# HeteroCL: A Multi-Paradigm Programming Infrastructure for Software-Defined Reconfigurable Computing
##### link: [Paper](https://vast.cs.ucla.edu/~chiyuze/pub/fpga19-heterocl.pdf), [Github](https://github.com/cornell-zhang/heterocl), [Website](https://heterocl.csl.cornell.edu/web/index.html), [Docs](https://cornell-zhang.github.io/heterocl/index.html)
###### paper origin: FPGA '19
- Problem:
It is difficut to Write hardware by **hardware description language** (verilog, VHDL) due to too many specialized hardware knowledge.
- Proposal:
HeteroCL, a programming infrastructure composed of a ==Python-based domain-specific language== (DSL) and an FPGA-targeted compilation flow (CPU+FPGA).
## Introduction
Heterogeneous computing platforms are becoming widely available such as CPU with GPU or FPGAs. FPGAs is especially difficult to be programmed. As a result, the use of such platforms has been limited to a small subset of programmers with ==specialized hardware knowledge==.
HeteroCL, a ==programming infrastructure== composed of a ==Python-based== domain-specific language (DSL) and an ==FPGA-targeted compilation flow== (CPU+FPGA). HeteroCL framework produces highly efficient hardware implementations such as **systolic arrays** and **stencil with dataflow architectures**. The HeteroCL DSL provides a clean programming abstraction that **decouples** algorithm specification from three important types of hardware customization in
1. compute,
2. data types, and
3. memory architectures.
HeteroCL is a Python-based DSL extended from ==TVM==, and incorporats state-of-the-art ==HLS optimizations==: ==PolySA== for systolic arrays and ==SODA== for stencil with dataflow architectures. And ==Merlin compiler== is as one of back-end tools. This compiler generates ==LLVM code on CPUs== and ==HLS code for FPGA== targets.

### Why choose TVM?
1. Python-based DSL provides programmers with a rich set of productive language features such as introspection and dynamic type system.
2. TVM is a tensor-oriented declarative DSL.
3. TVM inherits the idea of decoupling the algorithm specification from the temporal schedule, which is first proposed by Halide
### Compute Customization
performing loop transformations and executing the computation in parallel.
Table 1 lists compute customization primitives currently supported by HeteroCL. The primitives prevent programmers from using ==vendor-specific pragmas==, which makes HeteroCL programs **portable** to different back ends.

### Data Type Customization
**Quantized computation** using low-bitwidth integers and/or ==fixed-point types== is an essential technique to achieve efficient execution on FPGAs.


### Memory Customization
Accelerating applications on FPGAs usually requires a high on-chip memory bandwidth to match the throughput of massively parallel compute units.

Example: reuse_at function with CNN:

### Mapping to Spatial Architecture Templates

## Back-End code Generation and Optimization
- General Back End

### Why choose Merlin compiler?
1. Merlin compiler leverages a small set of OpenMP-like pragmas to apply certain architecture structures by source-to-source C code transformation.
2. Merlin compiler generates both HLS C kernels and OpenCL kernels for FPGAs.
- Stencil Back End
- Systolic Array Back End
## Evaluation



## Related Work
- TVM is a **Python-based DSL** and a ==deep learning compiler== that enables access to high-performance machine learning anywhere. TVM significantly improves code portability across different CPU and GPU architectures[^1].

- HLS (High-level synthesis)
HLS referred to as **C synthesis, electronic system-level (ESL) synthesis, algorithmic synthesis, or behavioral synthesis**, is an ==automated design process== that takes an abstract behavioral specification of a digital system and finds a ==register-transfer level (RTL)== structure that realizes the given behavior.
- PolySA: Polyhedral-Based Systolic Array Auto-Compilation
PolySA leverages the power of the **polyhedral model** to achieve the end-to-end compilation for systolic array architecture on FPGAs. PolySA is the first ==fully automated compilation framework== for generating high-performance ==systolic array architectures== on the **FPGA** leveraging recent advances in **high-level synthesis**.

- SODA (SODA Open Data Autonomy)
SODA Architecture is getting evolved to realize a challenging goal of building a unified framework for ==data and storage management==.
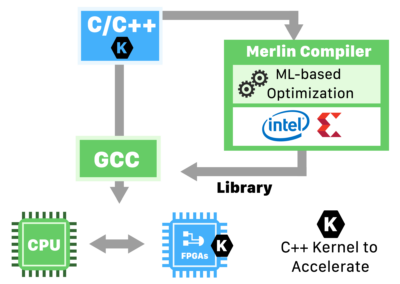
- Merlin compiler
Merlin Compiler takes **C/C++ code** as an input and generates an executable that includes the **CPU host-code & the FPGA bitstream**.
- Halide
Halide is a ==programming language== designed to make it easier to write high-performance ==image and array processing code== on modern machines. ==Halide is embedded in C++.==
[^1]: [TVM introduction](https://tvm.apache.org/docs/tutorial/introduction.html#sphx-glr-tutorial-introduction-py)