# 字典 (dictionary)
- 跟串列類似,都是一種儲存資料的容器
- 定義:contains unordered key-value pairs
- 字典內的元素是以key-value對的形式存在,key值是不能重複的。
- 字典的 key 需要是 immutable(不可更改)且 hashable(唯一雜湊值 → 唯一)。
- 常見的 immutable 資料型別包括:
- 數字(int, float)
- 字串(str)
- 元組(tuple)
## 字典的底層原理
### 插入:
當我們初始化一個空字典時,CPython會初始化一個擁有8個None元素的一維Array、一個空的二維Array
```python=
dict1 = {}
'''
indices = [None, None, None, None, None, None, None, None]
entries = []
'''
```
當我們在空字典加入一條數據,python會計算key的hash values,並對這個值取對8的餘數,
0代表這條數據是第一條數據。
```python=
hashValue = hash("小波")
print(hashValue1)
print(hashValue1 % 8)
# 結果:
# -5923010074522229261
# 3
```
```python=
dict1['小波'] = 183
'''
indices = [None, None, None, 0, None, None, None, None]
entries = [[-5923010074522229261, 小波的記憶體位址, 183的記憶體位址]]
'''
```
當我們再加入一條數據時,迪西的hash values對8取餘數是7。
```python=
dict1['小波'] = 183
dict1['迪西'] = 244
'''
indices = [None, None, None, 0, None, None, None, 1]
entries = [ [-5923010074522229261, 小波的記憶體位址, 183的記憶體位址],
[-588543676937807417, 迪西的記憶體位址, 244的記憶體位址] ]
'''
```
### 查詢
當我們想取得迪希所對應的value,python會根據餘數7找到 indices 中索引7的值是1,並去找entries索引1的值。
所以字典與list相比查詢速度很快,舉個例子:
```python=
list1 = [10, 20, 30, 40, 50]
50 in list1
```
這段程式碼必須走訪整個list才能算出結果
當使用字典:
```python=
dict1 = {10:1, 20:2, 30:3, 40:4, 50:5}
50 in dict1
```
只要將50 hash一下取對5的餘數就能在indices直接取得entries的索引值
資料量越大字典與list的查詢速度的差距就越大。
> 參考:
> <a href='https://blog.csdn.net/weixin_47906106/article/details/121772942'>详解Python字典的底层原理——哈希表(Python面试必备)</a>
> <a href='https://www.cnblogs.com/jiakecong/p/15881370.html'>python字典底层原理</a>
> <a href='https://blog.csdn.net/be5yond/article/details/120021250'>Python 深入理解dict---为什么 dict 查询元素比 list 快?</a>
## 建立一個空字典
```python=
people = {} # 建立空字典
print("天線寶寶身高辭典", people) # 天線寶寶身高辭典 {}
people['TA'] = 176
people['小波'] = 183
people['迪西'] = 244
people['拉拉'] = 259
people['丁丁'] = 300
print("天線寶寶身高辭典", people)
# 天線寶寶身高辭典 {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300}
```

## 字典基本操作
```python
dict1 = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300}
print(dict1["丁丁"]) # 300
# 列出字典資料型態
print("資料型態是: ",type(dict1)) # 資料型態是: <class 'dict'>
```
## 取值(更新)
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300}
# NOTE: key()
print(person.keys()) # dict_keys(['TA', '小波', '迪西', '拉拉', '丁丁'])
# 檢查 key 是否存在
print('TA' in person) # 輸出: True
print('助教' in person) # 輸出: False
# NOTE: value()
print(person.values()) # dict_values([176, 183, 244, 259, 300])
print(person['TA'])
print(person.get('TA'))
person['TA'] = 180 # 設置 value
# NOTE: item (key-value 對)
print(person.items()) # dict_items([('TA', 180), ('小波', 183), ('迪西', 244), ('拉拉', 259), ('丁丁', 300)])
# 遍歷 item
for key, value in person.items():
print(f"Key: {key}, Value: {value}")
```
## 新增字典特定元素
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300}
person["利姆路·坦派斯特"]=130 # 更新跟新增一樣
print(person)
# {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, '利姆路·坦派斯特': 130}
```
<!--  -->
<!--  -->
## 刪除字典元素
### 刪除字典特定元素
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
del person['小波']
print("新字典內容:", person)
# 新字典內容: {'TA': 176, '迪西': 244, '拉拉': 259, '丁丁': 300, '利姆路·坦派斯特': 130}
```
### 刪除字典所有元素
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
person.clear( )
print("新字典內容:", person) # 新字典內容: {}
```
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
copy = person.copy( )
print("位址 = ", id(person), " person元素 = ", person)
print("位址 = ", id(copy), " copy元素 = ", copy)
# 位址 = 1802586334400 person元素 = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, '利姆路·坦派斯特': 130}
# 位址 = 1802586329216 copy元素 = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, '利姆路·坦派斯特': 130}
```
## 取得字典元素數量
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
print("person字典元素數量= ", len(person)) # person字典元素數量= 6
```
## 檢驗是否存在於字典
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
key = input("請輸入鍵(key) = ")
print("鍵(key) = ", key)
value = input("請輸入值(value) = ")
print("值(value) = ", value)
if key in person:
print(f"{key}已經在字典了")
else:
person[key] = value
print("新的person字典內容 = ", person)
# 鍵(key) = 蜜莉姆·拿渥
# 值(value) = 135
# 新的person字典內容 = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, '利姆路·坦派斯特': 130, '蜜莉姆·拿渥': '135'}
```
## 字典合併
```python
personA = {'TA': 176, '小波': 183}
personB = {'利姆路·坦派斯特': 130, '蜜莉姆·拿渥': 135}
personA.update(personB) # A的後面加B
print(personA)
# {'TA': 176, '小波': 183, '利姆路·坦派斯特': 130, '蜜莉姆·拿渥': 135}
```
## 搭配字典使用的函數
### len()
```python
people = {
"維爾德拉·坦派斯特":{
"身高":130,
"瞳色": "金瞳",
"萌點": {"傲嬌","中二病"}
},
"蜜莉姆·拿渥":{
"別號": "破壞之暴君噠",
"身高":135,
"瞳色": "藍瞳",
"萌點": {"裝","條紋過膝襪","噠"}
}
}
# 列印字典元素個數
print("people字典元素個數", len(people))
# people字典元素個數 2
print("people字典元素個數['維爾德拉·坦派斯特']元素個數 ", len(people['維爾德拉·坦派斯特']))
# people字典元素個數['維爾德拉·坦派斯特']元素個數 3
print("people字典元素個數['蜜莉姆·拿渥']元素個數 ", len(people['蜜莉姆·拿渥']))
# people字典元素個數['蜜莉姆·拿渥']元素個數 4
```
### get() 如果沒有找到指定的值,就返回預設值
```python
person = {'TA': 176, '小波': 183, '迪西': 244, '拉拉': 259, '丁丁': 300, "利姆路·坦派斯特": 130}
temp = person.get("蜜莉姆·拿渥")
print(temp) # None
temp = person.get("蜜莉姆·拿渥", 135)
print(temp) # 135
```
### setdefault()
- 這個方法基本上與 get()相同,不同之處在於 get()方法不會改變字典內容。使用setdefault()方法時若所搜尋的鍵不在,會將"鍵:值"加入字典,如果有設定預設值則將鍵:預設值加入字典,如果沒有設定預設值則將鍵:none 加入字典。
```python=
# key在字典內
person = {'TA': 176, "利姆路·坦派斯特": 130}
temp = person.setdefault("蜜莉姆·拿渥")
print("temp = ", temp) # temp = None
print("person字典", person)
# person字典 {'TA': 176, '利姆路·坦派斯特': 130, '蜜莉姆·拿渥': None}
del person['蜜莉姆·拿渥']
temp = person.setdefault("蜜莉姆·拿渥", 135)
print("temp = ", temp) # temp = 135
print("person字典", person)
# person字典 {'TA': 176, '利姆路·坦派斯特': 130, '蜜莉姆·拿渥': 135}
```
# 集合(set)
- 一個集合裡所有的鍵都不會重複,元素裡的內容可以是整數(int)、浮點數(float)、字串(string)、元組(tuple)、布林(boolen),但是不可以是串列(list)、字典(dict)、集合(set)。
- 因為集合不會包含重複的資料的特性,常用來進行去除重複的字元、或判斷元素間是否有交集、聯集或差集之類的關聯性。
## 宣告
```python
# 方式1
fruits = ['apple', 'orange', 'apple', 'banana', 'orange']
x = set(fruits) # {'orange', 'apple', 'banana'}
print(x)
# 方式2
y = set(['apple', 'orange', 'apple', 'banana', 'orange'])
print(y) # {'orange', 'apple', 'banana'}
```
## add() 添加元素到集合中
```python
my_set = {1, 2, 3}
my_set.add(4)
print(my_set) # {1, 2, 3, 4}
```
## clear() 清空集合中的所有元素。
```python
my_set = {1, 2, 3}
my_set.clear()
print(my_set) # set()
```
## copy() 複製集合。
```python
original_set = {1, 2, 3}
copied_set = original_set.copy()
print(original_set) # {1, 2, 3}
print(copied_set) # {1, 2, 3}
```
## discard() 移除集合中的指定元素,如果元素不存在,则不发生任何操作。
```python
my_set = {1, 2, 3, 4}
my_set.discard(3)
print(my_set) # {1, 2, 4}
```
## 集合差集 difference()
```python
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
result = set1.difference(set2) # 输出: {1, 2}
```
## 集合交集 intersection()
```python
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
result = set1.intersection(set2) # 输出: {3, 4}
```
## 判断是否沒有交集 isdisjoint()
```python
set1 = {1, 2, 3}
set2 = {4, 5, 6}
result = set1.isdisjoint(set2) # True,因为两个集合没有交集
```
## issubset() 判断一个集合是否是另一个集合的子集
```python
set1 = {1, 2}
set2 = {1, 2, 3, 4}
result = set1.issubset(set2) # True,因为set1是set2的子集
```
## issuperset() 判断一个集合是否是另一个集合的超集
```python
set1 = {1, 2, 3, 4}
set2 = {1, 2}
result = set1.issuperset(set2) # True,因为set1是set2的超集
```
## union()
```python
set1 = {1, 2, 3}
set2 = {3, 4, 5}
result = set1.union(set2) # 输出: {1, 2, 3, 4, 5}
```
## set comprehension
如 list comprehension一樣,
set也有set comprehension
```python=
a = {x for x in 'abracadabra' if x not in 'abc'}
# >>>a: {r, d}
```
> 參考:
> [5. 資料結構— Python 3.12.5 說明文件](https://docs.python.org/zh-tw/3/tutorial/datastructures.html)
## lab作業題目
- 繳交方式 : 將程式碼以及程式輸出截圖放入名為'學號_Lab05'的資料夾,並上傳到github
- 繳交時間 : 9/25 12:00
### lab05_01
- 有一天助教需要紀錄每個學生的多次考試成績,並計算每個學生的平均成績。請你幫助教設計一個程式,輸入每個學生的多次考試成績,然後計算每個學生的平均成績。
- 學生的成績如下:
```python=
scores = {
'Alice': [85, 87, 90],
'Bob': [78, 82, 89],
'Charlie': [95, 92, 88],
'David': [64, 68, 70],
'Eve': [90, 91, 85]
}
```
- 範例程式輸出如下:
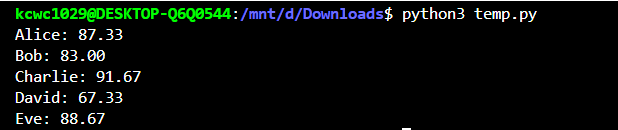
- 解答:
```python=
scores = {
'Alice': [85, 87, 90],
'Bob': [78, 82, 89],
'Charlie': [95, 92, 88],
'David': [64, 68, 70],
'Eve': [90, 91, 85]
}
average_scores = {student: sum(grades) / len(grades) for student, grades in scores.items()}
for student, avg in average_scores.items():
print(f"{student}: {avg:.2f}")
```
### lab05_02
- 有一天助教需要紀錄班上每個學生的成績,並找到成績最高的學生。請你幫助教設計一個程式,輸入每個學生的成績,然後找到成績最高的學生。
- 學生的成績如下:
```python=
scores = {
'Alice': 85,
'Bob': 92,
'Charlie': 78,
'David': 64,
'Eve': 90
}
```
- 範例程式輸出如下:

- 解答:
```python=
scores = {
'Alice': 85,
'Bob': 92,
'Charlie': 78,
'David': 64,
'Eve': 90
}
highest_score = max(scores.values())
top_student = [student for student, score in scores.items() if score == highest_score]
print(f"成績最高的學生是 {top_student[0]},分數是 {highest_score}")
```
### lab05_03
- 有一天助教需要紀錄班上每個學生的詳細資料,並找到年齡最大的學生。請你幫助教設計一個程式,輸入每個學生的詳細資料(包括年齡),然後找到年齡最大的學生。
- 學生的資料如下:
```python=
students = {
'Alice': {'age': 20, 'grade': 'A'},
'Bob': {'age': 22, 'grade': 'B'},
'Charlie': {'age': 19, 'grade': 'A'},
'David': {'age': 21, 'grade': 'C'},
'Eve': {'age': 20, 'grade': 'B'}
}
```
- 範例程式輸出如下:

- 解答:
```python=
students = {
'Alice': {'age': 20, 'grade': 'A'},
'Bob': {'age': 22, 'grade': 'B'},
'Charlie': {'age': 19, 'grade': 'A'},
'David': {'age': 21, 'grade': 'C'},
'Eve': {'age': 20, 'grade': 'B'}
}
oldest_age = max(student['age'] for student in students.values())
oldest_student = [name for name, info in students.items() if info['age'] == oldest_age]
print(f"年齡最大的學生是 {oldest_student[0]},年齡是 {oldest_age}")
```
### lab05_04
- 有一天助教需要統計班上學生選修課程的聯集。請你幫助教設計一個程式,輸入每個學生選修的課程,然後找到所有學生選修過的所有課程。
- 學生選修的課程如下:
```python=
students = {
'Alice': {'Math', 'Science'},
'Bob': {'Math', 'History', 'Science'},
'Charlie': {'Math'},
'David': {'Science', 'History'},
'Eve': {'Math', 'Science', 'History'}
}
```
- 範例程式輸出如下:

- 解答:
```python=
students = {
'Alice': {'Math', 'Science'},
'Bob': {'Math', 'History', 'Science'},
'Charlie': {'Math'},
'David': {'Science', 'History'},
'Eve': {'Math', 'Science', 'History'}
}
all_courses = set.union(*students.values())
print(f"所有學生選修過的課程有:{', '.join(all_courses)}")
```
### lab05_05
- 有一天助教需要統計班上某兩個學生選修課程的差集。請你幫助教設計一個程式,輸入這兩個學生選修的課程,然後找到其中一個學生選修但另一個學生沒選修的課程。
- 請幫助教找到 student_A 選修但 student_B 沒選修的課程並輸出結果:
- 學生選修的課程如下:
```python=
student_A = {'Math', 'Science', 'Art'}
student_B = {'Math', 'History'}
```
- 範例程式輸出如下:

- 解答:
```python=
student_A = {'Math', 'Science', 'Art'}
student_B = {'Math', 'History'}
unique_courses = student_A.difference(student_B)
print(f"student_A 選修但 student_B 沒選修的課程有:{', '.join(unique_courses)}")
```
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet