# Leetcode刷題學習筆記 -- Bucket Sort
## Introduction
ref : [Bucket Sort form GeeksforGeeks](https://www.geeksforgeeks.org/bucket-sort-2/)
ref : [Bucket Sort from Leetcode](https://leetcode.com/explore/learn/card/sorting/695/non-comparison-based-sorts/4439/)
把目標數字分散在幾個桶子裡面,對每個桶子進行排序,最後依序取出數字,即為排序後的結果。
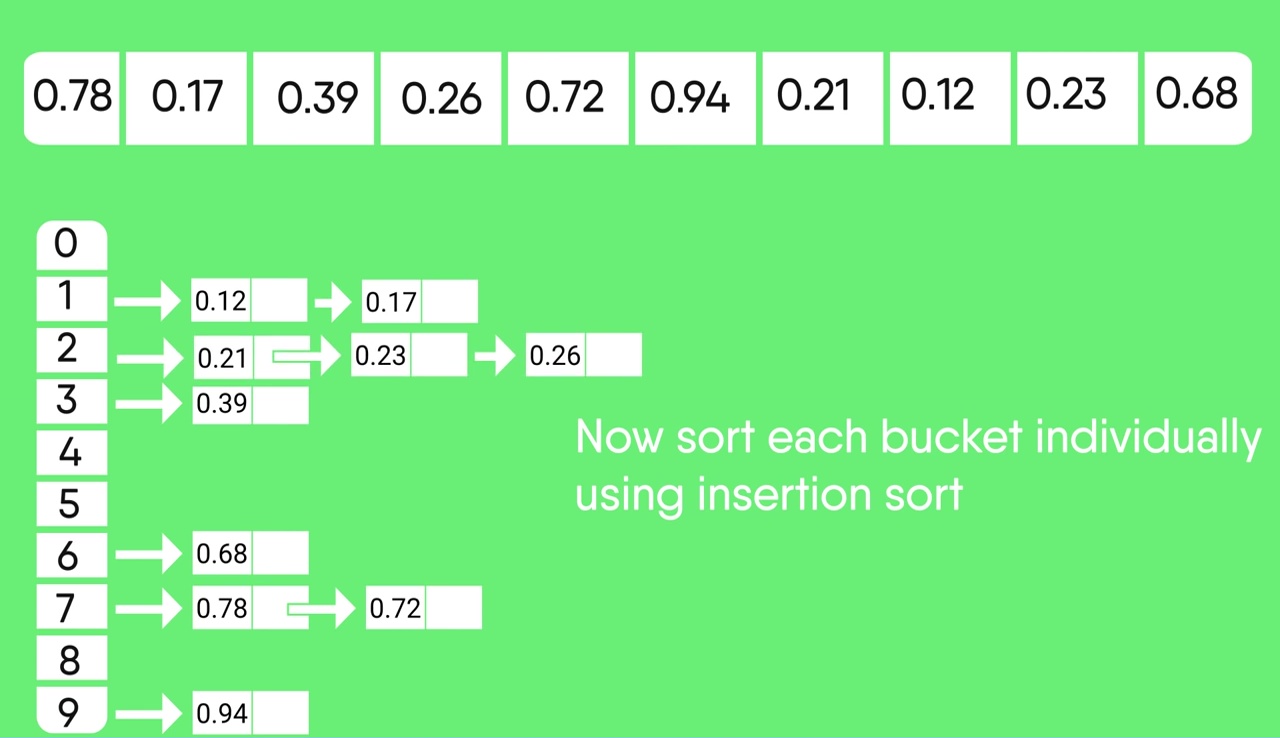
* 如果有負數的情況,可以分成兩個vector(正數和負數),分別對兩個vector做bucket sort,最後再合併成一個。負數一定比較小,所以先取負數。
* ref : [Bucket Sort To Sort an Array with Negative Numbers](https://www.geeksforgeeks.org/bucket-sort-to-sort-an-array-with-negative-numbers/)
## 使用情況
* 輸入是在一個範圍內,不規則的分佈。(input is uniformly distributed over a range)
* 針對非數值的範圍排序,例如:出現的頻率
* [347. Top K Frequent Elements](https://hackmd.io/K5s3M6TkS0q2HrRpCBpnnQ?both#347-Top-K-Frequent-Elements)
* 如果範圍不大,可以降低sort的複雜度。
* 對長度為N的vector進行排序,time complexity為$O(NlogN)$,但是使用bucket sort為O(N)
## Procedure
1. 先找出最大最小值,計算shift和bucket間的range
```cpp
vector<int>& nums;
auto [mn, mx] = minmax_element(begin(nums), end(nums));
int shift = *mn, range = (*mx - *mn) / k;
```
2. 建立k個bucket
```cpp
vector<vector<int>> buckets(k, vector<int>());
```
3. 分配每個element進入bucket
```cpp
for(auto& n : nums) {
int idx = (n - shift) / range;
buckets[idx].push_back(n);
}
```
4. 對每個bucket排序
```cpp
for(auto& vec : buckets)
sort(vec.begin(), vec.end());
```
5. 把所有的buckets內容收集到同一個vector
```cpp
int idx = 0;
for(auto& vec : buckets) {
for(auto& n : vec) {
nums[idx++] = n;
}
}
```
## Time Complexity
worst case : 全部的數值都在同一個bucket,
等於沒分類的效果,就是看你的sort algoritm,最壞情況是$O(N^2)$
best case : 每個bucket都只有一個element,不需要對每個bucket做sort,所以分配element:$O(N)$,把bucket內容組合起來$O(K)$,所以best case是$O(N+K)$
| | Best | Average | Worst |
| --- | ---- | ------- | ----- |
| Bucket Sort | $O(N+K)$ | $O(N+K)$ | $O(N^2)$ |
## Space complexity
需要額外的空間儲放所有的element,所以$O(N)$
## Example
### [220. Contains Duplicate III](https://leetcode.com/problems/contains-duplicate-iii/)
給你一個vector<int> nums, 找出index差小於等於k,且數字差小於等於t。
$abs(num[i] - nums[j]) <= t$ 且 $abs(i - j) <= k$。
> 1. 看到index差小於等於k,就會想到使用sliding window用兩個指標來代表window的前後。
> 2. ==重點是window裡面的資料怎麼排列?==
> 3. 因為兩個數的差小於等於t,可以使用bucket sort,每個bucket裡面的數字差一定小於等於t。
> 4. bucket裡面不會有兩個以上的數字,因為只要是兩個就會成立離開。
> 5. 還要跟前後的bucket去比較
```c
bool containsNearbyAlmostDuplicate(vector<int>& nums, int k, int t) {
int sz = nums.size();
unordered_map<int, int> m;
for(int i = 0, j = 0; i < sz; ++i) {
// 計算bucket,因為t有可能為INT_MAX,所以轉成long
int b = nums[i] / ((long)t + 1);
// 因為負數也會有0的情況
if(nums[i] < 0) b--;
// 兩個數在同一個bucket,符合情況。
if(m.count(b)) return true;
// 檢查後一個bucket
if(m.count(b + 1) && (long)m[b + 1] - nums[i] <= t) return true;
// 檢查前一個bucket
if(m.count(b - 1) && (long)nums[i] - m[b - 1] <= t) return true;
// 把資料放入bucket
m[b] = nums[i];
// 移除超出範圍的數字
if(i - j == k) {
int bj = nums[j] / ((long)t + 1);
if(nums[j] < 0) bj--;
m.erase(bj);
j++;
}
}
return false;
}
```
### [347. Top K Frequent Elements](https://leetcode.com/problems/top-k-frequent-elements/)
```cpp
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> freq; // value, count
for(auto& n : nums) freq[n]++; // O(N)
// create buckets, 因為最多出現次數為nums.size()
vector<vector<int>> buckets(nums.size() + 1, vector<int>());
for(auto& ref : freq)
buckets[ref.second].push_back(ref.first); //O(N)
vector<int> rtn; // O(K)
for(int i = buckets.size() - 1; i >= 0; --i) {
for(auto& n : buckets[i]) {
rtn.push_back(n);
k--;
if(k == 0) return rtn;
}
}
// time : O(N+N+K) = O(2N+K) = O(N+K)
// space : O(N+N) = O(2N) = O(N)
return {};
}
```
###### tags: `leetcode` `刷題`