# 技術簡答題
###### tags:`面試`
## 請找出三個課程裡面沒提到的 HTML 標籤並一一說明作用。
1. `<figure>`:用於包裝一段獨立的內容,經常與`<figcaption>`一起使用,`<figcaption>`則用與當前內容相關的說明或標題,所以通常放置在`<figure>`區塊內的第一行或最後一行
2. `<datalist>`:可表現出下拉式選單的樣式,常與`<input>`搭配使用,內含了多個`<option>`元素(選項)
3. `<blockquote>`:引用其他出處的內容,可以使用`cite`標明出處的 url
## 請問什麼是盒模型(box modal)
<details>
是 html 用於空間定位的模型,分別區分成以幾種區塊
* `content`:內容通常以文字或圖片為主,區塊大小則是以 width、height 所控制
* `padding`:區塊範圍為 content 到 border 之間(內距)
* `border`:邊寬,可透過
* `margin`:區塊範圍為 border區塊範圍為 border 之外的範圍,明確範圍可透過 css 設定
</details>
### box-sizing 屬性
1. content-box:為預設值,在這種模式下更改`padding`、`border`、`margin`時,都是以維持`content`原有尺寸大小的情形下做更動,也就是說區塊是向外長的
2. border-box:這種模式下則是以維持`border`原有尺寸大小的情形下做更動,不管是更改`padding`、`border`,都會維持`border`原有的寬度,也就是說區塊是向內壓縮的
## 請問 display: inline, block 跟 inline-block 的差別是什麼?
* `inline`:這種屬性的元素可以與其他元素相排列,需要注意的是不管我們調多少寬高都不會有變動,主要還是以內容為主,再來最常搞混的地方就是更改`padding`、`margin`時的狀況,在調整 padding 時候,左右的 padding 是有作用的(會影響其他元素的),但上下的 padding 則不會有作用(padding 的區塊有延伸出去,但不會影響其他元素,自身的 content 也不會跟著移動),而 margin 則是只有在調整左右 margin 才會變動,可以想像成在`inline`時都是以**行**為主來做調整
* `block`:不管是調整`padding`、`margin`都會有作用,比較需要注意的則是`block`屬性下的元素都會獨自佔滿一行,所以在排列方式則是會不斷地換行,向下排列
* `inline-block`:同時擁有`inline`和`block`的優點,能夠能夠像 inline 一樣,與其他元素並排,又能像 block 一樣調整 padding、margin,不過在這種屬性下有個小陷阱,那就是空白字元,常常會在 html 換行的空白處發現它,解決方式有很多種,我的話通常是將它註解調或從字元下手
## 請問 position: static, relative, absolute 跟 fixed 的差別是什麼?
* `static`:為預設值,正常的排版流(按照元素的先後順序),無法利用 top、left、bottom、right 調整元素位置
* `relative`:為相對定位,是以元素**原本的位置**作為定位點來位移,可以利用 top、left、bottom、right 調整元素位置,而且不會影響(推擠)相鄰的元素,而是以推疊的方式覆蓋在其他元素上
* `absolute`:為絕對定位,會跳脫原本的排版流,後面的元素會自動遞補指定元素原本的空間,而被指定的元素則會向上層尋找 position 屬性不是 static 的元素作為定位點,若沒找到就會把 body 當作定位點,一樣可以利用 top、left、bottom、right 調整元素位置,也不會影響(推擠)相鄰的元素,而是以推疊的方式覆蓋在其他元素上
* `fixed`:類似絕對定位,會跳脫原本的排版流,後面的元素會自動遞補指定元素原本的空間,在不以 top、left、bottom、right 調整元素位置時,元素會停留在原本排序的位置,在調整後,元素則是以 viewport 作為定位點進行位移,不會因為滑動頁面造成元素移動,這種模式同樣不會影響(推擠)相鄰的元素,而是以堆疊的方式覆蓋在其他元素上
## 什麼是 DOM?
DOM 全命為(Document Object Model),是瀏覽器所提供的一種介面,它就像是樹狀圖一樣,對應到 html 文件內的的結構關係,我們可以透過 DOM 使用 JS 存取 html 內的屬性及樣式,就像是我們在使用 js 取得 object 內的元素一樣,只是在這裡的 object 變成了 html 文件,最值得一提的是我們不只能夠存取,甚至還能監聽事件,在符合特定條件下,觸發我們所給予的行為
## 事件傳遞機制的順序是什麼;什麼是冒泡,什麼又是捕獲?
事件傳遞分為三個階段,首先是捕獲階段,次要為目標階段,最後是冒泡階段,這就像是小時候練習折返跑一樣,target 可以想像成地板上的三角錐,而我們跑向三角錐的過程就是捕獲階段,在到達三角錐觸地的那一刻就是目標階段,在返回原點的過程就是冒泡階段,不管 target 在哪,事件傳遞機制都會先捕獲,在冒泡,就像折返跑一樣,必須要到達三角錐,才能返回原點,而我們也正是透過這樣的特性,對事件進行監聽的,利用 eventlistner 套用在指定元素,再對其操控特定觸發條件以及預期行為
## 什麼是 event delegation,為什麼我們需要它?
就如同上述所形容的,不管 target 在哪,我們終究還是會反為原點,與其對每個元素添加 eventlistner,那不如就利用冒泡階段的特性,直接在根節點套用 eventlistner 就好了,這種指定一個根節點,就可以管理底下子節點的方式,就稱為event delegation,好處不只是能省下要對所有元素添加 eventlistner 的麻煩,還能夠同時監聽動態產生的新節點,這樣就不必再特地對新節點一一套用 eventlistner 了
## event.preventDefault() 跟 event.stopPropagation() 差在哪裡,可以舉個範例嗎?
event.preventDefault() :阻止預設的行為,如果放在超連結或是提交按鈕上,就會阻止開啟超連結及提交表單的行為
event.stopPropagation():阻止事件傳遞給下一節點,位於同層的節點依舊會被傳遞
event.stopImmediatePropagation():立刻阻止事件傳遞,位於同層的其他節點也會被阻止
preventDefault 阻止的是**行為**,而 stopPropagation 阻止的是**事件傳遞**,這邊特別提一下,如果在根節點(不管是捕獲還是冒泡階段)加上 preventDefault,之後,這個效果也會被傳遞下去,所以在子節點中的預設行為同樣也會被阻止
## 什麼是 Ajax?
Ajax 全名為「Asynchronous JavaScript and XML」,重點是 Asynchronous(**非同步**)
以發送 request 來說,同步的狀態下必須在等待接收完 response 後,才能執行下一段程式碼,而非同步則是在發送 request 後,不需等 response 回傳,就馬上執行下一段程式碼
Ajax 是利用 JS 透過瀏覽器發送 request 給 server,接收到 response 後再經由瀏覽器轉傳給 JS,之後我們就可以將收到的資料,按照自己想呈現的內容及方式,新增在網頁上
## 用 Ajax 與我們用表單送出資料的差別在哪?
利用表單的方式發送資料,在瀏覽器接收到 response 之後,就會馬上 render 出返回的 html 文件,相對於表單接收資料後呈現的方式,Ajax 在接收資料後,更能客製化的呈現瀏覽器上的結果
儘管兩者接收的資料一樣,相對於每次返回都要重新刷新一次頁面,透過 Ajax 這種刷新部分資料的方式,不但能減少資源的佔用,也能有更好的使用者體驗
## JSONP 是什麼?
基於安全性的考量,瀏覽器中有個名為「同源政策(Same Origin Policy)」的規範,如果並非處於同個 domain 之下,瀏覽器就不會將返回的 response 給我們
但我們總是需要串聯別人的 API,於是有人將腦筋動到了 html 的標籤,例如`script`、`img`,透過這種不被同源政策限制的特性,以一個 function 的形式,將資料塞進裡面,之後再命名一個同名的 function 名稱,就可以順利呼叫所需的資料了,不過缺點就是你要帶過去的參數,永遠都只能用附加在網址上的方式(GET)帶過去,沒辦法用 POST
例如:
```html
<script src="https://json.com">
<!--網址返回的資料如下
getData({
data: 'test'
})-->
</script>
<script>
function getData (response) {
console.log(response);
}
</script>
```
## 要如何存取跨網域的 API?
除了 JSONP 之外,要在不同 domain 中交換資料,還可以透過 「跨來源資源共享(Cross-Origin Resource Sharing,CORS)」這項規範,server 必須在 response header 加上 `Access-Control-Allow-Origin`,當瀏覽器收到 response 後,會先檢查 `Access-Control-Allow-Origin` 內的內容,如果裡面有包含發起這個 request 的 origin 的話,才會讓我們接收這個 response
除了`Access-Control-Allow-Origin`之外,其實還可以自定義接收那些 method、header
## 為什麼我們在第四週時沒碰到跨網域的問題,這週卻碰到了?
上述所提到的「跨來源資源共享」、「同源政策」,都是瀏覽器上的規範,也就是說在交換資料的過程中,如果當中有瀏覽器參與才會有這些問題,而第四週是透過 node.js 交換資料,並沒有瀏覽器參與,自然就沒有所謂跨網域的問題了
透過瀏覽器交換資料就像是我們在網路上購物(發 request),物流業者將貨物運送到便利商店(瀏覽器接收到 response),我們到超商取貨之後,再比對你的手機末 3 碼(確認 request 的來源),確認之後再給你商品(瀏覽器再給我們 response),如果你是用 node.js 就會像是我們選擇宅配的方式(發 request),物流業者直接將貨物送達你家(server 直接給我們 response),中間就不會再經過便利商店(瀏覽器)替你取貨了
## 資料庫欄位型態 VARCHAR 跟 TEXT 的差別是什麼
1. varchar 可以設定該欄位的字元長度,適用在已知欄位內會大概填入多少字元時使用
2. text 則是不可設定欄位的字元長度,適用在文字量多或不知道會填寫多少字時使用的欄位
總的來說,適當的使用 varchar 可以節省空間,在查詢速度上也會比較快,但如果不能預計欄位內會填入多少字元,使用 text 也是可以的
## Cookie 是什麼?在 HTTP 這一層要怎麼設定 Cookie,瀏覽器又是怎麼把 Cookie 帶去 Server 的?
cookie 就是儲存在瀏覽器內的小型文字檔(容量有限),在 http 這層 server 可以透過`Set-Cookie`這個 response header 來讓瀏覽器儲存相對應的 cookie,當瀏覽器發送 request 的同時,也會將相對應的 cookie 放在`Cookie`這個 request header 裡面,server 就可以依據 cookie 的資訊來判斷使用者的狀態
所以說 cookie 最主要的功用就是在儲存資料,而這些資訊基於資安的關係,也有被限制一些條件,只有符合條件的資訊才寫入及傳送
## 我們本週實作的會員系統,你能夠想到什麼潛在的問題嗎?
1. 在資料庫內的會員密碼是以明碼的方式被儲存,如果資料庫被駭,密碼就會一覽無遺
2. 由於 cookie 在瀏覽器上是可以直接被瀏覽及更改的,所以對有心人士來說是可以偽造他人身分的
## 請說明雜湊跟加密的差別在哪裡,為什麼密碼要雜湊過後才存入資料庫
### `雜湊`
特性:
* 將不定長度的輸入透過雜湊演算法,會輸出一段長度固定的雜湊值
* 同樣輸入,必定得到同樣輸出,但不同的輸入,也可能得到同樣的輸出,這種情況稱作「碰撞」
常見演算法:
* SHA 系列
* MD 系列
### `加密`
特性:
* 加密後的密文是可以透過密鑰來解密的
* 加密又分為「 對稱式加密 」、「 非對稱式加密 」
對稱式加密:
* 密鑰要是太簡單或長度太短,安全性以及在實際應用上不夠理想,所以出現安全性更高,應用範圍更廣的非對稱式加密
* 常見演算法: DES、3DES、AES
非對稱式加密:
* 非對稱式加密演算法會有兩把鑰匙,一把稱做公鑰,另一把稱做私鑰
* 非對稱式加密除了可以加密以外,還可以生成數位簽章,確認密文的傳送方身份真的是本人
* 常見演算法:RSA、DSA、ECC
雜湊與加密最大的差別在於,雜湊是不可逆的,而加密可逆,會將使用者的密碼先經過雜湊再存入資料庫,是為了防止資料庫不慎外洩後,攻擊者無法直接看到明碼
## `include`、`require`、`include_once`、`require_once` 的差別
### `include`
* 適合用來引入**動態**的程式碼
* 執行時,如果 include 進來的檔案發生錯誤的話,會顯示警告,不會立刻停止
* 可以用在迴圈
### `require`
* 適合用來引入**靜態**的內容
* 執行時,如果 require 進來的檔案發生錯誤會顯示錯誤,立刻終止程式,不再往下執行。
* 不可以用在迴圈
#### `include_once`與`require_once`
功能上與 include、require 一樣,比較不一樣的地方在於引入檔案前,會先檢查檔案是否已經在其他地方被引入過了,若有,就不會再重複引入。
## 請說明 SQL Injection 的攻擊原理以及防範方法
SQL Injection 的攻擊原理是攻擊者輸入我們非預期的字串,而這些字串會進而執行 SQL 的指令,透過這種方式來獲取資料庫的資訊,為了防止使用者輸入的字串被當成程式碼的一部份,我們可以透過 prepare statement,使這些字串跳脫字元
## 請說明 XSS 的攻擊原理以及防範方法
XSS 的攻擊原理也是攻擊者輸入我們非預期的字串進行攻擊,不過攻擊的語法則是以 HTML、JS 為主,在網頁顯示其資訊時,進而執行所預期的行為,為了防止使用者輸入的字串被當成程式碼的一部份,我們可以透過 htmlspecialchars,使這些字串跳脫字元,不管是 SQL Injection 還是 XSS,大原則就是只要是使用者可以自行控制的輸入內容,都要確保內容無法被當作程式碼的一部份,才能防止發生非預期的事件
## 請說明 CSRF 的攻擊原理以及防範方法
CSRF 的攻擊原理是利用瀏覽器自動帶上使用者 cookie 的機制,透過導向連結在使用者渾然不知得情況下,以你的身分執行目標網站的操作
防範方法:
* client 端:在每次使用完網站後,進行登出,就可以避免 CSRF
* server 端:
* `檢查 Referer`:request 的 header 裡面會帶一個欄位叫做 referer,可以檢視這個 request 是來自哪個 domain,如果不是合法的 domain,就 reject 掉,不過並不是所有瀏覽器都會帶 referer,就算瀏覽器有帶,使用者也可以關閉自動帶 referer 的功能,這就會導致真的使用者發出的 request 都被 reject 掉,再來就是要保證判定是不是合法 domain 的程式碼必須沒有 bug,否則還是可以繞過這項限制
* `加上驗證碼`:由於驗證碼只有使用者會收到,所以攻擊者就不可能攻擊了,但如果每次的操作都需驗證,對於使用者來說,這樣的體驗並不是很好
* `加上 CSRF token`:在 form 裡面加上一個 hidden 的欄位,name 為 `csrftoken`,值為 server 隨機產生,並存在 server 的 session 中,在 submit 後,透過比對表單中的 csrftoken 與 session 內的值是否一致,藉此判斷是否為本人所發送的 request
* `Double Submit Cookie`:同樣由 server 產生隨機的 token 值,一樣在表單放 csrftoken,但不存在 session 中,而是存在 client 端的 cookie 裡,由於瀏覽器的限制,攻擊者沒辦法讀寫目標網站的 cookie,所以 request 的 csrftoken 會跟 cookie 內的不一樣,所以他發上來的 request 的 cookie 裡面就沒有 csrftoken,就會被擋下來
* `Client 端生成的 Double Submit Cookie`:這個方法則是由 client 端產生隨機的 token 值,並存放在 form 與 cookie 中,因為 token 本身的目的其實不包含任何資訊,只是為了不讓攻擊者猜出而已,所以由 client 還是由 server 來生成都是一樣的,只要確保不被猜出來即可
* `browser 本身的防禦 - SameSite cookie `:原理就是幫 Cookie 再加上一層驗證,不允許跨站請求,除了我自己的網域,其他任何來自不同網域的 request 都不會帶上 cookie
只要在設置 cookie 時加上 SameSite ,如下
```
Set-Cookie: session_id=<id>; SameSite
```
SameSite 分為兩種模式,「Strict」、「Lax」
* `Strict`:默認值,不論是`<a href="">`、`<form>`、`new XMLHttpRequest`,只要是瀏覽器驗證不是在同一個 site 底下發出的 request,全部都不會帶上這個 cookie
* `Lax`:Lax 模式則是放寬了一些限制,例如說`<a>`、`<link rel="prerender">`、`<form method="GET">`這些都還是會帶上 cookie,但是 POST 方法 的 form,或是只要是 POST, PUT, DELETE 這些方法,就不會帶上 cookie,需要特別注意的是,Lax 模式之下就沒辦法擋掉 GET 形式的 CSRF
## 請簡單解釋什麼是 Single Page Application
又稱為「單頁面應用程式,SPA」,SPA 是透過 Ajax 的方法串接 API 來存取資料,按照我們想呈現的內容及方式,透過 JS 在 client 端就能動態新增資料,而這些交換資料的過程完全都是在單一頁面完成
## SPA 的優缺點為何
優點:
透過這種動態新增資料的方式,只需要刷新頁面部分資料即可,相對 Multi-page Application(多頁應用程式,MPA)每次交換資料都要重新刷新頁面的方式,不但能減少 server 資源的占用,也能有更好的使用者體驗,而且 SPA 也讓前端和後端在職責的分工上更加明確,後端負責產生計算資料,前端負責頁面的呈現
缺點:
由於 SPA 是將所有資料都放在頁面再透過 JS 動態新增,而非 server 處理過後再回傳 HTML 檔,所以在未添加資料的情況下,原始碼通常都不會有什麼內容,這也意味著網頁較難透過 SEO 優化,而且在過程中都在同個網址,因此必須自訂狀態來判斷資料的傳輸是否成功或失敗,SPA 的處理過程都是在 client 端執行,如果抓取的資料量多的話,在首次載入頁面的速度有可能會比較慢
## 這週這種後端負責提供只輸出資料的 API,前端一律都用 Ajax 串接的寫法,跟之前透過 PHP 直接輸出內容的留言板有什麼不同?
PHP:
server 在收到瀏覽器發出的 request 之後會在 server 端處理相對應的 php 檔,之後再將處理完後的結果(包含狀態管理、路由控制、完整的 HTML 檔)回傳給瀏覽器渲染出來,每次的渲染都會刷新一次頁面
Ajax:
SPA 則是透過 Ajax 發送 request 給 server,server 回傳資料以後,client 端再透過 JS 將資料添加上去並 render 出來,因為是動態新增資料,只需要刷新頁面部分資料即可,這種模式下後端就只要負責輸出資料,前端負責抓資料和渲染畫面,就算你後端壞掉,你前端還是看得到畫面(只是可能會顯示個錯誤畫面之類的);你前端壞掉,後端還是能安穩的輸出資料供其他服務使用
## Webpack 是做什麼用的?可以不用它嗎?
webpack 是用來將模組打包的工具,它可以將許多分散的模組按照依賴關係和規則打包整合成一個或多個模組,而 webpack 最厲害的地方就在於它打包的資源不只是限於 JS,甚至能打包 CSS、圖片、第三方模組,通過 webpack 提供的 loaders 還能在打包的過程中順便轉譯、壓縮,經過處理就能輕易的在瀏覽器上引入打包後的模組,當然你也可以不使用 webpack,不過上述所提到的的程序都必須使用其他工具做整合,但在檔案相容性及維護性的部分可能就不如使用 webpack 方便了
## gulp 跟 webpack 有什麼不一樣?
gulp 的主要功能是開發流程的**控制管理**,我們可以通過 gulp 提供的各種 plugin 配置不同的 task,然後再定義執行順序,進而去構建整個開發流程
webpack 則是注重在**打包模組**的功能,透過 loader 和 plugin 把開發時的各種資源進行轉化,在按照依賴關係和規則進而打包成符合開發環境的前端資源
## CSS Selector 權重的計算方式為何?
從權重高排到低:
1. !important
2. inline style
3. ID
4. Class
5. Elements
[參考資料](https://muki.tw/tech/css-specificity-document/)
## 什麼是 DNS?Google 有提供的公開的 DNS,對 Google 的好處以及對一般大眾的好處是什麼?
對於電腦來說要造訪一個網站,其實都是透過 IP 位置連接該網站伺服器,但眾所皆知 IP 就是一串數字所組成,這種沒什麼特殊涵義的數字,真的不是那麼好記,這就像你向朋友打招呼一樣,你會說出他的名字還是說出他的身分字號一樣。為了更利於記憶,所以我們會輸入網址來代替,而 DNS 就是幫我們將網址名稱轉換為 IP 的工具,通常在沒有特別指定 DNS 的情況下,預設都會是 ISP 提供的 DNS,當然也可以自訂
提供免費的 DNS 對於 Google 來說的好處,不外乎是為了蒐集使用者的數據、分析使用者行為,再依據數據進而提供其他更精確的服務,對用戶來說,由於 Google 掌握了相對更完整的數據,而且伺服器也遍布各地,所以在轉換上也會相對快速且穩定
## 什麼是資料庫的 lock?為什麼我們需要 lock?
當我們對同一筆資料同時進行多項操作時,由於沒辦法確保處理的先後順序,為了維持資料的完整性,以及防止造成 Race condition 的情況,我們可以在 transaction 中加入 lock,透過 lock 暫時鎖住指定欄位,使其依序處理,但也因為 lock 的特性,在後續的操作需要等待所以就會造成效能上的損耗
## NoSQL 跟 SQL 的差別在哪裡?
* SQL 在儲存上資料前,必須事先定義好 schema 才能儲存資料(嚴謹),NoSQL 則是以 key-value 的方式存資料,比較沒有一定的對應關係(寬鬆)
* SQL 可以透過 SQL 語法查詢資料(CRUD),NoSQL 通常是使用簡單的 API 來存取資料
* SQL 的查詢中提供了 JOIN 的語法,可以一次關聯多張 table 的相關資料,NoSQL 則是把相關的資料一次包進去
* SQL 在 transaction 設計中的特性為 ACID(Atomicity、Consistency、Isolation、Durability),較能確保資料的完整性,NoSQL資料庫大多沒有 transaction 的設計,而是採用了另外一個不同的 CAP(Consistency、Availability、Partition Tolerance)資料庫理論,理論上無法同時兼顧 CAP 這三種特性,NoSQL 資料庫通常會選擇其中兩種特性來設計,大多是 CP 或 AP
## 資料庫的 ACID 是什麼?
在資料庫進行 transaction 的操作時,為了確保資料的完整性,必須符合 ACID 這四項特性
* Atomicity(原子性)
每一筆 transaction 不是全部成功、就是全部失敗,如果發生錯誤就 rollback 當作什麼事都發生過
* Consistency(一致性)
在交易前後依舊維持資料的一致性,舉例來說:A 有 100 元,B 有 100 元,不管他們交易金額怎麼變動,最後兩人的金額加起來一定還是 200
* Isolation(隔離性)
在每一筆 transaction commit 之前,都不會執行另一筆 transaction,透過這種排序的方式,確保資料的完整性
* Durability(持續性)
交易完成後對資料的修改是永久的,資料不會因為系統重啟或錯誤而消失。
## hw1:Event Loop
```js
console.log(1)
setTimeout(() => {
console.log(2)
}, 0)
console.log(3)
setTimeout(() => {
console.log(4)
}, 0)
console.log(5)
```
## 執行流程
講解前先附上一 Event Loop 的流程圖比較容易理解一點
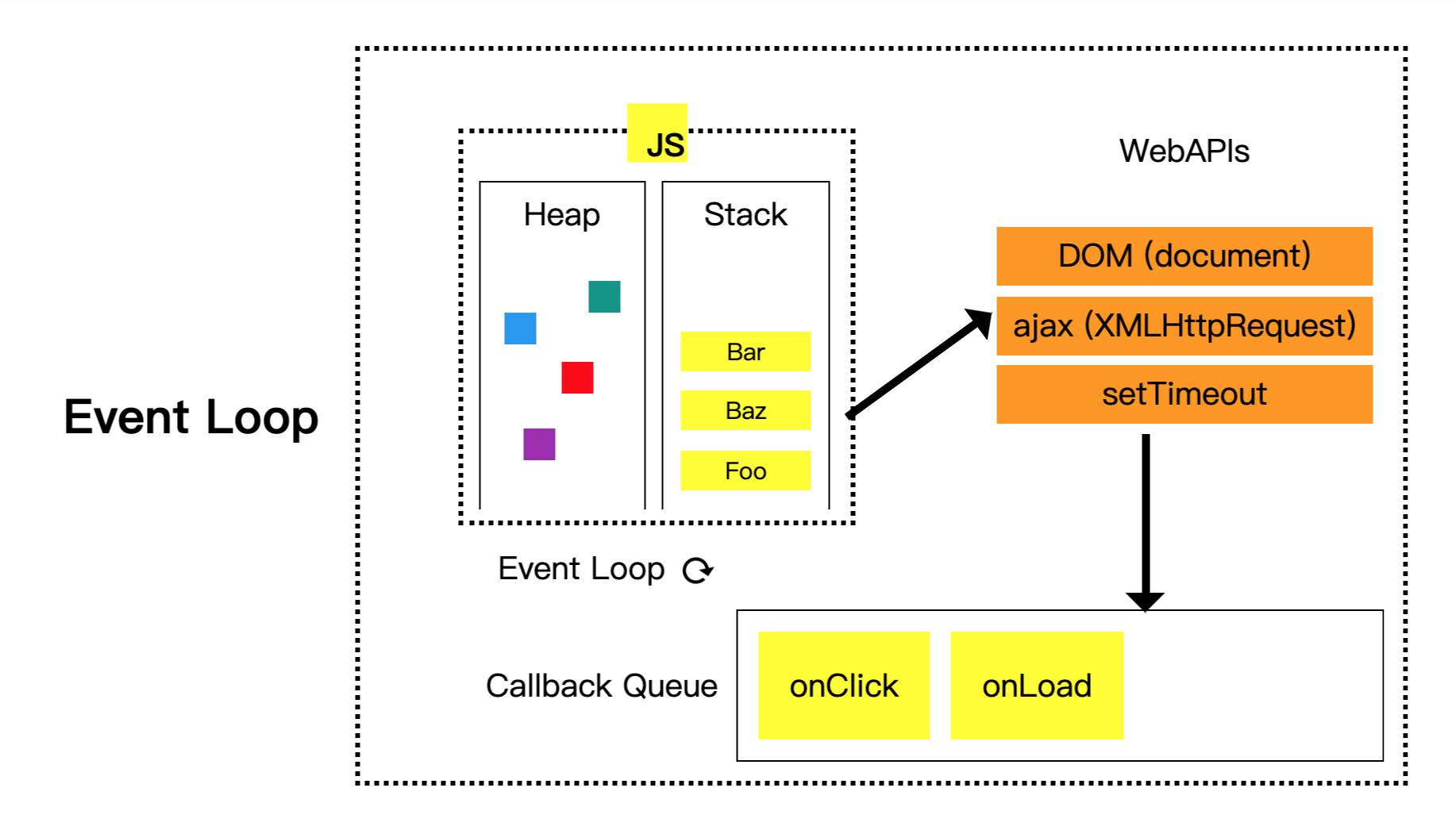
1. 將`console.log(1)`放入 call stack 執行,輸出 1
2. 將`setTimeout(() => { console.log(2) }, 0)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(2) }`,`() => { console.log(2) }`排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
3. 將`console.log(3)`放入 call stack 執行,輸出 3
4. 將`setTimeout(() => { console.log(4) }, 0)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(4) }`,`() => { console.log(4) }` 排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
5. 將`console.log(5)`放入 call stack 執行,輸出 5
6. event loop 偵測到 call stack 為空時,就會將 callback queue 中的程式按照順序依序放入 call stack 中
7. 將`console.log(2)`放入 call stack,輸出 2
8. 將`console.log(4)`放入 call stack,輸出 4
## 輸出結果
```js
1
3
5
2
4
```
## 小筆記
「非同步的 callback function 會先被放到 callback queue,並且等到 call stack 為空時候才被 event loop 丟進去 call stack」
## hw2:Event Loop + Scope
```js
for(var i=0; i<5; i++) {
console.log('i: ' + i)
setTimeout(() => {
console.log(i)
}, i * 1000)
}
```
## 執行流程
1. 設定變數 i = 0,判斷 i 是否 < 5,是,繼續執行,開始進入第一圈迴圈
2. 輸出 i: 0
3. 將`setTimeout(() => { console.log(i) }, i * 1000)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(i) }`,`() => { console.log(i) }`排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
4. 設定變數 i = 1,判斷 i 是否 < 5,是,繼續執行,開始進入第二圈迴圈
5. 輸出 i: 1
6. 將`setTimeout(() => { console.log(i) }, i * 1000)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(i) }`,`() => { console.log(i) }`排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
7. 設定變數 i = 2,判斷 i 是否 < 5,是,繼續執行,開始進入第二圈迴圈
8. 輸出 i: 2
9. 將`setTimeout(() => { console.log(i) }, i * 1000)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(i) }`,排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
10. 設定變數 i = 3,判斷 i 是否 < 5,是,繼續執行,開始進入第二圈迴圈
11. 輸出 i: 3
12. 將`setTimeout(() => { console.log(i) }, i * 1000)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(i) }`,`() => { console.log(i) }`排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
13. 設定變數 i = 4,判斷 i 是否 < 5,是,繼續執行,開始進入第二圈迴圈
14. 輸出 i: 4
15. 將`setTimeout(() => { console.log(i) }, i * 1000)`放入 call stack 執行,透過 setTimeout 這個非同步的 WebAPI,
在瀏覽器中設定計時器,等時間倒數結束後呼叫`() => { console.log(i) }`,`() => { console.log(i) }`排進 callback queue,執行結束後,setTimeout 就會從 call stack 中 pop 掉
16. 設定變數 i = 5,判斷 i 是否 < 5,否,跳出迴圈
17. event loop 偵測到 call stack 為空,將 callback queue 中的程式按照順序依序放入 call stack 中
18. 將`console.log(i)`放入 call stack,由於本身 EC 的 AO 找不到 i,所以找到上層 global EC 的 VO,此時 i 為 5
19. 輸出 5,清空 call stack
20. 將`console.log(i)`放入 call stack,由於本身 EC 的 AO 找不到 i,所以找到上層 global EC 的 VO,此時 i 為 5
21. 輸出 5,清空 call stack
22. 將`console.log(i)`放入 call stack,由於本身 EC 的 AO 找不到 i,所以找到上層 global EC 的 VO,此時 i 為 5
23. 輸出 5,清空 call stack
24. 將`console.log(i)`放入 call stack,由於本身 EC 的 AO 找不到 i,所以找到上層 global EC 的 VO,此時 i 為 5
25. 輸出 5,清空 call stack
26. 將`console.log(i)`放入 call stack,由於本身 EC 的 AO 找不到 i,所以找到上層 global EC 的 VO,此時 i 為 5
27. 輸出 5,清空 call stack
## 輸出結果
```js
i: 0
i: 1
i: 2
i: 3
i: 4
5
5
5
5
5
```
## hw3:Hoisting
```js
var a = 1
function fn(){
console.log(a)
var a = 5
console.log(a)
a++
var a
fn2()
console.log(a)
function fn2(){
console.log(a)
a = 20
b = 100
}
}
fn()
console.log(a)
a = 10
console.log(a)
console.log(b)
```
## 執行流程
1. 建立 global EC,初始化 VO
```js
global VO {
fn: func,
a: undefined
}
```
2. 執行程式碼
```js
global VO {
fn: func,
a: 1
}
```
3. 呼叫 fn(),建立 fn EC,初始化 AO
```js
fn AO {
fn2: func,
a: undefined
}
```
4. 執行`console.log(a)` 此時 fn AO 中的 a = undefined,所以輸出結果為 `{undefined}`
5. 執行 var a = 5,查看 fn AO 有沒有 a,有,為 a 賦值為 5
```js
fn AO {
fn2: func,
a: 5
}
```
6. 執行`console.log(a)` 此時 fn AO 中的 a = 5,所以輸出結果為 `{5}`
7. 執行 a++,查看 fn AO 有沒有 a,有,為 a 賦值為 6
```js
fn AO {
fn2: func,
a: 6
}
```
8. 呼叫 fn2(),建立 fn2 EC,初始化 AO
```js
fn2 AO {
}
```
9. 執行`console.log(a)` 此時 fn2 AO 中並未找到 a,於是往上一層的 fn AO 尋找
10. 查看 fn AO 有沒有 a,有,此時 此時 fn AO 中的 a = 6,所以輸出結果為 `{6}`
11. 執行`a = 20`,此時 fn2 AO 中並未找到 a,於是往上一層的 fn AO 尋找
12. 查看 fn AO 有沒有 a,有,為 a 賦值為 20
```js
fn AO {
fn2: func,
a: 20
}
```
13. 執行`b = 100`,此時 fn2 AO 中並未找到 b,於是往上一層的 fn AO 尋找
14. 查看 fn AO 有沒有 b,也沒有,繼續往上一層 global VO 尋找
15. 查看 global VO 有沒有 b,還是沒有,而且也已經最頂層了,由於我們是在非嚴格模式下執行程式碼,所以會將 b 宣告在 global VO 中
```js
global VO {
fn: func,
a: 1,
b: 100
}
```
16. fn2 EC 執行結束,回到 fn EC 執行其餘程式碼
17. 執行`console.log(a)` 此時 fn AO 中的 a = 20,所以輸出結果為 `{20}`
18. fn EC 執行結束,回到 global EC 執行其餘程式碼
19. 執行`console.log(a)` 此時 global AO 中的 a = 1,所以輸出結果為 `{1}`
20. 執行`a = 10`,查看 global VO 有沒有 a,有,為 a 賦值為 10
```js
global VO {
fn: func,
a: 10,
b: 100
}
```
21. 執行`console.log(a)` 此時 global AO 中的 a = 10,所以輸出結果為 `{10}`
22. 執行`console.log(b)` 此時 global AO 中的 b = 100,所以輸出結果為 `{100}`
## 輸出結果
```js
undefined
5
6
20
1
10
100
```
## hw4:What is this?
```js
const obj = {
value: 1,
hello: function() {
console.log(this.value)
},
inner: {
value: 2,
hello: function() {
console.log(this.value)
}
}
}
const obj2 = obj.inner
const hello = obj.inner.hello
obj.inner.hello() // ??
obj2.hello() // ??
hello() // ??
```
## 執行流程
在解題前先來補充一下關於 this 在各種情況下的值
1. 在物件導向中,this 所指的就是自己的 instance
2. 在非物件導向中
* 嚴格模式底下就都是`undefined`
* 非嚴格模式,瀏覽器底下是`window`
* 非嚴格模式,node.js 底下是`global`
3. 物件中的 this 則是能夠透過`call`、`apply`、`bind `來更改 this 的值
4. 可以把 a.b.c.hello() 看成 a.b.c.hello.call(a.b.c),以此類推,透過這種轉化的方式就能輕鬆找出 this 的值
**this 的值跟作用域跟程式碼的位置在哪裡完全無關,只跟「你如何呼叫」有關**
ok,那就讓我們開始吧!
1. `obj.inner.hello()`,利用轉化的方式,就能得到`obj.inner.hello.call(obj.inner)`,這樣我們馬上就能知道 this 指的是 obj.inner,
帶入函式就能得到`obj.inner.value`,所以輸出結果就是 2 啦
2. `obj2.hello()`,利用轉化的方式,就能得到`obj.inner.hello.call(obj.inner)`,與上題一樣,那麼輸出結果依然是 2 啦
3. `hello()`,再次利用轉化的方式,可以得到`hello.call()`,由於 hello 前面沒有東西,所以會呼叫全域物件,在嚴格模式底下就都是`undefined`,
非嚴格模式,瀏覽器底下是`window`,node.js 底下則是`global`,但無論 runtime 是瀏覽器還是 node.js,在全域環境中都找不到 value 的值,所以都會印出 undefined
## 執行結果
```js
2
2
undefined
```
## 什麼是 MVC?
MVC 是一種設計模式,透過 MVC 將程式碼區分成 Model、View、Controller 三大部分,Model 負責操作資料相關的工作,View 負責顯示畫面的相關工作,Controller 負責呼叫相對應的 Model 並 render 畫面,遵守 MVC 可以將各項職責切分開來,讓大家各司其職,也能更好維護程式碼和增加可讀性
## 什麼是反向代理(Reverse proxy)?
使用代理伺服器(例如 Nginx)來處理所有 Client 端的連線 Request,再由代理伺服器將 Request 轉發給內部網路不同伺服器上的不同服務,也就是說外部使用者只看得到代理伺服器,實際上哪個服務是運行在內部哪個伺服器則是不可見的。
## 什麼是 ORM?
ORM 是一套幫助開發者能使用程式語言的物件概念來操作資料庫的工具,透過 ORM 就可以不需要直接寫 SQL 語法。
## 什麼是 N+1 problem?
當使用 ORM 進行有一對多關係的資料庫查詢時,大多數的 ORM 工具會用比較簡單的方式遍歷查詢 N 次,而不會採用 SQL 的 JOIN 語法,如此一來,過多的查詢就容易拖累整個網站或應用程式的效能。
例如要查詢留言板五則留言分別是對應哪些使用者暱稱,ORM 會先查詢留言的 table,拿到 5 則留言的 userId, 再用 userId 逐一查詢使用者 table 5 次,所以一共需要查詢 5 + 1 次。在這兩週作業中使用的 Sequelize 有提供 Eager Loading 的做法,可以用 include 來關聯查詢不同的 tables,上面的例子中,在查詢留言時直接 include 使用者的,就可以不需要用遍歷的方式來查詢使用者暱稱。
## 為什麼我們需要 React?可以不用嗎?
React 可以讓我們將 component 拆分開來,每個 component 也都有自己的樣式及邏輯,React 還能幫我們將「資料」與「畫面」做連結,一旦資料的狀態更動,就會連動更改相關的畫面,透過這樣的渲染方式,我們只要關注在資料上就好了,不必擔心資料更動畫面卻沒同步的狀況發生
對於一些靜態網頁或規模不是很大操作簡單的專案來說,或許直接使用 CSS、HTML、JS 會比使用 React 來的方便也更有效率
## React 的思考模式跟以前的思考模式有什麼不一樣?
相比以往的作業,我們必須要同時更改資料及畫面,萬一其中有一個步驟沒統一,就很有可能發生資料與畫面不同步的情形,而現在使用 React 則是只要專注在資料上面就好,畫面會連動渲染,在實作上也要去極力避免直接去 DOM tree 上抓取元素或更動資料,以防出現預期外的 Bug 發生
在切板時,也必須考慮到 component 在專案中可以重複使用的地方,再決定要如何拆分才能更有效率的使用這些元件
## state 跟 props 的差別在哪裡?
state 是 component 本身的資料,只有只有這個 component 才能改變自己的 state
props 則是被父層當作參數傳遞給子層的 state,如果子層想更改這個 props,父層必須將改變 state 的方法一起傳遞給子層
## 請列出 React 內建的所有 hook,並大概講解功能是什麼
* `useState` 會回傳一個 state 的值和一個更新 state 的 setState function,可以在呼叫 useState 時帶上一個參數,而這個參數就是 state 的初始值,參數只會在初始 render 時使用,在後續 render 則會被忽略,此外,如果初始值需要經過複雜的計算才能得到,則可以傳入一個 function,這個 function 只會在初始 render 時才會被調用,而當我們使用 setState 改變 state 的同時,React 會幫我們重新渲染畫面
* `useEffect` 內的函式在預設情況下,useEffect 會在每次 render 後執行,不過 useEffect 還提供了第二個參數 dependencies 的陣列,只要我們把指定的 state 加入陣列,就能監控這個的 state,只有當這個 state 改變時才執行 useEffect,只要每次重新渲染後 dependencies 內的 state 沒有改變,任何 useEffect 裡面的函式就不會被執行,陣列內也可以不放入 state,代表只會在第一次 render 後執行這個 useEffect,同時, useEffect 還能回傳一個 cleanup function,會在移除 useEffect 前先執行這個 cleanup function,這也意味著每一次 useEffect 的更新,都會產生一個新的 useEffect
* `useContext` 可以接收一個 createContext 的回傳值,並回傳這個 context 目前的值,這使得 parent component 下的任何一個 children component 都能更輕易的取得 parent component 的資料
* `useReducer` 會接收 reducer 和 initialState,然後回傳現在的 state 和其配套的 dispatch 方法,reducer 這個函式會依據不同的 action 回傳不同的 state
* `useCallback` 會回傳一個 memoized 的 callback,在這個 useCallback 中也提供了一個 dependencies 的陣列,只有當 dependencies 改變時才會更新,透過 useCallback 可以防止不必要的 render 發生
* `useMemo` 會回傳一個 memoized 的值,useMemo 也提供了一個 dependencies 的陣列,只有當 dependencies 改變時才會更新,useMemo 和 useCallback 都是可以防止不必要的 render 發生,不過 useCallback 回傳一個 function,useMemo 則是回傳一個值
* `useRef` 回傳一個 mutable 的 ref object,.current 屬性被初始為傳入的參數 ( initialValue ),回傳的 object 在 component 的生命週期將保持不變,這也意味著 useRef 在每次 render 時都會給你同一個的 ref object
* `useImperativeHandle` 將 children component 的某些函式透過 ref 的方式 開放給 parent component 呼叫
* `useLayoutEffect` 與 useEffect 的功能相同,不過 useLayoutEffect 觸發的時機點會在 DOM 改變完之後、瀏覽器 paint 之前執行,React 官方建議還是先使用 useEffect,只當它有問題時才嘗試使用 useLayoutEffect
* `useDebugValue` 用來在 React DevTools 中顯示自訂義 hook 的標籤
## 請列出 class component 的所有 lifecycle 的 method,並大概解釋觸發的時機點
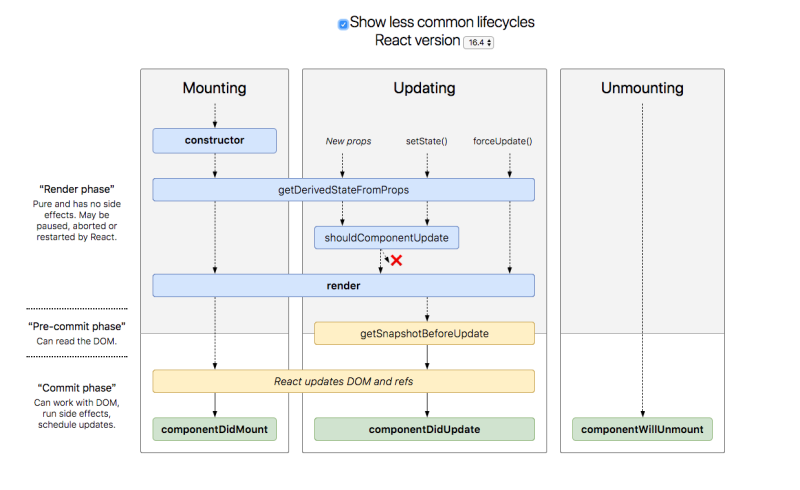
[class component 的生命週期表](https://projects.wojtekmaj.pl/react-lifecycle-methods-diagram/)
如上圖,class component 的 lifecycle 可區分為三個執行階段,Mounting 當 component 被加入到 DOM 中時會觸發,Updating 當 component 的 props 或 state 更新,重新渲染 (re-rendered) DOM 時觸發,Unmounting 當元件要從 DOM 中被移除時觸發
### Mounting
* `constructor` 一個 React component 的 constructor 會在其被 mount 之前被呼叫
* `getDerivedStateFromProps` 會在一個 component 被 render 前被呼叫,不管是在首次 mount 時或後續的更新時
* `render` 當 render 被呼叫時,它會檢視 this.props 和 this.state 中的變化,並回傳相關元素
* `componentDidMount` 在 component 被 mount(加入 DOM tree 中)後,componentDidMount 會馬上被呼叫
### Updating
* `getDerivedStateFromProps` 會在一個 component 被 render 前被呼叫,不管是在首次 mount 時或後續的更新時
* `shouldComponentUpdate` React 的預設行為是每當 state 有所改變時就重新 render,不過若 shouldComponentUpdate 回傳的值為 false 的話,render 將不會被呼叫,執行時機為getDerivedStateFromProps 和 render 之間
* `render` 當 render 被呼叫時,它會檢視 this.props 和 this.state 中的變化,並回傳相關元素
* `getSnapshotBeforeUpdate` 會在最近一次 render 的 output 被提交給 DOM 時被呼叫
* `componentDidUpdate` 會在更新後馬上被呼叫。這個方法並不會在初次 render 時被呼叫
### Unmounting
* `componentWillUnmount` 會在ㄧ個 component 被 unmount 前呼叫,可以透過 componentWillUnmount 清除一些綁定的資訊
## 請問 class component 與 function component 的差別是什麼?
由於目前還是以 function component 實作為主,所以這題會以 function component 為主體,進而探討兩者之間的差異
function component 本身並沒有 state(如果沒有使用 hook 的話),class component 本身可以定義一個 state 的物件,要修改 state 必須透過 setState 這個內建函式, function component 則是可以透過 hooks 中 useState 定義一個 state 和 setState,相比之下,使用 hooks 管理 state 的方式方便許多,值得一提的是,在 function component 中只要調用了 setState 這個函式就會就會觸發 component 重新渲染,儘管 state 的值並沒有改變,而對 function component 來說,只有 state 真正改變時才會重新渲染,這樣的機制能夠幫我們擋掉一些不必要的 re-render
function component 是以 hook 為主體思考,class component 則是以 instance 為主體思考,因此 function component 並沒有 this,這使得我們不必寫出 this.state.xxx 的冗長語法,也不必煩惱在傳入事件處理器時要根據情況來 bind(this),不過也正是因為 this 的關係,由於 props 與 state 都是 immutable 的,在使用 class component 的時候,React 內部的實現會幫你操控 this 指向 component,也就是說 this 是可變的。class component 能夠隨時拿到 this.props.xxx 最新的改變,可是 function component 並不是這樣的,每一次 render 就是一次 function call,而傳進來的 props 就會是「當時」的 props,不會因為 props 改變而改變。這個就是 function component 與 class component 最大的差別
class component 是透過 ES6 class 語法來實作基於 OOP 的元件, functional component 則是利用閉包來管理狀態 funtion 元件,前者由於 this 並非 immutable,導致 state, props 都會是最新的結果,對於一些 callback 操作的處理會比較複雜,例如:setTimeout;後者則由於不需要使用 this、且保持 function 的特性讓共同邏輯更容易抽取出來共用而且更容易測試,不過前者提供更多 lifecycle hooks 讓比較複雜的元件狀態更好管理。
## uncontrolled 跟 controlled component 差在哪邊?要用的時候通常都是如何使用?
差別在於 component 有沒有被 React 控制,controlled component 會隨著資料的變動進而改變 UI,uncontrolled component 則不會,若要取的 uncontrolled component 的 state 則必須直接操作 DOM 或使用 useRef 方式才能取到值,如果有重新渲染畫面的需求,建議還是使用 Controlled Component 來處理
## 為什麼我們需要 Redux?
在規模較大的專案當中,經常會透過不同的 component 來改變 state,對於這樣的情況可能不利於追蹤是哪個 component 改變了 state,但如果我們採用 Redux 來管理共同的 state,不管是在追蹤資料還是 debug 都會變得輕鬆許多
## Redux 是什麼?可以簡介一下 Redux 的各個元件跟資料流嗎?
Redux 是一個狀態管理工具,可以讓開發者更容易的管理 state,在我們詳細的講解流程之前先附上一張流程圖
### 三大元件
- `action`:是一個物件,action 必須帶有一個 type 用來描述發生的事件類別,如果有額外的資料可以放在 payload
```js
const Action = {
type: 'plus',
// payload: {
// message: ...
// }
};
```
- `reducer`:是一個函式,用來接收當前的 state 與 action,會根據不同的 action 更新 state 的狀態,當 reducer 被執行的時候,initialState 會當作 state 的預設值
```js
const initialState = { value: 0 };
export default function todosReducer(state = initialState, action) {
switch (action.type) {
case 'plus': {
return {
value: state.value + 1,
};
}
default: {
return state;
}
}
}
```
reducer 還有一些使用的規則需要注意
1. 新的 state 狀態只能是透過當前的 state 與 action 物件來取得
2. 不可以修改當前的 state,需要透過額外複製一份當前 state 的狀態,並從那份狀態來進行更新
3. reducer 必須是一個 pure function,不可以在此設計非同步邏輯、隨機值或者其他會造成 side effect 的行為
- `store`:負責儲存整個 state tree,可以透過 redux 中提供的 createStore 來創建 store,需要帶入一個 reducer 的參數
```js
import { createStore } from 'redux';
import rootReducer from './reducers';
export default createStore(rootReducer);
```
createStore 會回傳一個物件,會有以下幾個 method
1. `dispatch(action)`: 透過這個方法讓 store 知道我們想要觸發哪一個事件(藉由傳入 action 物件得知),這是唯一觸發 state 變更的方法
2. `getState()`: 回傳現在 store 的 state
3. `subscribe(listener)`: 會在 state 改變時被呼叫的 function
4. `replaceReducer(nextReducer)`: 可以被用來實作 hot reloading 與 code splitting
## 該怎麼把 React 跟 Redux 串起來?
Redux 官方有提供一個 react-redux 的套件,可以讓我們很方便地將 React 跟 Redux 串起來,我們可以透過 connect API 和 hooks API 兩種方法來連結
### connect API
開始前我們必須先從 react-redux 中引入 Provider 並在 component 的最頂層使用 `<Provider store={store}>` 傳入 store,讓所有 children component 都拿得到 store
要使用 connect(),你需要定義一個 mapStateToProps 的 function,它會轉換目前 Redux store state 成為 presentational component 的 props
除了讀取 state,container component 也可以 dispatch actions。以類似的方式,你可以定義一個 mapDispatchToProps() 的 function,它接收 dispatch() method 並回傳你想要傳給 presentational component 的 callback props
在建立完 mapStateToProps 和 mapDispatchToProps 完後,我們就可以用 higher order component 的方式將 store 和 component 綁定在一起
```js
const connectToStore = connect(mapStateToProps, mapDispatchToProp);
const ConnectedComponent = connectToStore(Component);
export default ConnectedComponent;
```
也可以簡化成
```js
export default connect(mapStateToProps, mapDispatchToProp)(Component);
```
這樣在 presentational component 的 props 裡就拿得到 dispatch 和 state 了
### hooks API
一樣要先在 component 的最頂層使用 `<Provider store={store}>` 傳入 store,讓所有 children component 都拿得到 store
在想使用 props 的 children component 中,從 react-redux 中引入 useDispatch、useSelector, 就可以直接在 children component 中 dispatch(action) 也可以根據自訂的 selector 來拿到不同的 state 了
## Redux middleware 是什麼?
在原來的 Redux 的資料流中,我們只能 dispatch 一個 obj 的 action,所以就不能做出像是非同步這樣的 side effect,不過如果使用了 Redux middleware 就可以在 action 抵達 store 之前,事先轉換 action 的內容再傳進 store
以 Redux thunk 這個 middleware 為例,我們不只可以在 action 中放入 obj 還能放入 function,再 dispatch 之後,Redux thunk 就會幫我們執行 action 中 function,如果沒有其他 middleware,待執行完畢後就會將執行結果傳進 store
## CSR 跟 SSR 差在哪邊?為什麼我們需要 SSR?
* `CSR`:CSR 是指網頁的畫面都是在前端由 JS 動態產生,所以當我們查看網頁原始碼時,只會看到沒什麼內容的 HTML,所以也會導致搜尋引擎在爬資料時,獲取不到網站的相關資料也意味著不利於 SEO 優化
* `SSR`:SSR 則是為了解決 SEO 優化問題的解決辦法,在網頁首次載入頁面時,伺服器會將內容都事先放到 HTML 中,所以當我們再次查看網頁原始碼時,就可以看到含有完整內容的 HTML
## React 提供了哪些原生的方法讓你實作 SSR?
在 `react-dom/server` 中有兩個方法 `renderToString` 和 `renderToStaticMarkup` 可以在 server 端渲染你的 components,主要都是將 React Component 在 Server 端轉成 DOM String,但對於事件處理會失效,因為 event handler 是屬於 JS ,這時就可以在 client 端加上 `ReactDOM.hydrate()`,將 JS 功能重新放回到已經被 server 端所轉譯的 HTML 上
`renderToString` 和 `renderToStaticMarkup` 最大的差別在於 `renderToStaticMarkup` 會少加一些 React 內部使用的 DOM 屬性,例如:data-react-id,因此可以節省一些資源
## 承上,除了原生的方法,有哪些現成的框架或是工具提供了 SSR 的解決方案?至少寫出兩種
* `Prerender`:Prerender 會預先將網站執行完 JS 的渲染結果 cache 住,當搜尋引擎的爬蟲造訪網站時,就能把之前快取的渲染結果回傳給它
* `Next.js`:是一套以 React 為基礎的 SSR 框架,Next.js 支援 SSG 和 SSR 兩種 pre-rendering 方式,SSG 的 HTML 在 build time 時就由 server 產生好,並且在之後的 client request 都會共用這個 HTML,而 SSR 則是每當有 client 發起對某個頁面的 request 時,server 會抓取對應的資料,建立完整的 HTML,最後再回傳給 client
React 組件每次在渲染或更新畫面時,都會重新呼叫產生這個組件的函式,而在 React Hooks 中會去記錄這些 Hooks 在函式中被呼叫的順序,以確保資料能夠被相互對應,但若當我們將 Hooks 放到條件式或迴圈時,就會破壞了這些 Hooks 被呼叫到的順序,這樣就可能會造成意外的錯誤。
## ⚠️ 重要補充:千萬不能在條件式(conditions)、迴圈(loops)或嵌套函式(nested functions)中呼叫 Hook 方法
之所以會有這樣的規定是因 React 組件每次在渲染或更新畫面時,都會呼叫產生這個組件的函式,而在 React Hooks 中會去記錄這些 Hooks 在函式中被呼叫的順序,以確保資料能夠被相互對應,但若當我們將 Hooks 放到條件式或迴圈時,就會破壞了這些 Hooks 被呼叫到的順序,如此會造成錯誤