# 0. wenet
> Production First and Production Ready End-to-End Speech Recognition Toolkit
- 以 wenet 為始的理由
- 開發簡單,有容易參考的 recipe,cf.:
- espnet: 環境很難 build (在研發雲),樣板很多但有點太多,
- k2(next-gen kaldi): 環境很難 build (在研發雲),門檻稍高
- speechbrain: research 取向
- nemo: 範例有點少
- fairseq/flashlight: 很 hardcore;都在解大問題
- 
- 社群接近
- 有比較多 runtime support 可以參考
- (2021 interspeech) WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
- Production first and production ready (JIT)
- Unified solution for streaming and non-streaming ASR (U2)
- Portable runtime
- light weight
- (2022 interspeech) WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit
- U2++
- Production language model solution
- Context biasing
- Unified IO (UIO)
# 1. ASR: review
## 1.1 Some seq2seq models
- 大類
1. Transformer
2. CTC
3. RNN-t
4. Neural transducer
- some references
- https://speech.ee.ntu.edu.tw/~tlkagk/courses/DLHLP20/ASR%20(v12).pdf
- https://lorenlugosch.github.io/posts/2020/11/transducer/
- https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/intro.
- https://www.youtube.com/watch?v=N6aRv06iv2g&t=15s&ab_channel=Hung-yiLee
### 1.1.1 Attention model
- (2016 icassp) "Listen, Attend and Spell" Chan, et al.
- 
- https://github.com/Alexander-H-Liu/End-to-end-ASR-Pytorch/blob/master/tests/sample_data/demo.png
<!-- #### 1.1.1.1 Listen

#### 1.1.1.2 Attention

#### 1.1.1.3 Spell
 -->
### 1.1.2 CTC model
- (2006 icml) "Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks". Alex Graves, et al.
#### 1.1.2.1 CTC

#### 1.1.2.2 CTC prediction

### 1.1.3 Transducer model
- (2012 icml) "Sequence Transduction with Recurrent Neural Networks". Alex Graves, et al.
- (2016 nips) "A Neural Transducer". Navdeep Jaitly, et al.
#### 1.1.3.1 RNN transducer

#### 1.1.3.2 Neural transducer

### 1.1.4 比較

- 優劣分析
- attention: 可看到完整上下文;無法 offline;長音檔attention 耗費 memory (O(TU));較難收斂
- CTC: 架構簡單;有 len(T)>len(U) 的假設;假設每個 frame 獨立不太合理
- transducers: 架構天生可以解決 CTC 的 frame 間獨立的假設與 attention 要看上下文無法 online 的問題;訓練更耗費 memory (O(BTUV))
## 1.2 streaming vs non-streaming
- streaming: 對整段聲音訊號進行辨識
- non-streaming: 一邊看訊號一邊辨識
# 2. e2e ASR: wenet
- model architecture
- decoding
- unified model
- language model
- contextual biasing
- UIO
- runtime
## 2.1 model architecture
- shared encoder:
- transformer
- conformer
- decoder:
- ctc
- transformer
- rnn-t
- 主要使用 joint CTC/AED 架構,加速與穩定訓練
### 2.1.1 joint CTC/attention training
- (2017 icassp) JOINT CTC-ATTENTION BASED END-TO-END SPEECH RECOGNITION USING MULTI-TASK LEARNING
- shared encoder 可使用基本的 transformer 或 conformer
- architecture of joint CTC/AED
- 
- loss of joint CTC/AED
- 
### 2.2 decoding
- modes:
- attention: transformer decode
- ctc_greedy_search: ctc 1best
- ctc_prefix_beam_search: 對 ctc 結果進行 beam search
- attention_rescoring: 根據 ctc prefix beam search 結果與 encoder output 做 attention rescoring
- rnn-t
- 可用 causal convolution 減少 right context dependency
### 2.3 U2 model
- U: unify streaming and non-streaming training,達到一個模型可以應用在 streaming 與 non streaming。dynamic chunk training:
- > We adopt a dynamic chunk training technique to unify the non-streaming and streaming model. Firstly, the input is split into several chunks by a fixed chunk size C with inputs [t + 1, t + 2, ..., t + C ] and every chunk attends on itself and all the previous chunk"
- 透過調整 chunk size 調整 latency,當 chunk size = 1 時為純 streaming;chunk size 不設定則等價於 non streaming
- 
- 藉由調整 chunk size 取得速度與準確度的平衡
- chunk size = -1 : non streaming
- chunk size = 4/8/16 : streaming
- 
#### 2.3.1 U2++
- decoder 改成雙向 attention
- 
- 
### 2.4 Language model
- ngram for fast domain adaption
- 有 in-domain training data 的話
- cf. rnn-t lm
- decoding graph: TLG
- cf. kaldi HCLG
- 
- 
### 2.5 Contexual biasing
- much faster domain adaption
- 提升特定名詞辨識率
- on the fly WFST
- w/o LM: 把 phrase list 分解成 decoder output units
- w/ LM: 把 phrase list 分解成 LM 的 vocabulary
- 
- 
### 2.6 UIO
- Unified IO
- 克服 production level training data 存取問題
- random access x 1000000+小檔案index = OOM
- 就算沒 oom 也很慢
- 通用 IO 介面,後端可為 local file system 或 cloud (S3/OSS/HDFS/...)
- 把所有檔案 load 完連同 metadata 包成 shards
- which is actually done by gnu tar
- 開發環境需要足夠的空間存 shard
- on the fly feature extraction
- 
- 
### 2.7 runtime
- system design:
- 
- 提供多種程度之支援
- 支援之 architecture: arm(andrdoid) / intel x86
- library
- 支援之 runtime platform: onnx / libtorch
- model
- 支援之語言: python/c++
- python: wenetruntime
- i.e. pip install wenetruntime
- 提供多個範例
- python
- command line
- websocket (python/c++)
### 2.7.1 quantization performance
- 
### 2.7.2 runtime rtf
- 
### 2.7.3 runtime latency
- 
- L1: model latency, waiting time introduced by model structure
- L2: rescoring latency, time spent on attention rescoring
- L3: final latency, user perceived latency
- L3 部分來自於 L2
## 2.8 conclusion
- 使用 joint CTC/AED 架構,提升速度與準確度
- 使用 dynamic chunk training,達到一個模型可以同時進行 streaming 與 non-streaming
- 提供多種 runtime 方案供使用與參考
- 提供 LM 與 context bias 等可快速處理 production ASR domain adaption 議題的方案
- 提供 UIO 解決大量資料訓練時可能產生的問題
# 3. others
## 3.1 furure works: wenet 3.0
- 
## 3.2 其他功能
- tts
- speaker
- kws
# 4. wenet in esun
|model|MER(att_res)|
|:--:|:--:|
|cnn-tdnnf| 11.32 |
|cnn-tdnnf-a-lstm| 10.97 |
|conformer CTC/AED| 9.83 |
|conformer CTC/AED U2++| 10.34 |
- training 語料未完全對齊
- training epoch 時間 (v100 16GB * 8)
- conformer ctc/aed: ~45 min
- u2++: ~55 min
# 5. 會後 qa
#### Q: dynamic chunk training 的 label?
A:
參考 http://placebokkk.github.io/wenet/2021/06/04/asr-wenet-nn-1.html#chunk-based-mask:
中的:第3節-問題3,conformer ctc/aed 的 attention 有:
1. encoder 中的 self attention
2. decoder 中的 self attention
3. encoder 與 decoder 間的 cross attention
dynamic chunk 是針對 encoder 中的 self attention 進行。
主要可以參考連結中的圖:
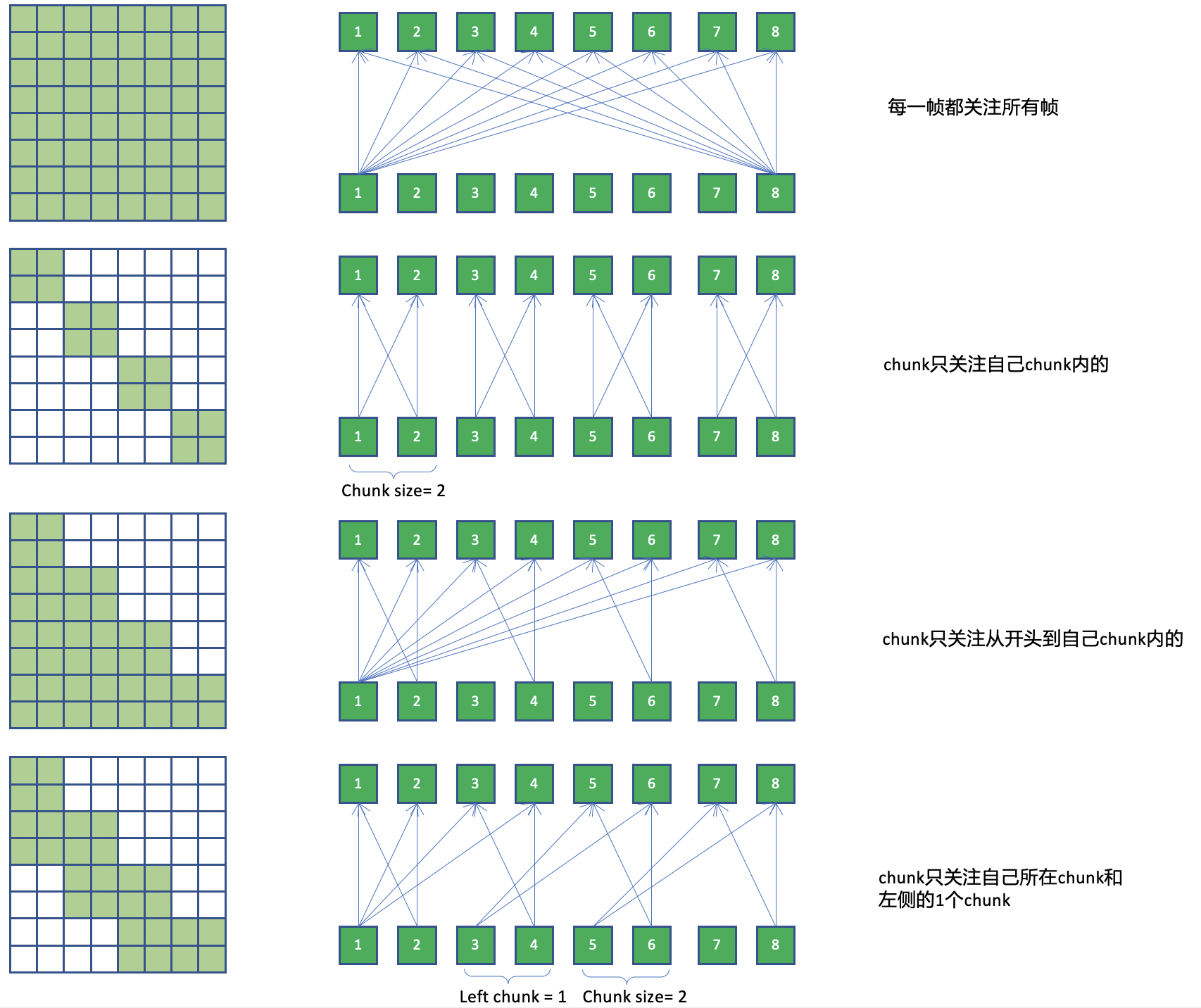
dynamic chunk 為 2,3,4 列。以圖片中 8 個 input 為例:
1. 如果是第一列 full attention,每個時間點都會看到所有 input 計算 attention,i.e.
- encoder t1 的 output 會看過 t1~t8
- encoder t2 的 output 會看過 t2~t8
- encoder t5 的 output 會看過 t1~t8
- encoder t8 的 output 會看過 t1~t8
2. 如果是第二列 chunk based attention,每個時間點只看 chunk 內的 input,i.e.
- encoder t1 的 output 會看過 t1~t2
- encoder t2 的 output 會看過 t1~t2
- encoder t5 的 output 會看過 t5~t6
- encoder t8 的 output 會看過 t7~t8
第三列的不看 right context 與第四列只看 limited left context 道理亦同。
#### Q: context bais 發生的時間點?是對 embedding 嗎?
#### Q: chunk size 跟 latency 的關係?