---
title: PDI1 - szkic
author: Michał Rokita
geometry: margin=3cm
lang: pl
date: \date{}
toc: true
...
\newpage
## Wstęp
Celem pracy jest stworzenie szkieletu aplikacyjnego pozwalającego na przetwarzanie w czasie rzeczywistym danych dotyczących zmian stanu obiektów, przystosowanego do obsługi danych lokalizacyjnych pojazdów na dużą skalę, oraz przykładu jego zastosowania.
Narzędzie będzie pozwalać na równoległe przetwarzanie danych oraz subskrybowanie do różnych reprezentacji danych wyjściowych.
Jako testowe zastosowanie zaimplementuję system przetwarzający archiwalne dane lokalizacyjne pojazdów komunikacji miejskiej m. st. Warszawy zebrane z miejskiego API[^apium], który będzie obliczał prędkość poszczególnych pojazdów, ostatni przystanek, na którym były oraz kurs, który realizowały.
Wspomniane dane archiwalne będą wprowadzane z użyciem programu symulującego wysyłanie raportów i traktowane jako aktualne - miejskie API nie aktualizuje raportów w czasie rzeczywistym.
Stworzę także aplikację internetową podobną do aplikacji pokazującej opóźnienia pojazdów komunikacji miejskiej, którą stworzyłem w ramach projektu na przedmiot Zaawansowane Programowanie w C++:

[^apium]: <https://api.um.warszawa.pl/files/9fae6f84-4c81-476e-8450-6755c8451ccf.pdf>
## Możliwe zastosowania rozwiązania
- Systemy diagnostyczne zbierające informacje o stanie technicznym pojazdów
- Systemy obliczające czas dojazdu pojazdów, np. dla korporacji taksówkarskich
- Systemy typu car-sharing
- Systemy obliczające opóźnienia pojazdów komunikacji miejskiej
- Systemy eco-driving badające spalanie pojazdów, np. w zależności od kierowcy
## Podstawowe pojęcia
- **Raport** - dane informujące o statusie pojazdu. Każdy raport zawiera unikalny identyfikator obiektu oraz czas wygenerowania.
- **Raport wejściowy** - raport spływający z pojazdu.
- **Pole sztuczne** - pole, którego nie ma w raporcie wejściowym, jest generowane przez system.
- **Reprezentacja raportu** - przetworzony raport, zawiera określone pola. Poza polami z raportu wejściowego może zawierać także pola generowane przez system.
- **Zależność** - pole, które jest wymagane do stworzenia pola sztucznego lub reprezentacji raportu.
- **Zależność archiwalna** - zależność, która jest wydobywana z archiwalnych raportów.
## Podstawowe funkcje szkieletu z perspektywy użytkownika
- Definiowanie raportów wejściowych z użyciem modeli pydantic[^pydantic].
- Definiowanie różnych reprezentacji raportów
- Definiowanie sposobu generowania pól sztucznych w raz z zależnościami - polami na podstawie których pola sztuczne będą generowane
- Sprawdzanie poprawności modelu na etapie ładowania programu
- Równoległe obliczanie pól sztucznych, które nie są od siebie zależne
## Wybrane technologie wraz z uzasadnieniem
Do wszystkich elementów poza aplikacją przeglądarkową, która będzie zaimplementowana w języku JavaScript, zamierzam wykorzystać język Python, ze względu na jego popularność i dostępność wielu świetnych narzędzi służących do tworzenia serwisów HTTP.
### Przykładowa implementacja
- WebSockets[^ws] - technologia kompatybilna z HTTP, pozwalająca na obustronną komunikację klient-serwer. W wypadku, gdy potrzebna jest komunikacja w czasie rzeczywistym, jest to dużo bardziej efektywne rozwiązanie niż long-polling.
- FastAPI[^fastapi] lub Starlette[^starlette] - backend HTTP. Obie technologie są do siebie bardzo podobne, ponieważ FastAPI bazuje na Starlette. Ich główną zaletą jest oparcie na technologii ASGI[^asgi], co pozwala na bezproblemową implementację punktów końcowych WebSocket.
- aioredis[^aioredis] - klient Redis kompatybilny z asyncio[^asyncio], dzięki czemu można go wykorzystać w aplikacji FastAPI/Starlette.
- React.js[^react] - prezentowanie danych na mapie w czasie rzeczywistym
[^asyncio]: <https://www.python.org/dev/peps/pep-3156/>
[^aioredis]: <https://aioredis.readthedocs.io/en/v1.3.0/>
[^fastapi]: <https://fastapi.tiangolo.com>
[^starlette]: <https://starlette.io>
[^react]: <https://reactjs.org>
[^ws]: <https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API>
[^asgi]: <https://asgi.readthedocs.io/en/latest/introduction.html>
### Framework
- Pydantic[^pydantic] - biblioteka pozwalająca na wydajną walidację oraz serializację i deserializację danych w formacie JSON.
- Redis[^redis] - baza danych NoSQL przechowująca dane w pamięci operacyjnej, przystosowana do tworzenia systemów czasu rzeczywistego z użyciem Redis Streams[^streams].
Rozważałem także wykorzystanie RabbitMQ[^rabbitmq] lub Apache Kafka[^kafka] i doszedłem do wniosku, że Redis będzie najlepszym rozwiązaniem - jest szybszy od obu tych rozwiązań (oba przechowują dane na dysku), a także prostszy, przez co daje użytkownikowi większą kontrolę. Oczywiście dzieje się to kosztem retencji, jednak gdybyśmy jej potrzebowali, wystarczy przesyłać przetworzone dane do innego serwisu, na przykład bazy danych SQL.
- walrus[^walrus]: klient Redis dla języka Python.
- asyncio[^asyncio]: wykonywanie funkcji obliczających pola sztuczne. Wykorzystanie asynchronicznego wejścia / wyjścia może dać tutaj duże korzyści, ponieważ w większości wypadków na czas wykonywania operacji największy wpływ będzie miało oczekiwanie na odpiowiedzi zewnętrznych usług.
[^kafka]: <https://kafka.apache.org/>
[^rabbitmq]: <https://www.rabbitmq.com/>
[^streams]: <https://redis.io/topics/streams-intro>
[^pydantic]: <https://pydantic-docs.helpmanual.io/>
[^redis]: <https://redis.io>
[^walrus]: <https://walrus.readthedocs.org>
### Testy i wdrożenie
- pytest[^pytest] - testy automatyczne
- locust[^locust] - testy wydajnościowe z użyciem archiwalnych danych ZTM
- Docker[^docker] + Docker Swarm[^docker swarm] - wdrożenie, testy skalowania wszerz.
- Traefik[^traefik] - routing, load balancing, backend uwierzytelniania.
[^pytest]: <https://pytest.org>
[^locust]: <https://locust.io>
[^traefik]: <https://docs.traefik.io>
[^docker]: <https://docker.com>
## Proponowana implementacja
### Definicja modelu
```python
import httpx
from pydantic import BaseModel
from datetime import datetime
from typing import Iterable
# Poniższe klasy jeszcze nie istnieją
from . import ReportRepresentation, ReportField, Dependency
# Report będzie klasą dziedziczącą z BaseModel
Report = BaseModel
class VehicleReport(Report):
vehicle_id: int
time: datetime
latitude: float
longitude: float
temperature: int
doors_open: bool
speed: float
class Config:
id_field = 'vehicle_id'
async def get_course_id(vehicle_id: int,
latitude: float,
longitude: float
) -> float:
...
async def get_stop_id(latitude: float, longitude: float) -> int:
async with httpx.Client() as client:
response = await client.get(
'/api/stops'
f'?lat={latitude}&lon={longitude}'
)
return await response.json()
class StopRepresentation(ReportRepresentation):
course_id: float = ReportField(
get_course_id,
Dependency('vehicle_id')
Dependency('latitude'),
Dependency('longitude'),
)
stop_id: Optional[int] = ReportField(
get_stop_id
Dependency('latitude'),
Dependency('longitude'),
# Jeśli w ciągu 5 sekund od zebrania wszystkich
# zależności nie uda się wygenerować pola,
# zostawiana jest wartość None.
timeout = 5.0
)
class Config:
report_model = Report
original_fields = ['vehicle_id', 'time']
```
\newpage
### Konsumenci i strumienie
Grupy konsumentów opisane w powyższym diagramie dzielą się na trzy rodzaje:
- Rozdzielacz (_Splitter_) (koło)
- Konsument zbierający zależności (_Dependency Resolver_) (koło)
- Konsument generujący pola sztuczne (_Producer_) (romb)
Każda grupa konsumentów będzie realizowana przez grupę procesów.
Strumienie są oznaczone prostokątnym obramowaniem.
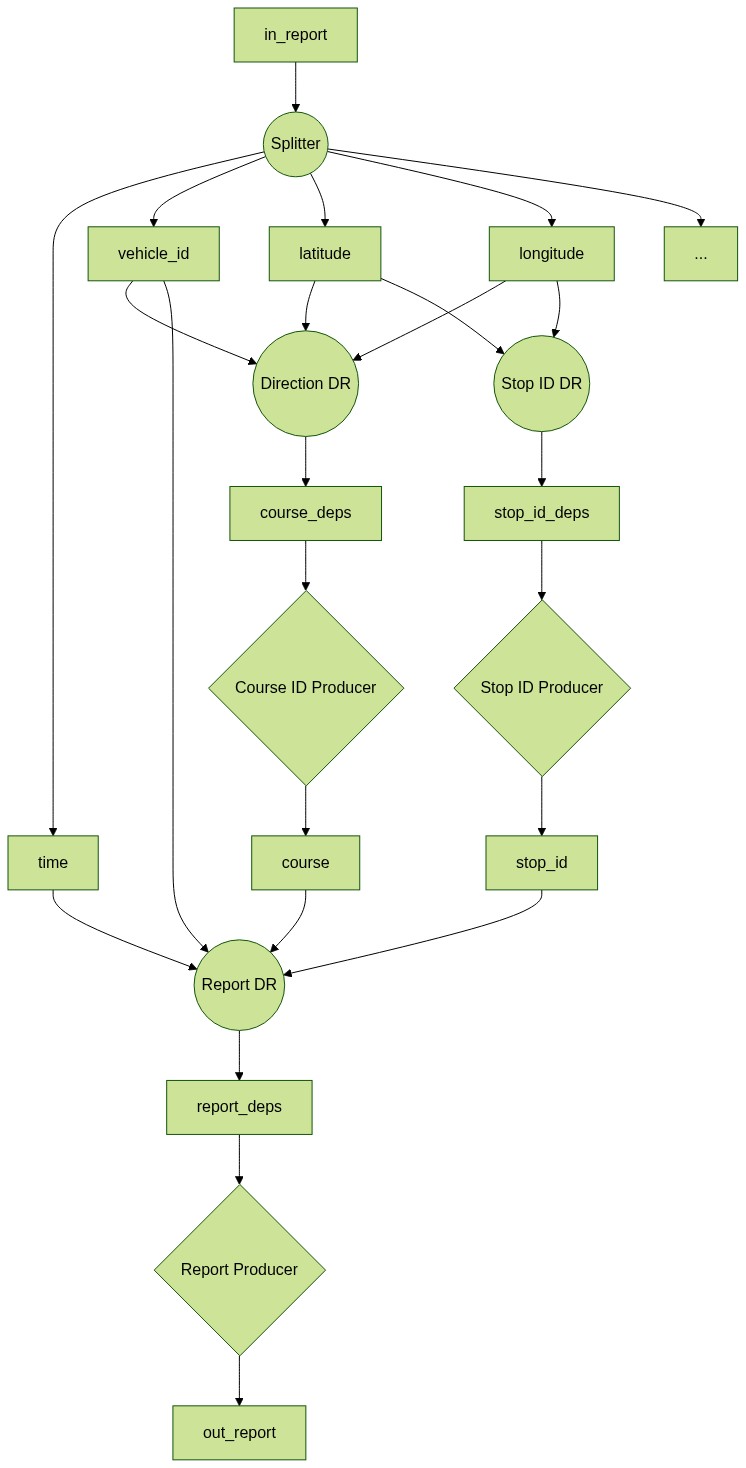{ height=70% }
\newpage
### Rozdzielacz
Głównym zadaniem rozdzielacza jest rozbicie danych ze
zawierającego raporty wejściowe na strumienie poszczególnych pól.
Każdy proces rozdzielacza, podobnie jak inni konsumenci, korzysta z polecenia `XREADGROUP`[^xreadgroup] z argumentem `STREAMS` o wartości `in_report`.
Każdy raport wejściowy jest najpierw deserializowany, po czym wartości jego poszczególnych pól wprowadzane są do odpowiednich strumieni z użyciem `XADD`[^xadd].
Aby umożliwić odpowiednie łączenie raportów przez konsumentów zbierających zależności, w każdym wywołaniu `XADD`, wiadomość poza wartością odpowiedniego pola, otrzumuje też pole `ID`, w formie `pojazd:nr_wiadomości_dla_pojazdu`, które będę określał _numerem wiadomości_.
Numer wiadomości dla pojazdu obliczany jest przez wywołanie polecenia `INCR`[^incr].
[^xreadgroup]: <https://redis.io/commands/xreadgroup>
[^xadd]: <https://redis.io/commands/xadd>
[^incr]: <https://redis.io/commands/incr>
### Konsument zbierający zależności
Konsument zbierający zależności także korzysta z `XREADGROUP`[^xreadgroup], jednak argument `STREAMS` przyjmuje wartość wszystkich zależności, które konsument zbiera.
Przy odebraniu wiadomości, wywołuje polecenie `HSET {nr_wiadomosci}_{nazwa_konsumenta_zbierajacego_zaleznosci} {pole} {wartość}`.
Następnie, z użyciem polecenia `HLEN`[^hlen], sprawdzana jest liczba spełnionych zależności dla danego `message_id`.
Jeśli wszystkie zależności zostały spełnione, zostają one pobrane za pomocą polecenia `HGETALL`[^hgetall] i przekazane do strumienia wyjściowego właściwego dla tego konsumenta, wraz z `message_id`.
### Zależności archiwalne
Dzięki możliwości obliczenia numeru następnej wiadomości, pola obliczane w poprzedniej wiadomości mogą być wprowadzane do odpowiedniego zbioru z wyprzedzeniem, z użyciem `HSET`[^hset].
Alternatywnym rozwiązaniem, ze względu utrzymenie stałej liczby wymaganych zależności, jest działanie odwrotne - pobieranie danych z poprzedniego raportu bezpośrednio po rozwiązaniu zależności.
> Należy pamiętać, że nie ma gwarancji, że dla danego pojazdu pojawiła się poprzednia wiadomość, w związku z czym obecność zależności z poprzednich raportów nie może być wymagana.
[^hgetall]: <https://redis.io/commands/hgetall>
[^hlen]: <https://redis.io/commands/hlen>
[^hset]: <https://redis.io/commands/hset>
### Konsument generujący pole sztuczne
Konsument generujący pola sztuczne czyta wiadomości generowane przez odpowiedniego konsumenta zbierającego zależności za pomocą `XREADGROUP` i wywołuje odpowiedni współprogram (_coroutine_), który oblicza wartość pola sztucznego i wprowadza ją do strumienia wyjściowego tego konsumenta.
### Konsument generujący reprezentację raportu
Działa w sposób analogiczny do konsumenta generującego pola sztuczne. Można także rozważyć dodanie większej liczby strumieni, dla różnych grup raportów - dotyczących konkretnego pojazdu, kategorii (autobus lub tramwaj), czy numeru linii, aby klient mógł wybrać, jakie go interesują.
### Wstępny plan pracy
- [ ] Podstawowy system zbierający dane, implementacja rozdzielacza i konsumenta generującego reprezentację raportu wraz z odpowiednim konsumentem zbierającym zależności
- [ ] Stworzenie archiwum raportów pozycyjnych pojazdów konunikacji miejskiej oraz narzędzia symulującego wysyłanie raportów w czasie rzeczywistym
- [ ] Konsument generujący pola sztuczne na podstawie pól raportu (bez pól sztucznych)
- [ ] Obsługa pól sztucznych jako zależności
- [ ] Implementacja mechanizmu ustawiania pustej wartości dla pola w wypadku przekroczenia maksymalnego dozwolonego czasu (_timeout_)
- [ ] Wizualizacja reprezentacji raportów na mapie
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet