# Concurrency Study -- ringbuffer
參考:
1. lock-less ringbuffer [ringbuffer.c](https://github.com/sysprog21/concurrent-programs/blob/master/ringbuffer/ringbuffer.c)
<!--2. lock-free mpmc ring buffer [lfring.c](https://github.com/sysprog21/concurrent-programs/tree/master/lfring)
3. [linux2021-summer-quiz4-test2](https://hackmd.io/@sysprog/linux2021-summer-quiz4#%E6%B8%AC%E9%A9%97-2) -->
2. [DPDK: Ring Library](https://doc.dpdk.org/guides/prog_guide/ring_lib.html)
* [bufring.h in FreeBSD](http://svn.freebsd.org/viewvc/base/release/8.0.0/sys/sys/buf_ring.h?revision=199625&view=markup)
* [bufring.c in FreeBSD](http://svn.freebsd.org/viewvc/base/release/8.0.0/sys/kern/subr_bufring.c?revision=199625&view=markup)
---
## ringbuffer 概論
ringbuffer或稱circular buffer。==固定大小==,當存取到底的時候,就會回過頭繼續存取開頭。通常會有兩個pointer,一個指向下一個要寫的位置,一個指向下一個要讀取的位置。**重點是怎麼判斷buffer是滿的或是空的。**
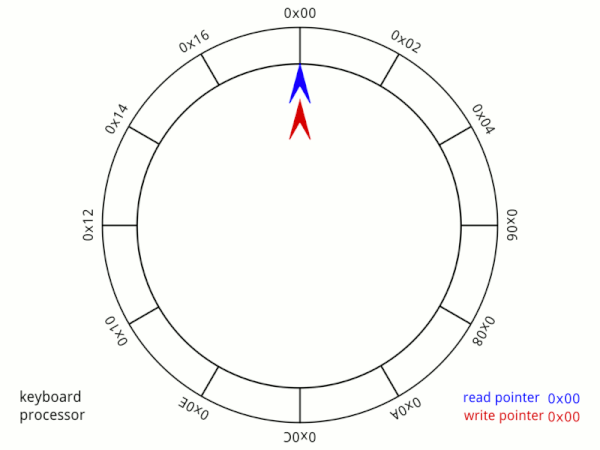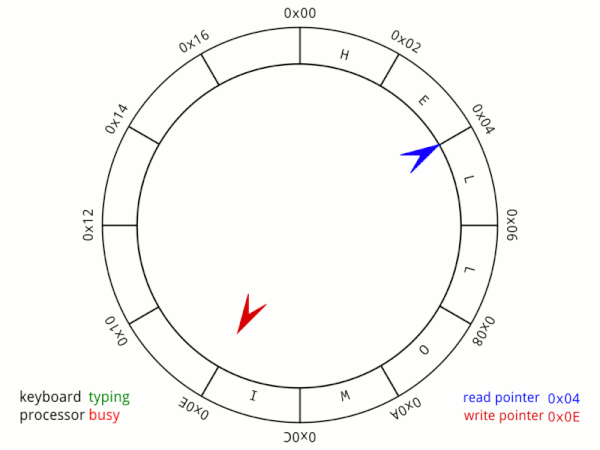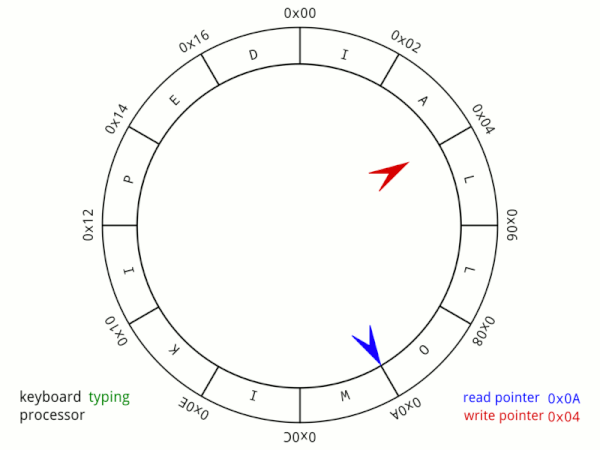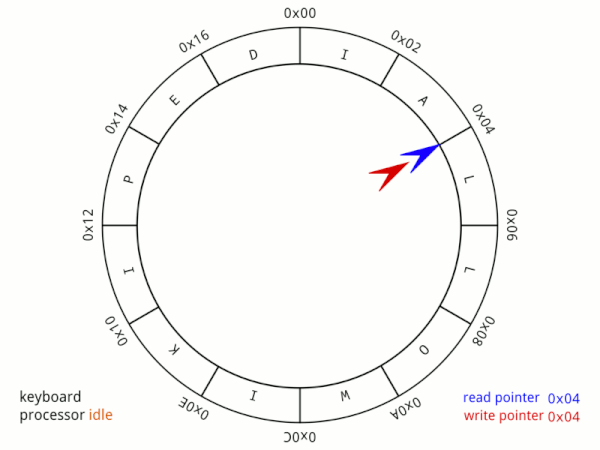
## ringbuffer is full or empty?
一般來說ringbuffer的重點是判斷到底現在是空的還是滿的,也就是需要知道還剩多少空間可以儲存或是多少空間還沒讀取。最簡單的辦法就是使用一個紀錄size的變數。
**這邊使用一個技巧,用一個比ringbuffer還大的unsigned數值當成read和write的位置。**
例如: 使用unsigned int 來記錄大小為8的ringbuffer。
因為size為2的倍數,所以read/write位置可以輕易的用 read & 0xf來取得。

再來探討一般情況,read和write都沒超過unsigned int最大值。
所以,寫入了多少資料可以用以下取得。
```c=
used = write - read;
```
剩下多少的空間可以用
```c=
avaliable = buffer_size - used;
```
所以判斷full就是read 和 write相差一個buffer size。因為buffer size為2的倍數,所以==只要判斷最後的幾個bit有沒有相同。== 即使,write位置overflow一樣成立。mask = buffer_size - 1 = 0b0111。後三個bit相同即為full。

```c=
mask = buffer_size - 1;
isFull = (write & mask) == (read & mask);
```
如果是用上面的方法判斷,會有個問題就是***如果是empty的情況,read和write相同的時候,也會被判斷成full。*** 所以改用以下方法。
```c=
isFull = (write - read == buffer_size);
```
或是因為buffer_size為2的倍數,所以可以額外比較MSB。
```c=
isFull = ((write & mask) == (read & mask) &&
(write & buffer_size) != (read & buffer_size));
```

empty的判斷更簡單,只要比較read和write的位置是不是一樣即可。一樣這個方法也不用管write是否overflow。
```c=
isEmpty = write == read;
```
## Align to power of 2
既然size為2的倍數那麼重要,所以判斷是否為2的倍數,或是轉成大於原本數的方法就格外重要。
判斷是否為2的倍數。
```c=
#define IS_POWEROF2(x) ((((x) -1) & (x)) == 0)
```
向上align到2的倍數。把自己加上負數自己取align - 1的位數。
```c=
#define ALIGN_CEIL(val, align) \
(typeof(val))((val) + (-(typeof(val))(val) & ((align) -1)))
```
例如: val = 13 = 0b1101, align to 64(0b0100_0000)。因為負數為!(val) + 1。所以:
```c=
13 = 0b0000_1101;
-13 = 0b1111_0010 + 1 = 0b1111_0011;
```
如果 val + !(val) 剛好會等於 0b1111_1111,全部都是1的情況。所以使用mask只取要align的部分。
```c=
0b0000_1101 = val;
0b1111_0010 = ~val;
0b1111_0011 = ~val + 1;
0b0011_0011 = (~val + 1) & (align - 1);
0b0100_0000 = val + ((-val) & (align - 1));
```
## Watermark and DMA
參考:[The design and implementation of a lock-free ring-buffer with contiguous reservations](https://blog.systems.ethz.ch/blog/2019/the-design-and-implementation-of-a-lock-free-ring-buffer-with-contiguous-reservations.html)
有些情況,我們需要連許寫入的空間,可是剛好ringbuffer的連續寫入空間不足,如下圖所示。
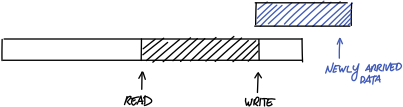
解決辦法是,設一個watermark來表示,watermark之後的還沒真的寫入,但是假設他已經寫入,所以write可以回到0的位置。且從0到read也有足夠空間來讓你寫入。
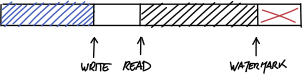
什麼情況會有這種需求?? ==DMA(Direct Memory Access)==
>DMA transactions do not understand the concept of a circular buffer. **They are only aware of a pointer to where the memory region starts, and how many bytes to use from the starting pointer.** This means that a normal circular buffer where the data region could wrap around would not work for DMA transfers.
因為DMA只給一個memory region start和多少bytes需要被傳輸,不知道circular buffer的機制,所以有可能發生寫過頭的現象。
>we leave an artificial “hole” in the “infinite buffer” representation. The watermark lets us keep track of where the “hole” starts, and the end of the physical buffers marks the end.
所以我們用watermark來表示之後到end of physical buffer都沒有data。
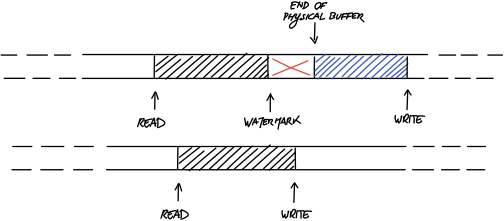
如果有watermark的設計,那write在寫入之前要先確定連續空間夠不夠,不夠就必須設定watermark。
```cpp=
// [writer thread]
if buffer.len.saturating_sub(buffer.write.load()) >= write_len {
// not shown: check `read` to make sure there's enough free room
buffer.watermark.store(buffer.write.load() + write_len);
buffer.write.store(buffer.write.load() + write_len);
} else { // not enough space, wrap around
// not shown: check `read` to make sure there's enough free room at the beginning of the buffer
buffer.watermark.store(buffer.write.load());
buffer.write.store(0 + write_len);
}
```
## Using two pointer to indicate progress
這邊有個技巧,使用兩個pointer來代表是不是進行中。
1. 進行前/後,(head == tail)
2. 進行中。(head != tail)
如下圖所示,在還沒開始之前,prod_head和prod_tail指向同一個block,就是下一個要寫入的位置。

### First step
開始要寫入時,prod_head會指向,最後要到達的位置。也就是prod_head = prod_head + n; 其中n為欲寫入的長度。==此時prod_head等於prod_tail。==

### Second step
把global variable(prod_head)指向local variable(prod_next),並且開始寫入資料。==此時prod_head不等於prod_tail。==

## Third-step
資料寫入完成之後,把global variable(prod_tail)移動到local variable(prod_next)。==此時prod_head又等於prod_tail。==

寫入(enqueue)流程如下所示。
```c=
uint32_t prod_next = prod_head + n;
r->prod.head = prod_next;
/* write entries in ring buffer */
ENQUEUE_PTRS();
__compiler_barrier();
r->prod.tail = prod_next;
```
同理,讀取(dequeue)也有類似的程式架構。
```c=
uint32_t cons_next = cons_head + n;
r->cons.head = cons_next;
/* copy in table */
DEQUEUE_PTRS();
__compiler_barrier();
r->cons.tail = cons_next;
```
所以,
prod_head表示produce thread最後準備要寫入的位置。(未來)
prod_tail表示produce thread已經寫入的位置。(現在)
cons_head表示consume thread最後讀取取完的位置。(未來)
cons_tail表示consume thread已經讀取的位置。(現在)
只有consume thread才需要知道已經寫入的數量,因為==必須判斷要讀取的數量是否大於已寫入的數量。== 如果是multi consume thread所以必須知道其他consume thread正要讀取的最後位置(cons_head)。和已經寫入的最後位置(prod_tail)。
```c
uint32_t entries = prod_tail - cons_head;
```
## SPSC(Single Producer Single Consumer)
只有一個producer thread和一個consumer thread,意味著,只有一個producer thread來存取struct prod和ring[],並且讀取struct cons的值來判斷。同一個時間sturct prod的值不會改變。
```c=
static inline int ringbuffer_sp_do_enqueue(ringbuf_t *r,
void *const *obj_table,
const unsigned n)
{
uint32_t mask = r->prod.mask;
uint32_t prod_head = r->prod.head;
uint32_t cons_tail = r->cons.tail; // r->cons.tail隨時會被consumer thread修改,
// 讀進來這個時間點,已經把值暫存在local
// 既然是兩個thread,要用atomic比較好??
// 這個時間點,cons.tail有可能被改變,
// 就是被讀走更多資料,==所以free_entries只會更多,不影響後續進行==
uint32_t free_entries = mask + cons_tail - prod_head;
/* check that we have enough room in ring buffer */
if ((n > free_entries))
return -ENOBUFS;
uint32_t prod_next = prod_head + n;
r->prod.head = prod_next;
/* write entries in ring buffer */
ENQUEUE_PTRS(); // 會不會有兩個thread同時存取相同位置ring[]的問題??
// 不會。
// 因為 consumer thread會讀取prod.tail來判斷buffer size
// 避免寫超過prod.tail,而producer thread正好從prod.tail
// 開始寫入資料。
__compiler_barrier();
r->prod.tail = prod_next;
/* if we exceed the watermark */
return ((mask + 1) - free_entries + n) > r->prod.watermark ? -EDQUOT : 0;
}
```
## 不同thread間存取的相同資源是什麼??
兩個thread,producer和consumer。
producer主要存取struct prod和ring[],但是會讀取cons.tail.
consumer主要存取struct cons和ring[],但是會讀取prod.tail.
對producer來說共同存取的資源是,ring[]和cons.tail。也就是**這兩個隨時都在改變,producer不一定會得到最正確的值。**
但是==cons.tail只會影響free_entries的判斷,只會讓free_entries更多,不會影響接下來enqueue的動作。==
==ring buffer的存取,因為producer是從prod.tail來往上enqueue,consumer是從cons.tail一直dequeue到prod.tail,所以prodc.tail是個分水嶺,把enqueue和dequeue動作分開來了,不會有同時存取的問題。==
同樣道理也適用於consumer theead。
## 有沒有ABA的問題?
這邊沒有進行任何的memory allocate,因為是SPSC的緣故,共同存取的變數從A->B->A,也不會影響判斷。所以沒有此問題。另外,enqueue的時候只是把address放進去,不是真的allocate的記憶體空間,因為不會有ABA問題。
```c=
for (int i = 0; !ringbuf_is_full(r); i++)
ringbuf_sp_enqueue(r, *(void **) &i);
```
## thread 間的資料切割
在怎麼好的程式技巧,還不如好好減少thread間的共同資料存取。這邊用兩個struct來區分不同thread的存取資料。
```c=
typedef struct {
struct { /** Ring producer status. */
uint32_t watermark; /**< Maximum items before EDQUOT. */
uint32_t size; /**< Size of ring buffer. */
uint32_t mask; /**< Mask (size - 1) of ring buffer. */
volatile uint32_t head, tail; /**< Producer head and tail. */
} prod __attribute__((__aligned__(CACHE_LINE_SIZE)));
struct { /** Ring consumer status. */
uint32_t size; /**< Size of the ring buffer. */
uint32_t mask; /**< Mask (size - 1) of ring buffer. */
volatile uint32_t head, tail; /**< Consumer head and tail. */
} cons __attribute__((__aligned__(CACHE_LINE_SIZE)));
void *ring[] __attribute__((__aligned__(CACHE_LINE_SIZE)));
} ringbuf_t;
```
## 資料間有沒有false sharing問題??
從上面的struct來看,兩個sub struct皆被align在cache line上面,所以不會有false sharing的問題。performance比較好。
## 單一資料有沒有跨過兩個cahce line?
變數皆是32bits或是64bits,不會有單一資料跨過兩個cache line的問題。
## 共同變數上使用volatile來防止compiler優化。
prod.head, prod.tail和cons.head, cons.tail皆有宣告成volatile。另外ring[]需要宣告成volatile??
###### tags: `linux2021`