# Concurrency & Atomic 學習筆記
ref[1] : [並行程式設計: Atomics 操作](https://hackmd.io/@sysprog/linux2021-summer/https%3A%2F%2Fhackmd.io%2F%40sysprog%2Fconcurrency-atomics)
book[1] : [C++ Concurrency in Action](https://www.manning.com/books/c-plus-plus-concurrency-in-action)
### Atomic operation
1. [Atomic vs. Non-Atomic Operations](https://preshing.com/20130618/atomic-vs-non-atomic-operations/)
原子操作(Atomic Operation)的定義:
>An operation acting on shared memory is atomic if **it completes in a single step relative to other threads.** When an atomic store is performed on a shared variable, **no other thread can observe the modification half-complete.**
對其他thread來說,原子操作是一個步驟,thread沒辦法從中間打斷,也看不到中間狀態,要馬就是完成後的狀態,要馬就是沒完成的狀態。在C/C++中,除非compiler或是hardware vendor明確規定,不然所有的操作都是**non-atomic**,即使是32bit整數操作。
```c=
uint64_t sharedValue = 0;
void storeValue()
{
sharedValue = 0x100000002;
}
```
上面的程式碼,單存的存取64bit整數,如果編譯成可以跑在32bits x86的機器上,會變成下面的樣子。
```bash
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov DWORD PTR sharedValue, 2
mov DWORD PTR sharedValue+4, 1
ret
...
```
一個存取64bits整數的動作,會被分成兩個instructions。如果,有個thread在這兩個指令中間打斷,就會有data race的情況。==thread間存取的共同資源,必須被保護(lock),或是只能用原子操作來存取。==
可以用C++11提供的API來改寫上述的code達到原子操作。
```cpp=
#include <atomic>
std::atomic<uint64_t> sharedValue(0);
void storeValue()
{
sharedValue.store(0x100000002, std::memory_order_relaxed);
}
uint64_t loadValue()
{
return sharedValue.load(std::memory_order_relaxed);
}
```
其中sharedValue.load和sharedValue.store為原子操作。後面的relaxed只是定義不限制它的前後排列。
### Declar atomic variable
[C11](https://zh.wikipedia.org/wiki/C11)中新增了一些和concurrency相關的header,如: ==stdalign.h==,==threads.h==,和==stdatomic.h==。其中,[stdatomic.h](https://code.woboq.org/gcc/gcc/ginclude/stdatomic.h.html)定義了如何宣告變數成為atomic,和一些atomic相關的function。
+ char --> _Atomic(char) --> _Atomic char --> atomic_char
+ int --> _Atomic(int) --> _Atomic int --> atomic_int
以上的atomic定義都是合理的定義。以下是一部分的header內容。
```c=
typedef _Atomic _Bool atomic_bool;
typedef _Atomic char atomic_char;
typedef _Atomic signed char atomic_schar;
typedef _Atomic unsigned char atomic_uchar;
typedef _Atomic short atomic_short;
```
其中有幾個變數掛有==least==和==fast==,例如:
+ atomic_int_least16_t : 最少長度使用16bits的變數
+ atomic_int_fast16_t : 最少長度使用16bits的變數,但是使用的長度可府合系統快速操作。
參考 [Why is uint_least16_t faster than uint_fast16_t for multiplication in x86_64?](https://stackoverflow.com/questions/4116297/why-is-uint-least16-t-faster-than-uint-fast16-t-for-multiplication-in-x86-64)
不同長度的變數做相同的運算,得到的執行時間也不一樣。
在沒開最佳化的情況(-O0)。
```cpp
Test uint16_t took 13.6286 s. (0)
Test uint32_t took 12.5881 s. (0)
Test uint64_t took 12.6006 s. (0)
```
有開最佳化參數(-O3)的情況下。
```cpp
Test uint16_t took 13.6385 s. (0)
Test uint32_t took 4.5455 s. (0)
Test uint64_t took 4.5382 s. (0)
```
使用uint_fast16_t的情況下,compiler會幫我們使用uint32_t或是uint64_t來讓系統效能提升。
### Align operation
在c11中定義了幾個和記憶體align相關的操作。這些全部定義在==stdalign.h==中。
+ alignas : 對齊記憶體address。
+ alignof : 取得此變數的對齊數。
例如以下的code。
```cpp=
alignas(16) int x;
printBinary(&x);
printf("%ld\n", alignof(x));
```
會得到以下的輸出。
```
_0000_0000_0000_0000_0000_0000_1010_1101_1001_0100_1111_1111_1111_1000_1101_0000
16
```
因為int x的address會對齊16 = pow(2, 4),所以後面四個binary皆為零。使用alignas的好處是可以避免==false sharing==。
參考: [多线程代码运行中缓存 False sharing 现象解析](https://blog.xiaokezhao.com/understand-cache-false-sharing-in-multiple-threads/)
使用以下兩個struct的定義
```cpp=
struct Par
{
int n1;
int n2;
};
```
```cpp=
struct Par
{
alignas(64) int n1;
alignas(64) int n2;
};
```
第二個的定義效率會比較好。因為存取的時候是以cacheline大小為單位,通常為==64bytes==。所以multiprocessor之間可以避免cache coherence的動作。
### atomic_store vs. atomic_exchange
從function name來看,本來以為atomic_exchange是作兩個值的交換,但是其實作用和atoimc_store一樣。
從function define來看==atomic_exchange有回傳值,會把obj的原本值回傳回來。==
```c=
void atomic_store( volatile A* obj , C desired);
C atomic_exchange( volatile A* obj, C desired );
```
對於兩個function的說明:
**[atomic_store](https://en.cppreference.com/w/c/atomic/atomic_store)**
>Atomically replaces the value of the atomic variable pointed to by obj with desired.
**[atomic_exchange](https://en.cppreference.com/w/c/atomic/atomic_exchange)**
>Atomically replaces the value pointed by obj with desired and returns the value obj held previously.
也是幾乎一樣,只差在atomic_exchange有把obj的原本值回傳回來。
### Atomic flag
在stdatomic.h中,有個特別的變數atomic_flag,它的定義如下, 基本上它就是一個被struct化的unsigned char。:
```c=
typedef _Atomic struct
{
#if __GCC_ATOMIC_TEST_AND_SET_TRUEVAL == 1
_Bool __val;
#else
unsigned char __val;
#endif
} atomic_flag;
```
可以使用下面的function來做init。
```c=
#define ATOMIC_FLAG_INIT { 0 }
```
可以用以下的function來操作atomic_flag
```c=
atomic_test_and_set();
atomic_test_and_set_explicit();
atomic_flag_clear();
atomic_flag_clear_explicit();
```
以下程式碼片段,可以用atomic_flag來實作一個mutex lock。
```c=
static void atomic_val_inc(int nLoops)
{
for (int loop = 0; loop < nLoops; loop++) {
while (atomic_flag_test_and_set(&atomic_float_obj.flag))
CPU_PAUSE();
atomic_float_obj.value += 1.0f;
atomic_flag_clear(&atomic_float_obj.flag);
}
}
```
當flag == 0 時,test成功,把它設成1,並且往下執行。
當flag == 1 時,test失敗,返回0繼續等待。
### Explicit function
在==stdatomic.h==中,很多function name會有explicit名字。例如:
```c
atomic_store_explicit(PTR, VAL, MO);
atomic_load_explicit(PTR, MO);
atomic_fetch_add_explicit(PTR, VAL, MO);
atomic_flag_test_and_set_explicit(PTR, MO);
atomic_compare_exchange_strong_explicit(PTR, VAL, DES, SUC, FAIL)
```
只要有==explicit的function皆可以指定其Memory Order==,可以使用的memory order如下:
```c
typedef enum
{
memory_order_relaxed = __ATOMIC_RELAXED,
memory_order_consume = __ATOMIC_CONSUME,
memory_order_acquire = __ATOMIC_ACQUIRE,
memory_order_release = __ATOMIC_RELEASE,
memory_order_acq_rel = __ATOMIC_ACQ_REL,
memory_order_seq_cst = __ATOMIC_SEQ_CST
} memory_order;
```
這些memory order的強弱關係如下:

越弱(weaker)表示越不在乎順序,越強(stronger)表示越要遵守其規定的順序執行。沒有使用explicit的function一律使用**ATOMIC_SEQ_CST**當成是它的memory order。
```c=
#define atomic_fetch_add(PTR, VAL) \
__atomic_fetch_add ((PTR), (VAL), __ATOMIC_SEQ_CST)
#define atomic_store(PTR, VAL) \
atomic_store_explicit (PTR, VAL, __ATOMIC_SEQ_CST)
#define atomic_compare_exchange_strong(PTR, VAL, DES) \
atomic_compare_exchange_strong_explicit (PTR, VAL, DES, __ATOMIC_SEQ_CST, __ATOMIC_SEQ_CST)
```
### Strong and weak function
在[stdatomic.h](https://code.woboq.org/gcc/gcc/ginclude/stdatomic.h.html)中compare_exchange有分為strong和weak。
```c=
atomic_compare_exchange_strong_explicit(PTR, VAL, DES, SUC, FAIL);
atomic_compare_exchange_weak_explicit(PTR, VAL, DES, SUC, FAIL);
```
根據gcc的說明:
>weak is true for weak compare_exchange, which may fail spuriously, and false for the strong variation, which never fails spuriously. Many targets only offer the strong variation and ignore the parameter. When in doubt, use the strong variation.
參考[C++11:原子交换函数compare_exchange_weak和compare_exchange_strong](https://www.codenong.com/cs107035480/)
>weak版本的CAS允许偶然出乎意料的返回(比如在字段值和期待值一样的时候却返回了false),不过在一些循环算法中,这是可以接受的。通常它比起strong有更高的性能。
參考[weak/strong compare-and-swap 的差別和應用](https://medium.com/@fcamel/weak-strong-compare-and-swap-%E7%9A%84%E5%B7%AE%E5%88%A5%E5%92%8C%E6%87%89%E7%94%A8-bf181e26678a)
>只需執行一次:用 strong 版的 compare-and-swap
>可能會執行多次:用 weak 版的 compare-and-swap
參考[c++并发编程3. CAS原语](https://zhuanlan.zhihu.com/p/56055215)
>想要性能,使用compare_exchange_weak+循环来处理。
想要简单,使用compare_exchange_strong。
如果是x86平台,两者没区别
如果想在移值的时候,拿到高性能,用compare_exchange_weak。
總結以上的參考,
**weak有可能會失敗,即使要比較的ptr是一樣的。所以必須用在迴圈判斷中。但是它會有更好的performance,和更好的移植性。**
### Memory Barriers
1. [Memory Barriers Are Like Source Control Operations](https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/)
2. [Fences are Memory Barriers](https://www.modernescpp.com/index.php/fences-as-memory-barriers)
3. [Acquire and Release Fences](https://preshing.com/20130922/acquire-and-release-fences/)
四種memory barrier
+ LoadLoad
+ LoadStore
+ StoreLoad
+ StoreStore
使用LoadLoad memory barrier,就可以防止前面的Load和後面的Load順序對調。
==Full Fence== : std::atomic_thread_fence(),可以防止任兩種操作的reordering,除了**StoreLoad**除外。

==Acquire Fence== : atomic_thread_fence(std::memory_order_acquire),可以防止Load被排到barrier後面。或是barrier後面的read(load)/write(store)不可以重排到barrier前面的load。

==Release Fence== : atomic_thread_fence(std::memory_order_release),可以防止後面的Store被排到前面。或是barrier前面的read(load)/write(store)不可以重排到barrier後面的store。

所以,
+ acquire fence = #LoadLoad + #LoadStore barrier.
+ release fence = #LoadStore + #StoreStore barrier.
可以得到以下的關係圖。

包含Memory barriers insturction在裡面的指令。
+ Certain inline assembly directives in GCC, such as the PowerPC-specific ==asm volatile("lwsync" ::: "memory")==
+ Any Win32 Interlocked operation, except on Xbox 360
+ Many operations on C++11 atomic types, such as ==load(std::memory_order_acquire)==
+ Operations on POSIX mutexes, such as ==pthread_mutex_lock==
任何memory barrier也是compiler barrier。
在c11/c++11中可以使用下列的API來使用fence。
```c=
#include <stdatomic.h>
atomic_thread_fence(memory_order_acquire);
atomic_thread_fence(memory_order_release);
```
The key idea of a ==std::atomic_thread_fence== is, to establish synchronisation and ordering constraints between threads without an atomic operation.
在cppreference中atomic_thread_fence的解釋。
>Establishes memory synchronization ordering of non-atomic and relaxed atomic accesses, as instructed by order, without an associated atomic operation.
不需要任何atomic operation的情況下,建立synchronization ordering。
**一個relaxed的atomic store操作前面有release fence就會被轉變成release fence。**
下面這段程式碼的意思是,我在store上面安插了一個release memory barrier,所以barrier之前的load/store不可以重排到barrier之後,也就是g_guard.store之後。但是因為store使用了relaxed所以只保證是個原子操作,所以可以允許barrier之後的順序重新排列。
```c
std::atomic_thread_fence(std::memory_order_release);
g_guard.store(1, std::memory_order_relaxed);
```
等同於下面的程式碼。意味著,store操作前面有個release memory barrier。
```c
g_guard.store(1, std::memory_order_release);
```
**同理,一個relaxed的atomic load操作接著acquire fence就會變成acquire fence。**
```c
if (atomic_load_explicit(published, memory_order_relaxed) == 1) {
atomic_thread_fence(memory_order_acquire);
assert(*val == 1); /* 不會失敗 */
}
```
等同於
```c
if (atomic_load_explicit(published, memory_order_acquire) == 1) {
assert(*val == 1);
}
```
### Compare and Swap
1. [You Can Do Any Kind of Atomic Read-Modify-Write Operation](https://preshing.com/20150402/you-can-do-any-kind-of-atomic-read-modify-write-operation/)
雖然stdatomic.h只定義一些原子操作。如下所示:
```cpp
std::atomic<>::fetch_add()
std::atomic<>::fetch_sub()
std::atomic<>::fetch_and()
std::atomic<>::fetch_or()
std::atomic<>::fetch_xor()
std::atomic<>::exchange()
std::atomic<>::compare_exchange_strong()
std::atomic<>::compare_exchange_weak()
```
但是可以透過compare-and-swap來達到任何RMW(read-modify-write)的原子操作特性。
```c
shared.compare_exchange_weak(T& expected, T desired, ...);
```
當shared和expect一樣的時候,就把desired的值存到shared。

以下是乘法的例子,因為stdatomic.h中沒定義原子乘法。
```cpp=
uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier)
{
uint32_t oldValue, newValue;
do {
oldValue = shared.load();
newValue = oldValue * multiplier;
} while(!shared.compare_exchange_weak(oldValue, newValue));
return oldValue;
}
```
CAS的精華就是,
1. 先從共享資料取(shared)得一份snapshot。這邊是oldValue。
2. 對oldValue進行你要的操作,得到newValue。
3. 比較shared和oldValue,如果一樣,表示中間沒有thread改過,進行swap把newValue存到shared。
另外一個例子:
```cpp=
uint32_t atomicDecrementOrHalveWithLimit(std::atomic<uint32_t>& shared)
{
uint32_t oldValue = shared.load();
uint32_t newValue;
do
{
if (oldValue % 2 == 1)
newValue = oldValue - 1;
else
newValue = oldValue / 2;
if (newValue < 10)
break;
}
while (!shared.compare_exchange_weak(oldValue, newValue));
return oldValue;
}
```
### Synchronize-with
1. [The Synchronizes-With Relation](https://preshing.com/20130823/the-synchronizes-with-relation/)
如何正確的從一個thread把修改後的資料正確的傳遞到另一個thread。這就是synchronize-with的用意。
>”Synchronizes-with” is a term invented by language designers to describe ways in which the memory effects of source-level operations – even non-atomic operations – are **guaranteed to become visible to other threads.**
一個thread的結果,對另一個thread來說是visible。
```cpp=
void SendTestMessage(void* param)
{
// Copy to shared memory using non-atomic stores.
g_payload.tick = clock();
g_payload.str = "TestMessage";
g_payload.param = param;
// Perform an atomic write-release to indicate that the message is ready.
g_guard.store(1, std::memory_order_release);
}
bool TryReceiveMessage(Message& result)
{
// Perform an atomic read-acquire to check whether the message is ready.
int ready = g_guard.load(std::memory_order_acquire);
if (ready != 0) {
// Yes. Copy from shared memory using non-atomic loads.
result.tick = g_payload.tick;
result.str = g_payload.str;
result.param = g_payload.param;
return true;
}
// No.
return false;
}
```
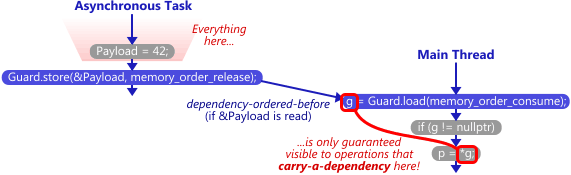
對TryReceiveMessage來說,如果看到g_guard為1的時候,表示g_payload都已經ready了,可以把它拿走使用。這種關係稱為synchronize-with,如下圖所示。
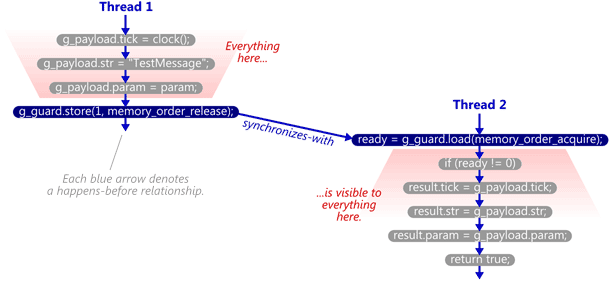
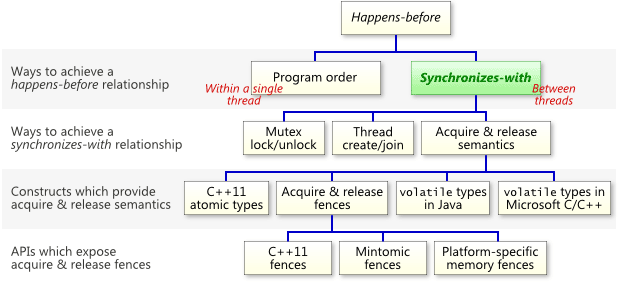
另外,read-acquire/write-release不是唯一的synchronize-with的方法,參考網站的作者彙整了資料如下:
### The purpose of memory_order_consume
1. [The Purpose of memory_order_consume in C++11](https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/)
2. [Consume Demo program](https://github.com/preshing/ConsumeDemo/blob/master/acquire/main.cpp)
以下的程式碼在不同平台上,所呈現的結構也不一樣。尤其是barrier的使用。
```cpp=
g = Guard.load(memory_order_acquire);
if (g != 0)
p = Payload;
```
在x86/x86_64上面,因為是strong memory model,所以不必使用任何的barrier,因為順序也不會重排。
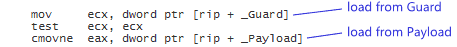
但是在PowerPC上,它是weak memory model,所以會在兩個Load之間產生barrier,因為從程式碼的角度定義了acquire所以會避免兩個Load之間的排序。

同理,ARMv7也是weakly-ordered CPU,一樣會使用barrier在兩個Load之間,避免順序重排。

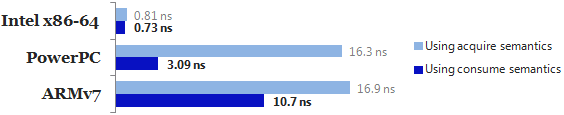
在PowerPC和ARMv7上使用barrier導致一定的效能下降。下圖為不同平台上的效能比較。
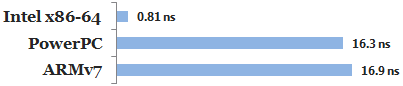
==即使在PowerPC和ARMv7上,有一種情況不需要使用barrier也不會有順序重排,那就是data-dependent。==
>there are some cases where they do enforce memory ordering at the machine instruction level without the need for explicit memory barrier instructions. Specifically, these processors always preserve memory ordering between data-dependent instructions.
例如以下的code:
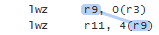
r9是第一個instruction的輸出,給第二個instruction當成輸入。因為這兩個instruction有data dependency所以loads會==in-order==執行。
當然不只register,讀寫memory也會有data dependency。
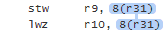
多個指令間的相依,稱為**data dependency chain**。在所有chain上面的執行都會被保證為in-order。

當寫程式碼時,如果指令之間有相依性,那compiler就會產生有data dependency的assembly。

為了使用comsume的特性,我們把上面的程式碼修改成如下:
```cpp=
g = Guard.load(memory_order_consume);
if (g != nullptr)
p = *g;
```
Guard.load的輸出g,會成為下一個的輸入。進而達到data dependency。
因為data dependency消除了costly memory barrier,所以效能得以提升。
在真實的世界中,linux kernel中的rcu就是用到這個技巧來避免使用memory barrier。
>One real-world example of a codebase that uses this technique – ***exploiting data dependency ordering to avoid memory barriers*** – is the Linux kernel.
### Memory Order
1. [深入理解C11/C++11內存模型](https://kknews.cc/zh-tw/code/v5e43gq.html)
2. [The Purpose of memory_order_consume in C++11](https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/)
3. [Acquire and Release Semantics](https://preshing.com/20120913/acquire-and-release-semantics/)
4. [Weak vs. Strong Memory Models](https://preshing.com/20120930/weak-vs-strong-memory-models/)
6. [An Introduction to Lock-Free Programming](https://preshing.com/20120612/an-introduction-to-lock-free-programming/)
7. [Memory Reordering Caught in the Act](https://preshing.com/20120515/memory-reordering-caught-in-the-act/)
8. [preshing github](https://github.com/preshing)
> Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that ==follows== it in program order.
>Release semantics prevent memory reordering of the write-release with any read or write operation that ==precedes== it in program order.
>One way to obtain the desired memory barriers is by issuing ==explicit== fence instructions.
>C++11’s atomic library standard defines a portable function ==atomic_thread_fence()==
The memory_order_relaxed arguments above mean ==“ensure these operations are atomic, but don’t impose any ordering constraints/memory barriers that aren’t already there.”==
### volatile
1. [ATOMIC](https://biscuitos.github.io/blog/ATOMIC/)
2. [易於誤用 volatile 關鍵字](https://hackmd.io/@sysprog/concurrency-atomics#%E6%98%93%E6%96%BC%E8%AA%A4%E7%94%A8-volatile-%E9%97%9C%E9%8D%B5%E5%AD%97)
**volatile 的使用意味著抑制編譯器最佳化**
編譯器對訪問該變數的程式碼就不再進行優化,從而可以提供對特殊地址的穩定訪問;如果不使用 volatile,則編譯器將對所聲明的語句進行優化。
volatile 關鍵詞影響編譯器編譯的結果,用 volatile 聲明的變數表示==該變數隨時可能發生變化==,與該變數有關的運算,不要進行編譯優化,以免出錯。
現代CPU都會把結果cache起來,方便以後繼續讀取使用。所以容易讓其他CPU看到錯誤的資料。因為multi thread會跑在不同的CPU。volatile應該解釋為 ==“直接存取原始記憶體地址”== 比較合適。如果兩個thread共同使用的變數通過 volatile 限定之後,任意thread對變數值修改之後,都會同步到memory,以此其他thread可以看到一樣的值。
問題在於 volatile 不能保證能夠讀到「最新」的資料,==它只保證編譯器每次都產生 load 操作。== 而 CPU 在執行過程中重排,使得該 load 操作讀到「舊值」,從而導致混亂。必須和memory barrier一起使用,才可以達到預期的效果。
**不應該用 volatile 做thread間同步,因為它禁止了編譯器優化,性能會下降。這種時候就應該用專門解決thread同步問題的方法。**
運用場景
1. 中斷服務process中修改的供其它process檢測的變數需要加 volatile.(因為ISR視為一個不可被打斷的thread/process,存取的共同變數)
2. multitask環境下各任務間共享的標志應該加 volatile.(==不同thread/process 存取的共同變數==)
3. 記憶體映射的硬體暫存器通常也要加 voliate,因為每次對它的讀寫都可能有不同意義.(硬體暫存器的變數會被CPU或是硬體修改)
=>只要變數的變動,不會被另一個CPU(thread/ISR)讀取到,就應該加volatile。
**解決concurrency的問題應該是用,
volatile(防止compiler優化) +
compiler barrier(防止compiler reorder) +
memory barrier(防止out-of-order execution)。**
因為memory barrier有compiler barrier的作用,所以使用memory barrier(implied compiler barrier)即可。參考:[Implied Compiler Barriers](https://preshing.com/20120625/memory-ordering-at-compile-time/#Implied-compiler-barriers)
>In the new C++11 (formerly known as C++0x) atomic library standard, **every non-relaxed atomic operation acts as a compiler barrier as well.**
#### READ_ONCE/WRITE_ONCE
1. [READ_ONCE()](https://zhuanlan.zhihu.com/p/102753962)
2. [Linux内核中的READ_ONCE和WRITE_ONCE宏](https://zhuanlan.zhihu.com/p/344256943)
**READ_ONCE()/WRITE_ONCE就是volatile的封裝。當需要用的時候把變數轉換成volatile型態。**
include/asm-generic/rwonce.h
```c
#define __READ_ONCE(x) (*(const volatile __unqual_scalar_typeof(x) *)&(x))
#define __WRITE_ONCE(x, val) \
do { \
*(volatile typeof(x) *)&(x) = (val); \
} while (0)
```
對於 volatile 變數來說,以一個 sequence point 為分界點,對於前面 volatile 變數的存取必須完成,且對於後面 volatile 變量的存取必須尚未開始。
```c
#define __READ_ONCE(x) (*(const volatile int *) &(x))
int a, b;
int i, j;
void foo()
{
a = __READ_ONCE(i);
b = __READ_ONCE(j) / 16;
}
```
**編譯器只是保證 2 個 volatile 變數之間讀取不會被亂序,但是 non-volatile 變數和 volatile 變數的讀取順序,依舊允許亂序。**
### Example
參考 [sysprog21/concurrent-programs](https://github.com/sysprog21/concurrent-programs)
1. [ringbuffer(SPSC)](/PcDLBa9kTluu9yXnF4SbgQ)
2. [SPMC](/Lexlfim5Ri-ptGWFJ6NgHw)
3. [MPSC](/NZ1Hw4_PSc6r_7L9U8Xt4Q)
4. [MPMC](/0jXe8cx7Tb6PYrSNEgpkOA)
5. Harzard Pointer
6. hashmap
### Conclusion
1. 不同thread間存取的相同資源是什麼??
2. 有沒有ABA的問題?
3. 盡量做到資源切割,或是使用Thread local storage。
4. 資料間有沒有false sharing問題??(performance issue)**(不同thread之間的變數在同一個cache line上面)**
5. 單一資料有沒有跨過兩個cahce line?
6. 共同變數上使用volatile來防止compiler優化。
###### tags: `linux2021`