# Linux 核心 Read-Copy Update 筆記整理
contributed by < [`linD026`](https://github.com/linD026) >
###### tags: `Linux kernel RCU` , `linux2021`
> [RCU concepts](https://www.kernel.org/doc/html/v5.10/RCU/index.html)
:::warning
<font size=2>關於 RCU 的概念,請見:[Linux 核心設計: RCU 同步機制](https://hackmd.io/@sysprog/linux-rcu) 、 [perfbook](https://mirrors.edge.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html) - section 9.5 , section B 。
關於 Linux 內 RCU 完整資料:[RCU concepts](https://www.kernel.org/doc/html/latest/RCU/index.html) 。
</font>
:::
---
* [What is RCU, Fundamentally?](https://lwn.net/Articles/262464/)
> So the typical RCU update sequence goes something like the following:
> 1. Remove pointers to a data structure, so that subsequent readers cannot gain a reference to it.
> 2. Wait for all previous readers to complete their RCU read-side critical sections.
> 3. At this point, there cannot be any readers who hold references to the data structure, so it now may safely be reclaimed (e.g., `kfree()`).
>
> This article has described the three fundamental components of RCU-based algorithms:
> - publish-subscribe mechanism for adding new data,
> - way of waiting for pre-existing RCU readers to finish, and
> - discipline of maintaining multiple versions to permit change without harming or unduly delaying concurrent RCU readers.
:::warning
**NOTE** [Mentorship Session: Unraveling RCU-Usage Mysteries (Fundamentals)](https://www.youtube.com/watch?v=K-4TI5gFsig)
:::











## Classic - RCU
### Toy - Classic RCU
在無 [`CONFIG_PREEMPT_RCU`](https://elixir.bootlin.com/linux/latest/source/include/linux/rcupdate.h#L66) 下, classic 版本的 read-side critical section 不准被 block 或 sleep ,因此 read-side lock 可寫成:
```cpp
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
rcu_read_unlock_strict();
}
static inline int rcu_preempt_depth(void)
{
return 0;
}
```
:::warning
而在沒有 `CONFIG_PREEMPT_COUNT` 下 (被用於 kernel preemption, interrupt count 等), [`preempt_disable()`](https://elixir.bootlin.com/linux/latest/source/include/linux/preempt.h#L252) 等相關函式彙編成 [compiler barrier](https://elixir.bootlin.com/linux/latest/source/include/linux/preempt.h#L252) 。
:::
而 `synchronize_rcu` 只要在每個 CPU 上執行 context switch ,則可視為已離開 read-side critical section :
```cpp
static __inline__ void synchronize_rcu(void)
{
int cpu;
smp_mb();
for_each_online_cpu(cpu)
run_on(cpu);
}
```
> There is a trick, and the trick is that RCU Classic read-side critical sections delimited by `rcu_read_lock()` and `rcu_read_unlock()` are not permitted to block or sleep. Therefore, when a given CPU executes a context switch, we are guaranteed that any prior RCU read-side critical sections will have completed. This means that as soon as each CPU has executed at least one context switch, all prior RCU read-side critical sections are guaranteed to have completed, meaning that `synchronize_rcu()` can safely return.
:::warning
[**`rcu_read_lock`**](https://www.kernel.org/doc/html/latest/core-api/kernel-api.html#c.rcu_read_lock)
> In v5.0 and later kernels, `synchronize_rcu()` and `call_rcu()` also wait for regions of code with preemption disabled, including regions of code with **interrupts** or **softirqs** disabled. In pre-v5.0 kernels, which define `synchronize_sched()`, only code enclosed within `rcu_read_lock()` and `rcu_read_unlock()` are guaranteed to be waited for.
>
> Note, however, that RCU callbacks are permitted to run concurrently with new RCU read-side critical sections. One way that this can happen is via the following sequence of events:
> (1) CPU 0 enters an RCU read-side critical section,
> (2) CPU 1 invokes `call_rcu()` to register an RCU callback,
> (3) CPU 0 exits the RCU read-side critical section,
> (4) CPU 2 enters a RCU read-side critical section,
> (5) the RCU callback is invoked.
> This is legal, because the RCU read-side critical section that was running concurrently with the `call_rcu()` (and which therefore might be referencing something that the corresponding RCU callback would free up) has completed before the corresponding RCU callback is invoked.
:::
### Sparse static-analysis checker - `__rcu`
> A pointer can be marked `__rcu`, which will cause the sparse static-analysis checker to complain if that pointer is accessed directly, instead of via `rcu_dereference()` and `rcu_assign_pointer()`. This checking can help developers avoid accidental destruction of the address and data dependencies on which many RCU use cases depend.
>> [address and data dependecies](https://paulmck.livejournal.com/63316.html)
利用 Sparse 提供的 `address_space` 等功能,檢測在 RCU 下的 pointer 不會直接被 dereference 。
```cpp
#ifdef __CHECKER__
...
# define __rcu __attribute__((noderef, address_space(__rcu)))
...
```
假設有一個 `struct test __rcu *foo` 指標,在 Sparse 的檢測下 plain access 會出現下列錯誤:
```cpp
main.c:42:9: warning: incorrect type in assignment (different address spaces)
main.c:42:9: expected struct test *[unused] tmp
main.c:42:9: got struct test [noderef] __rcu *static [toplevel] foo
```
這是為了要讓被 RCU 保護的指標,只經由 RCU API 來 access ,例如 `rcu_assign_pointer` 以及 `rcu_dereference` 。
### Sparse static-analysis checker - [lock](https://www.kernel.org/doc/html/v4.13/dev-tools/sparse.html#using-sparse-for-lock-checking)
```cpp
__must_hold - The specified lock is held on function entry and exit.
__acquires - The specified lock is held on function exit, but not entry.
__releases - The specified lock is held on function entry, but not exit.
```
### TODO Lockdep - RCU
> In most RCU use cases, the `rcu_dereference()` primitive that accesses RCU-protected pointers must itself be protected by `rcu_read_lock()`. The Linux-kernel lockdep facility has been therefore adapted to complain about unprotected uses of `rcu_dereference()`.
* [The kernel lock validator](https://lwn.net/Articles/185666/)
* [Lockdep-RCU](https://lwn.net/Articles/371986/)
### `rcu_dereference()`
```cpp
#define __rcu_dereference_check(p, c, space) \
({ \
/* Dependency order vs. p above. */ \
typeof(*p) *________p1 = (typeof(*p) *__force)READ_ONCE(p); \
RCU_LOCKDEP_WARN(!(c), "suspicious rcu_dereference_check() usage"); \
rcu_check_sparse(p, space); \
((typeof(*p) __force __kernel *)(________p1)); \
})
/**
* rcu_dereference_check() - rcu_dereference with debug checking
* @p: The pointer to read, prior to dereferencing
* @c: The conditions under which the dereference will take place
*
* Do an rcu_dereference(), but check that the conditions under which the
* dereference will take place are correct. Typically the conditions
* indicate the various locking conditions that should be held at that
* point. The check should return true if the conditions are satisfied.
* An implicit check for being in an RCU read-side critical section
* (rcu_read_lock()) is included.
*
* For example:
*
* bar = rcu_dereference_check(foo->bar, lockdep_is_held(&foo->lock));
*
* could be used to indicate to lockdep that foo->bar may only be dereferenced
* if either rcu_read_lock() is held, or that the lock required to replace
* the bar struct at foo->bar is held.
*
* Note that the list of conditions may also include indications of when a lock
* need not be held, for example during initialisation or destruction of the
* target struct:
*
* bar = rcu_dereference_check(foo->bar, lockdep_is_held(&foo->lock) ||
* atomic_read(&foo->usage) == 0);
*
* Inserts memory barriers on architectures that require them
* (currently only the Alpha), prevents the compiler from refetching
* (and from merging fetches), and, more importantly, documents exactly
* which pointers are protected by RCU and checks that the pointer is
* annotated as __rcu.
*/
#define rcu_dereference_check(p, c) \
__rcu_dereference_check((p), (c) || rcu_read_lock_held(), __rcu)
/**
* rcu_dereference() - fetch RCU-protected pointer for dereferencing
* @p: The pointer to read, prior to dereferencing
*
* This is a simple wrapper around rcu_dereference_check().
*/
#define rcu_dereference(p) rcu_dereference_check(p, 0)
```
### `rcu_assign_pointer()`
```cpp
/**
* rcu_assign_pointer() - assign to RCU-protected pointer
* @p: pointer to assign to
* @v: value to assign (publish)
*
* Assigns the specified value to the specified RCU-protected
* pointer, ensuring that any concurrent RCU readers will see
* any prior initialization.
*
* Inserts memory barriers on architectures that require them
* (which is most of them), and also prevents the compiler from
* reordering the code that initializes the structure after the pointer
* assignment. More importantly, this call documents which pointers
* will be dereferenced by RCU read-side code.
*
* In some special cases, you may use RCU_INIT_POINTER() instead
* of rcu_assign_pointer(). RCU_INIT_POINTER() is a bit faster due
* to the fact that it does not constrain either the CPU or the compiler.
* That said, using RCU_INIT_POINTER() when you should have used
* rcu_assign_pointer() is a very bad thing that results in
* impossible-to-diagnose memory corruption. So please be careful.
* See the RCU_INIT_POINTER() comment header for details.
*
* Note that rcu_assign_pointer() evaluates each of its arguments only
* once, appearances notwithstanding. One of the "extra" evaluations
* is in typeof() and the other visible only to sparse (__CHECKER__),
* neither of which actually execute the argument. As with most cpp
* macros, this execute-arguments-only-once property is important, so
* please be careful when making changes to rcu_assign_pointer() and the
* other macros that it invokes.
*/
#define rcu_assign_pointer(p, v) \
do { \
uintptr_t _r_a_p__v = (uintptr_t)(v); \
rcu_check_sparse(p, __rcu); \
\
if (__builtin_constant_p(v) && (_r_a_p__v) == (uintptr_t)NULL) \
WRITE_ONCE((p), (typeof(p))(_r_a_p__v)); \
else \
smp_store_release(&p, RCU_INITIALIZER((typeof(p))_r_a_p__v)); \
} while (0)
```
> In contrast, when assigning a non-NULL pointer, it is necessary to use smp_store_release() in order to ensure that initialization of the pointed-to structure is carried out before assignment of the pointer.
:::info
#### **Implementation** - [linD026/parallel-programs/rcu](https://github.com/linD026/parallel-programs/tree/main/rcu)
> Single atomic counter vs. mult-thread atomic counter
其中單個全域變數的 reference count 並以 C11 atomic 操作的 locked-RCU,與 per-thread 的 reference count 的 thrd-based-RCU 做比較。以下分別為 read side 和 update side 的花費時間:
* read side
```shell
locked rcu read side: reader 10, updater 5
[trace time] loop 1000 : 114887562.000000 ns
[trace time] loop 1000 : 106984171.000000 ns
[trace time] loop 1000 : 84999125.000000 ns
[trace time] loop 1000 : 66833412.000000 ns
[trace time] loop 1000 : 78764877.000000 ns
[trace time] loop 1000 : 62696166.000000 ns
[trace time] loop 1000 : 39124978.000000 ns
[trace time] loop 1000 : 7131566.000000 ns
[trace time] loop 1000 : 78920418.000000 ns
[trace time] loop 1000 : 92989250.000000 ns
-------------------------
thrd rcu read side: reader 10, updater 5
[trace time] loop 1000 : 43251951.000000 ns
[trace time] loop 1000 : 118788069.000000 ns
[trace time] loop 1000 : 32702430.000000 ns
[trace time] loop 1000 : 47056245.000000 ns
[trace time] loop 1000 : 78933604.000000 ns
[trace time] loop 1000 : 79083742.000000 ns
[trace time] loop 1000 : 37655794.000000 ns
[trace time] loop 1000 : 32983218.000000 ns
[trace time] loop 1000 : 13721025.000000 ns
[trace time] loop 1000 : 60575796.000000 ns
```
* update side
```shell
locked rcu update side: reader 100, updater 5
[trace time] loop 1000 : 55570025.000000 ns
[trace time] loop 1000 : 23735316.000000 ns
[trace time] loop 1000 : 39644951.000000 ns
[trace time] loop 1000 : 57753195.000000 ns
[trace time] loop 1000 : 25884461.000000 ns
-------------------------
thrd rcu update side: reader 100, updater 5
[trace time] loop 1000 : 39909560.000000 ns
[trace time] loop 1000 : 39606735.000000 ns
[trace time] loop 1000 : 52179505.000000 ns
[trace time] loop 1000 : 46154804.000000 ns
[trace time] loop 1000 : 29199636.000000 ns
```
可以看出 thread-based RCU 在有作 partition 下,在 read side 的時間花費較低。而在 update side ,則是兩者大致相同。
:::
---
## Brief Overview of Classic RCU Implementation in Linux Kernel
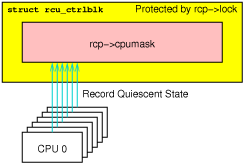
> The key concept behind the Classic RCU implementation is that Classic RCU read-side critical sections are confined to kernel code and are not permitted to block. This means that any time a given CPU is seen either blocking, in the idle loop, or exiting the kernel, we know that all RCU read-side critical sections that were previously running on that CPU must have completed. Such states are called “quiescent states”, and after each CPU has passed through at least one quiescent state, the RCU grace period ends.
>
> 
>
> Classic RCU's most important data structure is the `rcu_ctrlblk` structure, which contains the `->cpumask` field, which contains one bit per CPU. Each CPU's bit is set to one at the beginning of each grace period, and each CPU must clear its bit after it passes through a quiescent state. Because multiple CPUs might want to clear their bits concurrently, which would corrupt the `->cpumask` field, a `->lock` spinlock is used to protect `->cpumask`, preventing any such corruption. Unfortunately, this spinlock can also suffer extreme contention if there are more than a few hundred CPUs, which might soon become quite common if multicore trends continue. Worse yet, the fact that all CPUs must clear their own bit means that CPUs are not permitted to sleep through a grace period, which limits Linux's ability to conserve power.
> Reference: [Hierarchical RCU](https://lwn.net/Articles/305782/)
### RCU API
:::warning
**NOTE** [The RCU API, 2019 edition](https://lwn.net/Articles/777036/)
:::
> The “RCU” column corresponds to the consolidation of the three Linux-kernel RCU implementations, in which RCU read-side critical sections start with `rcu_read_lock()`, `rcu_read_lock_bh()`, or `rcu_read_lock_sched()` and end with `rcu_read_ unlock()`, `rcu_read_unlock_bh()`, or `rcu_read_unlock_sched()`, respectively. Any region of code that disables bottom halves, interrupts, or preemption also acts as an RCU read-side critical section. RCU read-side critical sections may be nested.
>
> The corresponding synchronous update-side primitives, `synchronize_rcu()` and `synchronize_rcu_expedited()`, along with their synonym `synchronize_net()`, wait for any type of currently executing RCU read-side critical sections to complete. The length of this wait is known as a “grace period”, and `synchronize_rcu_expedited()` is designed to reduce grace-period latency at the expense of increased CPU overhead and IPIs.
>
> The asynchronous update-side primitive, `call_rcu()`, invokes a specified function with a specified argument after a subsequent grace period. For example, `call_rcu(p,f)`; will result in the “RCU callback” `f(p)` being invoked after a subsequent grace period. There are situations, such as when unloading a Linux-kernel module that uses `call_rcu()`, when it is necessary to wait for all outstanding RCU callbacks to complete. The `rcu_barrier()` primitive does this job.
> Reference: [Perfbook Section 9.5.3](https://mirrors.edge.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html)
---
## Tree RCU
### Preemptible and Scalability
:::warning
[**The design of preemptible read-copy-update**](https://lwn.net/Articles/253651/) / [**Hierarchical RCU**](https://lwn.net/Articles/305782/)
:::
### 資料結構
> [A Tour Through TREE_RCU’s Data Structures [LWN.net]
](https://www.kernel.org/doc/html/v5.10/RCU/Design/Data-Structures/Data-Structures.html)
### Grace Period with Memory Order guaranteed
> [A Tour Through TREE_RCU’s Grace-Period Memory Ordering](https://www.kernel.org/doc/html/latest/RCU/Design/Memory-Ordering/Tree-RCU-Memory-Ordering.html)
:::warning
```
Centralized Barrier Performance
§ Latency
– Centralized has critical path length at least proportional to p
§ Traffic
– About 3p bus transactions
§ Storage Cost
– Very low: centralized counter and flag
§ Fairness
– Same processor should not always be last to exit barrier – No such bias in centralized
§ Key problems for centralized barrier are latency and traffic
– Especially with distributed memory, traffic goes to same node
Improved Barrier Algorithms for a Bus
– Separate arrival and exit trees, and use sense reversal
– Valuable in distributed network: communicate along different
paths
– On bus, all traffic goes on same bus, and no less total traffic
– Higher latency (log p steps of work, and O(p) serialized bus xactions)
– Advantage on bus is use of ordinary reads/writes instead of
locks
Software combining tree
- Only k processors access the same location, where k is degree of tree
```
:::
### [`struct rcu_head`](https://www.kernel.org/doc/html/latest/RCU/Design/Data-Structures/Data-Structures.html#the-rcu-head-structure)
```cpp
1 struct rcu_head *next;
2 void (*func)(struct rcu_head *head);
```
此結構嵌入至 RCU-protected 結構,用於 asynchronous 的 grace periods 。
> The `->next` field is used to link the `rcu_head` structures together in the lists within the rcu_data structures. The `->func` field is a pointer to the function to be called when the callback is ready to be invoked, and this function is passed a pointer to the `rcu_head` structure. **However, `kfree_rcu()` uses the `->func` field to record the offset of the `rcu_head` structure within the enclosing RCU-protected data structure.**
>
>Both of these fields are used internally by RCU. From the viewpoint of RCU users, this structure is an opaque “cookie”.
### `kfree_rcu()`
```graphviz
digraph main {
rankdir = TB
node [shape = box]
compound = true
kfree_rcu [label = "kfree_rcu()"]
kvfree_rcu [label = "kvfree_rcu(...)"]
subgraph cluster_kvfree_call_rcu {
kvfree_call_rcu [label = "kvfree_call_rcu()" shape = plaintext]
normal [label = "channel 3\nsynchronize_rcu()\nkfree()" shape = plaintext]
rcu_head [label = "channel 2\nno space\nbut have rcu_head\n add to linked list" shape = plaintext]
sched_monitor_work [label = "schedule_delayed_work(...)" shape = plaintext]
}
ptr_bulk [label = "channel 1\nadd_ptr_to_bulk_krc_lock()"]
subgraph cluster_kfree_rcu_monitor {
kfree_rcu_monitor [label = "kfree_rcu_monitor(struct work_struct *work)" shape = plaintext]
krm_channel1 [label = "channel 1\nSLAB-pointer bulk"]
krm_channel2 [label = "channel 2\nvmalloc-pointer bulk"]
krm_channel3 [label = "channel 3\nLinked list"]
commen_work [label = "krwp->bkvhead[i] <- krcp->bkvhead[i]" shape = plaintext]
ch3_work [label = "krwp->head_free <- krcp->head" shape = plaintext]
}
queue_work [label = "queue_rcu_work(system_wq, &krwp->rcu_work);" ]
call_rcu [label = "call_rcu(&rwork->rcu, rcu_work_rcufn)"]
gp [label = "grace period" style = filled color = lightgrey]
rcu_work_rcufn [label = "rcu_work_rcufn()\ncallback function\n"]
__queue_work [label = "__queue_work(WORK_CPU_UNBOUND, rwork->wq, &rwork->work)\nchoose the right pool workqueue"]
insert_work [label = "insert_work()\ninsert work into pool\nthen wake up worker (pool)"]
subgraph cluster_workqueue {
label = "workqueue"
kfree_rcu_work [label = "kfree_rcu_work()\nfrom ->rcu_work"]
}
subgraph cluster_mm {
label = "memory management"
labelloc = b
kmalloc_kfree [label = "kfree_bulk(...)"]
vmalloc_vfree [label = "for_each_bkvhead_record()\ndo vfree(..)"]
ll_vfree [label = "for_each_list()\ndo vfree(...)"]
}
wake_up_worker [label = "wake_up_woker()"]
wake_up_process [label = "wake_up_process(worker->task)"]
kfree_rcu -> kvfree_rcu
kvfree_rcu -> kvfree_call_rcu
kvfree_call_rcu -> ptr_bulk
kvfree_call_rcu -> rcu_head
kvfree_call_rcu -> normal
ptr_bulk -> sched_monitor_work
rcu_head -> sched_monitor_work
sched_monitor_work -> kfree_rcu_monitor
kfree_rcu_monitor -> krm_channel1
kfree_rcu_monitor -> krm_channel2
kfree_rcu_monitor -> krm_channel3
krm_channel1 -> commen_work
krm_channel2 -> commen_work
krm_channel3 -> ch3_work
commen_work -> queue_work
ch3_work -> queue_work
queue_work -> call_rcu
call_rcu -> gp
gp -> rcu_work_rcufn
rcu_work_rcufn -> __queue_work [label = "local_irq_disable()"]
__queue_work -> insert_work
insert_work -> wake_up_worker
wake_up_worker -> wake_up_process
wake_up_process -> kfree_rcu_work [lhead = cluster_workqueue]
kfree_rcu_work -> kmalloc_kfree [label = "kmalloc "]
kfree_rcu_work -> vmalloc_vfree [label = "vmalloc"]
kfree_rcu_work -> ll_vfree [label = "linked list\nrcu_head"]
label = "kfree_rcu() diagram"
}
```
:::warning
**NOTE** `vfree` also use the RCU to free the physical allocation when the reference count is 0.
:::
---
## Rereference Count ( `CONFIG_PREEMPT_RCU` )
> The `->rcu_read_lock_nesting` field records the nesting level for RCU read-side critical sections, and the `->rcu_read_unlock_special` field is a bitmask that records special conditions that require `rcu_read_unlock()` to do additional work. The `->rcu_node_entry` field is used to form lists of tasks that have blocked within preemptible-RCU read-side critical sections and the `->rcu_blocked_node` field references the `rcu_node` structure whose list this task is a member of, or `NULL` if it is not blocked within a preemptible-RCU read-side critical section.
[`rcu_preempt_read_enter`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_plugin.h#L408)
[`__rcu_read_lock`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_plugin.h#L428)
```cpp
static void rcu_preempt_read_enter(void)
{
current->rcu_read_lock_nesting++;
}
/*
* Preemptible RCU implementation for rcu_read_lock().
* Just increment ->rcu_read_lock_nesting, shared state will be updated
* if we block.
*/
void __rcu_read_lock(void)
```
[rcu_read_lock](https://elixir.bootlin.com/linux/latest/source/include/linux/rcupdate.h#L685)
```cpp
static __always_inline void rcu_read_lock(void)
{
__rcu_read_lock();
__acquire(RCU);
rcu_lock_acquire(&rcu_lock_map);
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_lock() used illegally while idle");
}
```
[rcu_preempt_depth](https://elixir.bootlin.com/linux/latest/source/include/linux/rcupdate.h#L56)
```cpp
/*
* Defined as a macro as it is a very low level header included from
* areas that don't even know about current. This gives the rcu_read_lock()
* nesting depth, but makes sense only if CONFIG_PREEMPT_RCU -- in other
* types of kernel builds, the rcu_read_lock() nesting depth is unknowable.
*/
#define rcu_preempt_depth() (current->rcu_read_lock_nesting)
```
[`___might_sleep`](https://elixir.bootlin.com/linux/latest/source/kernel/sched/core.c#L9207)
[`rcu_exp_handler`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_exp.h#L641)
```cpp
/*
* Remote handler for smp_call_function_single(). If there is an
* RCU read-side critical section in effect, request that the
* next rcu_read_unlock() record the quiescent state up the
* ->expmask fields in the rcu_node tree. Otherwise, immediately
* report the quiescent state.
*/
```
[`rcu_note_context_switch`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_plugin.h#L341)
[`rcu_flavor_sched_clock_irq`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_plugin.h#L737)
:::success
**疑問**
如果在 read-side critical section 前 update-side 更新了資料,但在 `synchronize_rcu` 還沒完成前 read-side 進入了 critical section ,`synchronize_rcu` 是否要等待明明是讀新的資料的 reader 離開 critical section ?
```
| read |
| critical |
| section |
read read
lock unlock
| |
-------^-----+-----------+------------->
| |
old | new synchronize_rcu
data | data => wait for old data
|
rcu_assign_pointer
=> update data
```
現存 API 可能以其他形式解決了,或者這是一種 `trade off` :
1. [`void synchronize_rcu_expedited(void)`](https://elixir.bootlin.com/linux/latest/source/kernel/rcu/tree_exp.h#L813)
```cpp
/**
* synchronize_rcu_expedited - Brute-force RCU grace period
*
* Wait for an RCU grace period, but expedite it. The basic idea is to
* IPI all non-idle non-nohz online CPUs. The IPI handler checks whether
* the CPU is in an RCU critical section, and if so, it sets a flag that
* causes the outermost rcu_read_unlock() to report the quiescent state
* for RCU-preempt or asks the scheduler for help for RCU-sched. On the
* other hand, if the CPU is not in an RCU read-side critical section,
* the IPI handler reports the quiescent state immediately.
*
* Although this is a great improvement over previous expedited
* implementations, it is still unfriendly to real-time workloads, so is
* thus not recommended for any sort of common-case code. In fact, if
* you are using synchronize_rcu_expedited() in a loop, please restructure
* your code to batch your updates, and then use a single synchronize_rcu()
* instead.
*
* This has the same semantics as (but is more brutal than) synchronize_rcu().
*/
```
2. `call_rcu()`
:::
---
## Sleepable RCU
> The “SRCU” column in Table 9.1 displays a special- ized RCU API that permits general sleeping in SRCU read-side critical sections delimited by srcu_ read_lock() and srcu_read_unlock(). However, unlike RCU, SRCU’s srcu_read_lock() returns a value that must be passed into the corresponding srcu_read_ unlock(). This difference is due to the fact that the SRCU user allocates an srcu_struct for each distinct SRCU usage. These distinct srcu_struct structures prevent SRCU read-side critical sections from blocking unrelated synchronize_srcu() and synchronize_ srcu_expedited() invocations. Of course, use of either synchronize_srcu() or synchronize_srcu_ expedited() within an SRCU read-side critical section can result in self-deadlock, so should be avoided. As with RCU, SRCU’s synchronize_srcu_expedited() de- creases grace-period latency compared to synchronize_ srcu(), but at the expense of increased CPU overhead.
---
## [Task RCU](https://lwn.net/Articles/607117/)
> The read-copy-update (RCU) mechanism is charged with keeping old versions of data structures around until it knows that no CPU can hold a reference to them; once that happens, the structures can be freed. Recently, though, a potential RCU user came forward with a request for something different: would it be possible to defer the destruction of an old data structure until it is known that no process holds a reference to it? The answer would appear to be "yes," as demonstrated by the RCU-tasks subsystem recently posted by Paul McKenney.
### Normal RCU
> Normal RCU works on data structures that are accessed via a pointer. When an RCU-protected structure must change, the code that maintains that structure starts by making a copy. The changes are made to the copy, then the relevant pointer is changed to point to that new copy. At this point, the old version is inaccessible, but there may be code running that obtained a pointer to it before the change was made. So the old structure cannot yet be freed. Instead, RCU waits until every CPU in the system goes through a context switch (or sits idle). Since the rules for RCU say that references to data structures can only be held in atomic context, the "every CPU has context switched" condition guarantees that no references to an old data structure can be held.
---
## [TREE_RCU’s Expedited Grace Periods](https://www.kernel.org/doc/html/latest/RCU/Design/Expedited-Grace-Periods/Expedited-Grace-Periods.html#rcu-preempt-expedited-grace-periods)
> In earlier implementations, the task requesting the expedited grace period also drove it to completion. This straightforward approach had the disadvantage of needing to account for POSIX signals sent to user tasks, so more recent implemementations use the Linux kernel’s workqueues.
### Mid-boot operation
> The use of workqueues has the advantage that the expedited grace-period code need not worry about POSIX signals. Unfortunately, it has the corresponding disadvantage that workqueues cannot be used until they are initialized, which does not happen until some time after the scheduler spawns the first task. Given that there are parts of the kernel that really do want to execute grace periods during this mid-boot “dead zone”, expedited grace periods must do something else during thie time.
>
> **What they do is to fall back to the old practice of requiring that the requesting task drive the expedited grace period, as was the case before the use of workqueues.** However, the requesting task is only required to drive the grace period during the mid-boot dead zone. Before mid-boot, a synchronous grace period is a no-op. Some time after mid-boot, workqueues are used.
>
> **Non-expedited non-SRCU synchronous grace periods must also operate normally during mid-boot. This is handled by causing non-expedited grace periods to take the expedited code path during mid-boot.**
>
> The current code assumes that there are no POSIX signals during the mid-boot dead zone. However, if an overwhelming need for POSIX signals somehow arises, appropriate adjustments can be made to the expedited stall-warning code. One such adjustment would reinstate the pre-workqueue stall-warning checks, but only during the mid-boot dead zone.
---
## Release the memory via RCU
> [LWN.net RCU 2024 API edition](https://lwn.net/Articles/988638/)
`kfree_rcu()`
- improve cache locality
- handle memory from `kmem_cache_alloc()`
- `rcu_barrier()` doesn't wait for memory beiing free via `kfree_rcu()`
- in this case, use `call_rcu()` instead
- rcu_head must embedded in the data structure
- use `kfree_rcu_mightsleep()` to avoid additional bytes
- Now (2024), single arguement of `kfree_rcu()` is changed to `kfree_rcu_mightsleep()`
- due to people might forget to specify the second argument from atomic context
- There are also kvfree_rcu() and kvfree_rcu_mightsleep() functions that operate on vmalloc() memory.
---
## Polled GP
> More control and information from gp
> [LWN.net RCU 2024 API edition](https://lwn.net/Articles/988638/)
> [LSFMM+BPF 2024: Reclamation Interactions with RCU](https://drive.google.com/file/d/1piN3sUrYJd9CwkY9jXGxPTvbGXwT-qvG/view)
> In recent Linux kernels, RCU instead provides a complete polling API for managing RCU grace periods. This permits RCU users to take full control over all aspects of waiting for grace periods and responding to the end of a particular grace period. For example, the get_state_synchronize_rcu() function returns a cookie that can be passed to poll_state_synchronize_rcu(). This latter function will return true if a grace period has elapsed in the meantime.
```cpp
/* Get GP cookie. */
cookie = get_state_synchronize_rcu();
do {
/* Do other work. */
} while (!poll_state_synchronize_rcu(cookie));
/* RCU GP is done. */
do_cleanup();
```

---
## Others
### [Non-maskable interrupt](https://en.wikipedia.org/wiki/Non-maskable_interrupt)
> In computing, a non-maskable interrupt (NMI) is a hardware interrupt that standard interrupt-masking techniques in the system cannot ignore. It typically occurs to signal attention for non-recoverable hardware errors. Some NMIs may be masked, but only by using proprietary methods specific to the particular NMI.
- [LWN.net RCU 2024 API edition](https://lwn.net/Articles/988638/)
> SRCU read-side critical sections use this_cpu_inc(), which excludes interrupt and software-interrupt handlers, but is not guaranteed to exclude non-maskable interrupt (NMI) handlers. Therefore, SRCU read-side critical sections may not be used in NMI handlers, at least not in portable code. This restriction became problematic for printk(), which is frequently called upon to do stack backtraces from NMI handlers. This situation motivated adding srcu_read_lock_nmisafe() and srcu_read_unlock_nmisafe(). These new API members instead use atomic_long_inc(), which can be more expensive than this_cpu_inc(), but which does exclude NMI handlers.
>
> **However, SRCU will complain if you use both the traditional and the NMI-safe API members on the same srcu_struct structure.** In theory, it is possible to mix and match but, in practice, the rules for safely doing so are not consistent with good software-engineering practice.
### Completion
> [source code](https://elixir.bootlin.com/linux/latest/source/include/linux/completion.h#L26)
```cpp
/*
* struct completion - structure used to maintain state for a "completion"
*
* This is the opaque structure used to maintain the state for a "completion".
* Completions currently use a FIFO to queue threads that have to wait for
* the "completion" event.
*
* See also: complete(), wait_for_completion() (and friends _timeout,
* _interruptible, _interruptible_timeout, and _killable), init_completion(),
* reinit_completion(), and macros DECLARE_COMPLETION(),
* DECLARE_COMPLETION_ONSTACK().
*/
```
---
## 相關資料
* [The RCU API, 2019 edition](https://lwn.net/Articles/777036/)
* [Userspace RCU](https://liburcu.org/)
* [User-space RCU](https://lwn.net/Articles/573424/)
* [Facebook folly - Rcu](https://github.com/facebook/folly/blob/main/folly/synchronization/Rcu.h)
* [Linux kernel Documentation - RCU](https://www.kernel.org/doc/Documentation/RCU/)
* [A Tour Through RCU's Requirements](https://www.kernel.org/doc/Documentation/RCU/Design/Requirements/Requirements.html)
* [Sleepable RCU](https://lwn.net/Articles/202847/)
* [What is RCU? – “Read, Copy, Update”](https://www.kernel.org/doc/html/latest/RCU/whatisRCU.html)
* [So You Want to Rust the Linux Kernel?](https://paulmck.livejournal.com/62436.html)
* [Introduction to RCU](http://www2.rdrop.com/users/paulmck/RCU/)
* [Completions - “wait for completion” barrier APIs](https://www.kernel.org/doc/html/latest/scheduler/completion.html)
* [User-space RCU](https://lwn.net/Articles/573424/)
* signal-based
* interrupt-based
* [So What Has RCU Done Lately? (2023)](https://www.youtube.com/watch?v=9rNVyyPjoC4)
* [HackMD: So What Has RCU Done Lately? (2023)](https://hackmd.io/@cccccs100203/So-What-Has-RCU-Done-Lately#Lazy-RCU-Callbacks)
* [[PATCH v6 0/4] rcu: call_rcu() power improvements](https://lore.kernel.org/all/20220922220104.2446868-1-joel@joelfernandes.org/T/#u)
* [[PATCH 1/1] Reduce synchronize_rcu() waiting time](https://lore.kernel.org/lkml/20230321102748.127923-1-urezki@gmail.com/)
* [Why RCU Should be in C++26, IEEE 2023](https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2023/p2545r2.pdf)
* [RCU Usage In the Linux Kernel: Eighteen Years Later, SIGOPS'20](https://dl.acm.org/doi/10.1145/3421473.3421481)
## Plmck
- [Unraveling Fence & RCU Mysteries, Paul E. McKenney, Meta Platforms Kernel Team, CPP-Summit, September 28, 2022](https://drive.google.com/file/d/143W28Yg_oRY1CwCrFGtKdk2QQSV5io2b/view)
- [User-Level Implementations of Read-Copy Update, IEEE book](https://www.computer.org/csdl/journal/td/2012/02/ttd2012020375/13rRUxjQybC)
- [Supplementary Material for User-Level Implementations of Read-Copy Update](http://www.rdrop.com/users/paulmck/RCU/urcu-supp-accepted.2011.08.30a.pdf)
- [User-Level Implementations of Read-Copy Update](https://www.efficios.com/pub/rcu/urcu-main.pdf)
- [Stupid RCU Tricks: Is RCU Watching?](https://paulmck.livejournal.com/67073.html)
- [Stupid RCU Tricks: How Read-Intensive is The Kernel's Use of RCU?](https://paulmck.livejournal.com/67547.html)
- [Stupid SMP Tricks: A Review of Locking Engineering Principles and Hierarchy](https://paulmck.livejournal.com/67832.html)
- [Confessions of a Recovering Proprietary Programmer, Part XIX: Concurrent Computational Models](https://paulmck.livejournal.com/67992.html)
- [Stupid RCU Tricks: So You Want To Add Kernel-Boot Parameters Behind rcutorture's Back?](https://paulmck.livejournal.com/69158.html#cutid1)
- [Google Doc: Introduction to RCU](https://docs.google.com/document/d/1X0lThx8OK0ZgLMqVoXiR4ZrGURHrXK6NyLRbeXe3Xac/edit)
- [Unraveling RCU-Usage Mysteries (Fundamentals), 2021](https://www.linuxfoundation.org/webinars/unraveling-rcu-usage-mysteries)
- [Unraveling RCU-Usage Mysteries (Additional Use Cases), 2022](https://www.linuxfoundation.org/webinars/unraveling-rcu-usage-mysteries-additional-use-cases)
- [LPC 2023 - Hunting Heisenbugs](https://lpc.events/event/17/contributions/1504/)
## Rust with RCU
- [So You Want to Rust the Linux Kernel?](https://paulmck.livejournal.com/62436.html)
## RCU 2024 API edition
- [LWN](https://lwn.net/Articles/988638/)
- [RCU update 2024 background material](https://lwn.net/Articles/988641/)
---
## Related paper
https://people.mpi-sws.org/~michalis/papers/spin2017-rcu.pdf
---
## Hazard pointer
[LPC 2024 slide](https://lpc.events/event/18/contributions/1731/attachments/1469/3113/Hazard%20pointers%20in%20Linux%20kernel.pdf)
[Patch](https://lore.kernel.org/lkml/20240917143402.930114-1-boqun.feng@gmail.com/)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet