# Convolutional neural network
## Convolutional neural network
- Giả sử ta có 1 tấm ảnh màu có kích thước $480 \times 480$, làm thế nào máy có thể nhận dạng được tấm ảnh này?
- Input: $480 \times 480 \times 3 = 691200$ giá trị pixels $\Rightarrow$ kích thước quá lớn.
- CNN giúp giảm số chiều đầu vào và vẫn giữ được các đặc trưng quan trọng của tấm ảnh.
---
## Convolutional neural network
- Chúng ta phân biệt các vật thể khác nhau như thế nào?
 
---
## Convolutional neural network
- $\Rightarrow$ Các đặc trưng đường nét, cạnh, màu sắc, kích thước...
- Làm thế nào để máy có thể hiểu 1 tấm ảnh?
---
## CNN giúp chúng ta giải quyết điều gì?
- CNN giúp máy tính “nhìn” và “phân tích” 1 tấm ảnh tìm ra các đặc trưng của tấm ảnh.
- CNN có 02 phần chính: Lớp trích xuất đặc trưng của ảnh (Conv, Relu và Pool) và Lớp phân loại (FC và softmax).
---
## CNN giúp chúng ta giải quyết điều gì?

---
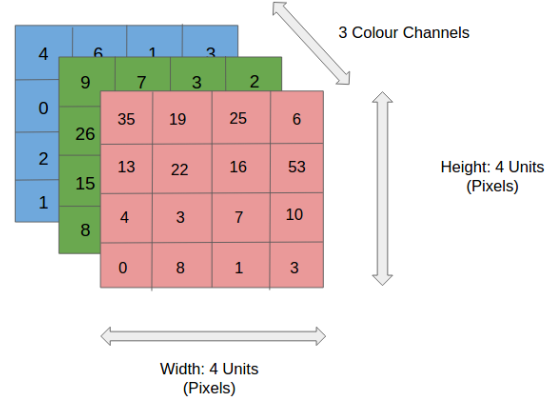
## Đầu vào (dữ liệu training):
Input đầu vào là một bức ảnh được biểu diển bởi ma trận pixel với kích thước: [W x H x D]
- W: chiều rộng
- H: chiều cao
- D: Là độ sâu, hay dễ hiểu là số lớp màu của ảnh.
---
## Đầu vào (dữ liệu training):
- Ví dụ ảnh RGB sẽ là 3 lớp ảnh Đỏ, Xanh Dương, Xanh.
---
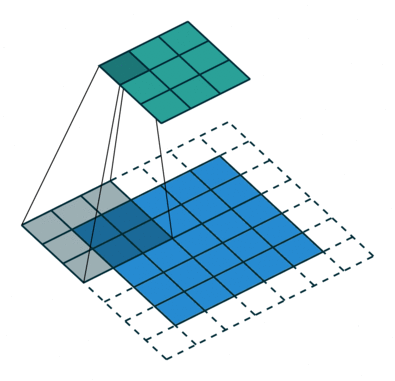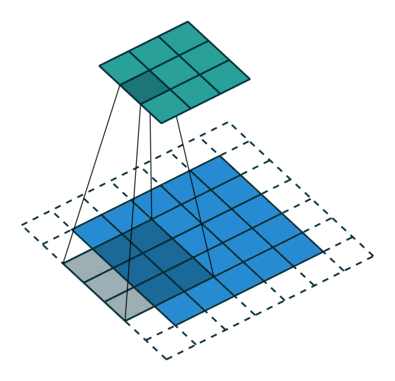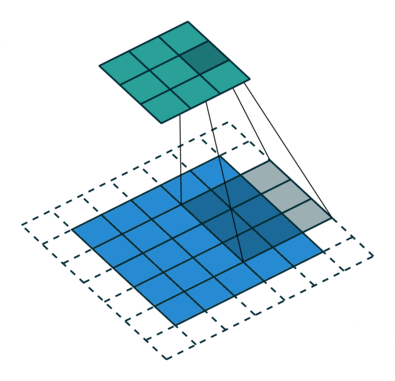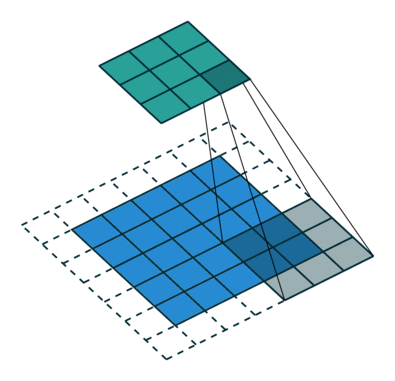
## Conv Layer:
- Mục tiêu của các lớp tích chập là trích xuất các đặc trưng của ảnh đầu vào.
- Đối với 1 kênh màu:

---
## Conv Layer:
- Lớp Conv so khớp bộ lọc (filter) với từng phần của tấm ảnh:
---
## Conv Layer:
- Đối với nhiều kênh màu:

---
### Conv Layer:
- Vậy kích thước đầu ra của ảnh với mỗi layer được tính như thế nào?
- Giả sử ảnh đầu ra là [W2 x H2 x D2]
$H2*W2*D2=(\frac{H-F+2P}{S} + 1) * (\frac{W-F+2P}{S} + 1) * K$
- Trong đó:
- [W1xH1xD1]: Kích thước đầu vào
- F: Kích thước bộ lọc Kernel
- S: giá trị Stride, K: Số lượng bộ lọc (Depth)
- P: số khung zero-padding thêm vào viền ảnh
---
## Conv Layer:
- Ví dụ về kích thước khi qua các layer

---
## Pooling Layer:
- Layer này giúp ta có thể giảm số chiều của đầu vào nhưng vẫn giữ được các đặc trưng cần thiết.
- Ví dụ: Max pooling với bộ lọc 2x2.

---
## Fully_Connected Layer (FC):
- Khi kết thúc phần trích xuất, ta có thêm 1 lớp flatten, trải các ma trận thu được thành 1 vector đặc trưng. Vector này là input cho lớp fully connected layer.

---
{"metaMigratedAt":"2023-06-15T09:20:28.081Z","metaMigratedFrom":"YAML","title":"Convolutional neural network","breaks":true,"contributors":"[{\"id\":\"b683ab44-e425-4d49-ab75-8b5d1906204e\",\"add\":10100,\"del\":6996}]"}