# Neural Network Compression 101
<br>
<br>
<small>Neil John D. Ortega</small><br>
<small>
<small>ML Engineer @ LINE Fukuoka</small><br>
<small>2020/07/03</small>
</small>
---
## Agenda
- Motivation
- Techniques
- How-To
- Recap
---
## Motivation
- SOTA DNNs are computationally expensive and memory intensive
- How do we deploy to real-time applications?
- How do we deploy to devices with limited resources?
---
## Techniques
- Parameter pruning and quantization
- Knowledge distillation
- Low-rank factorization
- Transferred/compact conv filters
- **Note**: These are independent and can be used simultaneously
---
## Techniques
- Parameter pruning and quantization :o:
- Knowledge distillation :o: (a bit)
- ~~Low-rank factorization~~
- ~~Transferred/compact conv filters~~
- **Note**: These are independent and can be used simultaneously
---
## Quantization and Pruning
----
### Quantization and Binarization
- Reducing number of bits e.g. 32-bit to 16-bit (or smaller)
- Binarization = extreme quantization (1-bit)
- **Issues**:
- Significant reduction in accuracy with large CNNs
- Significant reduction in accuracy with aggressive quantization
----
### Quantization and Binarization (cont.)
- "Conservative" (FP32 to INT8) $\to$ no significant loss in accuracy, can be easily done **post-training**
- "Aggressive" (INT4 or lower) $\to$ requires re-training, arch changes, **quantization-aware training**, etc.
----
### Quantization and Binarization (cont.)
<style>
.reveal ul {display: block !important;}
</style>
- **Post-training Quantization**
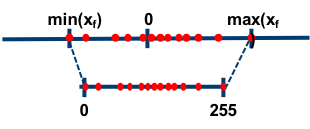
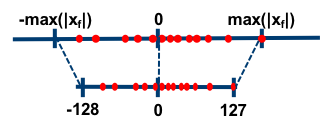
<small><small><strong>Fig. 1.</strong> Asymmetric and symmetric range-based linear quantization modes from "Neural Network Distiller," https://intellabs.github.io/distiller/algo_quantization.html. Accessed 5 Jun 2021.</small></small>
----
### Quantization and Binarization (cont.)
<style>
.reveal ul {display: block !important;}
</style>
- **Quantization-aware training**

<small><small><strong>Fig. 2.</strong> Quantization-aware training schematic diagram from "Neural Network Distiller," https://intellabs.github.io/distiller/quantization.html. Accessed 5 Jun 2021.</small></small>
----
### Network pruning
- Remove redundant non-informative weights on **(pre-)trained** DNNs
- Usually combined with quantization
- Sparsity constraints during training (as $l_0$ or $l_1$ regularizers)
----
### Network pruning (cont.)
- Early works include:
- Biased Weight Decay (Hanson and Pratt, 1989)
- The Optimal Brain Damage (Le Cun et al., 1990)
- Optimal Brain Surgeon (Hassibi et al., 1993)
----
### Network pruning (cont.)
- **Issues**:
- More training epochs needed for convergence
- Manual setup of sensitivity for layers - cumbersome
- Reduces model size but usually doesn't improve efficiency (train/inference time)
----
### Network pruning (cont.)
<style>
.reveal ul {display: block !important;}
</style>
- **Sensitivity** analysis

<small><small><strong>Fig. 3.</strong> Plot of accuracy vs. sparsity level in a sensitivity analysis run from "Neural Network Distiller," https://intellabs.github.io/distiller/pruning.html. Accessed 5 Jun 2021.</small></small>
----
### Network pruning (cont.)
- Element-wise Pruning
- Set some weight values to 0 using some criteria (e.g. threshold, sensitivity, etc.)
- Structure Pruning
- Remove entire large-scale structures entirely (e.g. kernels, filters, etc.)
---
## Knowledge distillation
- Distill knowledge from *teacher model* by training a compact *student model*

<small><small><strong>Fig. 4.</strong> Knowledge distillation network from "Neural Network Distiller," https://intellabs.github.io/distiller/knowledge_distillation.html. Accessed 5 Jun 2021.</small></small>
---
## Knowledge distillation (cont.)
- "Softmax temperature" (Hinton et al., 2015) $$p_{i} = \frac{exp(z_{i}/\tau)}{\sum_{j}{exp(z_{j}/\tau)}}$$
- $\mathcal{L} = \alpha * \mathcal{L}_{distillation} + \beta * \mathcal{L}_{student}$
- $\tau$, $\alpha$, and $\beta$ are hyperparams
---
## Knowledge distillation (cont.)
- **Issues**:
- Can only be applied to tasks with softmax loss
- Generally less performance compared to other methods
- Network requires training from scratch
---
## How-To
[NervanaSystems/distiller](https://github.com/NervanaSystems/distiller)

<small><small><strong>Fig. 5.</strong> Neural Network Distiller, https://github.com/NervanaSystems/distiller. Accessed 1 Jul 2020.</small></small>
---
## How-To (cont.)
### Post-Training Quantization
<style>
.reveal pre {font-size: 0.4em !important;}
</style>
```python=
quant_mode = {'activations': 'ASYMMETRIC_UNSIGNED', 'weights': 'SYMMETRIC'}
stats_file = "model_post_train_quant_stats.yaml"
dummy_input = distiller.get_dummy_input(input_shape=model.input_shape)
quantizer = quant.PostTrainLinearQuantizer(
deepcopy(model), bits_activations=8, bits_parameters=8, mode=quant_mode,
model_activation_stats=stats_file, overrides=None
)
quantizer.prepare_model(dummy_input)
```
---
## How-To (cont.)
### Post-Training Quantization
<style>
.reveal pre {font-size: 0.4em !important;}
</style>
```yaml=
conv1:
inputs:
0:
min: -2.1179039478302
max: 2.640000104904175
avg_min: -2.0179028272628785
avg_max: 2.4849105119705195
mean: -0.02644771572668106
std: 1.1904664382080992
b: 1.0037795305252075
shape: (256, 3, 224, 224)
output:
min: -37.17167663574219
max: 36.08745574951172
avg_min: -22.434925651550294
avg_max: 22.787699317932127
mean: -0.0001754729266394861
std: 1.7580939173603671
b: 1.0786008000373841
shape: (256, 64, 112, 112)
bn1:
inputs:
0:
min: -37.17167663574219
max: 36.08745574951172
avg_min: -22.434925651550294
avg_max: 22.787699317932127
mean: -0.0001754729266394861
std: 1.7580939173603671
b: 1.0786008000373841
shape: (256, 64, 112, 112)
output:
min: -6.58004093170166
max: 7.357358932495117
avg_min: -2.821167016029358
avg_max: 3.334167599678039
mean: 0.18160294145345687
std: 0.4129777229999846
b: 0.28660632371902467
shape: (256, 64, 112, 112)
.
.
```
---
## How-To (cont.)
### Post-Training Quantization
<style>
.reveal pre {font-size: 0.4em !important;}
</style>
```yaml=
.
.
linear_quant_params:
module.conv1.output_scale: 34.659175872802734
module.conv1.output_zero_point: 0.0
module.maxpool.output_scale: 34.659175872802734
module.maxpool.output_zero_point: 0.0
module.layer1.0.conv1.output_scale: 57.10962677001953
module.layer1.0.conv1.output_zero_point: 0.0
.
.
```
---
## Recap
<style>
.reveal ul {font-size: 32px !important;}
</style>
- Motivation - we want to deploy accurate **BUT** fast models
- Quantization - reduce bits required to represent weight
- Pruning - removes parts of network that has little information
- Knowledge distillation - trains a compact student model to learn from a dense teacher model
- [NervanaSystems/distiller](https://github.com/NervanaSystems/distiller) - provides said functionalities (and more!)
---
# Thank you! :nerd_face:
---
#### References
<style>
.reveal ul {font-size: 24px !important;}
</style>
- Cheng, Yu et al. “A Survey of Model Compression and Acceleration for Deep Neural Networks.” ArXiv abs/1710.09282 (2017)
- Zmora, Neta et al. “Neural Network Distiller: A Python Package For DNN Compression Research.” ArXiv abs/1910.12232 (2019)
- Hinton, Geoffrey E. et al. “Distilling the Knowledge in a Neural Network.” ArXiv abs/1503.02531 (2015)
{"metaMigratedAt":"2023-06-15T10:13:54.918Z","metaMigratedFrom":"YAML","title":"Neural Network Compression 101","breaks":true,"description":"View the slide with \"Slide Mode\".","slideOptions":"{\"spotlight\":{\"enabled\":true}}","contributors":"[{\"id\":\"ed2adf4d-7b64-4cc8-9c2f-656c184d7122\",\"add\":13552,\"del\":5129}]"}