Transformer
===
###### tags: `chatbot` `transformer` `attention`
- Self Attention
- RNN의 특징은 context vector안에 각 단어의 순서 및 위치 정보를 내포할 수 있도록 설계되었기 때문이다.
- RNN에서 'I' 'Love' 'You'라는 단어로 '난' '널' '사랑해'를 예측한다고 가정했을 때
'I' 'Love' 'You'의 hidden state은 '난' '널' '사랑해'를 순차적으로 받아 새로운 context vector를 생성하게 되는데 여기서 '난' '널' '사랑해'를 순차적으로 받는다는 것에 RNN의 특징에 대한 의미가 있다.
하지만 순차적인 training은 학습 시간이 길어지는데 큰 영향을 준다.
- Transformer에서 self attention은 input 문장에서 단어들의 context vector를 추출하기 위함인데 '월 화 수 목 금' 과 '시간은 금이다'라는 문장에서 단어 '금'은 동일한 의미를 지니지 않는다.
- 하지만 Embedding layer만 가지고 단어를 백터와 한다면 위 두문장에서 '금'은 동일한 벡터로 표현될 것이다. 따라서 우리는 문맥에서의 단어가 가진 의미를 표현할 수 있어야 하는데, 이를 단어의 문맥벡터라하며 self attention을 통해 얻을 수 있다.
- Self Attention은 문장안에서 단어가 문맥상 가지고 있는 정보를 추출할 수 있는데
단어와 단어의 positional 정보를 더해서 Query Key Value 메카니즘으로 진행된다.
QKV에서 나온 단어의 문맥벡터는 단어들 간 연관관계 포함하고 여기에 positional 정보를 더했으니 이제 문맥벡터는 단어들 간의 위치정보를 내포한 연관관계를 갖게 된다. 따라서 '월 화 수 목 금'의 '금과' '시간은 금이다'의 '금'은 완전히 다른 벡터로 표현되게 된다.
- Multi Head attention
- 동일한 query, key, value에 각기 다른 weight matrix W를 곱해 여러번 수행하는것
- Transformer 개요
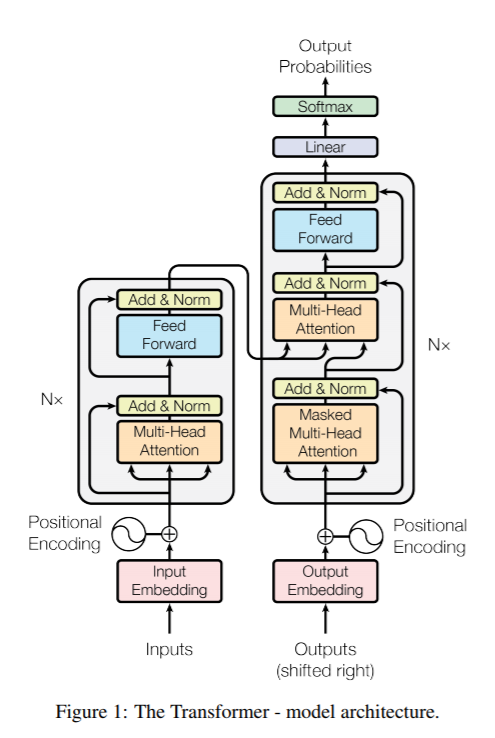
- Encoder
```python=
class Encoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Encoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['input_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'],
self.d_model)
self.enc_layers = [EncoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x)
for i in range(self.num_layers):
x = self.enc_layers[i](x, mask)
return x # (batch_size, input_seq_len, d_model)
```
1. '어떤 과일을 좋아합니까?'를 Input Embedding으로 벡터화
2. 각 단어에 positional encoding을 더해 위치 정보 추가
3. 위에서 나온 결과를 QKV로 Multi-Head Attention에 적용
4. Multi-Head 에서 나온 결과들을 Normalize하고 Feed
- Decoder
```python=
class Decoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Decoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['target_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'], self.d_model)
self.dec_layers = [DecoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, enc_output, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, look_ahead_mask, padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
```
1. '나는 사과를 좋아합니다.'를 Output Embedding으로 벡터화
2. 각 단어에 positional encoding을 더해 위치 정보 추가
3. 위에서 나온 결과를 QKV로 Subsequent Masked Attention에 적용
Masked Attention은 Query입장에서 현재 단어의 위치 기준으로 이후에 나오는 단어 Key정보를 알지 못하도록 처리하는 방식
4. Mutl-Head Attention에 QK에는 Encoder의 output을 V에는 Decoder의 output넣는다
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet