---
title: 'Integración de Sistemas 2'
disqus: hackmd
---
# Integración de sistemas 2
###### tags: `Integración de Sistemas`, `Camel`, `ActiveMQ`, `UCOM`
Tabla de contenido
=
[TOC]
Integración de múltiples sistemas
---
¡La integración es compleja! En el curso pasado vimos como integrar sistemas con socket, webservices SOAP y API REST. Nos faltó citar otros como colas de mensajes, llamadas RPC, RMI, JMS, AMQP o STOMP. Además, hay
otras formas más tradicionales de integración, como el acceso e intercambio de bases de datos compartidasde archivos, todavía muy común en los sistemas heredados.
### Ejemplo de integración directa sin framework de integración ni API:
```mermaid
graph TD
A[Caja] -->|sube archivos| B(fa:fa-server Servidor FTP)
B --> |descarga archivos| C[Comercial]
C --> |odbc|D(fa:fa-database Oracle-Comercial)
E[Logística] -->|odbc| D
F[Contabilidad] -->|odbc| G(fa:fa-database Postgres-Contabilidad)
C --> |archivo xlsx|F
```
<center><b>Fig1. Integración con archivos y base de datos</b></center>
### Ejemplo de integración directa con REST API sin transformaciones de datos:
```mermaid
graph TD
C --> |odbc|D(fa:fa-database Oracle-Comercial)
A[Caja] --> |API Comercial|C[Comercial]
C --> A
E[Logística] --> |API Comercial|C
C --> E
C -->|API Comercial|F
F --> C
F[Contabilidad] -->|odbc| G(fa:fa-database Postgres-Contabilidad)
```
<center><b>Fig2. Integración con API REST</b></center>
</br>
Un **framework de integración** ayuda a disminuir la complejidad y el impacto del código de integración escrito, ya que no tendremos que "reinventar la rueda". En definitiva, seguir los estándares de integración beneficia el mantenimiento de nuestro código.
¿Qué son los patrones de diseño / design patterns?
---
> Los patrones de diseño o *design patterns*, son soluciones generales, reutilizables y aplicables a diferentes problemas recurrentes de diseño de software.
Se trata de plantillas que identifican problemas en el sistema y proporcionan soluciones apropiadas a problemas generales a los que se han enfrentado los desarrolladores durante un largo periodo de tiempo, a través de prueba y error.
Ejemplo. Patrón Observer
---
El patrón de diseño ***Observer, Observer Pattern*** o **Patrón Observador** es uno de los patrones de diseño de software más populares. Esta herramienta ofrece la posibilidad de definir una dependencia uno a uno entre dos o más objetos para transmitir todos los cambios de un objeto concreto de la forma más sencilla y rápida posible.
El patrón ***Observer*** trabaja con dos tipos de actores: por un lado, ==**el sujeto**==, es decir, el objeto cuyo estado quiere vigilarse a largo plazo. Por otro lado, están los ==**objetos observadores**==, que han de ser informados de cualquier cambio en el sujeto (ver **Fig3**).

<center><b>Fig3. Diagrama de interacción del patrón Observador</b></center>
<br><br>

<center><b>Fig4. Diagrama de clase </b></center>
<br><br>
Los componentes del patrón se explican a continuación (**Fig. 4**):
**IObservable:** Interface que deben de implementar todos los objetos que quieren ser observados, en ella se definen los métodos mínimos que se deben implementar.
**ConcreteObservable:** Clase que desea ser observada, ésta implementa IObservable y debe implementar sus métodos.
**IObserver:** Interfaces que deben implementar todos los objetos que desean observar los cambios de IObservable.
**ConcreteObserver:** Clase concreta que está atenta de los cambios de IObserver, esta clase hereda de IObserver y debe de implementar sus métodos.

<center><b>Fig5. diagrama de sequencia de interacción</b></center>
Enterprise Integration Patterns (EIPs)
=
Analizando los desafíos recurrentes en la integración de sistemas, los autores Gregor Hohpe y Bobby Woolf, escribieron el libro de referencia de patrones de integración empresarial ([Enterprise Integration Patterns - EIP](https://en.wikipedia.org/wiki/Enterprise_Integration_Patterns)) para ayudar a los desarrolladores y arquitectos de sistemas a simplificar la integración de sistemas.
Los patrones proporcionan una guía de diseño independiente de la tecnología para que los desarrolladores y arquitectos describan y desarrollen soluciones de integración sólidas.
Porqué utilizar patrones
--
Los patrones son lo suficientemente abstractos como para aplicarse a la mayoría de las tecnologías de integración, pero lo suficientemente específicos como para brindar orientación práctica a diseñadores y arquitectos. Los patrones también proporcionan un vocabulario para que los desarrolladores describan eficientemente su solución.
Los patrones no se 'inventan'; se obtienen del uso repetido en la práctica. Si ha creado soluciones de integración, es probable que haya utilizado algunos de estos patrones, tal vez con ligeras variaciones y tal vez llamándolos por un nombre diferente.
[Algunos patrones de Mensajes: Fig6.](https://www.enterpriseintegrationpatterns.com/patterns/messaging/)

**Fig1. 6 patrones de Mensajes**
Opciones de integración de aplicaciones
==
Hay más de un enfoque para integrar aplicaciones. Cada enfoque aborda algunos de los criterios de integración mejor que otros. Los diversos enfoques se pueden resumir en cuatro estilos principales de integración:
* **Transferencia de archivos:** haga que cada aplicación produzca archivos de datos compartidos para que otros los consuman y consuma archivos que otros han producido.
* **Base de datos compartida:** haga que las aplicaciones almacenen los datos que desean compartir en una base de datos común.
* **Invocación de procedimientos remotos:** haga que cada aplicación exponga algunos de sus procedimientos para que puedan invocarse de forma remota y que las aplicaciones los invoquen para ejecutar comportamientos e intercambiar datos.
* **Mensajería:** haga que cada aplicación se conecte a un sistema de mensajería común e intercambie datos e invoque el comportamiento mediante mensajes.
Cada uno de los patrones intenta resolver el mismo problema, la necesidad de integrar aplicaciones, en contextos muy similares. Lo que los diferencia son diferentes fuerzas que buscan una solución más elegante. Cada patrón se basa en el anterior, buscando un enfoque más sofisticado para abordar las deficiencias de sus predecesores. Así, el orden de los patrones refleja un orden creciente de sofisticación.
El truco no es elegir el estilo que se usará siempre, sino elegir el mejor estilo para una oportunidad de integración en particular. Cada estilo tiene sus ventajas y desventajas. Dos aplicaciones pueden integrarse utilizando múltiples estilos, de modo que cada punto de integración aproveche el estilo que mejor se adapte a él.
> **En este curso nos enfocamos en la mensajería en parte porque creemos que a menudo es el mejor estilo para resolver muchas oportunidades de integración.**
También es el menos entendido de los estilos de integración y una tecnología madura con patrones que explican rápidamente cómo hacer un buen uso de ella. Finalmente, la mensajería es la base de muchos productos de Integración de Aplicaciones Empresariales, por lo que explicar cómo usar bien la mensajería también contribuye en gran medida a enseñarle cómo usar esos productos.
Familiarícese con estos patrones para comprender mejor los problemas relacionados con la integración de aplicaciones y para comprender mejor cómo encaja la mensajería en en el conjunto.
Conceptos básicos de mensajería
==

Cuando dos aplicaciones desean intercambiar datos, lo hacen enviando los datos a través de un canal que los conecta. Es posible que la aplicación que envía los datos no sepa qué aplicación recibirá los datos, pero al seleccionar un canal en particular para enviar los datos, el remitente sabe que el receptor buscará ese tipo de datos buscándolos en ese canal. canal. De esta forma, las aplicaciones que producen datos compartidos tienen una forma de comunicarse con aquellos que desean consumirlos.
Decidir usar un canal de mensajes es la parte simple; si una aplicación tiene datos para transmitir o datos que desea recibir, tendrá que usar un canal. El desafío es saber qué canales necesitarán las aplicaciones y para qué usarlos.
* **Conjunto fijo de canales :** el conjunto de canales de mensajes disponibles para una aplicación tiende a ser estático. Al diseñar una aplicación, un desarrollador debe saber dónde colocar qué tipos de datos para compartir esos datos con otras aplicaciones y, de la misma manera, dónde buscar qué tipos de datos provienen de otras aplicaciones. Estas rutas de comunicación no se pueden crear y descubrir dinámicamente en tiempo de ejecución; deben acordarse en el momento del diseño para que la aplicación sepa de dónde provienen los datos y hacia dónde se dirigen. (Si bien es cierto que la mayoría de los canales deben definirse estáticamente, existen excepciones a este tema, casos en los que los canales dinámicos son prácticos y útiles).
* **Determinación del conjunto de canales :** un problema relacionado es: quién decide qué canal de mensajess están disponibles, el sistema de mensajería o las aplicaciones? Es decir: ¿El sistema de mensajería define ciertos canales y requiere que las aplicaciones cumplan con ellos? ¿O las aplicaciones determinan qué canales necesitan y requieren que el sistema de mensajería los proporcione? Las aplicaciones determinan los canales que deberá proporcionar el sistema de mensajería. Las aplicaciones posteriores intentarán diseñar su comunicación en torno a los canales disponibles, pero cuando esto no sea práctico, requerirán que se agreguen canales adicionales.
* **Canales unidireccionales :** otra fuente común de confusión es si un canal de mensajeses unidireccional o bidireccional. Técnicamente, no es ninguno; un canal es más como un cubo al que algunas aplicaciones agregan datos y otras aplicaciones toman datos (aunque un cubo que se distribuye entre varias computadoras de manera coordinada). Pero debido a que los datos están en mensajes que viajan de una aplicación a otra, eso le da dirección al canal, haciéndolo unidireccional. Si un canal fuera bidireccional, eso significaría que una aplicación enviaría y recibiría mensajes del mismo canal, lo cual, aunque técnicamente es posible, tiene poco sentido porque la aplicación tendería a seguir consumiendo sus propios mensajes, los mensajes que supuestamente envió a otras aplicaciones. Entonces, para todos los propósitos prácticos, los canales son unidireccionales. Como consecuencia, para que 2 aplicaciones mantengan una conversación, deberá haber 2 canales).
### Patrones de mensajería
Cuando dos aplicaciones desean intercambiar un dato, lo hacen envolviéndolo en un mensaje. Mientras que un canal de mensajes no puede transmitir datos crudos, puede transmitir los datos envueltos en un mensaje.
La decisión de crear un mensaje y enviarlo plantea varios problemas, para lo cual se puede utilizar algunos patrones definidos:
* **Intención del mensaje :** en última instancia, los mensajes son solo paquetes de datos, pero el remitente puede tener diferentes intenciones sobre lo que espera que el receptor haga con el mensaje. Puede enviar un mensaje de comando (patrón ==*Command Message*==) , especificando una función o método en el receptor que el remitente desea invocar. El remitente le dice al receptor qué código ejecutar. Puede enviar un mensaje de documento(patrón ==*Document Message*==) , lo que permite al remitente transmitir una de sus estructuras de datos al receptor. El remitente pasa los datos al receptor, pero no especifica qué debe hacer necesariamente el receptor con ellos. O puede enviar un Mensaje de evento(patrón ==*Event Message*==) , notificando al receptor de un cambio en el remitente. El remitente no le dice al receptor cómo reaccionar, solo proporciona una notificación.
* **Devolver una respuesta :** cuando una aplicación envía un mensaje, a menudo espera una respuesta que confirme que el mensaje ha sido procesado y proporcione el resultado. Este es un escenario de Solicitud-Respuesta (*Request-Reply*) . La solicitud suele ser un ``mensaje de comando`` y la respuesta es un ==mensaje de documento== que contiene un valor de resultado o una excepción. El solicitante debe especificar una ``dirección de devolución``(patrón ==*Return Address*==) en la solicitud para decirle al que responde qué canal usar para transmitir la respuesta. El solicitante puede tener varias solicitudes en proceso, por lo que la respuesta debe contener un ``identificador de correlación``(patrón ==*Correlation Identifier*==) que especifique a qué solicitud corresponde esta respuesta.
* **Grandes cantidades de datos :** a veces, las aplicaciones desean transferir una estructura de datos realmente grande, que puede no caber cómodamente en un solo mensaje. En este caso, divida los datos en fragmentos más manejables y envíelos como una secuencia de mensajes (patrón ==*Message Sequence*==) . Los fragmentos deben enviarse como una secuencia, y no solo como un montón de mensajes, para que el receptor pueda reconstruir la estructura de datos original.
* **Mensajes lentos :** una preocupación con la mensajería es que el remitente a menudo no sabe cuánto tardará el receptor en recibir el mensaje. Sin embargo, el contenido del mensaje puede ser sensible al tiempo, de modo que si el mensaje no se recibe antes de la fecha límite, simplemente debe ignorarse y descartarse. En esta situación, el remitente puede utilizar la ``Caducidad del mensaje``(patrón ==*Message Expiration*==) para especificar una fecha de caducidad. Si el sistema de mensajería no puede entregar un mensaje antes de su vencimiento, debe descartar el mensaje. Si un receptor recibe un mensaje después de su vencimiento, debe descartarlo.
[Enterprise Integration Patterns (EIPs)- Ejemplos ](https://camel.apache.org/components/next/eips/enterprise-integration-patterns.html)
==
## Mensaje - *MESSAGE*

El paquete de información a transmitir se realiza mediante un Mensaje, un registro de datos que el sistema de mensajería puede transmitir a través de un canal de mensajes.
Por lo tanto, cualquier dato que deba transmitirse a través de un sistema de mensajería debe convertirse en uno o más mensajes que puedan enviarse a través de canales de mensajería.
En Apache Camel, cada mensaje contiene la siguiente información:
* **cuerpo:** el cuerpo del mensaje (es decir, la carga útil)
* **headers** - encabezados con información adicional
* **messageId:** identificación única del mensaje. De manera predeterminada, el mensaje usa la misma identificación que Exchange.getExchangeId
* **timestamp:** la marca de tiempo de la que se origina el mensaje. Algunos sistemas como JMS, Kafka, AWS tienen una marca de tiempo en el evento/mensaje que recibió Camel. Este método devuelve la marca de tiempo, si existe una marca de tiempo.
## Request Reply

Cuando una aplicación envía un mensaje, ¿cómo puede obtener una respuesta del receptor?
Se logra enviando un par de mensajes de Solicitud-Respuesta, cada uno en su propio canal.
## *Event Message* o Mensaje de Evento

¿Cómo se puede usar la mensajería para transmitir eventos de una aplicación a otra?
Para estos casos se utiliza un ==**Mensaje de evento o *Event Message***== para una notificación asíncrona y confiable de eventos entre aplicaciones.
Utilice un mensaje de evento para una notificación de eventos asíncrona y confiable entre aplicaciones.
Cuando un sujeto tiene un evento que anunciar, creará un objeto de evento, lo envolverá en un mensaje y lo enviará por un canal. El observador recibirá el mensaje del evento, obtendrá el evento y lo procesará. La mensajería no cambia la notificación del evento, solo se asegura de que la notificación llegue al observador.
### En Camel
Camel admite el mensaje de evento mediante el patrón de intercambio en un mensaje que se puede configurar en ***InOnly*** para indicar un mensaje de evento unidireccional.
El comportamiento predeterminado de muchos componentes es InOnly, como JMS, File o SEDA.
Algunos componentes admiten tanto InOnly como InOut y actúan en consecuencia. Por ejemplo, el JMS puede enviar mensajes unidireccionales (InOnly) o usar mensajes de solicitud/respuesta (InOut).
#### Ejemplo en Camel:
En el ejemplo a continuación, el mensaje se forzará como un mensaje de evento ya que el consumidor está en modo InOnly.
```java
from("mq:someQueue?exchangePattern=InOnly")
.to("activemq:cola:unidireccional");
```
o modificando el Componente Exchange
```java
from("mq:someQueue")
.setExchangePattern(ExchangePattern.InOnly)
.to("activemq:queue:one-way");
```
## *Translator* o Traductor

Los patrones anteriores describen cómo construir mensajes y cómo enrutarlos al destino correcto. En muchos casos, las soluciones de integración empresarial enrutan mensajes entre aplicaciones existentes, como sistemas heredados, aplicaciones empaquetadas, aplicaciones personalizadas de desarrollo propio o aplicaciones operadas por socios externos. Cada una de estas aplicaciones generalmente se basa en un modelo de datos propietario. Cada aplicación puede tener una noción ligeramente diferente de la entidad Cliente, los atributos que definen a un Cliente y con qué otras entidades está relacionado un Cliente. Por ejemplo, el sistema de contabilidad puede estar más interesado en los números de identificación del contribuyente del cliente, mientras que el sistema de gestión de relaciones con el cliente (CRM) almacena números de teléfono y direcciones. El modelo de datos subyacente de la aplicación generalmente impulsa el diseño del esquema de la base de datos física, un formato de archivo de interfaz o una interfaz de programación (API), aquellas entidades con las que una solución de integración tiene que interactuar. Como resultado, las aplicaciones esperan recibir mensajes que imitan el formato de datos internos de la aplicación.
Además de los modelos de datos propietarios y los formatos de datos incorporados en las diversas aplicaciones, las soluciones de integración a menudo interactúan con formatos de datos estandarizados que buscan ser independientes de aplicaciones específicas.
¿Cómo pueden los sistemas que utilizan diferentes formatos de datos comunicarse entre sí mediante mensajería?
El ==**traductor de mensajes**==,pueden y sirven para transformar los mensajes mientra viajan desde el origen al destino.
## Canal de comunicación - *Message Channel*

La comunicación entre aplicaciones se realiza mediante un canal de mensajes, donde una aplicación escribe información en el canal y la otra lee esa información del canal.
Cuando una aplicación tiene información para comunicar, no solo envía la información al sistema de mensajería, sino que la agrega a un canal de mensajes en particular. Una aplicación que recibe información no la recoge al azar del sistema de mensajería; recupera la información de un canal de mensajes en particular.
En Apache Camel, elcanal de mensajes es un detalle de implementación interna de la interfaz del *endpoint*, donde todas las interacciones del canal se realizan a través del *endpoint*.
## Punto de conexión o *Message EndPoints*

Los *endpoints* sirven para conectar una aplicación a un canal de mensajería mediante un *``Message Endpoint``*, un cliente del sistema de mensajería que la aplicación puede usar para enviar o recibir mensajes.
El código del *``Message Endpoint``* o *``Endpoint``* es personalizado tanto para la aplicación como para la API del cliente del sistema de mensajería. El resto de la aplicación sabe poco sobre formatos de mensajes, canales de mensajería o cualquier otro detalle de la comunicación con otras aplicaciones a través de mensajería. Solo sabe que tiene una solicitud o un dato para enviar a otra aplicación, o los está esperando de otra aplicación. Es el código del ``*Endpoint*`` el que toma ese comando o datos, lo convierte en un mensaje y lo envía a un canal de mensajería en particular. Es el *Endpoint* el que recibe un mensaje, extrae los contenidos y los entrega a la aplicación de manera significativa.
## Tubería o *PipeLine*

En muchos escenarios de integración empresarial, un solo evento desencadena una secuencia de pasos de procesamiento, cada uno de los cuales realiza una función específica. Por ejemplo, supongamos que llega un nuevo pedido a nuestra empresa en forma de mensaje. Un requisito puede ser que el mensaje esté encriptado. Un segundo requisito es que los mensajes contengan información de autenticación en forma de certificado digital. Además, se pueden enviar mensajes duplicados desde terceros. Para evitar envíos duplicados y clientes insatisfechos, debemos eliminar los mensajes duplicados antes de que se inicien los pasos de procesamiento de pedidos posteriores.
> ¿Cómo podemos realizar un procesamiento complejo en un mensaje manteniendo la independencia y la flexibilidad?
Utilice el estilo arquitectónico Tuberías o *Pipes* y filtros para dividir una tarea de procesamiento más grande en una secuencia de pasos de procesamiento independientes más pequeños (filtros) que están conectados por canales (tuberías).
Cada filtro expone una interfaz muy simple: recibe mensajes en la tubería de entrada, procesa el mensaje y publica los resultados en la tubería de salida. La tubería conecta un filtro con el siguiente, enviando mensajes de salida de un filtro al siguiente.
#### Ejemplo en Camel:
En el ejemplo a continuación, el mensaje cada mensaje será procesado en cascada.
```java
from("activemq:SomeQueue")
.pipeline()
.to("bean:foo")
.to("bean:bar")
.to("acitvemq:OutputQueueu");
```
# Patrones de Ruteo de Mensajes
## Message Broker

¿Cómo se puede desvincular el destino de un mensaje del remitente y mantener un control central sobre el flujo de mensajes?
Para lograrlo se utiliza un ==*Message Broker*==, el cual puede recibir mensajes de múltiples orígenes, determinar el destino correcto y enrutar el mensaje al canal correcto.
Un ==*Message Broker*== permite a las aplicaciones, sistemas y servicios comunicarse entre sí e intercambiar información. El message broker desempeña esta función traduciendo mensajes entre protocolos de mensajería formal. Esto permite que los servicios interdependientes "hablen" entre sí directamente, incluso si fueron escritos en diferentes idiomas o implementados en diferentes plataformas.
Con el fin de proporcionar almacenamiento de mensajes fiable y entrega garantizada, los ==*Message Broker*== a menudo se basan en una subestructura o componente denominado cola de mensajes que almacena y ordena los mensajes hasta que las aplicaciones consumidoras puedan procesarlos. En una cola de mensajes, los mensajes se almacenan en el orden exacto en el que se transmitieron y permanecen en la cola hasta que se confirma la recepción.

### Modelos de message broker
Los message brokers ofrecen dos patrones básicos de distribución de mensajes o estilos de mensajería:
**Mensajería de punto a punto:** este es el patrón de distribución que se utiliza en las colas de mensajes con una relación unívoca entre el remitente y el destinatario del mensaje. Cada mensaje de la cola se envía a un solo destinatario y se consume sólo una vez. La mensajería de punto a punto es llamada cuando un mensaje debe actuar sólo una vez. Ejemplos de casos de uso adecuados para este estilo de mensajería incluyen el procesamiento de transacciones financieras y de nóminas. En estos sistemas, tanto los remitentes como los receptores necesitan una garantía de que cada pago se enviará una vez y sólo una vez.

**Mensajería de publicación/suscripción:** en este patrón de distribución de mensajes, a menudo denominado "pub/sub", el productor de cada mensaje lo publica en un tema y varios consumidores de mensajes se suscriben a temas sobre los cuales desean recibir mensajes. Todos los mensajes publicados en un tema se distribuyen a todas las aplicaciones suscritas. Se trata de un método de distribución de estilo de difusión, en el que existe una relación entre el editor del mensaje y sus consumidores. Por ejemplo, si una aerolínea difunde actualizaciones sobre las horas de aterrizaje o el estado de retraso de sus vuelos, varias partes podrían utilizar esta información: tripulaciones terrestres que realizan mantenimiento y reabastecimiento de aviones, manipuladores de equipaje, comisarios de abordo y pilotos que se preparan para el próximo viaje del avión, y los operadores de las pantallas que informan al público. Un estilo de mensajería pub/sub sería adecuado para su uso en este caso de ejemplo.

[Camel - Patrón Productor/Suscriptor](https://camel.apache.org/components/4.10.x/eips/publish-subscribe-channel.html)
## *Multicast* o multidifusión

El EIP de multidifusión permite enrutar **el mismo mensaje a** varios ***endpoints*** y procesarlos de manera diferente.
El EIP de multidifusión tiene muchas funciones y también se utiliza como línea de base para la lista de destinatarios y los EIP divididos. Por ejemplo, el EIP de multidifusión es capaz de agregar cada mensaje de multidifusión en un solo mensaje de respuesta como resultado después del EIP de multidifusión.
[Multicast - Documentación Camel](https://camel.apache.org/components/4.10.x/eips/multicast-eip.html)
## *Content base router* - Ruteador basado en contenido

Supongamos que estamos construyendo un sistema de procesamiento de pedidos. Cuando se recibe un pedido entrante, primero validamos el pedido y luego verificamos que el artículo pedido esté disponible en el almacén. Esta función la realiza el sistema de inventario. Esta secuencia de pasos de procesamiento es un candidato perfecto para el estilo ==**Tuberías o *Pipes***== + ==**Filtros**==. Creamos dos filtros, uno para el paso de validación y otro para el sistema de inventario, y enrutamos los mensajes entrantes a través de ambos filtros. Sin embargo, en muchos escenarios de integración empresarial existe más de un sistema de inventario y cada sistema puede manejar solo artículos específicos.
¿Cómo manejamos una situación en la que la implementación de una sola función lógica (por ejemplo, verificación de inventario) se distribuye en múltiples sistemas físicos?
Utilizamos el patrón ==**Enrutador basado en contenido**== para enrutar cada mensaje al destinatario correcto según el contenido del mensaje.
El enrutador basado en contenido examina el contenido del mensaje y enruta el mensaje a un canal diferente según los datos contenidos en el mensaje. El enrutamiento se puede basar en una serie de criterios, como la existencia de campos, valores de campo específicos, etc. Al implementar un enrutador basado en contenido, se debe tener especial cuidado para que la función de enrutamiento sea fácil de mantener, ya que el enrutador puede convertirse en un punto de mantenimiento frecuente. En escenarios de integración más sofisticados, el enrutador basado en contenido puede adoptar la forma de un motor de reglas configurable que calcula el canal de destino en función de un conjunto de reglas configurables.
### En CAMEL
En camel el ==**Enrutador basado en contenido**== está implementado como el componente ==**CHOICE**==[Ver documentación](https://camel.apache.org/components/4.10.x/eips/choice-eip.html).
El EIP ==CHOICE== es un **enrutador basado en contenido** le permite enrutar los mensajes al destino correcto en función del contenido de los intercambios de mensajes.
## Filter

¿Cómo puede un componente evitar recibir mensajes poco interesantes?
Utilice un tipo especial de enrutador de mensajes, el patrón **Filtro de mensajes** , para eliminar los mensajes no deseados de un canal en función de un conjunto de criterios.
El filtro de mensajes tiene un solo canal de salida. Si el contenido del mensaje coincide con los criterios especificados por el filtro de mensajes , el mensaje se enruta al canal de salida. Si el contenido del mensaje no coincide con los criterios, el mensaje se descarta.
### En Camel
El filtro de mensajes implementado en Camel es similar a
```if (predicate) { block }``` en Java. El filtro incluirá el mensaje si el predicado se evaluó como verdadero.
### Ejemplo típico de uso
- Solo procesar pedidos con valor mayor a 1000.
- Ignorar mensajes que no tengan ciertos campos.
- Rechazar eventos repetidos o inválidos.
---
### Implementación en Apache Camel
```java
from("direct:entrada")
.filter(simple("${header.tipo} == 'IMPORTANTE'"))
.to("log:mensaje_valido")
.end();
```
### Consideraciones
- Los mensajes descartados no se almacenan a menos que se capture explícitamente.
- Puede combinarse con un Dead Letter Channel para no perder mensajes.
[Documentación Camel](https://camel.apache.org/components/4.10.x/eips/filter-eip.html)
## *Message Expiration* o Caducidad del mensaje

Si los datos o la solicitud de un Mensaje no se reciben en un tiempo determinado, es inútil y debe ignorarse.
¿Cómo puede un remitente indicar cuándo un mensaje debe considerarse obsoleto y, por lo tanto, no debe procesarse?
Se puede especificar un límite de tiempo durante el cual el mensaje es viable utilizando el patrón ==***Message Expiration o Caducidad de mensaje***==.
Una vez que pasa el tiempo durante el cual un mensaje es viable, y el mensaje aún no se ha consumido, el mensaje caducará. Los consumidores del sistema de mensajería ignorarán un mensaje caducado; tratan el mensaje como si nunca hubiera sido enviado. La mayoría de las implementaciones de sistemas de mensajería redirigen los mensajes vencidos al canal de mensajes fallidos, mientras que otros simplemente descartan los mensajes vencidos; esto puede ser configurable.
### En Camel
## Routing Slip (Guía de Enrutamiento)

<center><b>Fig. Routing Slip</b></center>
> ¿Cómo enrutar dinámicamente un mensaje a través de una secuencia de pasos definidos en tiempo de ejecución?
El patrón **Routing Slip** permite definir **en tiempo de ejecución** la secuencia de destinos por los que debe pasar un mensaje. La ruta se especifica como una lista de endpoints, y el mensaje se enruta siguiendo esa lista.
Este patrón es útil cuando el flujo de procesamiento **varía según el contenido del mensaje, reglas de negocio o configuración externa**, permitiendo diseñar procesos más dinámicos y flexibles.
---
### Motivación
En lugar de codificar la secuencia de rutas directamente en la lógica del sistema, el Routing Slip **desacopla** el flujo de enrutamiento, permitiendo definirlo en tiempo de ejecución.
Este patrón es ideal para:
- Workflows configurables por el usuario
- Orquestación dinámica de servicios
- Sistemas que deben evolucionar sin recodificar rutas
---
### ¿Cómo funciona?
1. Se adjunta al mensaje una lista de endpoints (la "slip").
2. Cada destino es invocado secuencialmente.
3. Al llegar al final de la lista, el procesamiento termina.
### Ventajas
- Alta flexibilidad y extensibilidad del flujo.
- Desacopla la lógica de enrutamiento de la lógica de negocio.
- Permite implementar flujos personalizables y adaptativos.
### Consideraciones
- Requiere validar que todos los destinos existan y estén disponibles.
- La secuencia puede depender de permisos, configuraciones o reglas cambiantes.
- -Puede dificultar el seguimiento del flujo si no se audita correctamente.
---
### Implementación en Apache Camel
Camel permite implementar este patrón fácilmente usando `.routingSlip(header("miRuta"))`, donde el header contiene una lista separada por comas de los endpoints a ejecutar.
#### Ejemplo básico
## Scatter-Gather (Dispersar y Reunir)
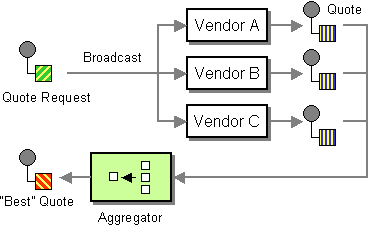
<center><b>Fig. Scatter-Gather</b></center>
> ¿Cómo consultar múltiples sistemas en paralelo y combinar sus respuestas?
El patrón **Scatter-Gather** permite enviar el mismo mensaje a múltiples destinos (o procesos) en paralelo, recolectar todas sus respuestas y combinarlas en una única respuesta. Es especialmente útil cuando una aplicación necesita comparar o consolidar datos de múltiples fuentes para tomar una decisión.
Este patrón es comúnmente utilizado en procesos como:
- Comparación de cotizaciones de precios desde múltiples proveedores.
- Consulta de disponibilidad en diferentes almacenes.
- Ejecución de tareas paralelas cuyos resultados deben consolidarse.
### Etapas del patrón:
1. **Scatter (Dispersión):** se envía el mensaje a múltiples destinatarios.
2. **Procesamiento paralelo:** cada destinatario procesa la solicitud independientemente.
3. **Gather (Recolección):** se recolectan todas las respuestas y se combinan usando una lógica de agregación.
### Ventajas:
- Aprovecha el procesamiento paralelo.
- Aumenta la tolerancia a fallas si algunos servicios no responden.
- Permite recolectar y comparar múltiples puntos de vista.
### Consideraciones:
- Requiere definir un tiempo de espera (timeout) para no quedar esperando indefinidamente.
- Debe definirse una estrategia clara de agregación (sumar, elegir el mínimo, etc).
### Implementación en Apache Camel
Camel proporciona soporte al patrón Scatter-Gather a través de `multicast()` con `parallelProcessing()` y un `AggregationStrategy`.
```java
from("direct:consulta")
.multicast()
.parallelProcessing()
.aggregationStrategy(new MiAgregador())
.to("direct:proveedorA", "direct:proveedorB", "direct:proveedorC")
.to("direct:respuestaFinal");
```
## Idempotent Receiver (Receptor Idempotente)
<center><b>Fig. Idempotent Receiver</b></center>
> ¿Cómo evitar que un mismo mensaje sea procesado más de una vez?
El patrón **Idempotent Receiver** asegura que, aunque un mensaje se reciba múltiples veces, solo se procese **una sola vez**. Este patrón es fundamental para evitar duplicados cuando el sistema de mensajería o la red reenvían mensajes por errores, reintentos o confirmaciones perdidas.
### Problema
En entornos distribuidos, es común que se pierdan confirmaciones o se retransmitan mensajes, generando duplicados. Si estos duplicados se procesan, pueden causar problemas como:
- Cargos duplicados
- Creación múltiple de registros
- Acciones repetidas en sistemas externos
### Solución
El **Idempotent Receiver** guarda un identificador único (por ejemplo, `messageId`, `orderId`, `UUID`, etc.) de cada mensaje procesado. Si llega un mensaje con un ID ya procesado, simplemente se descarta.
## Ventajas
- Evita duplicación de efectos colaterales (p. ej., transferencias bancarias).
- Mejora la confiabilidad del sistema.
- Simple de aplicar con identificadores únicos.
## Consideraciones
- Es necesario un identificador único por mensaje.
- Requiere almacenamiento persistente si el sistema se reinicia.
- El tamaño del repositorio debe controlarse (purga o TTL).
---
### Implementación en Apache Camel
Apache Camel implementa este patrón mediante el componente `idempotentConsumer`. Se puede usar con una **clave única** y un repositorio de IDs ya vistos, que puede ser en memoria, base de datos, archivo, etc.
#### Ejemplo simple en memoria
```java
org.apache.camel.processor.idempotent.MemoryIdempotentRepository
from("direct:entrada")
.idempotentConsumer(header("idMensaje"))
.messageIdRepository(new MemoryIdempotentRepository())
.to("direct:procesarUnico");
```
#### Ejemplo con archivo
```java
from("file:/var/entrada?noop=true")
.idempotentConsumer(header("CamelFileName"))
.messageIdRepository(new FileIdempotentRepository(new File("repo.txt")))
.to("direct:procesarArchivo");
```
#### Ejemplo con jdbc
```java
from("direct:pedidos")
.idempotentConsumer(header("orderId"))
.messageIdRepository(JdbcMessageIdRepository("datasource", "tabla_ids"))
.to("direct:procesarPedido");
```
## Dead Letter Channel (Canal de Mensajes Fallidos)
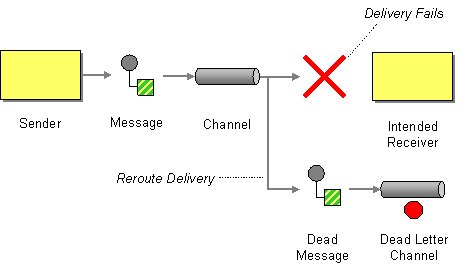
<center><b>Fig. Dead Letter Channel</b></center>
> ¿Cómo manejar mensajes que no se pueden procesar exitosamente?
El patrón **Dead Letter Channel (DLC)** proporciona un mecanismo para capturar mensajes que no pueden ser entregados o procesados correctamente, incluso después de varios intentos de reintento.
En vez de perder el mensaje o hacer que el sistema falle por completo, el mensaje se desvía hacia un **canal especial** donde puede ser almacenado, analizado o reprocesado posteriormente. Es especialmente útil para **resiliencia**, **auditoría** y **mantenimiento** de integraciones robustas.
---
### Motivación
En sistemas de mensajería, es común que un mensaje no pueda procesarse por diversas razones:
- Datos malformateados
- Destino no disponible
- Errores lógicos en el procesamiento
En lugar de fallar o descartar silenciosamente el mensaje, el **Dead Letter Channel** lo **captura**, lo **aísla**, y permite su análisis posterior.
---
### Comportamiento típico del patrón
1. El sistema intenta procesar un mensaje.
2. Si falla, realiza uno o más **reintentos**.
3. Si aún así falla, el mensaje se **redirige** a un canal de mensajes fallidos (DLC).
4. Opcionalmente, se registra información adicional (motivo del fallo, timestamp, stack trace).
### Ventajas
- Aumeta la robustez del sistema.
- Permite aislamiento y tratamiento especial de mensajes problemáticos.
- Facilita debugging y trazabilidad.
### Consideraciones
- Se debe monitorear activamente el canal de errores.
- Los mensajes deben tener suficiente información para ser reprocesados o analizados.
- Puede requerir políticas de retención y limpieza.
---
### Implementación en Apache Camel
Apache Camel implementa este patrón mediante el uso de `errorHandler()` con `deadLetterChannel()`.
#### Ejemplo básico con reintentos
```java
errorHandler(deadLetterChannel("direct:errores")
.maximumRedeliveries(3)
.redeliveryDelay(2000));
from("timer:inicial?repeatCount=1")
.setBody(constant("Mensaje inicial"))
.to("bean:procesadorInestable")
.to("log:exito");
from("direct:errores")
.log("Mensaje enviado a Dead Letter Channel: ${body}")
.to("file:/var/log/errores");
@Component("procesadorInestable")
public class ProcesadorInestable {
private Random random = new Random();
public String procesa(@Body String body) throws Exception {
if (random.nextInt(4) == 0) { // 25% de probabilidad de error
System.out.println("Error simulado en procesadorInestable");
throw new Exception("Error temporal en procesadorInestable");
}
System.out.println("Procesado correctamente: " + body);
return body.toUpperCase(); // Ejemplo de transformación exitosa
}
}
```
## Splitter (Divisor de Mensajes)
<b>Fig. Splitter</b>
¿Cómo procesar por separado elementos individuales contenidos en un mensaje compuesto?
El patrón **Splitter** permite dividir un único mensaje que contiene **múltiples elementos** (como una lista, un arreglo JSON, líneas de texto, registros XML, etc.) en varios **mensajes individuales**, para que cada uno pueda ser procesado de forma independiente.
---
### Motivación
Este patrón es útil cuando se recibe un lote de datos y se necesita tratar **cada elemento por separado**. Por ejemplo:
- Procesar ítems de una orden de compra.
- Leer un archivo con muchas líneas y procesar línea por línea.
- Dividir una respuesta JSON o XML compuesta.
---
### Implementación en Apache Camel
#### División simple de listas
```java
from("direct:entrada")
.split(body())
.to("log:procesar_item")
.end();
```
#### División por lineas de texto
```java
from("file:data/entradas?noop=true")
.routeId("ruta-splitter")
.log("📄 Archivo recibido: ${header.CamelFileName}")
.split(body().tokenize("\n")).streaming()
.filter(body().isNotNull())
.choice()
.when(simple("${body} contains 'ERROR'"))
.log("Línea con error detectada: ${body}")
.to("file:data/errores?fileName=errores-${date:now:yyyyMMdd}.log&fileExist=Append")
.otherwise()
.bean(LimpiezaLinea.class, "procesar")
.log("Línea válida procesada: ${body}")
.to("file:data/salidas?fileName=procesado-${header.CamelFileName}.ok.txt&fileExist=Append")
.endChoice()
.end()
.log("Archivo completado: ${header.CamelFileName}");
```
La opción ==.streaming()== le dice a Apache Camel que procese los elementos divididos uno por uno sin acumularlos todos en memoria.
## Polling Consumer (Consumidor con Sondeo)
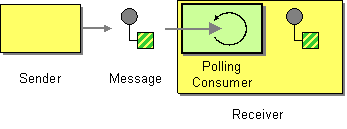
<b>Fig. Polling Consumer</b>
> ¿Cómo consumir mensajes de un recurso que no los envía activamente?
El patrón **Polling Consumer** se utiliza cuando una fuente de datos **no empuja los mensajes de forma proactiva** (push), sino que debe ser **consultada regularmente** por el consumidor para verificar si hay nuevos datos disponibles.
---
### Motivación
No todos los sistemas notifican automáticamente que hay nuevos datos. Algunos requieren que el consumidor:
- Revise un directorio para ver si hay archivos nuevos.
- Consulte una base de datos cada cierto tiempo.
- Haga polling a una API REST para detectar nuevos eventos.
Este patrón es útil cuando trabajamos con:
- Archivos en carpetas compartidas
- Tablas de base de datos que acumulan registros
- Servicios externos sin capacidad de webhook
### Ventajas
- Útil cuando no se dispone de integración activa o notificaciones.
- Fácil de implementar.
- Flexible para trabajar con archivos, APIs, base de datos, etc.
### Consideraciones
- Puede introducir latencia, ya que el consumidor podría no ver un dato nuevo hasta la próxima consulta.
- Puede generar carga innecesaria si el sondeo es muy frecuente.
- Requiere manejo de errores si la fuente no está disponible.
---
### Implementación en Apache Camel
Apache Camel soporta Polling Consumers de varias formas. Aquí se muestran las dos más comunes.
---
#### Opción 1: Sondeo automático por endpoint
```java
from("file:data/entradas?noop=true&delay=10000")
.to("log:archivoDetectado");
```
Consulta el directorio data/entradas cada 10 segundos (delay=10000).
Si encuentra un archivo, lo lee y lo envía al log.
==noop=true== evita que el archivo se mueva o borre.
### Opción 2: Uso explícito de pollEnrich (más control)
```java
from("timer:consulta?period=10000")
.pollEnrich("file:data/polling?noop=true")
.to("log:archivoProcesado");
```
Ahora un ejemplo detectar archivos nuevos en una carpeta, procesar su contenido línea por línea, separar errores de datos válidos, transformar las líneas válidas y guardar ambos resultados en archivos separados.
```java
/*
* Contenido de data/polling
evento 123, usuario A, login
evento 124, usuario B, logout
ERROR - línea malformada
evento 125, usuario C, login
evento 126, usuario D, logout
evento 127, usuario E, login
*
* */
from("timer:consulta?period=10000")
.routeId("polling-archivos")
.log("Iniciando sondeo de archivos a las ${date:now:HH:mm:ss}")
.pollEnrich("file:data/polling?noop=true")
.choice()
.when(body().isNull())
.log("No se encontraron archivos nuevos para procesar.")
.otherwise()
.log("Archivo detectado: ${header.CamelFileName}")
.split(body().tokenize("\n")).streaming()
.filter(body().isNotNull())
.choice()
.when(simple("${body} contains 'ERROR'"))
.log("Línea con error encontrada: ${body}")
.to("file:data/errores?fileName=errores-${header.CamelFileName}.log&fileExist=Append")
.otherwise()
.bean(EnriquecedorDeLinea.class, "enriquecer")
.log("Línea procesada: ${body}")
.to("file:data/salidas?fileName=procesado-${header.CamelFileName}.ok.txt&fileExist=Append")
.endChoice()
.end()
.end()
.log("Fin del ciclo de sondeo.");
public class EnriquecedorDeLinea {
public String enriquecer(String linea) {
String timestamp = java.time.LocalDateTime.now().toString();
return linea.trim().toUpperCase() + " | Procesado: " + timestamp;
}
}
```
Usa un timer como disparador.
El ==pollEnrich()== realiza el sondeo activo del recurso.
Si hay un archivo disponible, lo procesa.
La opción ==**.streaming()**== le dice a Apache Camel que procese los elementos divididos uno por uno sin acumularlos todos en memoria.
## Circuit Breaker (Cortacircuitos)
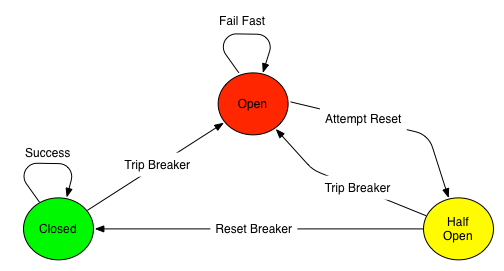
<b>Fig. Circuit Breaker </b>
### Descripción
Circuit Breaker (Cortacircuitos) es un patrón de resiliencia que protege los sistemas contra fallas en cascada al evitar repetir llamadas a servicios que están ==fallando continuamente==. Cuando detecta una tasa de error elevada, el circuito se "abre", bloqueando temporalmente nuevas llamadas y devolviendo respuestas alternativas o de respaldo (fallback). Luego de un tiempo, permite llamadas de prueba para ver si el servicio ha vuelto a la normalidad.
Este patrón es especialmente útil para protegerse de APIs externas, servicios lentos o fallos intermitentes.
### Ciclo de vida explicado paso a paso
🟢 **1. Closed (Cerrado)**
- Estado inicial.
- Las llamadas fluyen normalmente.
- El Circuit Breaker cuenta los fallos.
- Si los fallos superan un umbral (ej. 50% de 100 llamadas), se dispara el "Trip Breaker" → pasa al estado Open.
🔴 **2. Open (Abierto)**
- Corte total del tráfico: no se permite ninguna llamada real al servicio.
- En lugar de llamar al servicio, devuelve una respuesta inmediata de error o ejecuta un fallback().
- Después de un tiempo (waitDurationInOpenState, por ejemplo 60 segundos), intenta recuperarse → pasa al estado Half Open.
- Si alguien intenta llamar mientras está abierto → ==Fail Fast==: error inmediato.
🟡 **3. Half Open (Semiabierto)**
- Modo de prueba.
- Se permiten unas pocas llamadas reales (por ejemplo, 5).
- Si las respuestas son exitosas, se resetea el breaker → vuelve a Closed.
- Si alguna falla, el breaker vuelve a Open.
---
### Transiciones entre estados
| Desde | Hacia | Condición |
| ----------- | ----------- | ----------------------------------------- |
| `Closed` | `Open` | Umbral de fallos alcanzado (ej. 50%) |
| `Open` | `Half Open` | Tiempo de espera vencido (`waitDuration`) |
| `Half Open` | `Closed` | Llamadas de prueba exitosas |
| `Half Open` | `Open` | Llamadas de prueba fallan |
### ¿Por qué es útil?
Este ciclo evita:
- Sobrecargar un servicio caído.
- Enviar llamadas que sabemos que van a fallar.
- Generar efectos cascada en sistemas distribuidos.
### Aplicación en Apache Camel
Apache Camel integra `Circuit Breaker` mediante el componente [`camel-resilience4j`](https://camel.apache.org/components/latest/resilience4j-component.html), que se basa en la biblioteca [Resilience4j](https://resilience4j.readme.io/).
---
### Ejemplo de uso
```java
from("direct:servicioInestable")
.log("Llamando servicio inestable...")
.process(exchange -> {
if (Math.random() < 0.5) {
throw new RuntimeException("Falla simulada en el servicio");
}
exchange.getMessage().setBody("Servicio respondió correctamente");
});
from("timer:intentos?period=3000")
.routeId("circuit-breaker-eip")
.log("Llamada protegida por Circuit Breaker")
.circuitBreaker()
.resilience4jConfiguration()
.failureRateThreshold(50)
.minimumNumberOfCalls(5)
.waitDurationInOpenState(10000)
.end()
.to("direct:servicioInestable")
.log("Respuesta recibida: ${body}")
.onFallback()
.log("Circuito abierto. Ejecutando fallback.")
.setBody(constant("Respuesta alternativa por error"))
.end();
```
En práctica
===
APACHE CAMEL
===
Apache Camel es una biblioteca de integración para Java. Es un lenguaje, un conjunto de API de Java y un montón de componentes que le permiten integrar y procesar datos entre diferentes sistemas informáticos.
En otras palabras, Camel es como un pegamento para Java, que conecta diferentes aplicaciones entre sí.
## Casos de uso comunes para Camel
Casi siempre que necesite mover datos de A a B, probablemente pueda usar Camel. Cualquiera de los siguientes escenarios podría implementarse usando Camel:
* Recoger facturas de un servidor FTP y enviarlas por correo electrónico a su departamento de Cuentas
* Tomar archivos de una carpeta y empujarlos a Google Drive
* Tomar mensajes de una cola de ActiveMQ y enviarlos a un servicio web
* Crear un servicio web que permita a los usuarios recuperar detalles de clientes de una base de datos
## Patrones de integración empresarial (EIP)
Los EIP realizan un procesamiento especial en los mensajes de acuerdo con los patrones definidos en el libro Patrones de Integración Empresarial(EIP).
Cuando desee realizar algunas actividades comunes en un mensaje, como la transformación, la división y el registro, utilizará un EIP. Hay algunos EIP comunes en Camel:
| Nombre EIP | Que hace | Sintaxis Java |
| ---------- | -------- | ------------- |
| Splitter | Divide un mensaje en varias partes |.split()|
| Aggregator | Combina varios mensajes en un solo mensaje |.aggregate()|
| Log | Escribe un mensaje de log simple| .log()|
| Marshal |Convierte un objeto en un formato de texto o binario|.marshal()|
| From* | Recibe un mensaje desde un endpoint | .from()|
| To* | Envía un mensaje a un endpoint |.to()|
Context
---
Para ejecutar y administrar sus rutas, Camel tiene un contenedor llamado Camel Context. Las rutas se ejecutan dentro de este motor. Se podría pensar en él casi como un mini servidor de aplicaciones.
Cuando se inicia Camel , lee las definiciones de ruta (en Java o XML), crea las rutas, las agrega a Camel Context e inicia Camel Context.
Cuando Camel termina, cierra sus rutas y cierra Camel Context.
## Conceptos CAMEL
Se puede pensar en Camel como una tubería

Donde los:
* **Enpoints**: reciben y envía mensajes
* **Route**: un flujo de Camel
* **EIP**: procesamiento del mensaje
* **Context**: contenedor donde se ejecutan los routes
## Una ruta es como una tubería
El concepto más básico en Camel es la ruta o route. Las rutas son objetos que configuras en Camel, que mueven tus datos de A a B.
Para usar el ejemplo de plomería anterior, una ruta es una tubería que mueve datos de un lugar a otro. Mueve datos entre cosas llamadas puntos finales.
Puede crear rutas en Camel utilizando una sintaxis Java o una sintaxis XML. Aquí hay una ruta muy simple escrita en la sintaxis de Java. Esto mueve un archivo de una carpeta a otra:
```java=
// Esta es una definición completa de ruta en Camel!
// Camel moverá los archivos de una carpeta a otra
from("file:home/customers/new")
.to("file:home/customers/old");
```
## Endpoint
En Camel, un *endpoint* es una interfaz a través de la cual Camel intercambia un mensaje con otro sistema. Camel puede recibir un mensaje desde un *endpoint* o enviar un mensaje a un *endpoint*.
Los *endpoint* son los pasos a lo largo del camino en sus rutas o *routes*. Puede declararlos de un par de maneras diferentes, pero la forma más común es declararlos usando una sintaxis que parece un URI, como esta:
```javascript=
prefix:mainpart?option1=xxx&option2=xxx...
```
donde prefix es el Componente al que se refiere el *endpoint*, y *mainpart* es un poco de configuración que necesita el *endpoint*.
**Por ejemplo**: al inicio de una ruta, Camel recibe un mensaje de un *endpoint*. Si este *endpoint* es file:/micarpeta, entonces Camel usará el componente **File** para leer archivos en /micarpeta.
## Componentes
Para que Camel pueda crear un *endpoint*, viene con una biblioteca de **componentes** . Un componente son extensiones que le permite conectarse a un sistema externo, como un archivo en el disco, un buzón de correo o una aplicación como Dropbox o Twitter.
Puede pensar en un componente como una fábrica para crear *end points*.
Siempre que necesite introducir o sacar datos de una aplicación, probablemente encontrará que ya existe un componente Camel para hacer el trabajo por usted. Esto significa que no necesita perder tiempo escribiendo su propio código para leer un archivo o invocar un *web service*. Simplemente encuentre el componente que necesita y utilícelo.
Los componentes de Camel son reutilizables. Estos son algunos de los componentes más comunes y cómo puede hacer referencia a ellos en un *endpoint*:
|Componente |Objetivo| URI de endpoint |
|-----------|--------|------------------|
|HTTP |para crear o consumir sitios web| http:|
|File| para leer y escribir archivos| file:|
|JMS| para leer y escribir en colas de mensajes JMS| jms:|
|Direct| por unir rutas de Camel| direct:|
[Lista completa de Componentes Camel](https://camel.apache.org/components/4.10.x/index.html)
Cada componente generalmente puede leer y escribir:
* Un componente que está configurado para escribir algo se denomina productor (***producer***) ; por ejemplo, escribir en un archivo en el disco o escribir en una cola de mensajes.
* Un componente que está configurado para leer algo se denomina consumidor (***consumer***) ; por ejemplo, leer un archivo del disco o recibir una solicitud REST.
Entre cada *endpoint*, los datos también se pueden transformar o modificar, ya sea pasando los datos a través de otro *endpoint* o utilizando un EIP.
Cuando desarrollamos en Camel, creamos **rutas** (routes) que mueven datos entre ***endpoints*** , utilizando componentes.
Aunque Camel es una biblioteca para Java, se puede configurar usando uno de dos lenguajes: Java o XML, estos se conocen como DSL (Domain Specific Languages).
Cada ruta comienza con un ``from``, configurado con una URI, que define el **endpoint** de donde provienen los datos.
Una ruta puede constar de varios pasos, como transformar los datos o registrarlos. Pero una ruta generalmente termina con un ``to``, que describe dónde se entregarán los datos.
Una ruta realmente simple en Java DSL de Camel podría verse así:
```java=
from("file:home/customers/new")
.to("file:home/customers/old");
```
Herramientas a utilizar
---
JAVA SDK 18 - https://www.java.com/es/download/
Apache Maven - https://maven.apache.org/download.cgi
https://maven.apache.org/install.html
Eclipse - https://www.eclipse.org/downloads/
Apache Camel 3.17 - https://camel.apache.org/releases/release-3.17.0/
#### Pasos
1. Descargar e instalar Java JDK 18
2. Descargar y desempaquetar Maven.(Agregar al PATH del sistema)
3. Descargar e instalar Eclipse IDE
4. Ir a [Spring boot generator](https://start.spring.io/)
5. Elegir
* Maven project
* Java
* Boot version: 3.5.3
* Group: py.edu.ucom.is2
* Artifact: proyecto-camel
* Name: proyecto-camel
* Dependencies:
- Springboot dev tools
- Spring web
- Spring Boot actuator
- Apache Camel
[OBS: esta es una configuración pre-guardada ](https://start.spring.io/#!type=maven-project&language=java&platformVersion=2.6.8&packaging=jar&jvmVersion=18&groupId=py.edu.ucom.is2&artifactId=proyecto-camel&name=proyecto-camel&description=proyecto-camel%20de%20integracion%20de%20sistemas%202&packageName=py.edu.ucom.is2.proyecto-camel&dependencies=devtools,web,actuator,camel)
[OBS: esta es una configuración pre-guardada 2025](https://start.spring.io/#!type=maven-project&language=java&platformVersion=3.5.3&packaging=jar&jvmVersion=21&groupId=py.edu.ucom.is2&artifactId=proyecto-camel2025-limpio&name=proyecto-camel2025-limpio&description=IS2%202025%20limpio&packageName=py.edu.ucom.is2.proyecto-camel2025-limpio&dependencies=devtools,web,actuator,camel)
6. Generate y descartar ZIP
7. En Eclipse: importar maven project
Práctica 1 - Agenda
---
Objetivo: utilizar patrones de integración implementados en Apache Camel para
* leer una cola de mensajes (simular con timer)
* transformar el mensaje
* guardar mensaje en base de datos (simular con log)
1. Crear una Clase RouteTest que extienda de RouteBuilder
```java=
import org.apache.camel.builder.RouteBuilder;
public class RouteTest extends RouteBuilder {
@Override
public void configure() throws Exception {
// TODO Auto-generated method stub
}
}
```
2. Crear un endpoint Timer
3. Crear un endpoint Logger
4. Practicar transformaciones constantes con componente Transform (``transform().constant()``)
5. Practicar transformaciones con beans [Documentación](https://camel.apache.org/components/4.10.x/eips/message-translator.html)
6. Practicar de procesamiento con Beans
7. Practicar de procesamiento con Processor (**implements Processor**)
8. **Discutir diferencia entre procesadores y transformadores**
Práctica 2 - Agenda
---
Objetivo: practica de Patrón Message Broker con Apache Active MQ utilizando modo punto a punto
* Generar mensajes en una cola de mensajes
* Consumir mensajes desde una cola de mensajes
### Productor de Mensajes
1. Crear un endpoint Timer
2. Crear un endpoint Logger
3. Crear un Endpoint activemq apuntando a una cola de mensajes
4. Agregar al pom del proyecto
```xml=
<!-- agregar MQ -->
<dependency>
<groupId>org.apache.camel.springboot</groupId>
<artifactId>camel-activemq-starter</artifactId>
<version>${camel.version}</version>
</dependency>
```
6. OBS> configuración de conexión: en el archivo src\main\resources\application.properties del proyecto se debe incluir la siguiente contenido
```txt=
spring.activemq.broker-url:tcp://ucom-is2-2024.switzerlandnorth.cloudapp.azure.com:61616
spring.activemq.user=admin
spring.activemq.password=xCFbBY75uqM.
```
[Ingresar a la consola del Active MQ](https://b-89faf5ab-14d6-457b-ad3e-f82cec9da8e4-1.mq.us-east-2.amazonaws.com:8162/index.html)
### Receptor de Mensajes
1. Crear un Endpoint activemq
2. Crear un endpoint Logger
Práctica 3 - Agenda
---
Objetivo: practica de Patrón Message Broker con Apache Active MQ utilizando modo publicación/suscripción.
Simulación de una comunicación en una app de mensajería
* Generar mensajes en una topic de mensajes
* Consumir mensajes desde el topic de mensajes
### Productor de Mensajes
1. Crear un endpoint Timer
2. Crear un endpoint Logger
3. Crear un Endpoint activemq apuntando a un topic de mensajes
### Receptor de Mensajes
1. Crear un Endpoint activemq que lea el topic de mensajes
2. Crear un endpoint Logger
Práctica 4 - Agenda
---
Objetivo: Crear un REST con que pueda recibir un mensaje simple mediante método post, el cual debe encolar el mensaje en una cola ActiveMQ
1. Agregar la siguiente dependencia a nuestro proyecto
```xml=
<dependency>
<groupId>org.apache.camel.springboot</groupId>
<artifactId>camel-servlet-starter</artifactId>
<version>${camel.version}</version>
</dependency>
```
** [Ver proyecto de ejemplo](https://github.com/monodot/camel-demos/tree/master/examples/spring-boot/rest-service)
Práctica 5 - Agenda
---
Objetivo: Agregar capacidad de procesamiento de json a nuestro REST anterior
1. Agregar la siguiente dependencia a nuestro proyecto
```xml=
<dependency>
<groupId>org.apache.camel.springboot</groupId>
<artifactId>camel-jackson-starter</artifactId>
<version>${camel.version}</version>
</dependency>
```
Proyecto 1
===
**Forma de entrega:** subir al canvas el link al repositorio github
Objetivo: Simular las interconexiones del sistema de transferencias electrónicas SIPAP, mediante timer y colas de mensajes. Se solicita
1. Crear un generador de mensajes de "transferencia" en formato json. Los datos de la transferencia deben ser: cuenta y monto, banco_origen, banco_destino. Esto se debe simular mediante un timer, que genere periodicamente un json: Ej
```json=
{
"cuenta": "123456",
"monto": 500000,
"banco_origen": "ATLAS",
"banco_destino": "ITAU"
}
```
Cada mensaje json debe ser generado seleccionando como banco origen y destino: ITAU, ATLAS, FAMILIAR.
El número de cuenta y monto también deben ser aleatorios entre 1000 y 5000.
2. Procesar la petición enviando el mensaje json a una cola ActiveMQ con nombre constante
El nombre de la cola debe ser <apellidoAlumno-ITAU-IN>.
ej.: "morales-ITAU-IN"
Los nombres de las colas deben terminar con el subijo "-IN" para indicar que es una cola de entrada de cada banco para las transacciones pendientes.
3. Programar un consumidor Bean de la cola MQ para cada banco, que simule procesamiento de la transacción.
Se debe imprimir el json recibido.
OBS: se debe simular al menos 2 bancos
Ejemplo:
* Banco A quiere transferir al BancoB, envía mensaje json vía API, con método POST
* Banco B transfiere al Banco A, envía mensaje json vía API, con método POST
* Banco C transfiere al Banco A, envía mensaje json vía API, con método POST
* Banco A, lee su cola de mensajes y procesa (consumidor Banco A)
* Banco B, lee su cola de mensajes y procesa (consumidor Banco B)
Diagrama:
```mermaid
graph TB
A[productor: Banco A] ==> ENCOLADOR
B[productor: Banco B] --> ENCOLADOR
C[productor: Banco C] -.-> ENCOLADOR
ENCOLADOR ==> Apellido-BancoB-IN
ENCOLADOR --> Apellido-BancoA-IN
ENCOLADOR -.-> Apellido-BancoA-IN
subgraph ActiveMQ
Apellido-BancoB-IN
Apellido-BancoA-IN
end
Apellido-BancoB-IN -->|desencola| P[Bean consumidor: BancoB]
Apellido-BancoA-IN -->|desencola| Q[Bean consumidor: BancoA]
P & Q--> Imprimir
```
Proyecto 2
===
**Forma de entrega:** subir al canvas el link al repositorio github
Objetivo: mejorar sistema desarrollado en la Tarea 1 aplicando patrones de integración.
Se solicita:
1. Ajustar el json enviado para incluir la fecha de transacción y un id de transacción
```json=
{
"cuenta": "123456",
"monto": 500000,
"banco_origen": "ATLAS",
"banco_destino": "ITAU",
"fecha": "01/01/2022",
"id_transaccion": 123215
}
```
2. El pipeLine deberá controlar que los montos de transferencia sean menores a 20.000.000 para poder encolar al broker ActiveMQ, en caso de ser mayor o igual a 20.000.000 el pipeLine deberá rechazar la transacción con un mensaje "El monto supera máximo permitido", además del número de transacción.
Ej:
```json=
{"id_transaccion":123
"mensaje": "El monto supera máximo permitido"}
```
**Cambios en Bean consumidores**
3. A diferencia de la tarea 1 que pedía imprimir los mensajes de transferencia, los bean consumidores de la petición de transferencia deberán leer el mensaje de transferencia, validarlo e imprimir el resultado de la validación.
4. La validación a realizar es que la fecha de transferencia sea la misma a la fecha actual, caso contrario rechazar la transacción
Ejemplo validacion exitosa:
Ej:
```json=
{"id_transaccion":123
"mensaje": "Transferencia procesada exitosamente"}
```
Ejemplo validacion no exitosa
```json=
{"id_transaccion":123
"mensaje": "Mensaje caducado"}
```
5. Aplicar 2 patrones a elección de esta lista:
| Patrón EIP | Aplicación en Proyecto 2 |
|-------------------------|----------------------------------------------------------------------------------|
| **Dead Letter Channel** | Capturar errores de procesamiento en Beans y redirigir mensajes fallidos a una cola de errores. |
| **Multicast** | Enviar el mensaje simultáneamente a la cola del banco, a un log de auditoría y a una cola de respaldo. |
| **Splitter** | Dividir un lote de transferencias (por ejemplo, un arreglo JSON) en mensajes individuales. |
| **Idempotent Receiver** | Evitar procesar múltiples veces una transacción con el mismo `id_transaccion`. |
| **Wire Tap** | Clonar el mensaje para enviarlo a un log o auditoría sin afectar la ruta principal. |
| **Message Store** | Almacenar los mensajes procesados para trazabilidad, auditoría o reenvío futuro. |
Diagrama:
```mermaid
graph TB
A[productor: Banco A] ==> |post | API
B[productor: Banco B] --> |post | API
C[productor: Banco C] -.-> |post | API
API ==> Apellido-BancoB-IN
API --> Apellido-BancoA-IN
API -.-> Apellido-BancoA-IN
subgraph ActiveMQ
Apellido-BancoB-IN
Apellido-BancoA-IN
end
Apellido-BancoB-IN -->|desencola| P[Bean consumidor: BancoB]
Apellido-BancoA-IN -->|desencola| Q[Bean consumidor: BancoA]
P --> J{es fecha de hoy?}
J ==> |Mensaje caducado| Imprimir
J ==> |Transferencia exitosa| Imprimir
Q --> J
```
Referencia
=
* [Enterprise Integration Patterns](https://www.enterpriseintegrationpatterns.com/patterns/messaging/)
* [Apache Camel](https://camel.apache.org/components/4.10.x/index.html)
-----------
CIRCUIT BREAKER
JSONPATH
Envelope Wrapper
Content Filter