# 2016q1 Homework1 phonebook
===
小的是菜鳥一個,還有很多不懂的地方,請多多包涵@@
* 知道自己不足,就趕快補強,不要討拍取暖
首先是系統,電腦在很早之前我就給它裝上了ubuntu linux系統,coding方面一向來也是開ubuntu來寫,原因的話是因爲比較帥,版本也已經升級到最新的15.10。

作業部分
**<u>Cache Miss</u>**
首先要瞭解什麼是cache miss,不然我根本不懂要如何下手。上網爬了一下資料,才對cache miss有了那麼一點點的瞭解。
**_當processor在cache讀取資料時失敗,便稱為Cache Miss。_**
* Compulsory misses:第一次存取未曾在cache內的block而發生的cache miss,prefetching或更大的cache block可以改善這個問題
* Capacity misses:cache的大小無法吃進需要的資料大小
* Conflict misses:通常發生在direct-mapped caches.兩個cache line可能會映射到同一個cache slot,即使有空的slot,也有可能會儲存兩個cache lines,這樣會造成conflict misses.
參考資料:[](https://hackpad.com/ep/pad/static/3W85kjarBNa)https://hackpad.com/ep/pad/static/3W85kjarBNa
**<u>Astyle</u>**
* 就是一個很帥的程式!還沒認真的去研究,Astyle主要的功能是可以幫你排版你的code,而作業規定的排版如下:
* astyle --style=kr --indent=spaces=4 --indent-switches --suffix=none *.[ch]
**<u>Gnuplot</u>**
剛開始在測試的時候發現,make plot出來的圖不管幾次都是同一個結果,懊惱了一段時間去研究code才發現,在main.c裏的這段fopen所使用的是"a",這個"a"的意思是從檔案的尾端開始寫,所以它不會覆寫原有的資料。因此如果沒有在make plot之前把"opt.txt"跟"orig.txt"刪掉的話,它的資料會一直增加,而且是從後面增加,所以每次make plot出來的圖都是前100筆的資料。
* #if defined(OPT)
* output = fopen("opt.txt", "a");
* #else
* output = fopen("orig.txt", "a");
解決方法:
1. 每次make plot前記得刪掉"opt.txt"跟"orig.txt"
2. 或許可以調整下main.c的code
**<u>Perf</u>**
* 全名是 Performance Event,是linux內建的系統效能分析工具
* 利用[](http://wiki.csie.ncku.edu.tw/embedded/perf-tutorial)http://wiki.csie.ncku.edu.tw/embedded/perf-tutorial 上的範例是看看perf的功用,程式碼如下:
```clike=
#include <stdio.h>
#include <unistd.h>
double compute_pi_baseline(size_t N) {
double pi = 0.0;
double dt = 1.0 / N;
for (size_t i = 0; i < N; i++) {
double x = (double) i / N;
pi += dt / (1.0 + x * x);
}
return pi * 4.0;
}
int main() {
printf("pid: %d\n", getpid());
sleep(10);
compute_pi_baseline(50000000);
return 0;
}
```
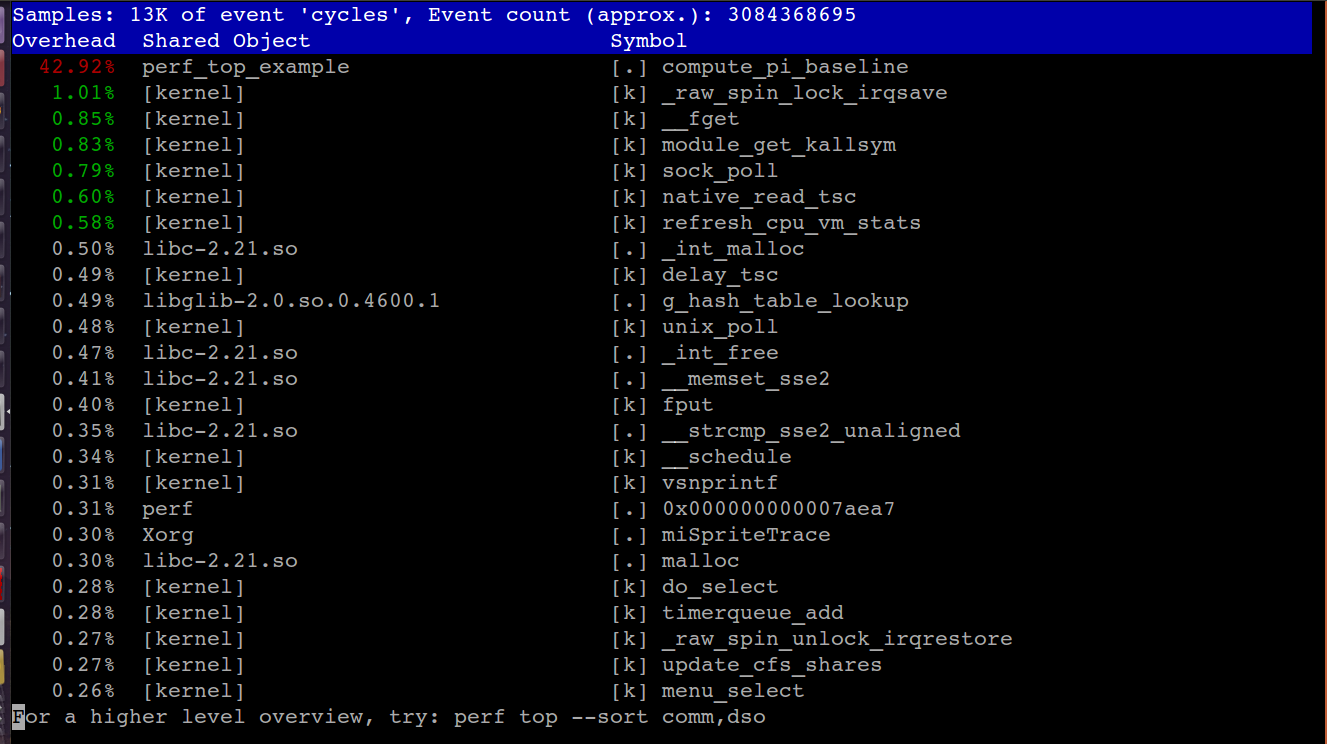
* 執行程式後,打開另一個terminal進入root mode輸入指令:
* perf top
* 結果如下,可以很清楚的看到運行中的程式熱點:
* 
**<u>作業要求</u>**
1. findName() 的時間必須原本的時間更短
2. append() 的時間可以比原始版本稍久,但不應該增加太多
方法:
* 首先我有將還沒用到的資料搬到其它的結構,所以cache miss就少了很多,再來排除老師wiki上給的方向,提一些我自己想到的。
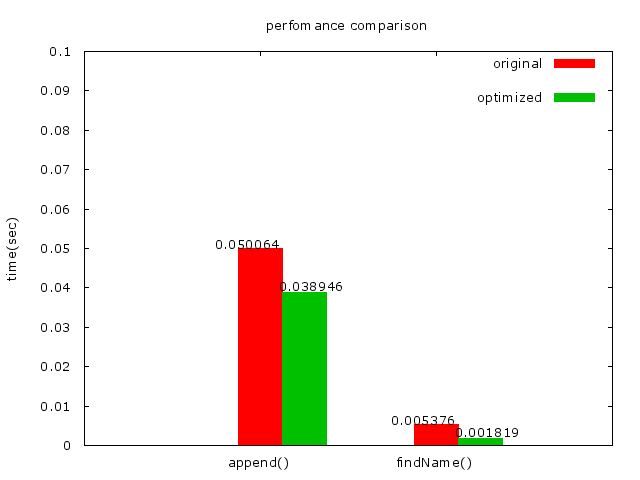
* 我一開始是想有沒有更快的方法可以compare字串,因此就想到如果可以指定大小寫,那就不需要用到strcasecmp了,可以直接用strcmp,速度是差蠻多的。
* _strcmp的結果:_
* 
* _strcasecmp的結果:_
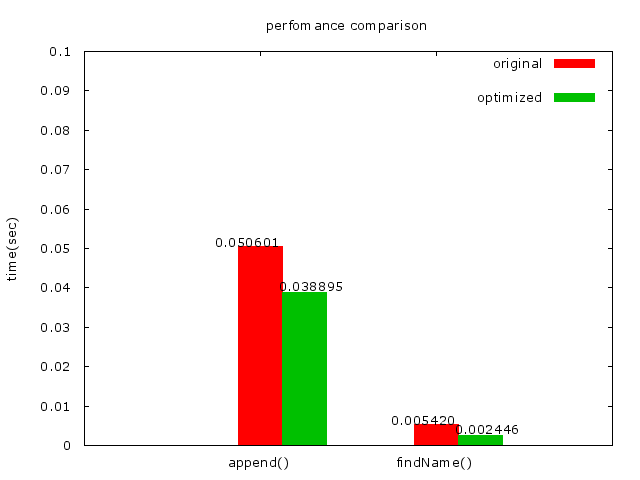
```clike=
char *a = "abcdef";
char *b = "abcded";
if(strcmp(a,b)==0)
* printf("YES\n");
else
* printf("No\n");
char *c = "ABCDEF";
if(strcasecmp(a,c)==0)
* printf("yes\n");
else
* printf("no\n");
Output: Yes
* No
```
再來是append方面,有找到memcpy比strcpy的速度還來的快,但還沒仔細研究memcpy,先放個圖參考參考。
_strcpy的結果:_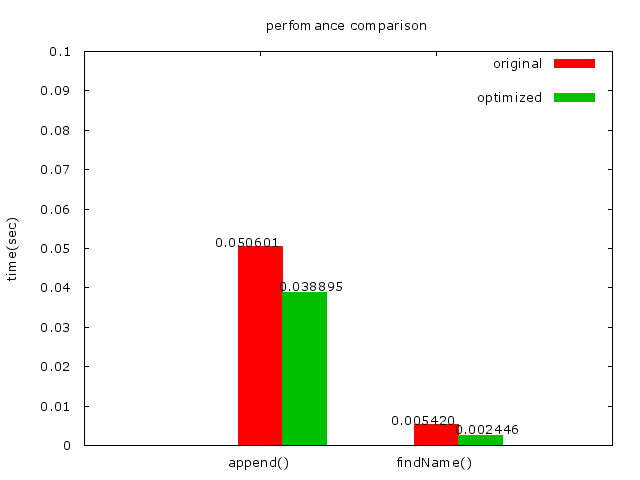
_memcpy的結果:_
* 問題:如何解釋這點?
* memcpy是用內存來進行copy的動作,且可以對任意類型的數據進行copy,因爲並不是所有數據都有null char,所以必須先指定要copy的大小。而strcpy只能copy字串,讀到字串的結尾就結束。
* 如果要copy字串卻不知道字串的長度,strcpy是會跟memcpy加strlen一樣快或快過memcpy,因此我選擇使用了strcpy。
**<u>Hash Table 優化</u>**
有研究了一段時間才搞懂...好吧 至少我搞懂了
方法:
利用hash function計算出不同lastName的hash value,在利用這些hash value做一個hash table。hash table中存的是每個entry的地址,同樣hash value的就用linked list連起來。尋找字串的時候就先計算該字串的hash value,然後去到對應的table尋找是否在裏面。
1. 首先要準備所需要用到的table結構
```clike=
typedef struct _hash_table {
entry **table;
} hash_table;
```
利用雙pointer去指向每個entry的位置,再來就malloc記憶體給它:
```
new_table = malloc(sizeof(hash_table));
new_table->table = malloc(sizeof(entry *) * SIZE );
```
SIZE是由我定義的table大小,這個SIZE越大,findName的速度就越快,而缺點就是記憶體會使用的比較多
`#define SIZE 1024`
1. 再來就是entry本身的結構:
```clike=
typedef struct __PHONE_BOOK_ENTRY {
char lastName[MAX_LAST_NAME_SIZE];
struct __PHONE_BOOK_ENTRY *pNext;
Details *details;
} entry;
```
先將有使用到的lastName定義好,再來使用一個指標指向details的結構中,這樣就能減少記憶體、減少cache miss,以下是details的結構:
```clike=
typedef struct __PHONE_BOOK_DETAILS {
char firstName[16];
char email[16];
char phone[10];
char cell[10];
char addr1[16];
char addr2[16];
char city[16];
char state[2];
char zip[5];
} Details;
```
1. hash function只要碰撞機率越小就越好,所以我在計算hash value的過程中加上了每個字串中的個別字元,原本打算用乘法,可是乘法的效率好像比加減還要慢。以下是我的hash function:
```clike=
unsigned int hash(hash_table *hashtable , char *str)
{
unsigned int hash_value = 0;
while(*str)
hash_value = (hash_value << 5) - hash_value + (*str++);
return (hash_value % SIZE);
}
```
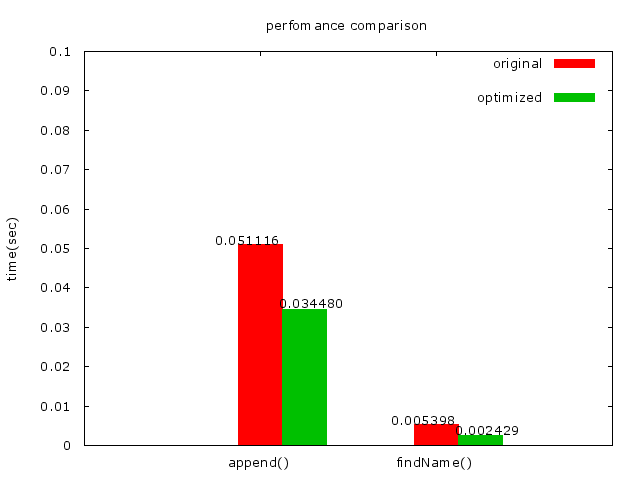
1. 再來就是實做啦,一開始將SIZE設成1024的結果:
* Performance counter stats for ’./phonebook_opt’ (100 runs):
* 81,185 cache-misses # 53.494 % of all cache refs
* 147,246 cache-references
* 228,715,876 instructions # 1.87 insns per cycle
* 180,942,857 cycles
* 0.049180162 seconds time elapsed ( +- 0.84% )
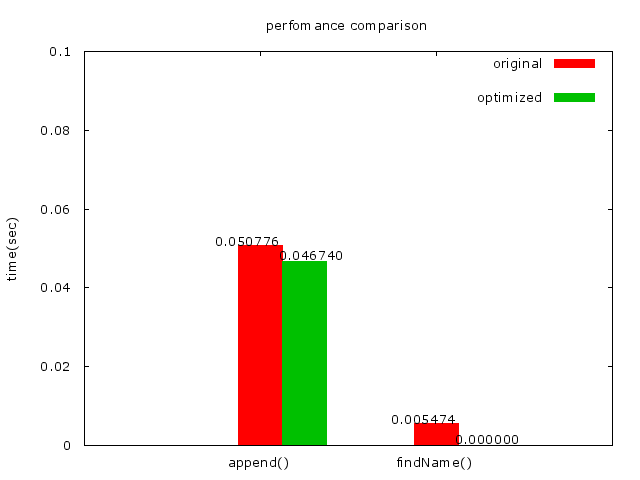
* 發現Cache miss跟findName時間都減少了很多!
* 再來嘗試看看將SIZE設大一點,102400,加了兩個0的結果:
* Performance counter stats for ’./phonebook_opt’ (100 runs):
* 141,792 cache-misses # 30.019 % of all cache refs
* 435,141 cache-references
* 240,963,888 instructions # 1.66 insns per cycle
* 135,276,512 cycles
* 0.058827466 seconds time elapsed ( +- 0.91% )
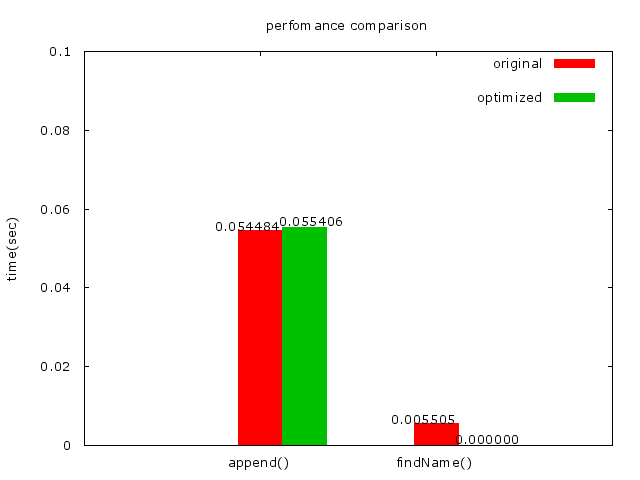
* Cache miss 大大減少了很多!可是append的時間卻加長了一點,相信findName的時間也相對的減少了很多,但findName的時間在表中已經見底了,所以看不出來。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet