# Data drift and concept drift
## Introduction
The performance of a Machine Learning (ML) model degrades over time because of the so-called **data drift**. Drift is the change in an entity with respect to a baseline. Data drift, that underlies model drift, is defined as a change in the distribution of data. In the production stage of ML models, it is the change between the real-time production data and a **baseline data set**, likely the **training set**, that is representative of the task the model is intended to perform. Production data can diverge or drift from the baseline data over time due to *changes in the real world*. Drift of the predicted values is a good proxy for concept drift (see below), or data integrity issues.
- The **fundamental assumption** in developing any machine learning model is that *the data that is used to train the model mimics the real-world data*. A practical problem is how to assert this assumption after the model is deployed to *production*. Indeed, unlike traditional code, ML models performance can fluctuate over time due to changes in the data input into the model *after deployment*. As a consequence, successful AI deployments require **continuous ML monitoring**.
- Over time, even highly accurate models are prone to decay as the incoming data shifts away from the original training set. This phenomenon is called **model/concept drift**.
**Data drift** is defined as a variation in the production data from the data that was used to test and validate the model before deploying it in production.
- There are many factors that can cause data to drift. One key factor is the *time dimension*. Several other factors can also cause drift like *errors in data collection*, *seasonality* (e.g., if the data were collected before Covid-19, and model is deployed post-Covid-19).
- The model in production is constantly receiving new data to make predictions upon, but these new data might have a *different probability distribution* than the ones you have trained the model. Using the original model with the new data distribution will cause a *drop in model performance*. To avoid performance degradation, you need to monitor these changes. See section “Data Drift in Machine Learning” below.
- Another aspect is that while labels are always available in a training data set, they might not always be available in production for a given use case. In the absence of these inputs, *monitoring changes in production features and prediction distributions* can be used as a leading indicator for performance issues.
## Terminology: “Concept”, and concept components
We introduce further terminology to highlight the difference between **data drift** and **concept drift**.
- **Concept** stands for the **joint probability distribution** of a machine learning model's inputs ($X$) and outputs ($Y$), i.e.,
$$
P(X, Y) = P(Y) P(X \vert Y) = P(X) P(Y \vert X).
$$
- **Concept drift** happens when the joint distribution of inputs and outputs changes over time, i.e.,
$$
P_{t_1} (X, Y) \neq P_{t_2}(X, Y), \quad \text{with} \quad t_{1} \neq t_{2}.
$$
Concept drift can originate from any of the concept components (i.e., $P(Y)$, $P(X \vert Y)$, $P(X)$, and $P(Y \vert X)$). The most important source is the **posterior probability** $P(Y|X)$, i.e., the probability of $Y$ given $X$. It shows how well our model understands the relationship between inputs and outputs. For this reason, people use the term “concept drift” or “real concept drift” for this specific type. During training, our model learns to simulate $P(Y|X)$. Concept drift means that our model will not be fit for the task. See section “Concept Drift in Machine Learning” below.
- It is also useful to monitor **the other components** as they can affect model performance or predict the presence of “real concept drift”. We can distinguish the following additional sources of drift:
- **“Data drift”** or **feature drift**: it is the change in the **covariates** $P(X)$, i.e., a shift in the model’s input data distribution.
- **Prediction drift** or change in $P(\hat{Y} \vert X)$ is a shift in the model’s predictions.
- **“Label drift”**: these are the **prior probabilities** $P(Y)$. Label drift indicates that there has been a change in the representation of these classes in the real world or your sampling or processing method, and possibly also a concept drift.
- **Conditional covariates**: $P(X \vert Y)$.
Some of these probabilities affect each other because of their relationship (e.g., for $P(Y)$ to change, $P(X)$ or $P(Y|X)$ also has to change). **Label drift**, **prediction drift**, and **data drift** are metrics that are easier to measure directly and may be strong indicators of concept drift.
## Data Drift in Machine Learning
As mentioned in the previous section, **data drift** is the situation where the model’s input distribution changes over time:
$$
P_{t_1} (X) \neq P_{t_2}(X), \quad \text{with} \quad t_{1} \neq t_{2}.
$$
Some scientists also call it **covariate shift**, virtual drift, or virtual concept drift depending on their definition of ‘concept’. Other terms are **feature drift** or **population drift**.
### Example
Here is a way to think about data drift: let us consider **feature segments**, where **segment** refers to a *specific categorical value* or a *continuous value range* in our input features. Example segments are an *age group*, a *geographical origin*, or *customers from particular marketing channels*. Let’s assume that our model works well on the entire dataset, but it does not produce good results on a specific segment. Low segment-level performance is not a problem if the segment’s proportion is small, and we aim only for aggregate results. However, **our overall performance drops when our model receives new data with a high proportion of the poorly predicted segment**. The input distribution shift makes the model less capable of predicting labels. **Data drift does not mean a change in the relationship between the input variables $X$ and the output $Y$. *It means that the performance weakens because the model receives data on which it wasn’t trained enough.*** Performance degrades in proportion to the importance of that particular feature. For example, if we try to predict cancer and train our model on non-smokers, introducing a significant smoking subpopulation can alter the results. **The main cause of data drift is the increased relevance of “underlearned” segments**.
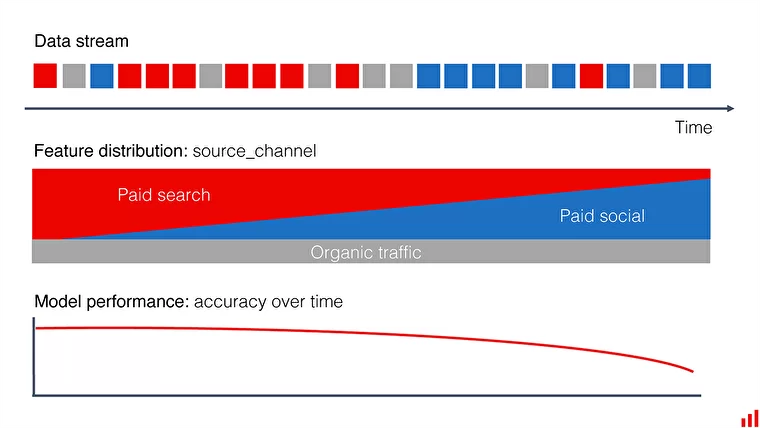

## Concept Drift in Machine Learning
(Real) concept drift is the situation when **the functional relationship between the model inputs and outputs changes**, i.e., when the probability of $Y$ output given $X$ input, or $P(Y|X)$, changes. *The context has changed, but the model doesn’t know about the change. The patterns that the model has learned during training do not hold anymore*.
A concept drift means a change of **posterior probabilities** between two situations:
$$
P_{t_1} (Y \vert X) \neq P_{t_2}(Y \vert X), \quad \text{with} \quad t_{1} \neq t_{2}.
$$
Other terms for concept shift are class drift, real concept drift, or **posterior probability shift**.
Concept drift is essentially a **discrepancy** between a real and learned decision boundary. It implies that the model necessitates **re-learning** the data to maintain the error rate and accuracy of the previous regime.
## The difference between “Data Drift” and “Concept Drift”
Here we further emphasize the difference between “Data Drift” and “Concept Drift”.
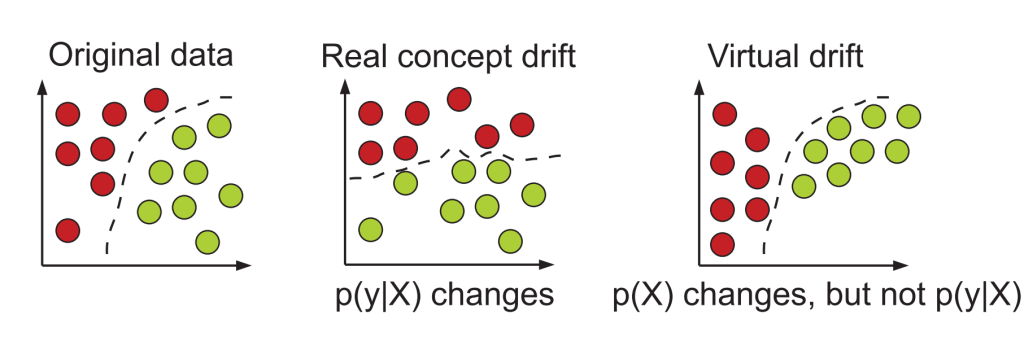
- In the case of (real) concept drift, the decision boundary $P(Y \vert X)$ changes. In the case of data drift (or virtual drift), the boundary remains the same even though $P(X)$ has changed. See the picture below.
- Another difference is that in data drift, the cause is somewhat **internal** to the process of collecting and processing data and training our model on it. In the case of concept drift, the reason is usually **external** to this process (see previous sections).
## Determining the cause of model drift
*How do we determine the root cause of model drift?*
1. **The cause of the relationship change is some kind of external event or process**. For example, let us assume that we are trying to predict life expectancy using **geographic regions** as input. As the region’s development level increases (or decreases), region loses its predictive power, and our model degrades. Other examples:
- A change in the ground truth or input data distribution, e.g. shifting customer preferences due to a pandemic.
- Product launch in a new market etc.
- There is a concept change, e.g. a competitor launching a new service.
This mechanism is also behind the original understanding of ‘concept drift’, the change of “meaning” of predicted labels. Examples:
- A common example is the shifting view of what emailing behavior we consider “normal” or “spam”. Until a few years ago, sending emails frequently and in mass was a clear sign of spamming behavior. Nowadays, this is much less so. Models using these attributes to identify spam experienced concept drift, and had to be retrained.
- Another (similar) example is from the the cybersecurity field. Imagine you are trying to develop a system that notifies you upon potential Denial-of-Service attacks. Perhaps your model will use a feature such as the number of requests received by the server per minute. Maybe when this model was trained, 1000 requests a minute seemed like an extremely large number of requests that may have indicated something fishy was going on. But what if your company launched an advertising campaign after which your website became much more popular. This is an example for when the concept of suspicious behavior has drifted due to changes in reality.

The plot shows data with two labels – orange and blue (potentially loan approvals and non-approvals). When concept drift occurs in the second image, we observe a new decision boundary between orange and blue data as compared to our training set. It is the decision boundary to have changed, not the input data.
2. **Data integrity** might be the main issue. Drift can be caused by changes in the world, changes in the usage of your product, or **data integrity** issues — e.g. bugs and degraded application performance. Data integrity issues can occur at any stage of a product’s pipeline.
- For example, a bug in the frontend might permit a user to input data in an incorrect format and skew your results.
- Alternatively, a bug in the backend might affect how that data gets transformed or loaded into your model. If your application or data pipeline is degraded, that could skew or reduce your dataset.
- Correct data enters at source but is incorrectly modified due to faulty data engineering. For example, debt-to-income values and age values are swapped in the model input.
- Incorrect data enters at source. For example, due to a front-end issue, a website form accepts leaving a field blank.
**If you notice drift, a good place to start is to check for data integrity issues**. The next step is to dive deeper into your model analytics to pinpoint when the change happened and what type of drift is occurring. Using the statistical tools mentioned above, work with the data scientists and domain experts on your team to understand the shifts you’ve observed. Model explainability measures can be very useful at this stage for generating hypotheses.
Depending on the root cause, resolving a feature drift or label drift issue might involve **fixing a bug**, updating a pipeline, or simply refreshing your data. If you determine that context drift has occurred, it’s time to **retrain your model**.
## Other Drift Types and Related Issues
Here is a list of the most important ones:
- **Prior Probability Shift**: Prior probability shift means a change in the output’s distribution $P_{t_1} (Y) \neq P_{t_2}(Y)$.
- **Novel Class Appearance**: This is the case when in a classification problem, your model needs to predict a label that it hasn’t seen before, i.e., at two different situations $t_1$ and $t_2$, one has
$$
P_{t_1} (Y = y) = 0 \quad \text{and} \quad P_{t_2} (Y = y) > 0.
$$
New unseen labels be a typical result of a change in upstream data collection (e.g., a new field in a form) introducing a new value.
- **Subconcept drift** (intersected drift) and Full-concept drift (severe drift): Within concept drift, we can further differentiate between subconcept and full-concept drift depending on whether the drift affects the whole domain of $X$ or just a section of it.
## Conclusions
To maintain the performance of your models, you need to prevent data and concept drift. To do that, you need to monitor your model to identify them in advance. Next notes to do: [**identification/detection of data drift**](https://hackmd.io/-I0-9fv1TOS6zmy_mDPn7Q).
***
### Sources:
1. [https://deepchecks.com/data-drift-vs-concept-drift-what-are-the-main-differences/]
2. [https://towardsdatascience.com/why-data-drift-detection-is-important-and-how-do-you-automate-it-in-5-simple-steps-96d611095d93]
3. [https://www.fiddler.ai/blog/drift-in-machine-learning-how-to-identify-issues-before-you-have-a-problem]