## Setup
- 使用 llama2
## RAG

### Text Embedding
* [Text Embedding model](https://python.langchain.com/docs/modules/data_connection/text_embedding/)
* [What is Text Embedding](https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/)
---
- 詞嵌入只是單單把要輸入的文本或句子轉為向量嗎?
- 不僅是轉換成能用數字表達的矩陣表示法
- 其中的數值牽涉到文本的語意
---
- 文本的轉換後的樣式都是單一向量嗎?
- 有很多種形式,要看使用的 model
- 都是高密度的向量,會根據上下文來生成
---
- 著名的模型:
- Word2Vec
- 生成維度較低的向量
- 每個詞在不同的句子中,具有相同的詞嵌入(靜態生成)
- 只關注上下幾個詞,不能捕捉完整的句意
- BERT
- 生成高維度向量
- 每個詞在不同的句子中,具有不同的詞嵌入(動態生成)
- 根據整個句子的意思產生詞嵌入,能處理複雜的上下文
---
### [Vector stores](https://python.langchain.com/docs/modules/data_connection/vectorstores/)
- What is Vector store ?
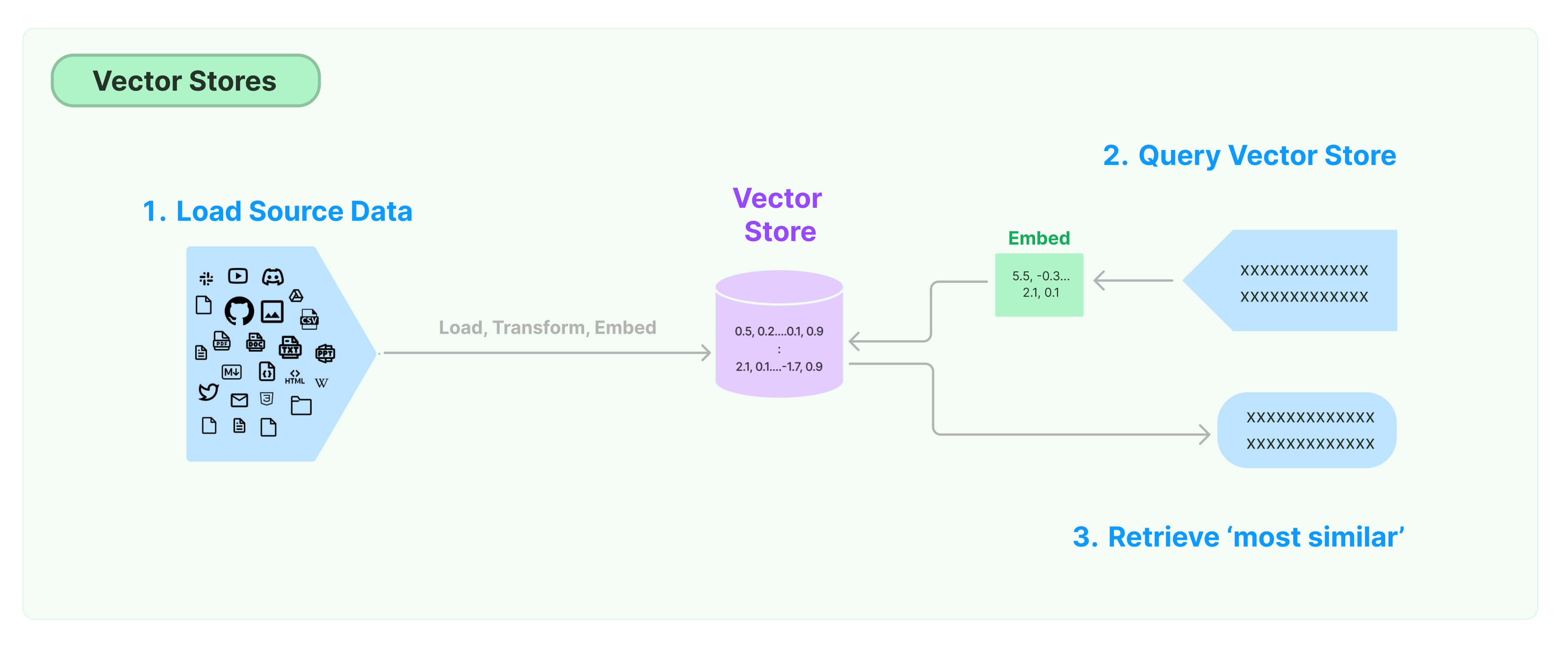
- 在前面我們透過 tranformer model 把文本轉換成 Embeddings 後,需要一個存放他們的地方
- Vector store 就是用來存放詞嵌入的 database,並提供相似文檔檢索的功能
---
- 使用流程
- Create a Vector store
```python
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_chroma import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
```
- 詞分割:
- 先把大型的文檔分割成多個組塊,因為 Embedding model 有 token 上限
- chunk_overlap:設定組塊之間重疊的詞語的數量,確保完整的句子不會被分割在不同組塊之間
- 存入 Vector store (Chroma)
- documents 要存入的文檔
- OpenAIEmbeddings():當 from_documents 被呼叫時,會先使用 OpenAI 的 model 做 Text Embedding,然後再存入 Vector store
- Similarity search
- By string
```python=
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
```
- By vector
```python=
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
```
---
- Asynchronous operations : 因為文本輸入跟檢索可能需要花較長的處理時間 -> 支援非同步的方法
- Maximum marginal relevance search (MMR):透過檢索多個與輸入文本相關的詞嵌入,先選出 fetch_k 個,最後提供最相似的 k 個
```pyhoon!
query = "What did the president say about Ketanji Brown Jackson"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")
```
---
### [Retrievers](https://python.langchain.com/docs/modules/data_connection/retrievers/)
- What is Retrievers ?
- based on Vector store 建立的一個接收input(文本)的模組,會回傳包含一個或多個相似文本的 documents
- 流程
- 建立一個 prompt 的模板 & document_chain
```python
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
```
- context : 跟 input 相關的上下文
- create_stuff_documents_chain 把 llm 與 prompt 串接成一個 documents_chain 可以透過 invoke() 來觸發
---
- 手動輸入 context
```python!
from langchain_core.documents import Document
document_chain.invoke({
"input": "how can langsmith help with testing?",
"context": [Document(page_content="langsmith can let you visualize test results")]
})
```
- 為什麼要使用 Retriever ?
- 因為使用者並不知道上下文 -> 透過 Retriever 對 vector store 做 Similarity search 產生 context
```python
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
```
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet