# Survey(All)
###### tags:`Survey`
## [基於卷積神經網路的肺癌細胞學影像自動診斷輔助系統](https://csme2020.nfu.edu.tw/CSME2020%E8%AB%96%E6%96%87%E9%9B%86/%E5%85%A8%E8%AB%96%E6%96%87/%E5%AD%B8%E7%94%9F%E8%AB%96%E6%96%87%E7%AB%B6%E8%B3%BD/E.%E6%96%B0%E8%88%88%E7%A7%91%E6%8A%80%E8%88%87%E5%85%B6%E4%BB%96/505-E11-%E5%BC%B5%E5%AE%B6%E7%9D%BF-%E5%9F%BA%E6%96%BC%E5%8D%B7%E7%A9%8D%E7%A5%9E%E7%B6%93%E7%B6%B2%E8%B7%AF%E7%9A%84%E8%82%BA%E7%99%8C%E7%B4%B0%E8%83%9E%E5%AD%B8%E5%BD%B1%E5%83%8F%E8%87%AA%E5%8B%95%E8%A8%BA%E6%96%B7%E8%BC%94%E5%8A%A9%E7%B3%BB%E7%B5%B1.pdf)
###### tags:
### Abstract:
#### 1. 建立一套先分類良惡性細胞再對惡性細胞做語意分割(Semantic Segmentation)的深度學習自動輔助肺癌細胞診斷系統來降低醫師手術中細胞檢驗的誤判率並縮短手術時間。
#### 2. 使用深度更深的深度學習分類模型以及更適合的超參數以提升良惡性分類準確度,並加上語意分割模型標註出惡性細胞區域,以方便醫師確認本系統判斷結果。
### Method:
#### 1. DataSet: 細胞檢體資料集(台灣大學醫學院附設癌醫中心醫院林敬凱醫師提供)Heamcolor及劉氏染色染色後,以顯微鏡三種倍率存取影像,共496張原始影像。
#### 2.資料前處理:

#### 3. 良惡性細胞分類
**train:** 以ResNet101在ImageNet資料集的預訓練上再做100個時期的微調訓練。
**test:** 從原影像左上角向右一次滑動112個像素點,並一排一排向下,若影像被判斷為惡性的機率高於0.99則該原影像為惡性,反之則為良性。惡性細胞需判別細胞核與細胞比例等特徵,誤判率較高,因此只有當原影像中有極高信心(0.99)含有惡性小影像時才將原影像判斷為惡性。
#### 4. 針對分類為惡性的影像透過語意分割模型標註出影像中的惡性細胞區域。
**train:** 惡性細胞的語意分割是以惡性的原影像訓練
**test:** 訓練時以HRNet在ImageNet資料集的預訓練上再做300個時期的微調訓練。
### Conclusion:
#### 1. 一套先分類後語意分割的流程不僅準確度高,診斷時間也可以大幅縮減,也間接縮短了手術所需時間,有助於輔助醫師在支氣管鏡檢體的肺癌細胞學分析。
#### 2. 小影像分類準確度經過模型選擇與超參數調整可以ResNet101達到97%、原影像的分類準確度達到90.9%
#### 3. 判斷出惡性細胞後以語意分割模型對影像中的每一個像素點分類以標註出惡性細胞區域,並以HRNet達到平均IoU 89.2%。
#### 4. 這是第一個針對肺癌細胞學分類搭配語意分割的輔助系統, 也是第一個對Hemacolor及劉氏染色肺癌細胞學影像進行深度學習的分析研究


#### 1. 訓練準確度達到99%,測試時準確度達97%,靈敏度達98%,特異度達95%
## [Reconstructing cell cycle and disease progression using deep learning](https://www.researchgate.net/publication/346374484_Reconstructing_cell_cycle_and_disease_progression_using_deep_learning)
###### [tags](https://www.nature.com/articles/s41467-017-00623-3#Sec9):Nature ARTICLE 2017
### Abstract:
#### 1. 以重建Jurkat細胞的細胞週期以及糖尿病性視網膜病變的疾病可以證明deep convolutional neural networks結合non-linear dimension reduction能夠依照原始圖像數據重建生物過程。
#### 2. Jurkat細胞分析時,檢測並分離了unsupervised manner下的死細胞亞群,並且在對離散的細胞週期階段進行分類時,與最近基於增強圖像特徵的方法相比,我們的錯誤率降低了6倍。
> Jurkat细胞属于人急性T淋巴细胞白血病细胞/人淋巴细胞瘤细胞
#### 3. 主要關注fluorescence microscopy 的 image data,特別是imaging flow cytometry (IFC)
> #### FC 是對懸液中的單細胞或其他生物粒子,通過檢測標記的螢光信號,實現高速、逐一的細胞定量分析和分選的技術。
> #### IFC 流式細胞儀的熒光敏感性和高通量功能與單細胞成像相結合
> #### IFC provides very high sample numbers and image data from several channels --> well-suited to deep learning
> #### IFC 為每個單個單元格提供一張圖像,因此不需要全圖像分割。
#### 4.提出一個結合了分類和可視化的深度卷積神經網絡非線性降維的工作流程

#### 5.選擇深度學習是因為相較於機器學習,DL較:
1. 不需要繁瑣的預處理和手動特徵定義
2. 提高了預測精度
3. 可以將學習到的特徵可視化
### Method:
#### [DataSet1](https://github.com/theislab/deepflow): 異步增長的原始IFC圖像-->immortalized human T lymphocyte cells (Jurkat細胞)32,266個
> Images of these cells can be classified into [seven different stages](https://cn.lamscience.com/what-are-two-main-stages-cell-cycle) of cell cycle (Figure 2), including phases of interphase (G1, S and G2) and phases of mitosis (Prophase, Anaphase, Metaphase and Telophase).
#### [DataSet2](https://www.kaggle.com/c/diabetic-retinopathy-detection/data?select=test.zip.002): 30.000 publicly available images from the Diabetic Retinopathy Detection Challenge (2015).
> classified into four disease states: “healthy”, “mild”, “medium”, and “severe”.
#### ground thruth:
based on the inclusion of two fluorescent stains:propidium iodide (PI)& mitotic protein monoclonal #2 (MPM2)antibody
> propidium iodide (PI),碘化丙啶,是一種熒光嵌入劑,可用於對細胞和核酸進行染色。在本論文用於定量每個細胞的DNA含量。
> mitotic protein monoclonal antibody,有絲分裂蛋白單克隆抗體,在本論文用於在有絲分裂期時鑑定細胞。
#### Model:
1. Based on the widely used “Inception” architecture25
> The architecture consists in 13 three-layer “dual-path” modules,該modules處理和匯總可視化圖像,這39層後面是標準卷積層,
完全連接的層和softmax分類器。
2. developed the “DeepFlow” [architecture](https://github.com/theislab/deepflow/blob/master/network_architecture.pdf)(针对IFC数据的较小输入维度进行了优化。)
#### 1. t-SNE:The activation space of our network’s last layer is much too high dimensional-->非線性降維來可視化低維空間中的數據
#### 2. unsupervised檢測異常細胞: 細胞週期的labels沒提供任何信息,所以使用unsupervised,這些具有型態異常,ex.破碎的細胞壁和生長產物,表明死細胞


### Conclusion:
#### 1. 使用對32,266個細胞的五重交叉驗證,我們獲得了98.73%±0.16%的準確度。
#### 2. 使用tSNE在網絡的最後一層對數據進行可視化顯示了深度學習如何克服傳統機器學習問題-->當使用離散的類別標籤對連續的生物過程進行訓練時,傳統的機器學習通常無法解決連續體
#### 3. 深度學習能夠基於類別標籤重構連續過程,因為相鄰類在形態上比在時間上進一步分離的類更為相似。
## [DenseNet](https://arxiv.org/pdf/1608.06993.pdf)
###### tags:
### Abstract:
#### 1.如果卷積網絡在靠近輸入的層和靠近輸出的層之間用shortcut 連接,那麼卷積網絡可以更深入、更準確、更高效(because Bottleneck layers can reduce the number of input feature-maps)地進行訓練。 也就是將每一層與除該層外的所有層連線起來。
#### 2. 每一層都將前面所有層的特徵圖譜作為輸入(使用 concatenate 來聚合資訊),DenseNet著重於對每一層feature maps的重複利用。
> 1. inception 加寬網絡結構
> 2. ResNet 加深網絡結構
#### 3. 特點:
1. 降低了梯度消失與過擬合問題
2. 增強了特徵傳播,特徵可重用
3. 大大減少了參數量。
### Method:

> Transition Layer中,以Conv 與 pooling進行採樣,BN 層and an 1×1 convolutional , 2×2 average pooling layer.

> 1. Dense block中,每一個卷積層的輸入都是前幾個卷積層輸出的concatenation(拼接),這樣即每一次都結合了前面所得到的特徵,來得到後續的特徵。
> 2. Dense block中,layer = 5,that is mean 有5個BN+Relu+Conv(3 * 3)這樣的layer
> 3. k = 4,每一個layer輸出的feature map的維度爲4。
> 4. 每一個Dense Block模塊都利用到了該模塊中前面所有層的信息,即每一個layer都和前面的layer有highway的稠密連接。假設一個具有L層的網絡,那麼highway稠密連接數目爲*L(L+1)/2*
### Dense connectivity.


> 上為ResNet,下為DenseNet
### Composite function
batch normalization、ReLU、3x3 Cov.
### Bottleneck layers
利用1 * 1 * n的卷積操作對特徵圖進行降維,並設定n=4 * k,使得每一層輸出特徵圖的維數是4k(k是增長率Growth rate)。
> * 也就是將BN-Relu-Conv(3 * 3)改爲BN-Relu-Conv(1 * 1)-BN-Relu-Conv(3 * 3).
> * 帶有Bottleneck layers的網絡稱爲DenseNet-B
### Compression
在Dense Block模塊之外的過渡層(transition layers)進行降維操作
### Dataset
CIFAR-10, CIFAR-100,SVHN和ImageNet
### Problem
as information about the input or gradient passes through many layers, it can vanish and “wash out” by the time it reaches the end (or beginning) of the network.-->即深度越深,效果越差。
>1. ResNet和Highway Networks:做法是通過一個旁路信號連接來傳遞原始信息。
>2. Stochastic depth:再training中,隨機丟棄層,已獲得更好的信息流。
>3. FractalNets:通過將多個不同數量的convolutional blocks 的parallel layer拼接在一起,來達到較深的深度。
>
>they create short paths from early layers to later layers.
#### Classification Results on CIFAR and SVHN

#### Classification Results on Imag


#### Feature Reuse

> 可以看出在較深層中也會用到較淺層提取到的特徵
### Conclusion:
#### 1. 提出了一種新的CNN結構,DenseNet
#### 2. 證明DenseNet 再擴展到上百層的情況下,no optimization difficulties
#### 3. 隨著參數數量的提升,準確率持續提升,沒有出現退化和過擬合的現象。
#### 4. 進行設置之後,它在多個數據集上取得了SOTA效果。而且,DenseNet比SOTA的方法有著更少的參數和計算量,仍能取得SOTA結果。
## [A Style-Based Generator Architecture for Generative Adversarial Networks](https://openaccess.thecvf.com/content_CVPR_2019/papers/Karras_A_Style-Based_Generator_Architecture_for_Generative_Adversarial_Networks_CVPR_2019_paper.pdf)
### Abstract:
* 從style transfer literature文獻中藉用了一種用於GAN的alternative generator architecture(使其exposes novel ways to control the image synthesis process)。
* 新架構可以 automatically learned、unsupervised分離高級屬性(例如,在人臉上訓練時的姿勢和身份)
* 可以隨機變換生成圖像的一些noise來增加差異(例如雀斑、頭髮)
* new generator在traditional distribution quality metrics做出改善,有更好的interpolation properties,且可以更好的disentangles the latent factors of variation.
* 為了量化interpolation quality和disentanglement,提出了兩種適用於任何生成器架構的新的自動化方法:perceptual path length and linear separability(感知路徑長度和線性分離度)。
* 最後,我們引入了一個新的、高度多樣化和高質量的人臉數據集(FFHQ)。
### Method:
我们的生成器从一个学习的常数输入开始,在每个卷积层根据潜伏代码调整图像的 "风格",因此直接控制不同尺度的图像特征的强度。与直接注入网络的噪声相结合,这种结构上的变化导致了在生成的图像中自动地、无监督地分离高级属性(如姿势、身份)和随机变化(如雀斑、头发),并实现了直观的特定规模的混合和插值操作。我们不以任何方式修改判别器或损失函数,因此我们的工作与正在进行的关于GAN损失函数、正则化和超参数的讨论是正交的。

> * mapping network f:8 layer,使用MLP(Multilayer Perceptron)
> * synthesis network g:18 layer(two for each resolution(4^2^ - 1024^2^)
> * * AdaIN:adaptive instance normalization.
* Given a latent code z in the input latent space Z, a non-linear mapping networkf: Z → W
* The output of the last layer is converted to RGB using a separate 1 × 1 convolution.
* “A” stands for a learned affine transform.
* “B” applies learned per-channel scaling factors to the noise input.

> * celebA-HQ :名人的dataset
> * FFHQ :普通人的dataset


### Conclusion:
* styleGAN is better than traditional GAN
* our investigations to the separation of high-level attributes and stochastic effects, as well as the linearity of the intermediate latent space will prove fruitful in improving the understanding and controllability of GAN synthesis.
* we expect that methods for directly shaping the intermediate latent space during training will provide interesting avenues for future work.
# Diverse Image Inpainting with Disentangled Uncertainty
### Abstract:
* 圖像修復本質上是一個多模態問題,因為修復的結果可能有多種可能性。
* 為了生成多樣化和逼真的修復結果,我們提出了一個具有解開不確定性的多樣化圖像修復框架。
* 我們將缺失區域的不確定性分為兩個方面:結構和外觀。
* 多元圖像修復過程分為兩個階段:多元結構修復和多元外觀修復。
* 設計一個light-weighted disentangling subnetwork來解開結構信息和外觀信息。
* 提出了Style-based Masked Residual Block以更好地處理不確定性。
* 可以以更高的保真度和多樣性修復損壞的圖像。
### 鮮有產生多結果的image inpainted論文的缺點:
1)尽管它们可以生成多样化的结果,但特别是在结构方面的多样性仍然有限,有待进一步改进;
2)如果不明确考虑结构信息,一些不着色的结果可能会有模糊的区域和人工痕迹。
> 最近的研究工作[8, 17]已经证明,首先修复边缘图,然后应用完整的边缘图来指导图像的涂抹,将使涂抹的结果得到提升,尤其是在轮廓清晰方面。
In our framework with two diverse inpainting stages, we can choose to introduce diversity in either stage or both stages. For example, we can fix the structure information of the missing region and fill in diverse appearance information (see Figure 2 and Figure 10), or fix the appearance information of the missing region and fill in diverse structure information (see Figure 11). Therefore, many flexible and user-controlled image inpainting and editing tasks can be accomplished by our framework (see Section 4.9).
在我们的框架中,有两个不同的绘画阶段,我们可以选择在任何一个阶段或两个阶段引入多样性。例如,我们可以固定缺失区域的结构信息并填入多样化的外观信息(见图2和图10),或者固定缺失区域的外观信息并填入多样化的结构信息(见图11)。因此,许多灵活的、由用户控制的图像绘制和编辑任务都可以通过我们的框架完成(见第4.9节)。
### Contribution:
* We disentangle the uncertainty in diverse image inpainting task into structure uncertainty and appearance uncertainty, which has never been studied before.
* We develop a two-stage diverse image inpainting framework, which restores the structure information and appearance information of the missing region separately.
* Another two contributions are a light-weighted disentangling subnetwork unified with our two-stage framework and a novel Style-based Masked Residual Block (SMRB) specifically designed for diverse image inpainting.
* Extensive experiments on three datasets demonstrate the effectiveness and flexibility of our method.
* 我们将各种图像修复任务中的不确定性分解为结构不确定性和外观不确定性,这是以前从未研究过的。
* 我们开发了一个两阶段不同的图像修复框架,它分别恢复了缺失区域的结构信息和外观信息。
* 另外两个贡献是与我们的两阶段框架统一的轻量级解缠子网络和专为各种图像修复设计的新型基于样式的掩码残差块(SMRB)。
* 对三个数据集的大量实验证明了我们方法的有效性和灵活性。
### Method:


## [PD-GAN: Probabilistic Diverse GAN for Image Inpainting](https://arxiv.org/pdf/2105.02201.pdf)
### Abstract:
* 用於做缺損圖像的修復。
* 提出PD-GAN的架構,機率且多樣化的GAN
* 認為hole filling時,hole邊界的像素應該具有確定性(為了產生自然的過度邊界),越靠近hole中心的像素的自由度越高。
* 提出SPDNorm,可以動態的平衡hole裡面的真實性與多樣性。
> 也有用CNN來修復圖像的研究,它們的目標是單幅圖像的生成,即每個輸入圖像對應於一個修復的結果
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View








### Conclusion:
#### contribution:
* Based on a vanilla GAN, the proposed PD-GAN modulates deep features of random noise vector via the proposed SPDNorm to incorporate context constraint.
* We propose a perceptual diversity loss to empower the network diversity.
* Experiments on the benchmark datasets indicate that our PD-GAN is effective to generate diverse and visually realistic contents for image inpainting.
### 理解障礙:

# [MSG-GAN](https://arxiv.org/pdf/1903.06048.pdf)
##### CVPR2020

### Abstract:
* GANs are notoriously difficult to adapt to different datasets, in part due to instability during training and sensitivity to hyperparameters.
>Because gradients passing from the discriminator to the generator become uninformative when there isn’t enough overlap in the supports of the real and fake distributions.
* propose the Multi-Scale Gradient Generative Adversarial Network (MSG-GAN)
* MSG-GAN allowing the flow of gradients from the discriminator to the generator at multiple scales.
### Method:
#### PROGAN

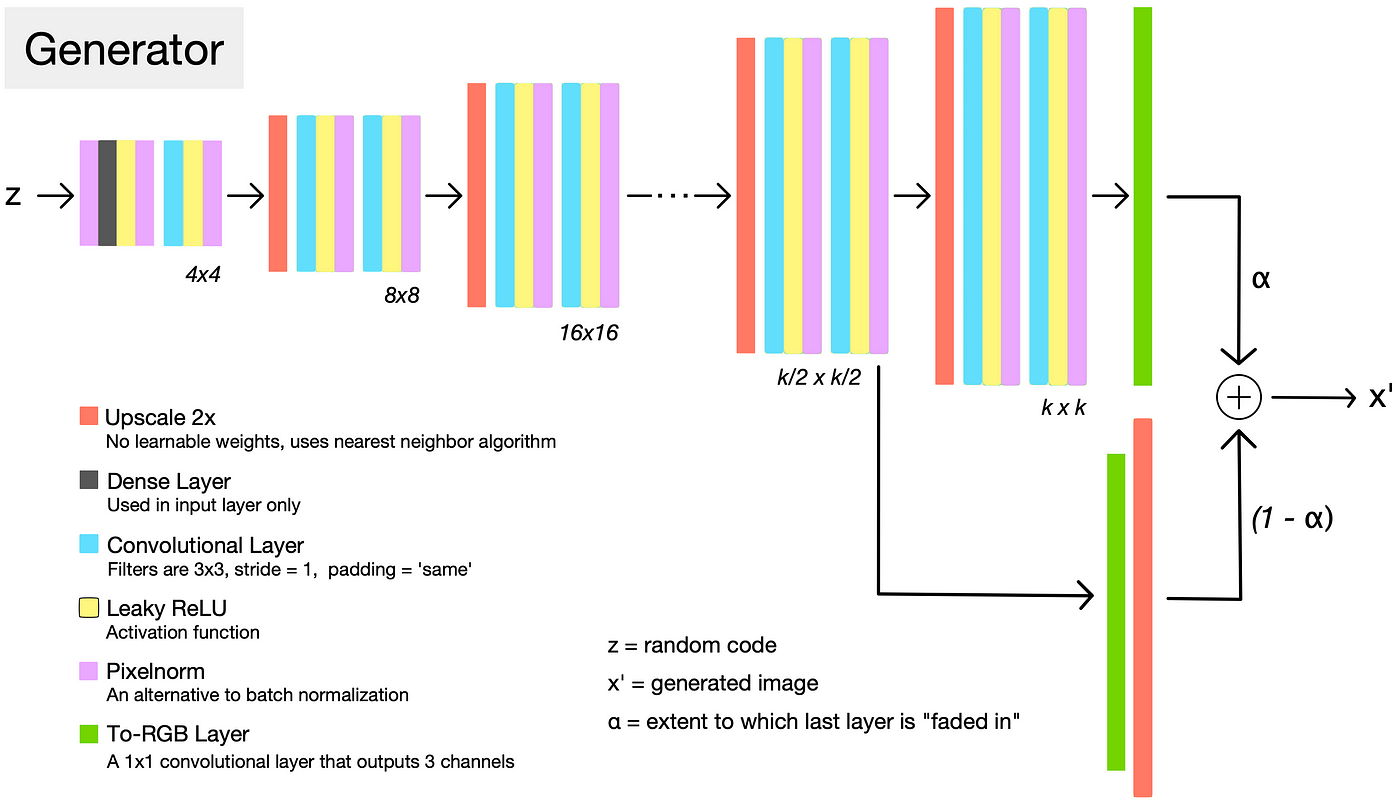
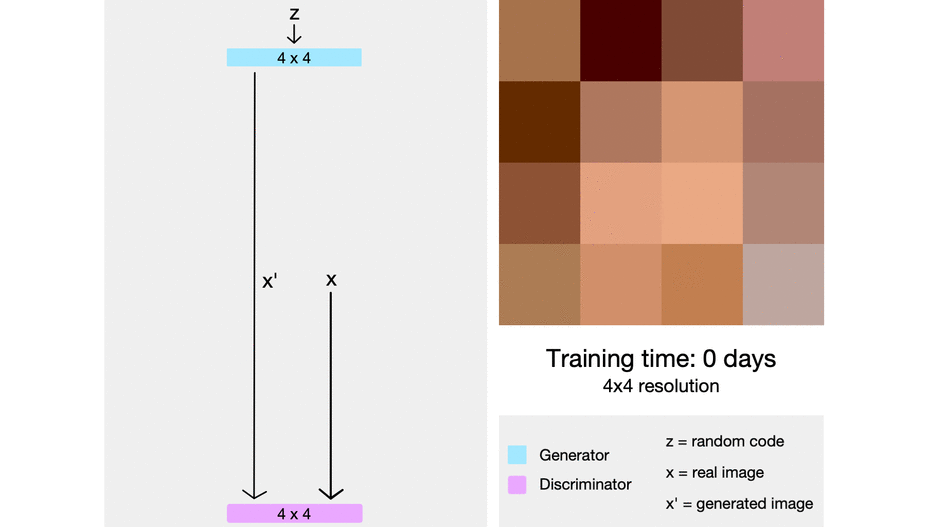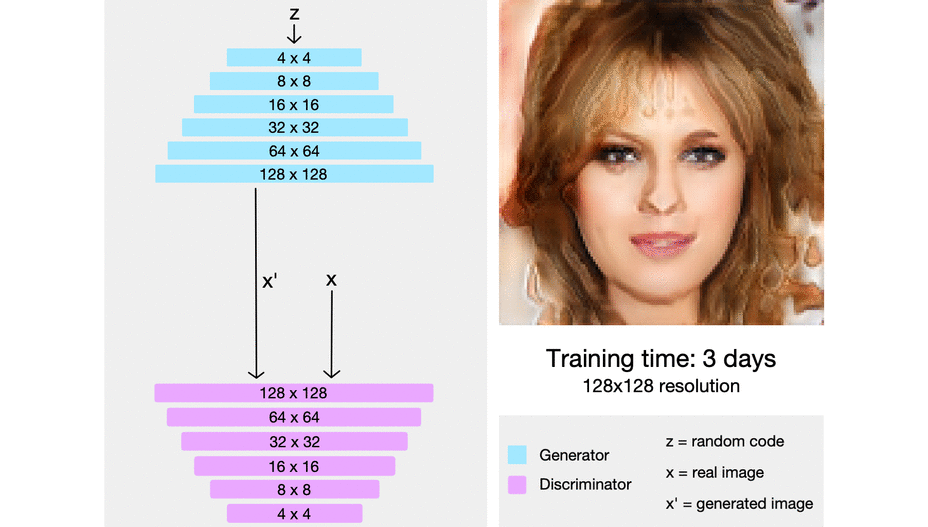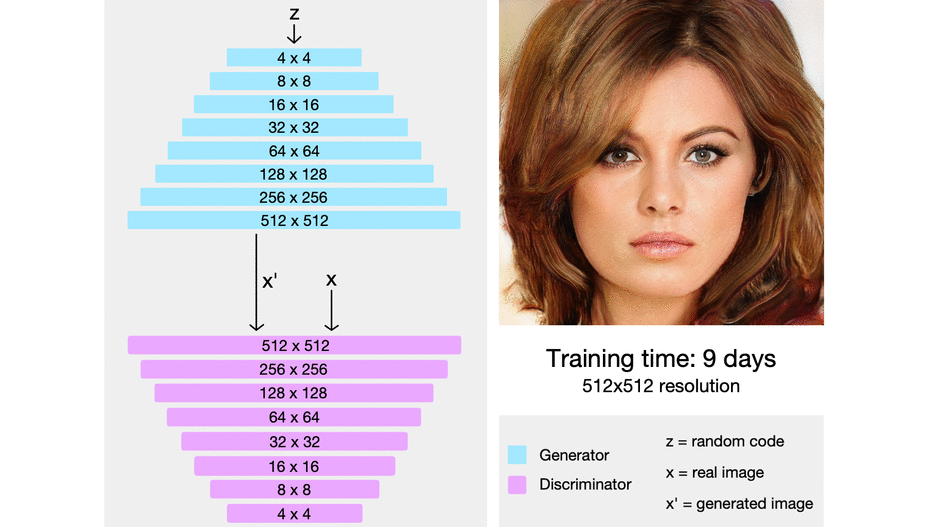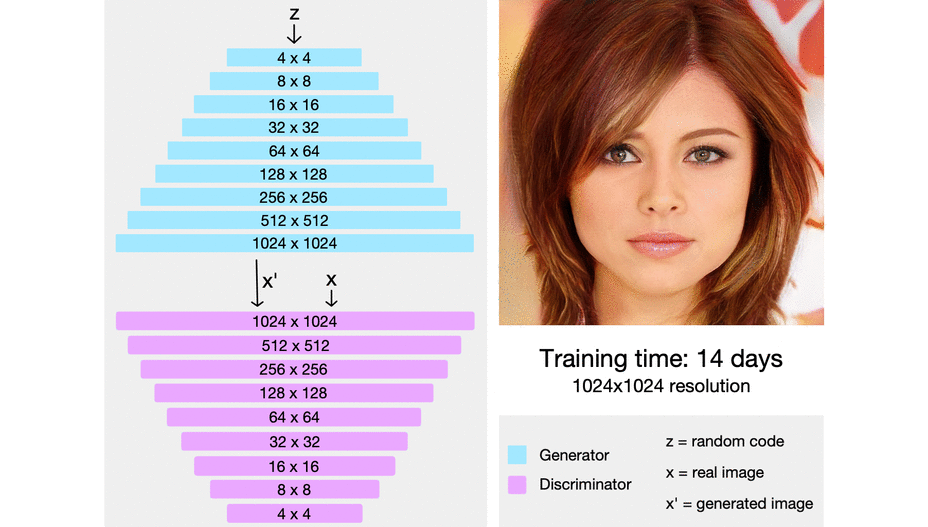
#### MSG-GAN



#### Dataset: CelebA-HQ、FFHQ、LSUN Churches、Indian Celebs、etc
### Result:



https://towardsdatascience.com/progan-how-nvidia-generated-images-of-unprecedented-quality-51c98ec2cbd2
https://hackmd.io/2uePDq5RRwS3M4OFhVq4fQ?both
# [TediGAN: Text-Guided Diverse Face Image Generation and Manipulation](https://arxiv.org/pdf/2012.03308.pdf)
### Abstract:
* a novel framework for multi-modal image generation and manipulation with textual descriptions.
* The proposed method consists of three components: StyleGAN inversion module(根據預訓練的StyleGAN將圖片映射到一個latent space), visual-linguistic similarity learning(將文本和圖片映射到common embedding space來計算相似度), and instance-level optimization(確保修改後人臉的identity不會發生改變).
* 現在最流行的StyleGAN's inversion方法是在一個pretrained的styleGAN generator前,先簡單的學習了letent space(W),不僅可以實現忠實的重建,還可以進行語義上有意義的編輯,且很容易將 W 空間的分層語義特性引入任何 GAN 模型。


#### Contribution:
* Propose a unified framework that can generate diverse images given the same input text, or text with image for manipulation, allowing the user to edit the appearance of different attributes interactively.
* Propose a GAN inversion technique that can map multi-modal information into a common latent space of a pretrained StyleGAN where the instance-level image-text alignment can be learned.
> 
* Introduce the Multi-Modal CelebA-HQ dataset, consisting of multi-modal face images and corresponding textual descriptions, to facilitate the community.
### Method:

#### Dataset: Multi-Modal CelebA-HQ







# [InsetGAN for Full-Body Image Generation](https://arxiv.org/pdf/2203.07293.pdf)
###### CVPR 2022

### Abstract:
* the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose.
* propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas.
#### Contribution:
* We propose a multi-GAN optimization framework that jointly optimizes the latent codes of two or more collaborative generators such that the overall composed result is coherent and free of boundary artifacts when the generated parts are inserted as insets into the generated canvas.
* We demonstrate our framework on the highly challenging full-body human generation task and propose the first viable pipeline to generate plausible-looking humans unconditionally at 1024×1024px resolution.
### Method:

#### Histogram feature:
* color constancy literature
* constructed to be a differentiable histogram of colors in the log-chroma space.
* The histogram is computed from a given input image, I, by first converting it into the log-chroma space.
#### Color-controlled Image Generation
#### Image Recoloring
#### Dataset: Multi-Modal CelebA-HQ
### Result:




# [HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms](https://arxiv.org/pdf/2011.11731.pdf)
###### CVPR 2021

### Abstract:
* Propose HistoGAN, a color histogram-based method for controlling GAN-generated images’ colors.
* Focus on color histograms as they provide an intuitive way to describe image color while remaining decoupled from domain-specific semantics.
* introduce StyleGAN2 to control the colors of GAN-generated images specified by a target color histogram feature.
#### Contribution:
*
### Method:


#### Histogram feature:
* color constancy literature
* constructed to be a differentiable histogram of colors in the log-chroma space.
* The histogram is computed from a given input image, I, by first converting it into the log-chroma space.
#### Color-controlled Image Generation
#### Image Recoloring
#### Dataset: Multi-Modal CelebA-HQ
### Result:




### Conclusion:
* HistoGAN, a simple, yet effective, method for controlling colors of GAN-generated images.
* HistoGAN framework learns how to transfer the color information encapsulated in a target histogram feature to the colors of a generated output image.(They say: this is the first work to control the color of GAN-generated images directly from color histograms. )
* HistoGAN can be extended to control colors of real images in the form of the ReHistoGAN model.
# [Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation](https://openaccess.thecvf.com/content/CVPR2021/papers/Richardson_Encoding_in_Style_A_StyleGAN_Encoder_for_Image-to-Image_Translation_CVPR_2021_paper.pdf)
###### CVPR_2021

### Abstract:
* present a generic image-to-image translation framework, pixel2style2pixel (pSp).
* pSp framework is based on a novel encoder network that directly generates a series of style vectors which are fed into a pretrained StyleGAN generator, forming the extended W+ latent space.
* The encoder can directly embed real images into W+, with no additional optimization.
* solving translation tasks through StyleGAN significantly simplifies the training process, as no adversary is required, has better support for solving tasks without pixel-to-pixel correspondence, and inherently supports multi-modal synthesis via the resampling of styles.
> 因為是提出在pre-train好的styleGAN前一個加一個產生latent code的encoder,所以不需要Discriminator.
> 在這篇之前已經有很多的研究是關於控制latent space以及在W中執行有意義的操作。大多的方法都是採取 “invert first, edit later” ,先將圖像反轉到 StyleGAN 的latent space中,然後以semantically meaningful的方式編輯latent code以獲得new latent code,在把這new latent code丟給styleGAN生成圖片。
<br>
> 若將真實圖像invert為 512 維向量 w ∈ W 不會導致準確的reconstruction。將真實圖像編碼到擴展的潛在空間 W+ 已成為普遍做法。
#### Contribution:
* A novel StyleGAN encoder able to directly encode real images into the W+ latent domain.
* A new methodology for utilizing a pretrained StyleGAN generator to solve imageto-image translation tasks.
### Method:


> * psp encoder的任務是將任意圖像直接編碼為 W+,架構base on Feature Pyramid Network(FPN)。
> * 風格向量從不同的金字塔尺度中提取,並直接插入到與其空間尺度相對應的固定、預訓練的 StyleGAN 生成器中。
> * 他們提出的架構是一個叫psp的encoder,輸入是一個圖片,輸出是latent code
> 
> multi-scale 是一個很大的問題,要如何比較好的提取不同scale的特徵-->FPN

> * 7個從psp encoder出來的和9個randomly出來的W 做style Mixing在一起(concatenation)
#### Dataset: AFHQ(Cat & Dog)、 CelebA-HQ、FFHQ
#### loss function:
* pixel-wise L2 loss:(計算預測和目標圖像的像素間損失)
>用於比較看起來相似的兩幅不同的圖像,比如相同的照片,但在不同分辨率下移動了一個像素或相同的圖像。在這些情況下,儘管圖像非常相似,像素級的損失函數將輸出一個大的誤差值

* perceptual loss:(感知相似度)

* regularization loss:(鼓勵生成的style code 與styleGAN的平均style code的一致性)
> 提高圖像質量,而不會損害我們輸出的保真度(參考styleGAN)

* identity loss:(保證身份信息的一致性。 R表示預訓練的ArcFace網絡。)
> 用預訓練好的人臉識別模型計算輸入和生成圖片的cosine相似度。







### Conclusion:
* 將圖像轉成latent code(psp)
* 將人臉轉正
* 圖像合成(根據草圖或者分割結果生成圖像)
* 將低分辨率圖像轉成高清圖像。
# [GAN](https://arxiv.org/pdf/1406.2661.pdf)
###### tags: 10 Jun 2014

### Training:
* #### Generator:輸入是一個n-D的vector,輸出是一個合成圖像。
> Tips: 這裡的生成器可以是任意可以輸出圖片的模型,比如最簡單的全連接神經網絡,又或者是反捲積網絡等。
* 這裡輸入的向量我們將其視為攜帶輸出的某些信息,比如說手寫數字為數字幾,手寫的潦草程度等等。由於這裡對於輸出數字的具體信息不做要求,只要求其能夠最大程度與真實手寫數字相似(能騙過判別器)即可。所以我們使用隨機生成的向量來作為輸入即可,這裡面的隨機輸入最好是滿足常見分佈比如均值分佈,高斯分佈等。
> Tips: 假如我們後面需要獲得具體的輸出數字等信息的時候,我們可以對輸入向量產生的輸出進行分析,獲取到哪些維度是用於控制數字編號等信息的即可以得到具體的輸出。而在訓練之前往往不會去規定它。
* #### Discriminator:輸入是Generator的輸出圖片,輸出結果是label(Real or Fack)或數字
### Training流程

* 初始化D的參數 和G的參數 。
* 從真實樣本中採樣 m 個樣本,從先驗分佈噪聲中採樣 m 個噪聲樣本並通過生成器獲取 m 個生成樣本 。固定生成器G,訓練判別器D盡可能好地準確判別真實樣本和生成樣本,盡可能大地區分正確樣本和生成的樣本。
* 循環k次更新判別器之後,使用較小的學習率來更新一次生成器的參數,訓練生成器使其盡可能能夠減小生成樣本與真實樣本之間的差距,也相當於盡量使得判別器判別錯誤。
* 多次更新迭代之後,最終理想情況是使得判別器判別不出樣本來自於生成器的輸出還是真實的輸出。亦即最終樣本判別概率均為0.5。
> Tips: 之所以要訓練k次判別器,再訓練生成器,是因為要先擁有一個好的判別器,使得能夠教好地區分出真實樣本和生成樣本之後,才好更為準確地對生成器進行更新。

>* 注:圖中的黑色虛線表示真實的樣本的分佈情況,藍色虛線表示判別器判別概率的分佈情況,綠色實線表示生成樣本的分佈。 Z表示噪聲, Z 到 X 表示通過生成器之後的分佈的映射情況。
我們的目標是使用生成樣本分佈(綠色實線)去擬合真實的樣本分佈(黑色虛線),來達到生成以假亂真樣本的目的。
>*可以看到在(a)狀態處於最初始的狀態的時候,生成器生成的分佈和真實分佈區別較大,並且判別器判別出樣本的概率不是很穩定,因此會先訓練判別器來更好地分辨樣本。
通過多次訓練判別器來達到(b)樣本狀態,此時判別樣本區分得非常顯著和良好。然後再對生成器進行訓練。
>*訓練生成器之後達到(c)樣本狀態,此時生成器分佈相比之前,逼近了真實樣本分佈。
經過多次反複訓練迭代之後,最終希望能夠達到(d)狀態,生成樣本分佈擬合於真實樣本分佈,並且判別器分辨不出樣本是生成的還是真實的(判別概率均為0.5)。也就是說我們這個時候就可以生成出非常真實的樣本啦,目的達到。
## [High-Resolution Photorealistic Image Translation in Real-Time:A Laplacian Pyramid Translation Network](https://arxiv.org/pdf/2105.09188.pdf)
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [DG-Font: Deformable Generative Networks for Unsupervised Font Generation](https://arxiv.org/pdf/2104.03064.pdf)
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing](https://arxiv.org/pdf/2104.14754.pdf)
> #### CVPR 2021 首爾大學
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [Context Encoders: Feature Learning by Inpainting](https://arxiv.org/pdf/1604.07379.pdf)
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [Free-Form Image Inpainting with Gated Convolution](https://openaccess.thecvf.com/content_ICCV_2019/papers/Yu_Free-Form_Image_Inpainting_With_Gated_Convolution_ICCV_2019_paper.pdf)
> ##### ICCV 2019
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [Coherent Semantic Attention for Image Inpainting](https://openaccess.thecvf.com/content_ICCV_2019/papers/Liu_Coherent_Semantic_Attention_for_Image_Inpainting_ICCV_2019_paper.pdf)
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [Bayesian Image Reconstruction using Deep Generative Models](https://arxiv.org/pdf/2012.04567v4.pdf)
### Abstract:
### Method:
#### Dataset: CelebA-HQ,Places2 and Paris Street View
#### Input:
#### Output:
### Conclusion:
## [Editing Text in the Wild](https://arxiv.org/pdf/1908.03047v1.pdf)
### Abstract:
### Method:
#### Dataset:
#### Input:
#### Output:
### Conclusion:
## [3D Photography using Context-aware Layered Depth Inpainting](https://arxiv.org/pdf/2004.04727.pdf)
### Abstract:
### Method:
#### Dataset:
#### Input:
#### Output:
### Conclusion:
## [Few-Shot Adversarial Learning of Realistic Neural Talking Head Models](https://arxiv.org/pdf/1905.08233.pdf)
### Abstract:
### Method:
#### Dataset:
#### Input:
#### Output:
### Conclusion:
## [First Order Motion Model for Image Animation](https://proceedings.neurips.cc/paper/2019/file/31c0b36aef265d9221af80872ceb62f9-Paper.pdf)
### Abstract:
### Method:
#### Dataset:
#### Input:
#### Output:
### Conclusion:
## [Coherent Semantic Attention for Image Inpainting](https://openaccess.thecvf.com/content_ICCV_2019/papers/Liu_Coherent_Semantic_Attention_for_Image_Inpainting_ICCV_2019_paper.pdf)
### Abstract:
### Method:
#### Dataset:
#### Input:
#### Output:
### Conclusion:
## [Distributed vector Processing of a new local MultiScale Fourier transform for medical imaging applications](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1425674)
## [Deep Learning Applications in Medical Image Analysis](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8241753)
## [GAN](https://arxiv.org/pdf/1406.2661v1.pdf)
## [DiNTS: Differentiable Neural Network Topology Search for 3D Medical Image Segmentation](https://arxiv.org/pdf/2103.15954.pdf)
## [High-Resolution Photorealistic Image Translation in Real-Time: A Laplacian Pyramid Translation Network](https://arxiv.org/pdf/2105.09188.pdf)
### Abstract:
* 現有的image-to-image translation (I2IT)遇到的問題:
* 局限於低分辨率的Image
* 由於對高分辨率特徵圖的convolution有計算負擔而導致推理時間長
### Method:
### Conclusion:
## xxx
###### tags:
### Abstract:
### Method:
### Conclusion: