## NLP自然語言處理
---
## NLP可以拿來幹嘛,可以吃嗎?

----
### 前處理
* part-of-Speech(POS)Tagging (詞性標記)
* word segmentation
* Parsing (產生樹狀結構)
* Constituency Parsing
* Dependency Parsing
* Coreference Resolution(指代消解)
----
### NLP功能
* Summarization(摘要)
* Extractive Summarization
* Abstractive Summarization
* Sentiment Classification (情緒分類)
* Sentiment Detection (立場分析)
* Veracity Prediction (事實真測)
* Natural Language Inference (NLI)
* Question Answering (QA)
* Dialogue
* chatting (E.g. cleverbot)
* Task-oriented (任務導向)
----
* Natural Language Ubderstanding
* Intent Classification
* Slot Filling
* Knowledge Graph
* Name Entity Recognition (NER)
* Relation Extraction
https://www.youtube.com/watch?v=tFBrqPPxWzE&list=PLJV_el3uVTsO07RpBYFsXg-bN5Lu0nhdG&index=17
---
## 極簡易情感分類器 Naive Bayes
----
### Bag of words
1. 每篇文章/評論,會用一個一維的vector來表示,每個vector的長度就是全部詞彙的總數(有點抽象沒關係,等等會有程式碼來幫你釐清觀念)
2. 文字之間的順序在詞袋之中無法被保存。
3. 文字之間的「意義」沒有被保存,「貓」和「狗」以及「貓」和「飛機」,貓和狗應該是較為相似的,但在詞袋之中也沒辦法體現這種「距離」的概念(到下一篇word-embedding就會提到解決方法)。
----
### Bag of words

----
### Naive Bayes Classifier
* 貝氏定理: $P(A|B)=\dfrac{P(B|A)P(A)}{P(B)}$

###### P(正面 | 這): 在出現”這”以後,影評是”正面”的條件機率
###### P(正面 | 一部): 在出現”一部”以後,影評是”正面”的條件機率
----
### Naive Bayes Classifier
* P(正面 |我覺得這部電影真的很好看) = P(正面 | 我) * P(正面 | 覺得) * P(正面 | 這部) * P(正面 | 電影) * P(正面 | 真的) * P(正面 | 很) * P(正面 | 好看)
1. smoothing(確認字/詞在出現過n次)
3. 去除stop words
4. underflow
1. 因為機率介於0,1之間,如果文本很長,很容易造成數值太小的問題

----
### 分類器
* Naive bayes Classifier
* Base Classifier
* Decision Tree Classifier
* MaxEnt Classifier
---
## 怎麼做到自然語言處理
1. 電腦怎麼讀懂一個"詞"*(透過編碼)*
2. 編碼是怎麼產生的
3. 目標怎麼達成(了解輸入輸出的格式)
----
### 電腦怎麼讀懂一個"詞"
* 對單詞的解讀
* 1-of-N Encoding(E.g. Bag-of-words)
* Word Class
* Word Embedding
E.g.「錢,不是問題」、「不,錢是問題」會被轉換成完全相同的 vector。
* 連結上下文,對於單詞的解讀 (Contextualized Word Embedding)
* word type
* word token
----
### 對單詞的解讀

----
### 編碼是怎麼產生的
* RNN(卷積神經網路)
* LSTM
* self-attention
* Transformer
----
* 神經網路

----
#### RNN(遞迴神經網路)
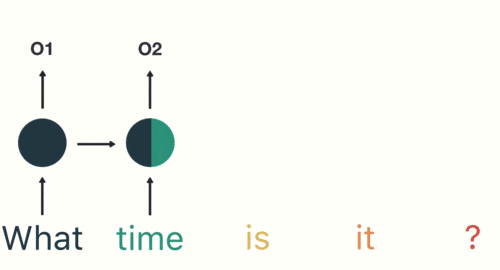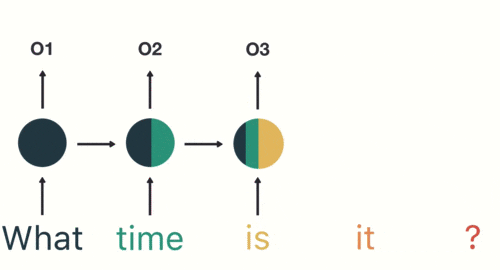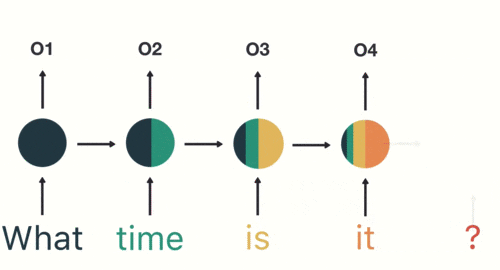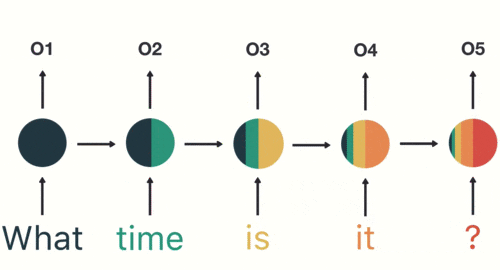
----
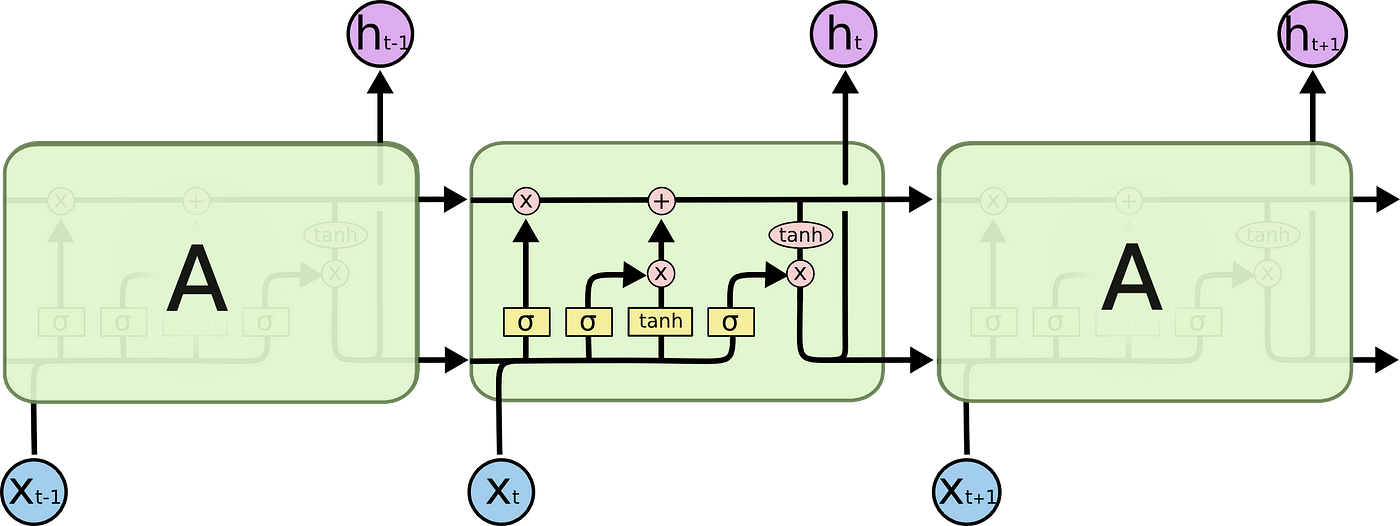
#### LSTM 長短期記憶模型
----
#### self-attention

----

----

----
### 目標怎麼達成(了解輸入輸出的格式)
1. 單一句子**分類**任務(E.g. 情感分析)
2. 單一句子**標數**任務(E.g. 詞性標記)
3. 成對句子**分類**任務(E.g. 自然語言推理)
4. 問答任務
---
## BERT ~~與他的朋友們~~

----
### 朋友們~~~

----
### Pre-training

----
### Fine-tuning

----
### ELMO(Embeddings from Language Models)訓練方法

----
### ELMO(Embeddings from Language Models)訓練方法

----
### BERT訓練方法
[CLS]:在做分類任務時其最後一層的 repr. 會被視為整個輸入序列的 repr.
[SEP]:有兩個句子的文本會被串接成一個輸入序列,並在兩句之間插入這個 token 以做區隔
[UNK]:沒出現在 BERT 字典裡頭的字會被這個 token 取代
[MASK]:未知遮罩,僅在預訓練階段會用到
----
### BERT訓練方法
* Encoder of Transformer

----
### BERT 實際運用

{"metaMigratedAt":"2023-06-15T08:59:05.049Z","metaMigratedFrom":"YAML","title":"NLP簡報","breaks":true,"slideOptions":"{\"theme\":\"white\",\"transition\":\"fade\",\"slideNumber\":true,\"spotlight\":{\"enabled\":true}}","contributors":"[{\"id\":\"128398da-3a37-4e61-bde0-e5f4c00bef33\",\"add\":10001,\"del\":6341}]"}