# Hand Pose Recognition ---- Using High-Density Surface Electromyogram Recordings
Contributed by < `group7` >
P86104110 黃柏瑜
P88104069 張安之
S98081054 高明蔚
## Overview
Our project design an addaptable low latancy response prosthetic control system based on the deep learning technique, **While ensuring its accuracy,** **we have shortened the detection time so that it can operate with lower latency**.
## Target Issue
### Prosthetic control
Dexterous hand motion is critical for object manipulation. Electrophysiological studies of the hand are key to understanding its underlying mechanisms. **High-density electromyography (HD-EMG)** provides spatio-temporal information about the underlying electrical activity of muscles, which can be used in neurophysiological research.
### Specific aim
Our specific aim is to **design an low latancy response prosthetic control system**, by reciving a short signal from EMG array attached on front end of upper extremity, the system can rapidly derive palm amputation patients' intention, and sending correct action command to control the mechanical palm.
## Method
### Deep learing
Due to the multi-channel EMG complexity, it is hard to design a addaptable hand pose classifier using traditional signal processing method. Deep leaning method can saperate this hard task into pieces to fulfill our objective. We chose **High-Density Surface Electromyogram Recordings (HD-sEMG)** open dataset and tool on web to train our detector. This dataset includes **34** common hand movements, competent enough to cover most hand tasks in everyday life.
### Literature review
In practical applications, users of mechanical prosthetic hands not only hope that the system can correctly predict their intentions, but also expect the consistency of thinking and action, that is, low latency between the intention occurred and the beginning of performing a single move.
#### Time window length
Time window, a length of time to determine how long EMS signal the system can receive to predict a single move, will directly affect the latancy of the system, but too short of the time window lengh would cause bad prediction because it means that the system can only predict the intent of the user with few information. According to the original paper of the HD-sEMG we use, the reccomanded time window lengh is set to **250 ms** to predict the hand pose once.
To reduce delays caused by excessively long time windows, we foucus on [**the research**](https://ieeexplore.ieee.org/document/9535296) published in 2021, the analysis indicates that with the HD-EMG dataset we use, even with windows sizes as small as **32 ms**, can achieve considerably high decoding accuracy, e.g. ≥90%.
---
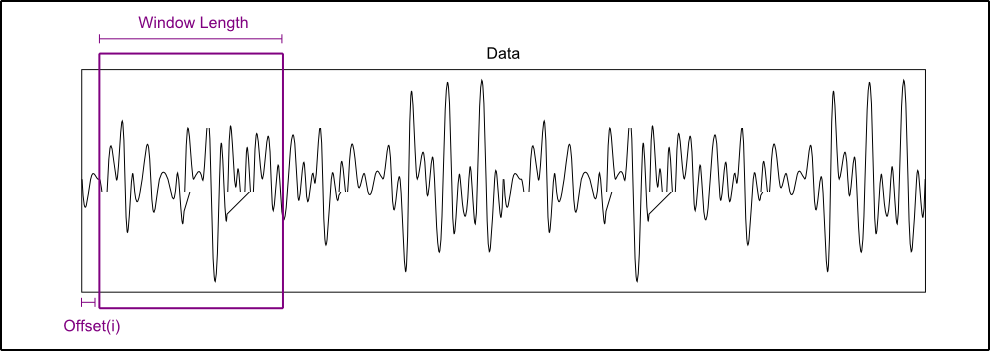
> The concept of window lengh is in that we called "siding window", The data inside the window is the current segment to be processed.
---
---
 
>Average mis-classification rates across the HD-EMG databases
>The dashed line represents the 10% acceptable threshold
---
The conclusion in the research would be the reference for us to shorten the time window length.
### Implement enviroment and materials
- Mac mini (M1, 2020)
- MATLAB_R2022a
- Open HD-sEMG dataset and toolkit
:::info
This deep learning training project mainly utilise "pattern recognition dataset (PR dataset) " in **High-Density Surface Electromyogram Recordings (HD-sEMG)** open dataset and tool on web.
- Click this [**Reference link**](https://physionet.org/content/hd-semg/1.0.0/) to get more information of this dataset
- Download the files (142.8Gb) by your terminal
```shell=
wget -r -N -c -np https://physionet.org/files/hd-semg/1.0.0/
```
:::
#### data discription
Twenty subjects, consisting of 12 males and 8 females (aged 22 to 34 years) with intact fingers, participated in this study.
For the PR dataset, a 256-channel HD-sEMG was acquired when subjects performed **34** different hand gestures. For each gesture, both **dynamic tasks** (1 s duration, from subjects' relaxed state to the required gesture) and **maintenance tasks** (4 s duration, from subjects' relaxed state to the required gesture followed with maintenance at that gesture) were performed.
In this project, we select **dynamic tasks** to train uor system.
---

> Diagram for 34 different hand gestures
> (1) thumb extension, (2) index finger extension, (3) middle finger extension, (4) ring finger extension, (5) little finger extension, (6) wrist flexion, (7) wrist extension, (8) wrist radial, (9) wrist ulnar, (10) wrist pronation, (11) wrist supination, (12) extension of thumb and index fingers, (13) extension of index and middle fingers, (14) wrist flexion combined with hand close, (15) wrist extension combined with hand close, (16) wrist radial combined with hand close, (17) wrist ulnar combined with hand close, (18) wrist pronation combined with hand close, (19) wrist supination combined with hand close, (20) wrist flexion combined with hand open, (21) wrist extension combined with hand open, (22) wrist radial combined with hand open, (23) wrist ulnar combined with hand open, (24) wrist pronation combined with hand open, (25) wrist supination combined with hand open, (26) extension of thumb, index and middle fingers, (27) extension of index, middle and ring fingers, (28) extension of middle, ring and little fingers, (29) extension of index, middle, ring and little fingers, (30) hand close, (31) hand open, (32) thumb and index fingers pinch, (33) thumb, index and middle fingers pinch, (34) thumb and middle fingers pinch.
---
---

> HD-sEMG dataset with 256 channel electrode array
---
### Data preparation
#### 256 channel HD-sEMG
Each subject takes only one second for recording one hand gesture per times, though time interval is short, high sample rate (2048 Hz) let it have high resolution in each signal segment.
---

> 1 second, 2048 Hz, 256 channel HD-sEMG signal visualization of a single subject, the reason why time interval is short is we want to just record the moment subject "trigger" one hand gesture perform, not from the begining to the end.

> This image shows only one channel recorded signal
---
#### K-fold
One of the most common technique for model evaluation and model selection in machine learning practice is K-fold cross validation. The main idea behind cross-validation is that each observation in our dataset has the opportunity of being tested. K-fold cross-validation is a special case of cross-validation where we iterate over a dataset set k times. In each round, we split the dataset into 𝑘 parts: one part is used for validation, and the remaining 𝑘−1 parts are merged into a training subset for model evaluation. The figure below illustrates the process of 5-fold cross-validation:
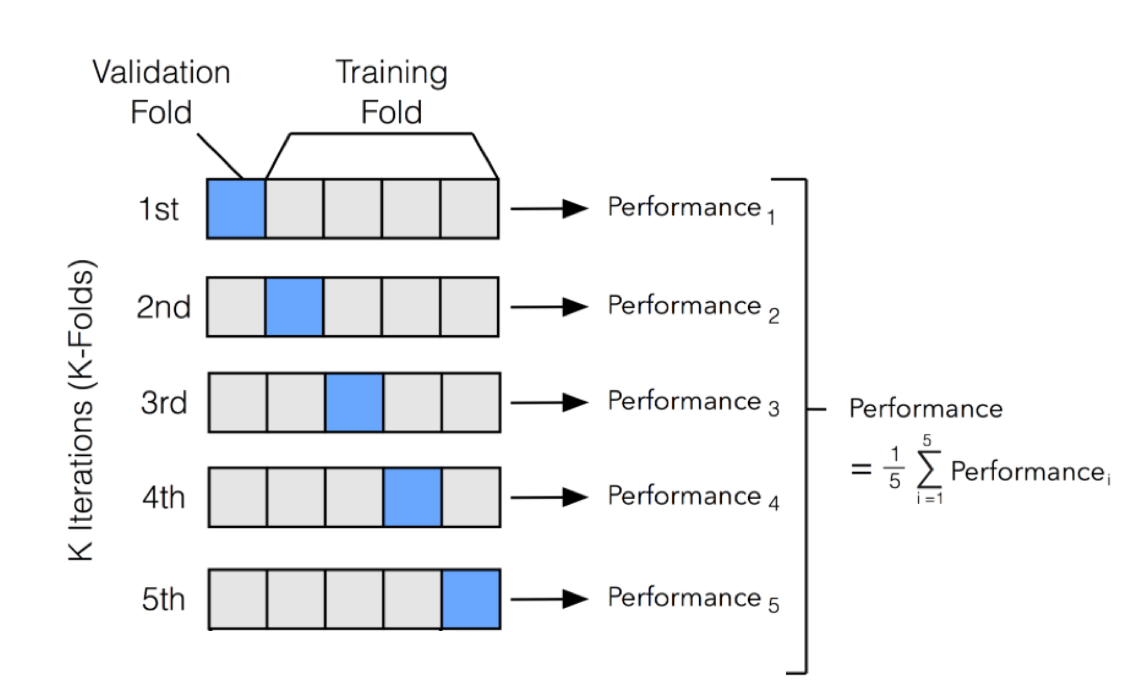
The main benefit behind this approach versus a simple train/test split is to reduce the pessimistic bias by using more training data in contrast to setting aside a relatively large portion of the dataset as test data.
In our project we perform **6-fold**, each session will be split into 6 group, totoally 12 group.
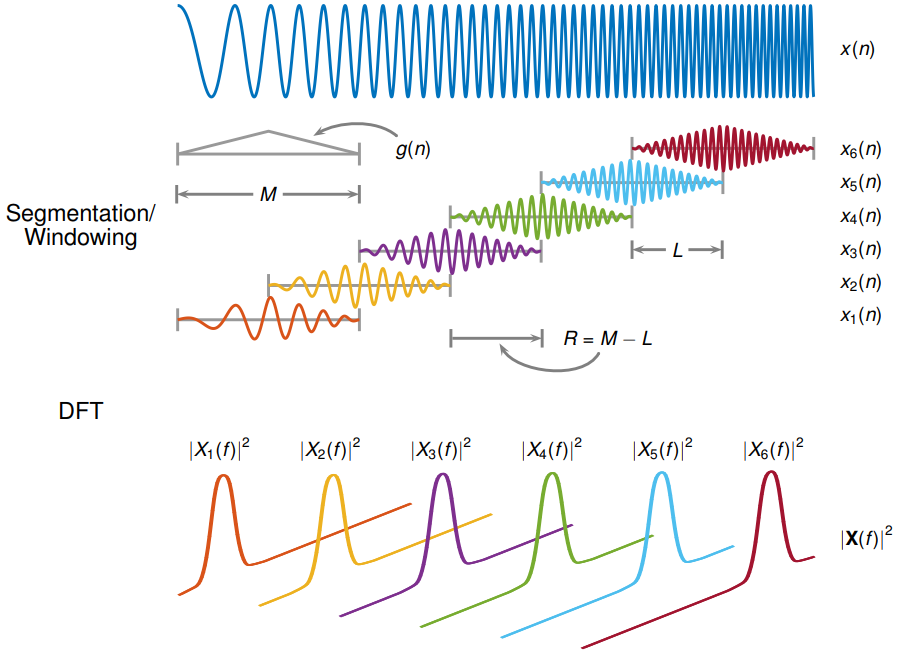
#### Short-time Fourier transform
:::info
We took effort to knowing Short-time Fourier transform, the artical below we just conclude something you have to know. For knowing more detail, please click **[HERE](https://www.mathworks.com/help/signal/ref/stft.html)** read MATLAB document
:::
The Short Time Fourier Transform (STFT) is a special flavor of a Fourier transform where you can see how your frequencies in your signal change through time. It works by **slicing up your signal into many small segments and taking the fourier transform of each of these**. The result is usually a waterfall plot which shows frequency against time.
Where are some features of this analysis method:
- If the signal you want to analysis is non stationary, general Fourier Transfrom lack the dimansion to make you clarify the variation during times by. STFT is suitable to show the variation in different time and frequency
- When the data is cut into pieces, the edges make a sharp transition that didn’t exist before. Multiplying by a **window function** helps to fade the signal in and out so that the transitions at the edges do not affect the Fourier transform of the data
---

> With general Fourier Transform, we only know this non stationary signal is mainly composed by three different frequency, but don't know "when" they appear.
---
According to the research of window length, we transformed each obtained 128 ms signal tospectrogram via short-time Fourier transform (STFT), using Hamming window with a length of 87 data points and 50% overlap. The output of STFT for each 128 ms signal is with 4 time frames and 44 spectral bands (23.27 Hz for each band)
---

> 256 channel HD-sEMG signal segment visualization of a single subjec signal, in time window 0.25 sec ~ 0.378 sec

> STFT of 1 channel HD-sEMG signal segment visualization of a single subjec signal, x-axis is time domain with ~> 32 ms resolution, and y-axis represent frequency domain with 23.27 Hz resolution
---
### Deep learning model structure
The representation $X ∈ R^{F×NR×NC}$ was fed into the CNN model, where $F = 4×44 = 176$ denotes the length of vectors stacked by 4 time frames in all **44** spectral bands, $NC × NR = 16×16$ denotes the **16×16** electrode array reshaped by the **256** channels. We used **batch normalization** to speed up convergence and avoid gradient vanishing problem. **Dropout technique** was applied to address overfitting issues
```verilog=
layers = [imageInputLayer([16,16,176])
convolution2dLayer(3,32,'Padding','same')
batchNormalizationLayer
leakyReluLayer(0.1)
dropoutLayer(0.2)
maxPooling2dLayer(3,'Stride',2)
convolution2dLayer(3,64,'Padding','same')
batchNormalizationLayer
leakyReluLayer(0.1)
dropoutLayer(0.2)
maxPooling2dLayer(3,'Stride',2)
fullyConnectedLayer(576)
fullyConnectedLayer(34)
softmaxLayer
classificationLayer];
options = trainingOptions('adam', ...
'InitialLearnRate',0.001, ...
'GradientDecayFactor',0.9, ...
'SquaredGradientDecayFactor',0.999, ...
'L2Regularization',0.0001, ...
'MaxEpochs',50, ...
'MiniBatchSize',512)
```
## Result
### accuracy
#### Original result in dataset source code (250 ms window length)

- Best mini batch accuracy
| Accuracy | fold - 1 | fold - 2 | fold - 3 | fold - 4 | fold - 5 | fold - 6 |
|-|-|-|-|-|-|-|
| Session 1 | 0.8293 | 0.8104 | 0.8164 | 0.8089 | 0.808 | 0.8107 |
| Session 2 | 0.8353 | 0.8327 | 0.8208 | 0.8295 | 0.8231 | 0.8256 |
#### Our result (128 ms window length)

- Best mini batch accuracy
| Accuracy | fold - 1 | fold - 2 | fold - 3 | fold - 4 | fold - 5 | fold - 6 |
|-|-|-|-|-|-|-|
| Session 1 | 0.807 | 0.8054 | 0.7897 | 0.7854 | 0.8004 | 0.8121 |
| Session 2 | 0.8224 | 0.8212 | 0.8261 | 0.8199 | 0.8251 | 0.8204 |
### Confusion matrix
#### Original result in dataset source code (250 ms window length)

#### Our result (128 ms window length)

## Discussion
Both the original results and our results, the dataset of session 2 trains the better model.
From the confusion matrix, it can be found that some poses are not classified well, such as pose 11 and pose 19 in the original confusion matrix, and pose 16 and pose 8, pose 32 and pose 33 in our confusion matrix, which may be Because of the high similarity of these groups of actions, or the problem caused by our reduced spectral resolution. Overall, however, we achieve the same accuracy in pose prediction as the original experiment, and we use a shorter time window.
---

> Some of poses don't classify well, and they have a similar gesture
---
## Conclusion
#### Contribution
we **achieve the same accuracy in pose prediction as the original experiment, and we use a shorter time window**, this confirms the expected results of the literature, the high sampling rate of this data set allows us to retain the message characteristics in shorter signal segments to provide computer analysis, and proves that we can achieve faster under the same neural network model forecast speed.
#### Future Work
Try to improve the prediction accuracy of the model by changing the neural network architecture, a possible direction is to use the U-net of 3D CNN, because this can extract the features of multiple time periods at one time
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet