing*
Natural Language Processing (NLP) adalah cabang dari AI yang berfokus untuk memungkinkan komputer memahami, menafsirkan, dan menghasilkan teks atau ucapan dalam bahasa alami dengan cara yang bermakna. Berikut adalah common use case dari NLP:
| Use case | Deskripsi | Input | Output |
| --- | --- | --- | --- |
| Machine Translation | Menerjemahkan teks dari satu bahasa ke bahasa lain. | Teks dalam bahasa sumber | Teks terjemahan dalam bahasa target |
| Text Summarization | Merangkum dokumen panjang menjadi ringkasan yang lebih pendek dan koheren. | Dokumen atau artikel panjang | Ringkasan singkat dan koheren |
| Question Answering | Menjawab pertanyaan spesifik berdasarkan dokumen konteks. | Pertanyaan + dokumen konteks / korpus | Jawaban singkat atau potongan teks yang relevan |
| Text Generation | Menghasilkan teks baru berdasarkan prompt (penulisan kreatif, kode, dsb.). | Prompt atau seed text | Teks yang dihasilkan (paragraf, kode, dsb.) |
| Sentiment Analysis | Mengklasifikasikan teks berdasarkan nada emosional (positif/negatif/netral). | Teks (ulasan, tweet, komentar) | Label sentimen dan/atau skor kecenderungan |
| Chatbots & Conversational AI | Sistem dialog yang memahami dan merespons pengguna secara interaktif. | Utterance pengguna + riwayat percakapan | Respons bot (teks/aksi) dan status dialog |
| Named Entity Recognition (NER) | Mengidentifikasi dan mengkategorikan entitas penting dalam teks (nama, tempat, organisasi). | Teks utuh atau kalimat | Token atau segmen teks berlabel entitas beserta jenisnya |
| Genomic Analysis | Menerapkan model urutan untuk menganalisis data biologis (DNA/protein). | Urutan DNA / protein (string nukleotida/aminos) | Prediksi fungsionalitas, motif, atau anotasi biologis |
### Keterbatasan Model Sekuensial
Pada awalnya, bidang NLP didominasi oleh arsitektur sekuensial seperti RNN yang memiliki keterbatasan dalam menangkap konteks jangka panjang. Arsitektur sekuensial memproses data secara berurutan, yang dapat menyebabkan masalah seperti *vanishing gradient*, di mana informasi penting dari input sebelumnya hilang seiring waktu.
Untuk mengatasi keterbatasan model sekuensial, banyak solusi yang diusulkan, seperti arsitektur Long Short-Term Memory (LSTM) dan Gated Recurrent Unit (GRU). LSTM dan GRU memperkenalkan mekanisme *gating* yang memungkinkan model untuk mempertahankan informasi penting dari input sebelumnya, sehingga mengurangi masalah *vanishing gradient* yang sering terjadi pada RNN standar. Meskipun begitu, masalah yang sama tetap terjadi pada LSTM dan GRU ketika menangani data dalam jumlah yang sangat besar atau input sequence yang sangat panjang. Selain itu, kedua arsitektur ini masih memproses data secara berurutan, yang membatasi efisiensi komputasi dan paralelisasi selama training model.
### Transformers
Pada tahun 2017, para peneliti dari Google memperkenalkan arsitektur Transformer dalam sebuah paper berjudul "Attention is All You Need". Transformer menggunakan mekanisme *self-attention* yang memungkinkan model untuk mempertimbangkan semua bagian dari input sequence secara bersamaan (paralel), bukan secara berurutan. Hal ini memungkinkan Transformer untuk menangkap konteks jangka panjang dengan lebih efektif dan mengatasi masalah *vanishing gradient* yang sering terjadi pada model sekuensial. Selain itu, arsitektur Transformer memungkinkan paralelisasi yang lebih baik selama training, sehingga mempercepat proses training model.
Karena kemampuannya yang sangat baik dalam memproses bahasa, Transformer telah menjadi arsitektur dasar yang paling umum digunakan dalam berbagai aplikasi NLP, termasuk *Large Language Model* (LLM) seperti GPT, BERT, dan T5.
#### Arsitektur Transformer
Arsitektur Transformer terdiri dari dua bagian utama: encoder dan decoder. Encoder bertugas untuk memproses input sequence dan menghasilkan representasi yang kaya akan konteks, sedangkan decoder menggunakan representasi ini untuk menghasilkan output sequence. Berikut adalah representasi visual paling sederhana dari arsitektur Transformer:

Pada gambar ini, usecase yang digunakan adalah machine translation, di mana input sequence berbahasa Prancis diproses oleh Optimus-Prime (Transformer) untuk menghasilkan output sequence berbahasa Inggris. Jika kita melihat isi dari Transformer, kita bisa mengetahui komponen penyusunnya.
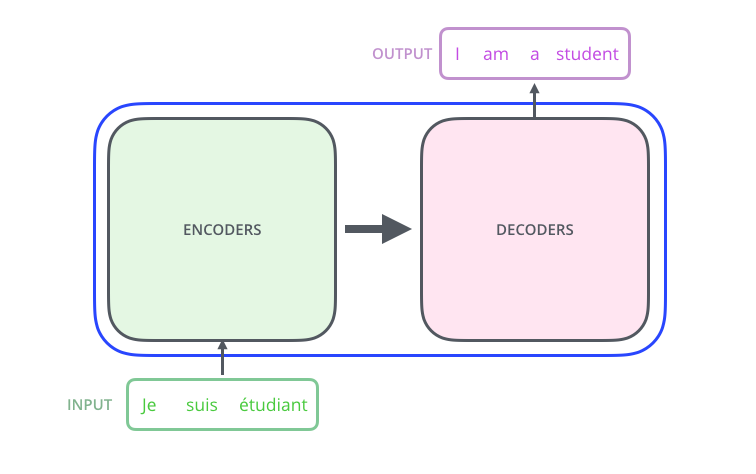
Sebuah Transformer terdiri dari encoder dan decoder. Encoder bertugas untuk memproses input sequence dan menghasilkan representasi yang kaya akan konteks, sedangkan decoder menggunakan representasi ini untuk menghasilkan output sequence. Akan tetapi, satu layer encoder dan decoder tidak cukup untuk menangkap kompleksitas bahasa alami. Oleh karena itu, Transformer biasanya terdiri dari beberapa layer encoder dan decoder yang ditumpuk secara vertikal untuk membentuk model yang lebih dalam dan kuat.
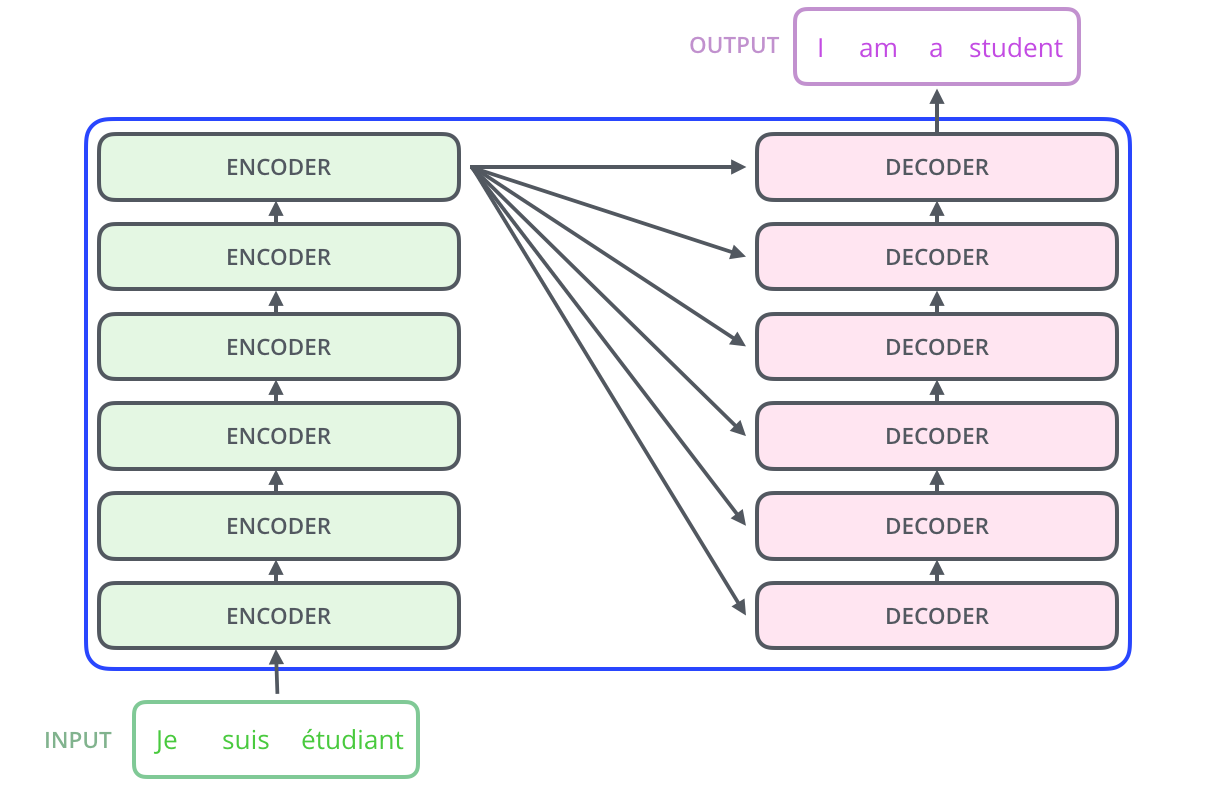
Input sequence diproses oleh beberapa layer encoder secara berurutan. Setiap layer baru pada encoder menyempurnakan representasi yang dihasilkan oleh layer sebelumnya, sehingga menghasilkan representasi yang semakin kaya akan konteks. Setelah melalui semua layer encoder, representasi akhir dari input sequence diteruskan ke decoder. Seperti yang dapat kita lihat, output dari encoder terakhir menjadi input bagi setiap layer decoder. Hal ini memungkinkan decoder untuk mendapatkan konteks secara penuh dari input sequence saat menghasilkan output sequence. Mekanisme ini disebut *attention*, karena memungkinkan decoder untuk "memperhatikan" bagian-bagian penting dari input sequence yang relevan dengan kata yang sedang dihasilkan. Pembahasan lebih dalam mengenai mekanisme *attention* khusus pada Transformer akan dibahas dalam modul selanjutnya.
Transformer memiliki dua komponen fundamental yang menyusun setiap layer encoder dan decoder, yaitu *self-attention* dan *feed-forward neural network* (FFN).
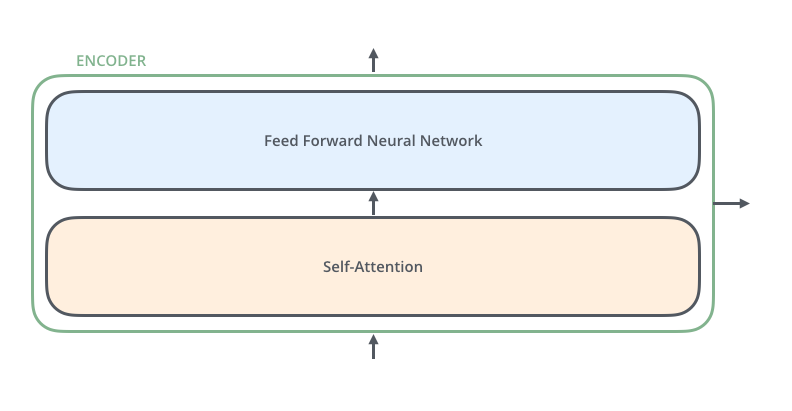
Modul selanjutnya akan berfokus pada penjelasan kedua komponen ini secara mendalam dan cara kerjanya.
### Turning Words into Numbers
Komputer tidak bisa memproses bahasa alami secara langsung. Oleh karena itu, diperlukan sebuah cara untuk mengubah kata-kata menjadi representasi numerik yang dapat dipahami oleh komputer. Untuk bisa memahami cara kerja Transformer, kita perlu memahami bagaimana proses pengubahan kata-kata menjadi representasi numerik tersebut. Hal ini dilakukan melalui dua langkah utama: *tokenization* dan *vector embedding*.
#### Tokenization
Tokenization adalah proses memecah teks menjadi unit-unit yang lebih kecil, yang disebut token. Sebuah token sebenarnya bisa berupa kata, frasa, atau bahkan karakter, tergantung pada pendekatan yang digunakan. Dalam konteks Transformer, token biasanya berupa kata atau sub-kata. Proses tokenization penting karena memungkinkan model untuk menangkap makna dari setiap bagian teks secara terpisah. Setelah proses tokenization, setiap token akan diberikan sebuah ID unik yang akan digunakan dalam langkah selanjutnya.

#### Word Embedding
Word embedding adalah teknik untuk mengubah token yang telah di-tokenisasi menjadi representasi vektor numerik. Sebuah vektor sebenarnya adalah array dari angka-angka yang mewakili fitur-fitur tertentu dari kata tersebut. Berikut adalah contoh visualisasi dari word embedding:
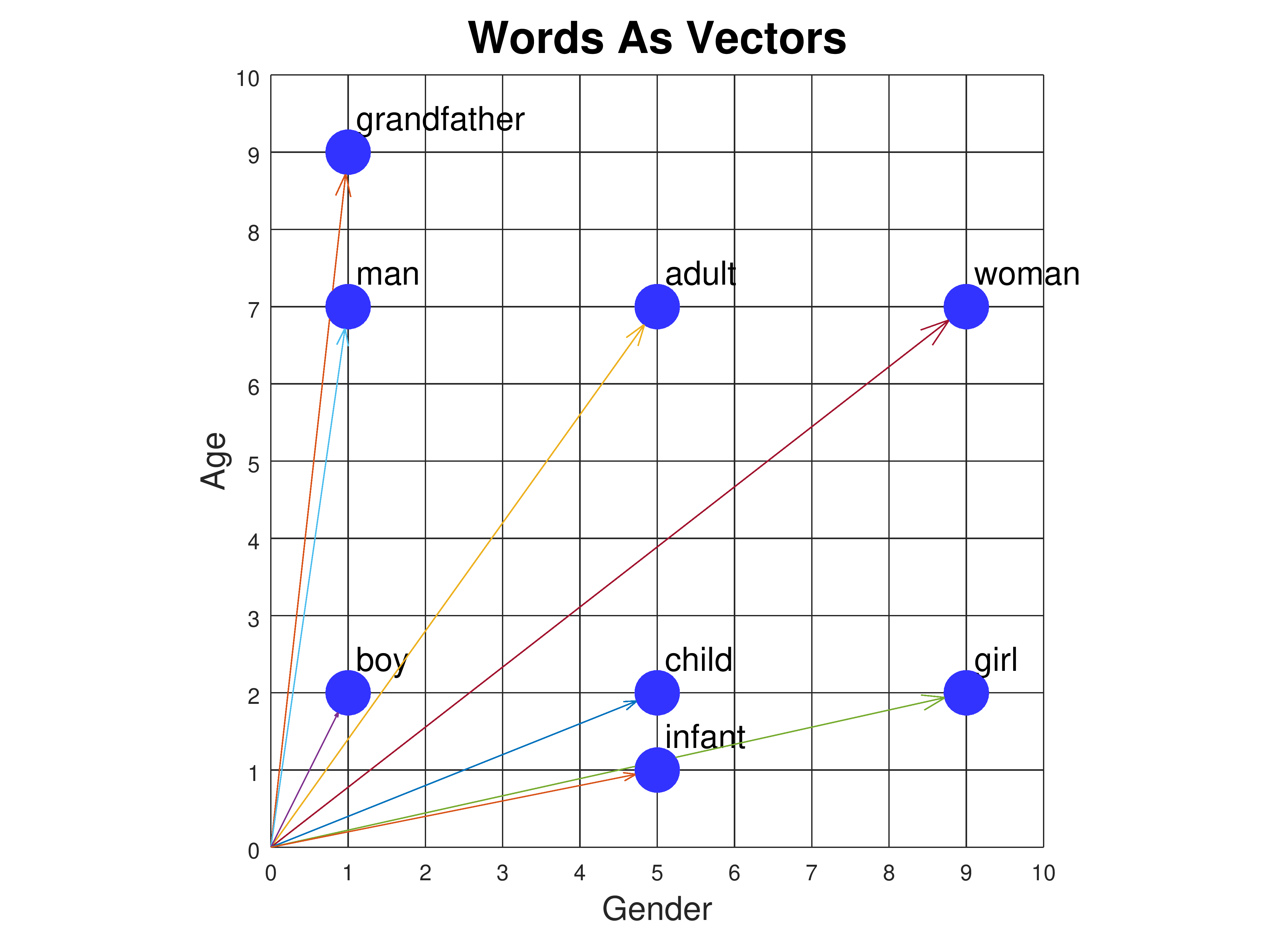
Contoh tersebut menunjukkan bagaimana kata-kata dapat direpresentasikan sebagai vektor dua dimensi. Setiap kata diwakili oleh sebuah titik pada grafik, di mana jarak antara titik-titik tersebut mencerminkan hubungan semantik antara kata-kata tersebut. Misalnya, kata-kata yang memiliki makna serupa, seperti "grandfather" dan "man", akan berada lebih dekat satu sama lain dibandingkan dengan kata-kata yang tidak berhubungan, seperti "man" dan "infant".
Pada praktisnya, word embedding biasanya memiliki dimensi yang jauh lebih tinggi, seperti 100, 200, atau bahkan 300 dimensi, untuk menangkap nuansa makna yang lebih kompleks dari kata-kata tersebut. Kumpulan vektor dari input sequence-lah yang kemudian akan diproses oleh Transformer untuk memahami konteks dan menghasilkan output yang diinginkan.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet