# SGD (Stochastic Gradient Descent)
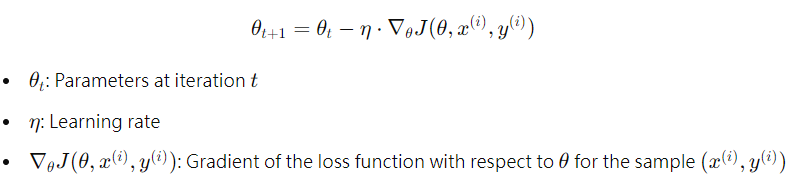
The stochasticity comes from using only one sample (or mini-batch) to compute the gradient, making it suitable for large datasets.
* Advantages: Fast computation, especially for large-scale data.
* Disadvantages: Slower convergence, prone to getting stuck in local minima, and fluctuations in update directions.
# SGD with Momentum
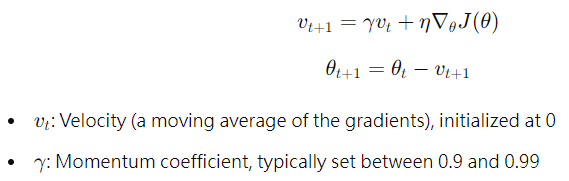
Like standard SGD, it updates based on one sample or mini-batch, but momentum adds a "memory" of past gradients, reducing fluctuations.
* Advantages: Faster convergence, smoother updates, and more efficient escape from saddle points.
* Disadvantages: Requires careful tuning of the momentum parameter, and is still prone to local minima.
# Adagrad (Adaptive Gradient Algorithm)
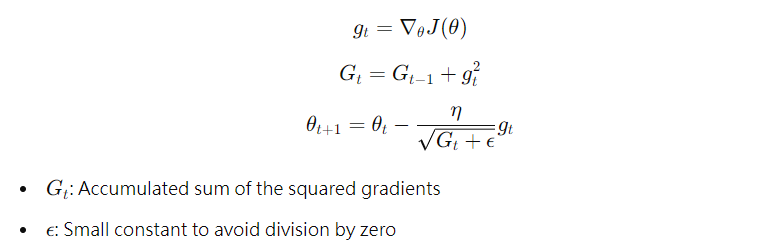
Adagrad works well for sparse data as it dynamically adapts the learning rate, giving more significant updates to less frequent parameters.
* Advantages:No need to manually tune the learning rate, Works well for sparse data
* Disadvantages: The accumulated squared gradients 𝐺𝑡 can grow without bound, causing the learning rate to shrink to near zero and stop learning.
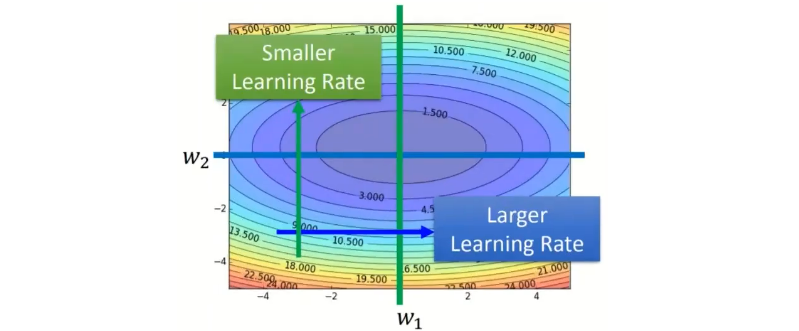
在gradient比較陡峭的地方就用比較小的learning rate,在gradient比較平緩的地方就用比較大的learning rate
# RMSProp (Root Mean Square Propagation)
**The Problem with Adagrad**
* Over time, the term 𝐺𝑡 keeps growing because it accumulates the sum of squared gradients from all previous time steps.
* As 𝐺𝑡 increases, the effective learning rate 𝜂/𝐺𝑡 becomes very small, **especially when the gradients are large early on, resulting in extremely slow convergence later in training.**

## Why RMSProp Solves Adagrad's Problem:
No rapid decay: The key advantage is that RMSProp avoids the extreme shrinkage of learning rates that happens in Adagrad. By using an exponentially weighted average, it "forgets" old gradients rather than accumulating them indefinitely. This keeps the effective learning rate under control, preventing it from decaying too fast.

* Advantages: Handles non-stationary objectives ,more stable and consistent updates compared to Adagrad
* Disadvantages: Sensitive to the choice of hyperparameters like decay rate and learning rate
# Adam (Adaptive Moment Estimation)
Adam (Adaptive Moment Estimation) is an extension of RMSProp that incorporates momentum and adaptive learning rates

* Bias Correction:
Adam applies bias correction, especially in the early stages, where the moving averages 𝑚𝑡 and 𝑣𝑡 are biased toward zero. The bias correction helps avoid very small updates in the initial steps.
* Momentum Term:
Adam incorporates momentum (𝑚𝑡) to smooth out the gradient updates, making it more stable in the long run and preventing erratic updates.
Adam improves on RMSProp by incorporating momentum, bias correction, and providing a more stable and efficient optimization process with fewer hyperparameter tuning requirements.
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet