# TCP/IP 學習筆記
資工二 李易 111010512
## netstat
`netstat`是一個基於命令列介面的網路實用工具,可顯示當前的網路狀態,包括傳輸控制協定層的連線狀況、路由表、網路介面狀態和網路協定的統計資訊等。`netstat`命令適用於類Unix系統(如macOS、Linux、Solaris和BSD)、IBM OS/2和Windows NT作業系統家族(如Windows XP、Windows Vista、Windows 7、Windows 8和Windows 10)。
`netstat`可用於尋找網路中的問題,並可通過計算網路流量來度量網路效能。儘管該工具仍然被包含在許多Linux發行版中,但基本都被看作過時、應被替代的工具。
在Linux上,推薦使用`ss`替代`netstat`,使用`ip route`替代`netstat -r`,使用`ip -s link`替代`netstat -i`,使用`ip maddr`替代`netstat -g`。
### 命令參數
命令netstat的參數必須以連字元(-)而非斜槓(/)為字首。並非所有平台都支援某些參數。
```
-a 顯示所有活動中的網路連接和電腦正在監聽的TCP/UDP埠。
-b 顯示每個應用程式所使用的網路連接和監聽埠 。(僅適用於Windows XP、Windows Server 2003或更高版本的Microsoft Windows作業系統,Windows 2000或更早版本不可用。)
-b 同-i,但計算網路流量的總位元組數。
-e 顯示乙太網路統計資訊,例如傳送和接收的位元組數及封包數。此參數可以與-s組合使用。
-f 顯示外部位址的完整網域名稱。(僅適用於Windows Vista和更高版本的Microsoft Windows作業系統。)
-f 限定顯示使用特定通訊端(unix、inet、inet6)的位址族。
-g 顯示多播組資訊。(可能僅適用於較新的作業系統。)
-i 顯示網路介面及統計資訊。
-m 顯示隨機存取記憶體統計資訊。
-n 顯示活動中的TCP連接,但主機位址和埠號以數字形式表示,不會嘗試確定實際主機名。
-o 顯示活動中的TCP連接,並包含每個連接的行程ID(PID)。根據PID,可在Windows工作管理員的「行程」索引標籤中找到該應用程式。此參數可以與-a、-n和-p組合使用。如果安裝了Windows修補程式,則此參數在Windows XP、Windows Server 2003和Windows 2000上可用。
-p 顯示使用指定網路協定的連接。協定可以是TCP、UDP、TCPv6或UDPv6。如果此參數與-s組合使用,則協定可以是TCP、UDP、ICMP、IP、TCPv6、UDPv6、ICMPv6或IPv6。
-p 顯示哪些行程正在使用哪些網路介面,類似於Microsoft Windows下的-b。(需要root權限才能執行此操作。)
-P 顯示使用指定網路協定的連接。協定可以是IP、IPv6、ICMP、ICMPv6、IGMP、UDP、TCP或RawIP。
-r 顯示路由表內容,與Microsoft Windows下route print命令相同。
-s 按網路協定顯示統計資訊。預設情況下,顯示TCP、UDP、ICMP和IP協定的統計資訊。如果Windows XP安裝了IPv6協定,亦可以顯示TCPv6、UDPv6、ICMPv6和IPv6協定的統計資訊。-p參數可用於指定一組協定。
-t 僅顯示TCP連接。
-u 僅顯示UDP連接。
-W 顯示完整主機名或IPv6位址。
-v 與-b組合使用時,將顯示所有應用程式使用的網路連接和監聽埠所涉及的組件列表。
-h 顯示該命令的提示。
-? 顯示該命令的提示。
/? 顯示該命令的提示。
```
### 命令範例
要僅顯示TCP或UDP協定的統計資訊,請鍵入以下命令之一:
```
netstat -sp tcp
netstat -sp udp
```
#### 類Unix系統:
* 顯示行程ID為「pid」的行程打開的所有埠:
```
netstat -aop | grep "pid"
```
* 持續更新活動中的TCP和UDP連接,但主機位址和埠號以數字形式表示,並顯示哪些行程正在使用這些連接:
```
sudo netstat -nutpacw
```
#### Microsoft Windows:
* 顯示活動的TCP連接和關聯的行程ID,每5秒為一個更新周期(僅適用於基於Windows NT的作業系統或裝有修補程式的Windows 2000):
```
netstat -o 5
```
* 顯示活動中的TCP連接和關聯的行程ID,但主機位址和埠號以數字形式表示(僅適用於基於Windows NT的作業系統或裝有修補程式的Windows 2000):
```
netstat -no
```
### 應用(類UNIX系統)
```
netstat -a 顯示所有埠(無論被監聽或不被監聽)、所有網路協定的連接。
netstat -at 僅顯示TCP連接。
netstat -au 僅顯示UDP連接。
netstat -ant 顯示所有TCP連接,但不進行域名解析(即顯示IP位址而不顯示主機名)。
netstat -al 顯示所有被監聽的埠。
sudo netstat -aep 同時顯示每個埠相關的行程和行程ID(需要root權限以執行此命令)。
netstat -s > wiki.txt 輸出當前電腦網路統計資訊到文字檔案wiki.txt。
netstat -r 顯示路由表。與route -e的輸出結果相同。
netstat -i 顯示所有網路介面。netstat -i -e與ipconfig的輸出結果類似。
netstat -ct 顯示TCP連接(持續更新)。
netstat -g 顯示多播組資訊。
netstat -lntu 顯示所有監聽埠的守護行程和本地電腦上所有空閒的開放埠。
netstat -atnp | grep ESTA 顯示所有狀態為ESTABLISHED的TCP連接。
```
## NAT
**網絡地址轉換(英語:Network Address Translation,縮寫:NAT,又稱網絡掩蔽、IP掩蔽)**,在計算機網絡中是一種在IP封包通過路由器或防火牆時重寫來源IP地址或目的IP地址的技術。
這種技術被普遍使用在有多台主機但只通過一個公有IP地址訪問網際網路的私有網絡中。它是一個方便且得到了廣泛應用的技術。當然,NAT也讓主機之間的通信變得複雜,導致了通信效率的降低。
#### 好處:
* 完美地解決了IP地址不足的問題
* 有效地避免來自網絡外部的攻擊
* 隱藏並保護網絡內部的計算機
* 實現TCP流量的負載均衡
而除了上述這些,NAT還可以再進一步分成:**SNAT**、**DNAT**、**NAPT**。
### SNAT
**源地址轉換(英語:Source Network Address Translation,縮寫:SNAT)**,其作用是將ip數據包的源地址轉換成另外一個地址。
假設區域網路主機A(192.168.2.8)要和外網主機B(61.132.62.131)通信,A向B發出IP數據包,如果沒有SNAT對A主機進行源地址轉換,A與B主機的通訊會不正常中斷,因為當路由器將區域網路的數據包發到公網IP後,公網IP會給你的私網IP回數據包,這時,公網IP根本就無法知道你的私網IP應該如何走了。
為了實現數據包的正確傳送及返回,網關必須將A的址轉換為一個合法的公網地址,同時為了以後B主機能將數據包傳送給A,這個合法的公網地址必須是網關的外網地址,如果是其它公網地址的話,B會把數據包傳送到其它網關,而不是A主機所在的網關,A將收不到B發過來的數據包,所以區域網路主機要上公網就必須要有合法的公網地址。
而得到這個地址的方法就是讓網關進行SNAT(源地址轉換),將區域網路地址轉換成公網址(一般是網關的外部地址),所以大家經常會看到為了讓區域網路用戶上公網,我們必須在RouterOS的firewall中設定snat,俗稱ip地址欺騙或偽裝(masquerade)。
### DNAT
**目的地址轉換(英語:Destination Network Address Translation,縮寫:DNAT)**,常用於防火牆中,其作用是將一組本地內部的地址映射到一組全球地址。
通常來說,合法地址的數量比起本地內部的地址數量來要少得多。RFC1918中的地址保留可以用地址重疊的方式來達到。當一個內部主機第一次放出的數據包通過防火牆時,動態NAT的實現方式與靜態NAT相同,然後這次NAT就以表的形式保留在防火牆中。
除非由於某種個原因會引起這次NAT的結束,否則這次NAT就一直保留在防火牆中。引起NAT結束最常見的原因就是發出連線的主機在預定的時間內一直沒有回響,這時空閒計時器就會從表中刪除該主機的NAT。
### NAPT
**網路位址埠轉換(英語:Network Address Port Transfer,縮寫:NAPT,又稱PAT、內網路由器、FW)**,結合了運輸層的埠,用於區分不同的主機。
這種技術曾遭到一些人的批評,認為NAPT沒有嚴格按照層間關係,去使用了運輸層的東西。但是儘管如此,NAPT和NAT都成了網際網路的重要構件。
**NAPT轉換表:**

## DNS
**網域名稱系統(英語:Domain Name System,縮寫:DNS)**,是網際網路的一項服務。它作為將域名和IP位址相互對映的一個分散式資料庫,能夠使人更方便地存取網際網路。DNS使用TCP和UDP埠53。當前,對於每一級域名長度的限制是63個字元,域名總長度則不能超過253個字元。
開始時,域名的字元僅限於ASCII字元的一個子集。2008年,ICANN通過一項決議,允許使用其它語言作為網際網路頂級域名的字元。使用基於Punycode碼的IDNA系統,可以將Unicode字串對映為有效的DNS字元集。因此,諸如「XXX.中國」、「XXX.台灣」的域名可以在網址列直接輸入並存取,而不需要安裝外掛程式。但是,由於英語的廣泛使用,使用其他語言字元作為域名會產生多種問題,例如難以輸入、難以在國際推廣等。
### 歷史
DNS最早於1983年由保羅·莫卡派喬斯(Paul Mockapetris)發明;原始的技術規範在882號網際網路標準草案(RFC 882)中發布。1987年發布的第1034和1035號草案修正了DNS技術規範,並廢除了之前的第882和883號草案。在此之後對網際網路標準草案的修改基本上沒有涉及到DNS技術規範部分的改動。
早期的域名必須以英文句號`.`結尾。例如,當使用者存取HTTP服務時必須在網址列中輸入:`http://www.wikipedia.org`.,這樣DNS才能夠進行域名解析。如今DNS伺服器已經可以自動補上結尾的句號。
### 記錄類型
DNS系統中,常見的資源記錄類型有:
* 主機記錄(A記錄):RFC 1035定義,A記錄是用於名稱解析的重要記錄,它將特定的主機名對映到對應主機的IP位址上。
* 別名記錄(CNAME記錄): RFC 1035定義,CNAME記錄用於將某個別名指向到某個A記錄上,這樣就不需要再為某個新名字另外建立一條新的A記錄。
* IPv6主機記錄(AAAA記錄): RFC 3596定義,與A記錄對應,用於將特定的主機名對映到一個主機的IPv6位址。
* 服務位置記錄(SRV記錄): RFC 2782定義,用於定義提供特定服務的伺服器的位置,如主機(hostname),埠(port number)等。
* 域名伺服器記錄(NS記錄) :用來指定該域名由哪個DNS伺服器來進行解析。 您註冊域名時,總有預設的DNS伺服器,每個註冊的域名都是由一個DNS域名伺服器來進行解析的,DNS伺服器NS記錄位址一般以以下的形式出現: ns1.domain.com、ns2.domain.com等。 簡單的說,NS記錄是指定由哪個DNS伺服器解析你的域名。
* NAPTR記錄:RFC 3403定義,它提供了正規表示式方式去對映一個域名。NAPTR記錄非常著名的一個應用是用於ENUM查詢。
### 技術實現
#### 概述
DNS通過允許一個名稱伺服器把它的一部分名稱服務(眾所周知的zone)「委託」給子伺服器而實現了一種階層的名稱空間。此外,DNS還提供了一些額外的資訊,例如系統別名、聯絡資訊以及哪一個主機正在充當系統組或域的郵件樞紐。
任何一個使用IP的電腦網路可以使用DNS來實現它自己的私有名稱系統。儘管如此,當提到在公共的Internet DNS系統上實現的域名時,術語「域名」是最常使用的。
這是基於984個全球範圍的「根域名伺服器」(分成13組,分別編號為A至M)。從這984個根伺服器開始,餘下的Internet DNS命名空間被委託給其他的DNS伺服器,這些伺服器提供DNS名稱空間中的特定部分。
#### 軟體
DNS系統是由各式各樣的DNS軟體所驅動的,例如:
* BIND(Berkeley Internet Name Domain),使用最廣的DNS軟體
* DJBDNS(Dan J Bernstein's DNS implementation)
* MaraDNS
* Name Server Daemon(Name Server Daemon)
* PowerDNS
* Dnsmasq
#### 國際化域名
Punycode是一個根據RFC 3492標準而製定的編碼系統,主要用於把域名從地方語言所採用的Unicode編碼轉換成為可用於DNS系統的編碼。而該編碼是根據域名相異字表 (頁面存檔備份,存於網際網路檔案館)(由IANA制定),Punycode可以防止所謂的IDN欺騙。
#### 域名解析
舉一個例子,*zh.wikipedia.org* 作為一個域名就和IP位址*198.35.26.96* 相對應。DNS就像是一個自動的電話號碼簿,我們可以直接撥打*198.35.26.96* 的名字*zh.wikipedia.org* 來代替電話號碼(IP位址)。DNS在我們直接呼叫網站的名字以後就會將像*zh.wikipedia.org* 一樣便於人類使用的名字轉化成像*198.35.26.96* 一樣便於機器辨識的IP位址。
DNS查詢有兩種方式:遞迴和迭代。DNS客戶端設定使用的DNS伺服器一般都是遞迴伺服器,它負責全權處理客戶端的DNS查詢請求,直到返回最終結果。而DNS伺服器之間一般採用迭代查詢方式。
以查詢 zh.wikipedia.org 為例:
* 客戶端傳送查詢報文"query zh.wikipedia.org"至DNS伺服器,DNS伺服器首先檢查自身快取,如果存在記錄則直接返回結果。
* 如果記錄老化或不存在,則:
1. DNS伺服器向根域名伺服器傳送查詢報文"query zh.wikipedia.org",根域名伺服器返回頂級域 .org 的頂級域名伺服器位址。
2. DNS伺服器向 .org 域的頂級域名伺服器傳送查詢報文"query zh.wikipedia.org",得到二級域 .wikipedia.org 的權威域名伺服器位址。
3. DNS伺服器向 .wikipedia.org 域的權威域名伺服器傳送查詢報文"query zh.wikipedia.org",得到主機 zh 的A記錄,存入自身快取並返回給客戶端。
#### WHOIS(域名資料庫查詢)
一個域名的所有者可以通過查詢WHOIS資料庫而被找到;對於大多數根域名伺服器,基本的WHOIS由ICANN維護,而WHOIS的細節則由控制那個域的域序號產生器構維護。
對於240多個國家代碼頂級域名(ccTLDs),通常由該域名權威序號產生器構負責維護WHOIS。例如中國互聯網絡信息中心(China Internet Network Information Center)負責.CN域名的WHOIS維護,香港互聯網註冊管理有限公司(Hong Kong Internet Registration Corporation Limited)負責.HK域名的WHOIS維護,台灣網路資訊中心(Taiwan Network Information Center)負責.TW域名的WHOIS維護。
### /etc/resolv.conf
此檔案位在Linux系統內,可用來設定 DNS 用戶端要求名稱解析時,所定義的各項內容。我們分別來看一個完整的resolv.conf的檔案:
```
domain twnic.com.tw
nameserver 192.168.10.1
nameserver 192.168.2.5
search twnic.com.tw twnic.net.tw
```
* “domain”指定本地的網域名稱,如果查詢時的名稱沒有包含小數點,則會自動補上此處的網域名稱為字尾再送給DNS伺服器。
* “nameserver”指定用戶端要求進行名稱解析的 nameserver IP位址,在此可指定多部DNS伺服器,則用戶端將會依序提出查詢要求。
* “search”這個選項為非必要選項,而功能在於若使用者指定主機名稱查詢時,所需要搜尋的網域名稱。例如,當我們設 “search twnic.com.tw”時,當DNS伺服器在做名稱解析過程中,無法對輸入的名稱,例如pc1,找出相對應的IP時,則DNS會利用search的設定值加上需查詢的名稱,即pc1.twnic.com.tw來進行解析,解析失敗時則會嘗試pc1.twnic.net.tw。
* 需要注意的是當我們想嘗試多種在沒有包含小數點,於字尾補上所需要搜尋的網域名稱時,我們會在"search"中指定幾種組合給DNS伺服器,而不能在"domain"中指定。因為“domain”是指定本地的網域名稱,而搜尋時也以“domain”為優先嘗試,如果失敗之後才會嘗試"search"中的組合。
### 其他
此外,一些駭客通過偽造DNS伺服器將使用者引向錯誤網站,以達到竊取使用者隱私資訊的目的。
## DDNS
**動態DNS(英語:Dynamic DNS,簡稱DDNS)**,是域名系統(DNS)中的一種自動更新名稱伺服器(Name server)內容的技術。根據網際網路的域名訂立規則,域名必須跟從固定的IP位址。但動態DNS系統為動態網域提供一個固定的名稱伺服器(Name server),透過即時更新,使外界使用者能夠連上動態使用者的網址。
這個術語被用來描述兩種不同的概念。在網際網路的管理層面來說,動態DNS更新是指建立一個DNS系統,能夠自動更新傳統的DNS記錄,而不需要手動編輯。這個機制在RFC 2136中被解釋,利用TSIG機制來提供安全性。
在使用者端來說,動態DNS提供了一個輕量化機制,讓本地DNS資料庫可以即時的更新。它能把網際網路域名指往一個可能經常改變的IP位址,讓經常改變位置及組態的裝置,能夠持續性的更新IP位址。令網際網路上的外界使用者可以透過一個大家知道的域名,連接到一個可能經常動態改變IP位址的機器。其中一個常用的用途是在使用動態IP位址連線(例如在每次接通連線就會被分配一個新的IP位址的撥號連線,或是偶爾會被ISP變更IP位址的DSL連線等)的電腦上運行伺服器軟體。
若要實現動態DNS,就需要將網域的「最大快取時間」設定在一個非常短的時間(一般為數分鐘)。此舉可避免外界使用者在快取中保留了舊的IP位址,並且使每個新連線被建立時都會經過Name Server取得該機器的新位址。
各種機構都有大規模地提供動態DNS的服務。他們會利用資料庫儲存使用者當前的IP位址,並會對使用者提供更新當前IP位址的方法。當一些"客戶"程式被安裝了之後,會在後台執行並每隔數分鐘檢查電腦的IP位址。當發現其IP位址有所變更,程式便會送出一個更新IP位址的請求至動態DNS的伺服器。有很多路由器和其他網路裝置也在其韌體中包含了上述的功能。
## IPv4 標頭
IP 封包的組成部份,以及各部件的長度:

事實上,真正的封包是由連續的位元依序排列在一起的,之所以分行,完全是因為排版的關係。
> ### Version
>
> 版本 (VER)。表示的是IP規格版本,目前的 IP 規格多為版本4 (version 4),所以這裡的數值通常為0x4 (注意:封包使用的數字通常都是十六進位的)。
> ### Internet Header Length
>
> 標頭長度 (IHL)。
> 從 IP 封包規格中看到前面的6行為header,如果Options和Padding沒有設定的話,也就只有5行的長度;每行有32bit;也就是4byte;那麼,5列就是20byte了。20這個數值換成16進位就成了0x14所以。當封包標頭長度為最短的時候,這裡數值會被換算為0x14。
> ### Type of Service
>
> 服務類型 (TOS)。這裡指的是IP封包在傳送過程中要求的服務類型,其中一共由8個bit組成,每組bit組合分別代表不同的意思:
> 內容為『RRRDTRUU』:
> RRR:Routine。設定IP順序,預設為0,否則,數值越高越優先
> D:若為0表示一般延遲(delay),若為1表示為低延遲;
> T:Throughput。若為0表示為一般傳輸量 (throughput),若為1表示為高傳輸量。
> R:Reliability。若為 0 表示為一般可靠度(reliability),若為 1 表示高可靠度。
> UU:Not Used。保留尚未被使用。
> ### Total Length
>
> 封包總長(TL)。以byte做單位來表示該封包的總長度,此數值包括標頭和數據的總和。就是代表封包大小,IP標準的MTU就是65535bytes,就跟Total Length有關(2的16次方-1)
> ### Identification
>
> 識別碼 (ID)。IP袋子必須要放在MAC袋子當中。不過,如果IP袋子太大的話,就得先要將IP再重組成較小的袋子然後再放到MAC當中。而當IP重組時,每個來自同一個IP的小袋子就得要有個識別碼以告知接收端這些小袋子其實是來自同一個IP封包才行。
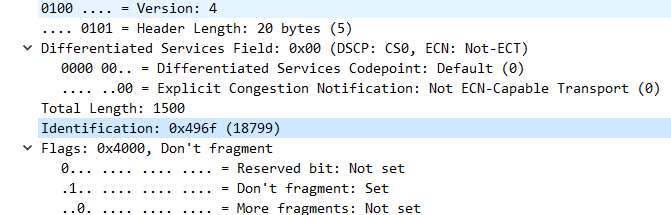
> ### Flag
>
> 旗標 (FL)。這是當封包在傳輸過程中進行最佳組合時使用的 3 個 bit 的識別記號。
> 這個地方的內容為『0DM』,其意義為:
> 0 : 保留,必須為0
> D(Don’t Fragment,DF):若為0表示可以分段,若為1表示不可分段
> M(More Fragment,MF):當上一個值為 0 時, 0表示此IP為最後分段,若為1表示非最後分段。
> 如果DF標誌被設定為1(不可分段),但路由要求必須分片封包,此封包會被丟棄。這個標誌可被用於發往沒有能力組裝分片的主機。
> ### Fragment Offset
>
> 分割定位 (FO)。當一個大封包在經過一些傳輸單位(MTU)較小的路徑時,會被切割成碎片(fragment) 再進行傳送(這個切割和傳送層的打包有所不同,它是由網路層決定的)。由於網路情況或其它因素影響,其抵達順序並不會和當初切割順序一至的。所以當封包進行切割的時候,會為各片段做好定位記錄,所以在重組的時候,就能夠依號入座了。
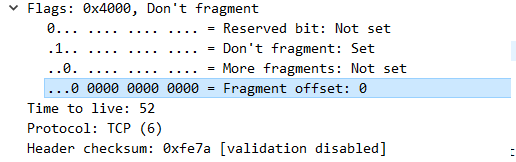
所以就是IP分段要組合成原本的IP,需要:
Total Length(原本的IP的大小)
Identification(IP分段才能知道它是來自哪一個原本的IP)
Flags(知道哪個IP分段是最後一個分段,不然沒辦法確認IP分段到底到哪結束)
Fragment Offset(當要重組的時候,才能組成原本的IP,不然會把手腳顛倒)
> ### Time To Live
>
> 存活時間 (TTL)。這個TTL的概念,在許多網路協定中都會碰到。當一個封包被賦予TTL值(以秒或跳站數目(hop)為單位),之後就會進行倒數計時。在IP協定中,TTL是以hop為單位,每經過一個router就減一,如果封包 TTL值被降為0的時候,就會被丟棄。這樣,當封包在傳遞過程中由於某些原因而未能抵達目的地的時候﹐就可以避免其一直充斥在網路上面。有隻叫做traceroute的程式,就是一個TTL利用實作。
> ### Protocol
>
> 協定(PROT)。這裡指的是該封包所使用的網路協定類型。例如﹕ICMP或TCP/UDP等等。要注意的是:這裡使用的協定是網路層的協定,這和上層的程式協定(如:FTP﹑HTTP 等)是不同的。可以從Linux的/etc/protocol這個檔案中找到這些協定和其代號
> 或是維基:https://zh.wikipedia.org/wiki/IP%E5%8D%8F%E8%AE%AE%E5%8F%B7%E5%88%97%E8%A1%A8
> ### Header Checksum
>
> 標頭檢驗值(HC)。這個數值主要用來檢錯用的,用以確保封包被正確無誤的接收到。當封包開始進行傳送後,接收端主機會利用這個檢驗值會來檢驗餘下的封包,如果一切看來無誤,就會發出確認信息,表示接收正常。
> ### Source IP Address
>
> 來源位址(SA)。就是發送端的IP位址,長度為32bit。
> ### Destination IP Address
>
> 目的地位址(DA)。也就是接收端的IP位址,長度為32 bit。
> ### Options & Padding
>
> 這兩個選項甚少使用,只有某些特殊的封包需要特定的控制,才會利用到。
### 分割重組
網際網路協定(IP)是整個網際網路架構的基礎,可以支援不同的實體層網路,即IP層獨立於連結層傳輸技術。不同的連結層不僅在傳輸速度上有差異,還在影格結構和大小上有所不同,不同MTU參數描述了資料框的大小。為了實現IP封包能夠使用不同的連結層技術,需要將IP封包變成適合連結層的資料格式,IP封包的分片即是IP封包為了滿足連結層的資料大小而進行的分割。
在IPv6不要求路由器執行分片操作,而是將檢測路徑最大傳輸單元大小的任務交給了主機。
#### 分片
當裝置收到IP封包時,分析其目的位址並決定要在哪個鏈路上傳送它。MTU決定了資料載荷的最大長度,如IP封包長度比MTU大,則IP封包必須進行分片。每一片的長度都小於等於MTU減去IP首部長度。接下來每一片均被放到獨立的IP封包中,並進行如下修改:
* 總長欄位被修改為此分片的長度;
* 更多分片(MF)標誌被設定,除了最後一片;
* 分片偏移量欄位被調整為合適的值;
* 首部核對和被重新計算。
例如,對於一個長20位元組的首部和一個MTU為1,500的乙太網路,分片偏移量將會是:0、(1480/8)=185、(2960/8)=370、(4440/8)=555、(5920/8)=740、等等。
如果封包經過路徑的MTU減小了,那麼分片可能會被再次分片。
比如,一個4,500位元組的資料載荷被封裝進了一個沒有選項的IP封包(即總長為4,520位元組),並在MTU為2,500位元組的鏈路上傳輸,那麼它會被破成如下兩個分片:

現在,假設下一跳的MTU為1,500位元組,那麼每一個分片都會被再次分成兩片(由於資料片段只有在目的主機才重新被組成資料報,因此再次分片是針對每個在網路中傳輸的資料框):

第3和4片是從原始第2片再次分片而來,所以除了分片後的最後一個分片外MF為都為1。
#### 重組
當一個接收者發現IP封包的下列專案之一為真時:
* DF標誌為0;
* 分片偏移量欄位不為0。
它便知道這個封包已被分片,並隨即將資料、識別碼欄位、分片偏移量和更多分片標誌一起儲存起來。
當接受者收到了更多分片標誌未被設定的分片時,它便知道原始資料載荷的總長。一旦它收齊了所有的分片,它便可以將所有片按照正確的順序(通過分片偏移量)組裝起來,並交給上層協定棧。
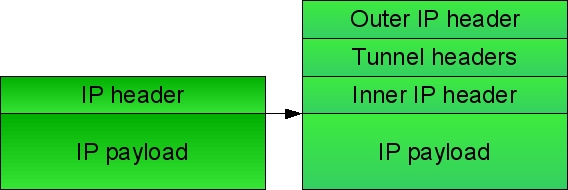
## IP 隧道
**IP 隧道(IP Tunneling)**,是指一種可在兩網路間用網際協定進行通信的通道。在該通道里,會先封裝其他網路協定的封包,之後再傳輸資訊。
IP隧道經常用於連接兩個不是用路由直接連結的IP網路,IP隧道會通過底層路由協定來架構中間傳輸網路。若IP隧道與兩個或多個IPSec一起使用時,可以建立虛擬私人網路(Virtual Private Network,VPN),讓二個或多個被公開網路(如網際網路)隔開的私有網路彼此存取,另一個主要應用也是目前常用的,讓各IPv6網路隔著IPv4網路上通訊。
在IP隧道中,每個IP包、來源/目的位址資訊都被封裝在一個封包中,該封包用於實際物理網路傳遞。
在源網路與傳輸網路的邊界,以及傳輸網路和目的網路的邊界,會用閘道器來建立跨網路的隧道端點(endpoint)。因此,IP隧道端點可以變成本地IP路由器,在源網路與目的網路間建立標準路由。端點會截取通過端點封包的隧道協定報頭及報尾,再轉換為標準IP格式,與其他來源的封包一樣注入到隧道端點的IP棧(IP stack)上。在這一層上,像IPSec或TLS等封裝用協定都被移除了。
IP in IP, 又被稱為 ipencap,是將IP協定封裝入傳輸用的IP協定的一個例子,RFC 2003描述此協定。類似的變體有IPv6-in-IPv4隧道 (6in4) 和 IPv4-in-IPv6 隧道(4in6)。
因為防火牆的本質及原始資料報被隱藏了,IP隧道經常用於繞過簡單的防火牆規則,通常需要通過內容控制軟體才能對IP隧道進行篩查。
移動IPv4主要有三種隧道技術,它們分別是:IP in IP、最小封裝以及通用路由封裝。
IP隧道封裝:
## IPv6 標頭
熟悉 IPv6 標頭欄位,可更瞭解 IPv6 運作方式:

> ### Version(4 位元)
>
> 此 4 位元欄位內容為通訊協定版本。在 IPv6 下,數字為 6。版本編號 5 不能用,因為
> 已被指派給實驗性資料流通訊協定(RFC 1819)。
>
> ### Traffic class(1 位元組)
>
> 此欄位置換 IPv4 的 Type of Service 欄。幫助即時資料處理,與需要特殊處理的其他
> 資料,而傳送節點與轉送的路由器可以利用它確認與辯識 IPv6 封包裡各種類別與優
> 先權。
>
> RFC 2474「Definition of the Differentiated Services Field(DS Field)in the IPv4 and IPv6
> Headers」說明如何利用 IPv6 的 Traffic Class 欄。RFC 2474 用 DS Field 這個字指 IPv4
> 標頭的 Type of Service 欄,以及 IPv6 標頭的 Traffic Class 欄。
>
> ### Flow label(20 位元)
>
> 此欄位識別為促進即時流量封包處理而必須一視同仁的封包。傳送主機可以一組選項為
> 封包依序貼上標籤。路由器對資料流保持追蹤,且能夠更有效率處理屬於相同資料流的
> 封包,因為無須重新處理每個封包標頭。資料流標籤與來源端位址可以當成資料流唯一
> 識別。不支援 Flow Label 欄位功能的節點,轉送封包時需傳送未經更動的欄位,接收封
> 包時則忽略該欄位。所有屬於相同資料流的封包必須擁有相同 Source 與 Destination IP
> 位址。
>
> ### Payload length(2 位元組)
>
> 此欄定義 負載(payload)── 例如 IPv6 標頭後所攜帶的資料長度。IPv6 計算方式與
> IPv4 不同。IPv4 的 Length 欄包含 IPv4 標頭長度,但 IPv6 的 Payload Length 欄僅接續
> IPv6 標頭後的資料。Extension 標頭被視為負載的一部份,因此會計算進去。
>
> 事實上 2 位元組的 Payload Length 欄將最大封包負載大小限制在 64 KB。IPv6 有
> Jumbogram Option,在必要時可支援更大封包。Jumbogram Option 攜於 Hop-by-Hop
> Option 標頭(將於本章稍候探討)內。Jumbograms 只有在 IPv6 節點附加至連結 MTU
> 大於 64 KB 連結時才會派上用場,它們定義於 RFC 2675。
>
> ### Next Header(1 位元組)
>
> IPv4 下,此欄位稱之為 Protocol Type 欄,但 IPv6 將之更名,反映 IP 封包新的組織方
> 式。若下一個標頭為 UDP 或 TCP,此欄內容為與 IPv4 相同通訊協定編號,例如 TCP
> 的通訊協定編號 6,或 UDP 的 7。但若在 IPv6 使用 Extension 標頭,此欄內容則為下一
> 個 Extension 標頭型態。Extension 標頭定位在 IP 標頭與 TCP 或 UDP 標頭之間。表 3-1
> 列出了 Next Header 欄可能值。IPv6 相關新標頭以粗體顯示。


> ### Hop limit(1 位元組)
>
> 此欄與 IPv4 的 TTL 欄類似。最初,IPv4 TTL 欄內含秒數,指出封包被丟棄前在網路裡
> 停留了多久時間。事實上,IPv4 路由器每跳一個點就減去此值。此欄在 IPv6 裡更名為
> Hop Limit 反映這樣的處理。此欄位裡的值表示中繼器(hops)數量。每個轉送節點都
> 會將此數字減 1。若路由器接收 Hop Limit 為 1 的封包,會被減成 0,丟棄封包,然後
> 回傳 ICMPv6 訊息「Hop Limit exceeded in transit」給傳送者。
>
> ### Source address(16 位元組)
>
> 此欄內容為封包發起者 IP 位址。
>
> ### Destination address(16 位元組)
>
> 此欄內容為封包預期接收者 IP 位址。可以是最終目的地,或在出現 Routing 標頭時,可
> 為下一個中繼路由器位址。

## EUI-64
EUI 64 是由電氣和電子工程師協會 (IEEE) 定義的地址,將 EUI-64 地址指派給網絡適配器,或從 IEEE802 地址派生得到該地址。
### 轉換方法
IPv6的EUI-64產生方法是透過該裝置網卡的mac address來作轉換,轉換後會得到一串數字,最後在前面加上特定的prefix,如link local的`fe80`或是ISP業者提供的prefix,就是使用EUI-64所得到的IP位置,詳細作法如下所示:
1. 首先先取得mac address,我們使用`d8:50:e6:d0:3b:d0`來作為範例
2. 接下來我們把他從中間切一刀,變成`d8:50:e6`以及`d0:3b:d0`
3. 接下來在他們中間塞入`fffe`,變成`d8:50:e6fffed0:3b:d0`
4. 把冒號去掉,然後每四個字母以冒號分開來,變成`d850:e6ff:fed0:3bd0`
5. 最後一步,把第7個bit作補數運算,講簡單一點就是把第二個數字變成二進位,並把從前面數過來第3個1變成0,0變成1,就完成了,而我們的範例中的第二個數字為`8`,變成二進位會是`0100`,把前面數過來的第3位數從0變成1,就會變成`0110`,換回16進位則會變成`a`
6. 得到後64bit的數字,就是`da50:e6ff:fed0:3bd0`
7. 與link local的prefix `fe80`結合,則該link local的IP就變成`fe80::da50:e6ff:fed0:3bd0`完成
### 內憂外患
使用EUI-64保證了後64bit保證沒有人會跟你搶,但就如mac address都有可能重複的情況發生時,EUI-64似乎就不是那麼美好的事情。
此外,EUI-64保證了後64bit是唯一的,那就代表,你把裝置換上不同的prefix(可能是不同網路,如iTaiwan或是FreeTPE之類的),後面64bit都不會變,因此要追蹤一個人的行蹤,似乎變得很簡單。
## TCP 三向交握
**TCP** 用 **三路握手(或稱三次握手,three-way handshake)** 過程來建立一個連接。在連接建立過程中,很多參數要被初始化,例如序號被初始化以保證按序傳輸和連接的強壯性。
一對終端同時初始化一個它們之間的連接是可能的。但通常是由一端(伺服器端)打開一個通訊端(socket)然後監聽來自另一方(客戶端)的連接,這就是通常所指的被動打開(passive open)。伺服器端被被動打開以後,客戶端就能開始建立主動打開(active open)。
伺服器端執行了listen函式後,就在伺服器上建立起兩個佇列:
* SYN佇列:存放完成了二次握手的結果。 佇列長度由listen函式的參數backlog指定。
* ACCEPT佇列:存放完成了三次握手的結果。佇列長度由listen函式的參數backlog指定。
三次握手協定的過程:
1. 客戶端(通過執行connect函式)向伺服器端傳送一個SYN包,請求一個主動打開。該包攜帶客戶端為這個連接請求而設定的亂數A作為訊息序列號。
2. 伺服器端收到一個合法的SYN包後,把該包放入SYN佇列中;回送一個SYN/ACK。ACK的確認碼應為A+1,SYN/ACK包本身攜帶一個隨機產生的序號B。
3. 客戶端收到SYN/ACK包後,傳送一個ACK包,該包的序號被設定為A+1,而ACK的確認碼則為B+1。然後客戶端的connect函式成功返回。當伺服器端收到這個ACK包的時候,把請求影格從SYN佇列中移出,放至ACCEPT佇列中;這時accept函式如果處於阻塞狀態,可以被喚醒,從ACCEPT佇列中取出ACK包,重新建立一個新的用於雙向通信的sockfd,並返回。
如果伺服器端接到了客戶端發的SYN後回了SYN-ACK後客戶端斷線了,伺服器端沒有收到客戶端回來的ACK,那麼,這個連接處於一個中間狀態,既沒成功,也沒失敗。於是,伺服器端如果在一定時間內沒有收到的TCP會重發SYN-ACK。在Linux下,預設重試次數為5次,重試的間隔時間從1s開始每次都翻倍,5次的重試時間間隔為1s, 2s, 4s, 8s, 16s,總共31s,第5次發出後還要等32s才知道第5次也逾時了,所以,總共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP才會斷開這個連接。使用三個TCP參數來調整行為:tcp_synack_retries 減少重試次數;tcp_max_syn_backlog,增大SYN連接數;tcp_abort_on_overflow決定超出能力時的行為。
「三次握手」的目的是「為了防止已失效的連接(connect)請求報文段傳送到了伺服器端,因而產生錯誤」,也即為了解決「網路中存在延遲的重複分組」問題。例如:
> client發出的第一個連接請求報文段並沒有遺失,而是在某個網路結點長時間的滯留了,以致延誤到連接釋放以後的某個時間才到達server。本來這是一個早已失效的報文段。但server收到此失效的連接請求報文段後,就誤認為是client發出的一個新的連接請求。於是就向client發出確認報文段,同意建立連接。假設不採用「三次握手」,那麼只要server發出確認,新的連接就建立了。由於現在client並沒有發出建立連接的請求,因此不會理睬server的確認,也不會向server傳送資料。但server卻以為新的運輸連接已經建立,並一直等待client發來資料。這樣,server的很多資源就白白浪費掉了。採用「三次握手」的辦法可以防止上述現象發生,client不會向server的確認發出確認。server由於收不到確認,就知道client並沒有要求建立連接。
## UDP
**使用者資料包協定(英語:User Datagram Protocol,縮寫:UDP;又稱使用者資料包協定)**,是一個簡單的面向資料包的通信協定,位於OSI模型的傳輸層。該協定由David P. Reed在1980年設計且在RFC 768中被規範。典型網路上的眾多使用UDP協定的關鍵應用在一定程度上是相似的。
在TCP/IP模型中,UDP為網路層以上和應用層以下提供了一個簡單的介面。UDP只提供資料的不可靠傳遞,它一旦把應用程式發給網路層的資料傳送出去,就不保留資料備份(所以UDP有時候也被認為是不可靠的資料包協定)。UDP在IP資料包的頭部僅僅加入了復用和資料校驗欄位。
UDP適用於不需要或在程式中執行錯誤檢查和糾正的應用,它避免了協定棧中此類處理的開銷。對時間有較高要求的應用程式通常使用UDP,因為丟棄資料包比等待或重傳導致延遲更可取。
### 可靠性
由於UDP缺乏可靠性且屬於無連接協定,所以應用程式通常必須容許一些遺失、錯誤或重複的封包。某些應用程式(如TFTP)可能會根據需要在應用程式層中添加基本的可靠性機制。
一些應用程式不太需要可靠性機制,甚至可能因為引入可靠性機制而降低效能,所以它們使用UDP這種缺乏可靠性的協定。串流媒體,即時多人遊戲和IP語音(VoIP)是經常使用UDP的應用程式。 在這些特定應用中,丟包通常不是重大問題。如果應用程式需要高度可靠性,則可以使用諸如TCP之類的協定。
例如,在VoIP中延遲和抖動是主要問題。如果使用TCP,那麼任何封包遺失或錯誤都將導致抖動,因為TCP在請求及重傳遺失資料時不向應用程式提供後續資料。如果使用UDP,那麼應用程式則需要提供必要的握手,例如即時確認已收到的訊息。
由於UDP缺乏擁塞控制,所以需要基於網路的機制來減少因失控和高速UDP流量負荷而導致的擁塞崩潰效應。換句話說,因為UDP傳送端無法檢測擁塞,所以像使用包佇列和丟棄技術的路由器之類的網路基礎裝置會被用於降低UDP過大流量。資料擁塞控制協定(DCCP)設計成通過在諸如串流媒體類型的高速率UDP流中增加主機擁塞控制,來減小這個潛在的問題。
### 應用
許多關鍵的網際網路應用程式使用UDP,包括:
* 域名系統(DNS),其中查詢階段必須快速,並且只包含單個請求,後跟單個回覆封包;
* 動態主機組態協定(DHCP),用於動態分配IP位址;
* 簡單網路管理協定(SNMP);
* 路由資訊協定(RIP);
* 網路時間協定(NTP)。
串流媒體、線上遊戲流量通常使用UDP傳輸。即時影片流和音訊流應用程式旨在處理偶爾遺失、錯誤的封包,因此只會發生品質輕微下降,而避免了重傳封包帶來的高延遲。 由於TCP和UDP都在同一網路上執行,因此一些企業發現來自這些即時應用程式的UDP流量影響了使用TCP的應用程式的效能,例如銷售、會計和資料庫系統。 當TCP檢測到封包遺失時,它將限制其資料速率使用率。由於即時和業務應用程式對企業都很重要,因此一些人認為開發服務品質解決方案至關重要。
某些VPN應用(如OpenVPN)使用UDP並可以在應用程式級別實現可靠連接和錯誤檢查。
### UDP的分組結構

UDP報頭包括4個欄位,每個欄位占用2個位元組(即16個位元)。在IPv4中,「來源連接埠」和「校驗和」是可選欄位(以粉色背景標出)。在IPv6中,只有來源連接埠是可選欄位。 各16bit的來源埠和目的埠用來標記傳送和接受的應用行程。因為UDP不需要應答,所以來源埠是可選的,如果來源埠不用,那麼置為零。在目的埠後面是長度固定的以位元組為單位的長度域,用來指定UDP資料報包括資料部分的長度,長度最小值為8byte。首部剩下地16bit是用來對首部和資料部分一起做校驗和(Checksum)的,這部分是可選的,但在實際應用中一般都使用這一功能。
#### 報文長度
該欄位指定UDP報頭和資料總共占用的長度。可能的最小長度是8位元組,因為UDP報頭已經占用了8位元組。由於這個欄位的存在,UDP報文總長不可能超過65535位元組(包括8位元組的報頭,和65527位元組的資料)。實際上通過IPv4協定傳輸時,由於IPv4的頭部資訊要占用20位元組,因此資料長度不可能超過65507位元組(65,535 − 8位元組UDP報頭 − 20位元組IP頭部)。
在IPv6的jumbogram中,是有可能傳輸超過65535位元組的UDP封包的。依據RFC 2675,如果這種情況發生,報文長度應被填寫為0。
#### 校驗和
校驗和欄位可以用於發現頭部資訊和資料中的傳輸錯誤。該欄位在IPv4中是可選的,在IPv6中則是強制的。如果不使用校驗和,該欄位應被填充為全0。
### UDP校驗和計算
#### IPv4偽頭部
當UDP執行在IPv4之上時,為了能夠計算校驗和,需要在UDP封包前添加一個「偽頭部」。偽頭部包括了IPv4頭部中的一些資訊,但它並不是傳送IP封包時使用的IP封包的頭部,而只是一個用來計算校驗和而已。

#### IPv6偽頭部
當UDP執行於IPV6之上時,校驗和是必須的,其計算方法位於RFC 2460:
> 任何包含來自IP頭位址的傳輸層或其他上層協定,其校驗和計算必須被修改,以適應IPv6的128位元ip位址。
IPv6偽頭部是生成校驗和所用的資料。

## TCP/UDP 常用埠號
| Port | Usage |
| ---- | ------------------------------------------- |
| 20 | FTP (Data) |
| 21 | FTP (Control) |
| 22 | SSH / SCP |
| 23 | Telnet |
| 25 | SMTP |
| 53 | DNS |
| 67 | DHCP |
| 68 | DHCP |
| 80 | HTTP |
| 110 | POP3 |
| 115 | SFTP |
| 119 | Network News Transport Protocol, NNTP |
| 123 | Network Time Protocol, NTP |
| 137 | NetBIOS Name |
| 138 | NetBIOS Data |
| 139 | NetBIOS Connection |
| 143 | IMAP |
| 389 | Lightweight Directory Access Protocol, LDAP |
| 443 | HTTPS |
| 989 | FTPS (Data) |
| 990 | FTPS (Control) |
| 1433 | SQL Server |
| 1434 | Azure Database Migration Service (DMS) |
| 3306 | MySQL |
| 3389 | Windows Remote Desktop |
| 5022 | SQL Server Availability Groups Listener |
### /etc/services
Service檔案是現代作業系統在etc目錄下的一個設定檔,記錄網路服務名對應的埠號與協定。
service檔案的用途是:
* 通過TCP/IP的API函式(聲明在netdb.h中)直接查到網路服務名與埠號、使用協定的對應關係。如getservbyname("serve","tcp")取得埠號;[1]getservbyport(htons(port),“tcp”)取得埠和協定上的服務名。[2]
* 如果使用者在這個檔案中維護所有使用的網路服務名字、埠、協定,那麼可以一目了然的獲悉哪些埠號用於哪個服務,哪些埠號是空閒的。
#### 介紹
IP協定的埠號,可用於區分伺服器提供的不同服務。值得範圍是0至65535. IP位址、埠號、TCP/UDP協定,這三者合起來稱為通訊端(socket)。
前1000個被保留用於特定應用,被稱為著名埠(well known ports)。細節見RFC 1340。並寫在service檔案中
#### 歷史
最初在Internet的前身ARPANET中,其成員SRI International手動維護並分享了一個名為SERVICES.TXT的檔案,其中就包括網路服務名對應的埠號與協定。
埠號和標準服務之間的對應關係在RFC 1700 「Assigned Numbers」中有詳細的定義。
#### Linux作業系統
檔案位置是`/etc/services`
只有「root」使用者才有權限修改這個檔案。檔案中的每一行由4個欄位組成,用TAB或空格分隔,分別表示「服務名稱」、「使用埠」、「協定名稱」以及「別名」。例如:
```
http 80/tcp www
```
#### Windows作業系統
檔案位置是`C:\WINDOWS\system32\drivers\etc\services`
只有「administrator」使用者才有權限修改這個檔案。檔案中的每一行由5個欄位組成,用TAB或空格分隔,分別表示「服務名稱」、「使用埠」、「協定名稱」、「別名」、「注釋」。例如:
```
qotd 17/tcp quote #Quote of the day
qotd 17/udp quote #Quote of the day
```
Winsock的API函式WSAConnectByName的第三個參數servicename,其官方文件解釋是:服務名是埠號的字串別名。
## TCP/IP 資料傳輸
在TCP的資料傳送狀態,很多重要的機制保證了TCP的可靠性和強壯性。它們包括:使用序號,對收到的TCP報文段進行排序以及檢測重複的資料;使用校驗和檢測報文段的錯誤,即無錯傳輸;使用確認和計時器來檢測和糾正丟包或延時;流控制(Flow control);擁塞控制(Congestion control);遺失包的重傳。
### 可靠傳輸
通常在每個TCP報文段中都有一對序號和確認號。TCP報文傳送者稱自己的位元組流的編號為序號(sequence number),稱接收到對方的位元組流編號為確認號。TCP報文的接收者為了確保可靠性,在接收到一定數量的連續位元組流後才傳送確認。這是對TCP的一種擴充,稱為選擇確認(Selective Acknowledgement)。選擇確認使得TCP接收者可以對亂序到達的資料塊進行確認。每一個位元組傳輸過後,SN號都會遞增1。
通過使用序號和確認號,TCP層可以把收到的報文段中的位元組按正確的順序交付給應用層。序號是32位元的無符號數,在它增大到232-1時,便會迴繞到0。對於初始化序列號(ISN)的選擇是TCP中關鍵的一個操作,它可以確保強壯性和安全性。
TCP協定使用序號標識每端發出的位元組的順序,從而另一端接收資料時可以重建順序,無懼傳輸時的包的亂序交付或丟包。在傳送第一個包時(SYN包),選擇一個亂數作為序號的初值,以克制TCP序號預測攻擊.
傳送確認包(Acks),攜帶了接收到的對方發來的位元組流的編號,稱為確認號,以告訴對方已經成功接收的資料流的位元組位置。Ack並不意味著資料已經交付了上層應用程式。
可靠性通過傳送方檢測到遺失的傳輸資料並重傳這些資料。包括逾時重傳(Retransmission timeout,RTO)與重複累計確認(duplicate cumulative acknowledgements,DupAcks)。
### 基於重複累計確認的重傳
如果一個包(不妨設它的序號是100,即該包始於第100位元組)遺失,接收方就不能確認這個包及其以後的包,因為採用了累計ack。接收方在收到100以後的包時,發出對包含第99位元組的包的確認。這種重複確認是包遺失的訊號。傳送方如果收到3次對同一個包的確認,就重傳最後一個未被確認的包。閾值設為3被證實可以減少亂序包導致的無作用的重傳(spurious retransmission)現象。選擇性確認(SACK)的使用能明確回饋哪個包收到了,極大改善了TCP重傳必要的包的能力。
### 逾時重傳
傳送方使用一個保守估計的時間作為收到封包的確認的逾時上限。如果超過這個上限仍未收到確認包,傳送方將重傳這個封包。每當傳送方收到確認包後,會重設這個重傳定時器。典型地,定時器的值設定為 `smoothed RTT + max(G, 4 × RTT variation)` 其中G是時鐘粒度。進一步,如果重傳定時器被觸發,仍然沒有收到確認包,定時器的值將被設為前次值的二倍(直到特定閾值)。這是由於存在一類通過欺騙傳送者使其重傳多次,進而壓垮接收者的攻擊,而使用前述的定時器策略可以避免此類中間人攻擊方式的阻斷服務攻擊。
### 資料傳輸舉例
1. 傳送方首先傳送第一個包含序列號為1(可變化)和1460位元組資料的TCP報文段給接收方。接收方以一個沒有資料的TCP報文段來回覆(只含報頭),用確認號1461來表示已完全收到並請求下一個報文段。
2. 傳送方然後傳送第二個包含序列號為1461,長度為1460位元組的資料的TCP報文段給接收方。正常情況下,接收方以一個沒有資料的TCP報文段來回覆,用確認號2921(1461+1460)來表示已完全收到並請求下一個報文段。傳送接收這樣繼續下去。
3. 然而當這些封包都是相連的情況下,接收方沒有必要每一次都回應。比如,他收到第1到5條TCP報文段,只需回應第五條就行了。在例子中第3條TCP報文段被遺失了,所以儘管他收到了第4和5條,然而他只能回應第2條。
4. 傳送方在傳送了第三條以後,沒能收到回應,因此當時鐘(timer)過時(expire)時,他重發第三條。(每次傳送者傳送一條TCP報文段後,都會再次啟動一次時鐘:RTT)。
5. 這次第三條被成功接收,接收方可以直接確認第5條,因為4,5兩條已收到。
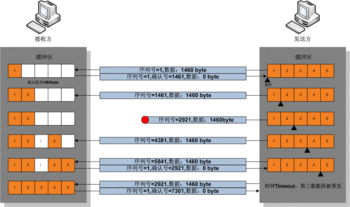
### 校驗和
TCP的16位元的校驗和(checksum)的計算和檢驗過程如下:傳送者將TCP報文段的頭部和資料部分的和計算出來,再對其求一補數(一的補數),就得到了校驗和,然後將結果裝入報文中傳輸。(這裡用一補數和的原因是這種方法的迴圈進位使校驗和可以在16位元、32位元、64位元等情況下的計算結果再疊加後相同)接收者在收到報文後再按相同的演算法計算一次校驗和。這裡使用的一補數使得接收者不用再將校驗和欄位儲存起來後清零,而可以直接將報文段連同校驗加總。如果計算結果是全部為一,那麼就表示了報文的完整性和正確性。
*注意:TCP校驗和也包括了96位的偽頭部,其中有源位址、目的位址、協定以及TCP的長度。這可以避免報文被錯誤地路由。*
按現在的標準,TCP的校驗和是一個比較脆弱的校驗。出錯概率高的資料鏈路層需要更高的能力來探測和糾正連接錯誤。TCP如果是在今天設計的,它很可能有一個32位元的CRC校驗來糾錯,而不是使用校驗和。但是通過在第二層使用通常的CRC校驗或更完全一點的校驗可以部分地彌補這種脆弱的校驗。第二層是在TCP層和IP層之下的,比如PPP或乙太網路,它們使用了這些校驗。但是這也並不意味著TCP的16位元校驗和是冗餘的,對於網際網路傳輸的觀察,表明在受CRC校驗保護的各跳之間,軟體和硬體的錯誤通常也會在報文中引入錯誤,而端到端的TCP校驗能夠捕捉到大部分簡單的錯誤。這就是應用中的端到端原則。
### 流量控制
流量控制用來避免主機分組傳送得過快而使接收方來不及完全收下,一般由接收方通告給傳送方進行調控。
TCP使用滑動窗口協定實現流量控制。接收方在「接收窗口」域指出還可接收的位元組數量。傳送方在沒有新的確認包的情況下至多傳送「接收窗口」允許的位元組數量。接收方可修改「接收窗口」的值。
TCP包的序號與接收窗口的行為很像時鐘。
當接收方宣布接收窗口的值為0,傳送方停止進一步傳送資料,開始了「保持定時器」(persist timer),以避免因隨後的修改接收窗口的封包遺失使連接的雙側進入死結,傳送方無法發出資料直至收到接收方修改窗口的指示。當「保持定時器」到期時,TCP傳送方嘗試恢復傳送一個小的ZWP包(Zero Window Probe),期待接收方回覆一個帶著新的接收窗口大小的確認包。一般ZWP包會設定成3次,如果3次過後還是0的話,有的TCP實現就會發RST把連結斷了。
如果接收方以很小的增量來處理到來的資料,它會發布一系列小的接收窗口。這被稱作愚蠢窗口綜合症,因為它在TCP的封包中傳送很少的一些位元組,相對於TCP包頭是很大的開銷。解決這個問題,就要避免對小的window size做出回應,直到有足夠大的window size再回應:
* 接收端使用David D Clark演算法:如果收到的資料導致window size小於某個值,可以直接ack把window給關閉了,阻止了傳送端再發資料。等到接收端處理了一些資料後windows size大於等於了MSS,或者接收端buffer有一半為空,就可以把window打開讓傳送端再發資料過來。
* 傳送端使用Nagle演算法來延時處理,條件一:Window Size>=MSS 且 Data Size >=MSS;條件二:等待時間或是逾時200ms,這兩個條件有一個滿足,才會發資料,否則就是在積累資料。Nagle演算法預設是打開的,所以對於一些需要小包場景的程式——比如像telnet或ssh這樣的互動性程式,需要關閉這個演算法。可以在Socket設定TCP_NODELAY選項來關閉這個演算法。

### 擁塞控制
擁塞控制是傳送方根據網路的承載情況控制分組的傳送量,以取得高效能又能避免擁塞崩潰(congestion collapse,網路效能下降幾個數量級)。這在網路流之間產生近似最大最小公平分配。
傳送方與接收方根據確認包或者包遺失的情況,以及定時器,估計網路擁塞情況,從而修改資料流的行為,這稱為擁塞控制或網路擁塞避免。
TCP的現代實現包含四種相互影響的擁塞控制演算法:慢開始、擁塞避免、快速重傳、快速恢復。
此外,傳送方採取「逾時重傳」(retransmission timeout,RTO),這是估計出來回通訊延遲 (RTT) 以及RTT的方差。
RFC793中定義的計算SRTT的經典演算法:指數加權移動平均(Exponential weighted moving average)
1. 先採樣RTT,記下最近好幾次的RTT值。
2. 做平滑計算SRTT公式為:`SRTT = (α ∗ SRTT) + ((1 − α) ∗ RTT)`,其中α取值在0.8到 0.9之間
3. 計算RTO,公式:`RTO = min(UBOUND, max(LBOUND, (β ∗ SRTT))`,其中UBOUND是最大的timeout時間上限值,LBOUND是最小的timeout時間下限值,β值一般在1.3到2.0之間。
1987年,出現計算RTT的Karn演算法或TCP時間戳(RFC 1323),最大特點是——忽略重傳,不把重傳的RTT做採樣。但是,如果在某一時間,網路閃動,突然變慢了,產生了比較大的延時,這個延時導致要重傳所有的包(因為之前的RTO很小),於是,因為重傳的不算,所以,RTO就不會被更新,這是一個災難。為此,Karn演算法一發生重傳,就對現有的RTO值翻倍。這就是的Exponential backoff。
1988年,在RFC 6298中給出范·雅各布森演算法取平均以獲得平滑往返時延(Smoothed Round Trip Time,SRTT),作為最終的RTT估計值。這個演算法在被用在今天的TCP協定中:
`SRTT = SRTT + α ∗ (RTT − SRTT) DevRTT = (1 − β) ∗ DevRTT + β ∗ |RTT − SRTT| RTO = μ ∗ SRTT + ∂ ∗ DevRTT`
其中:DevRTT是Deviation RTT。在Linux下,α = 0.125,β = 0.25,μ = 1,∂ = 4
目前有很多TCP擁塞控制演算法在研究中。
## TCP 標頭

> * 來源埠口(Source Port):來源之 TCP 埠口。
> * 目的地埠口(Destination Port):目的地之 TCP 埠口。
> * 順序編號(Sequence Number):該封包的順序編號。
> * 確認號碼(Acknowledge Number):回應封包的確認號碼,也是期望傳送端下次發送封包的序號,其表示該確認號碼以前的封包都以正常接收。
> * 資料偏移量(Data Offset):因為 TCP 的 Option 欄位長度並非固定,Data Offset 用來表示傳輸資料(Data)是在整個封包之區段起始位址。
> * 位元碼(Code bits):(6 位元)(URG, ACK, PSH, TST, SYN, FIN)此欄位作控制訊息傳遞之用。而且目前有關 TCP/IP 網路上的特殊處理工作(如防火牆等等)都是利用這些控制碼來運作。其中:
> 1. URG(Urgent):表示該封包為緊急資料,並使 Urgent Point 欄位有效。
> 2. ACK(Acknowledge):本封包有回應確認功能,其確認 Acknowledge Number 欄位中所指定的順序號碼。
> 3. PSH(Push):請求對方立即傳送 Send Buffer 中的封包。
> 4. RST(Reset):要求對方立即結束連線(強迫性),且發送者已斷線。
> 5. SYN(Synchronous):通知對方要求建立連線(TCP 連線)。
> 6. FIN(Finish):通知對方,資料已傳輸完畢,是否同意斷線。發送者還在連線中等待對方回應。
>
> * 視窗(Window):此欄位是用來控制封包流量,告訴對方目前本身還有多少緩衝器(Receive Buffer)可以接收封包(滑動視窗法之特性)。如果 Window = 0 表示緩衝器已滿暫停傳送資料。Window 大小的單位是以位元組表示(Byte)。
> * 檢查集(Checksum):此欄位為 16 bits 長的檢查碼,接收方可依此 Checksum 來確定所收封包(資料極表頭)是否正確。
> * 緊急指標(Urgent Point):當 URG = 1 時,其代表緊急資料是在資料區的什麼位址。
> * 任選欄(Option):目前此欄位只應用於表示接收端能夠接收最大資料區段的大小。如果不使用此欄位,則可以使用任意的資料區段大小。
> * 填補欄位(Padding):將 Option 欄位補足 32 位元的整數倍。
## ARP、RARP、ICMP
### ARP
**位址解析協定(英語:Address Resolution Protocol,縮寫:ARP)**,是一個通過解析網路層位址來找尋資料鏈路層位址的網路傳輸協定,它在IPv4中極其重要。ARP最初在1982年的RFC 826(徵求意見稿)中提出並納入網際網路標準STD 37。ARP也可能指是在多數作業系統中管理其相關位址的一個行程。
ARP是通過網路位址來定位MAC位址。 ARP已經在很多網路層和資料鏈結層之間得以實現,包括IPv4、Chaosnet、DECnet和Xerox PARC Universal Packet(PUP)使用IEEE 802標準, 光纖分散式資料介面, X.25,影格中繼和非同步傳輸模式(ATM),IEEE 802.3和IEEE 802.11標準上IPv4占了多數流量。
在IPv6中鄰居發現協定(NDP)用於代替位址解析協定(ARP)。
### RARP
**逆位址解析協定(Reverse Address Resolution Protocol,RARP)**,是一種網路協定,網際網路工程任務組(IETF)在RFC903中描述了RARP。RARP使用與ARP相同的報頭結構,作用與ARP相反。RARP用於將MAC位址轉換為IP位址。其因為較限於IP位址的運用以及其他的一些缺點,因此漸為更新的BOOTP或DHCP所取代。
### ICMP
**網際網路控制訊息協定(英語:Internet Control Message Protocol,縮寫:ICMP)**,是網際網路協定套組的核心協定之一。它用於網際網路協定(IP)中傳送控制訊息,提供可能發生在通訊環境中的各種問題回饋。通過這些資訊,使管理者可以對所發生的問題作出診斷,然後採取適當的措施解決。
ICMP依靠IP來完成它的任務,它是IP的主要部分。它與傳輸協定(如TCP和UDP)顯著不同:它一般不用於在兩點間傳輸資料。它通常不由網路程式直接使用,除了 ping 和 traceroute 這兩個特別的例子。 IPv4中的ICMP被稱作ICMPv4,IPv6中的ICMP則被稱作ICMPv6。
## Traceroute
**traceroute**,Linux系統稱為**tracepath**,Windows系統稱為**tracert**,是一種電腦網路工具。它可顯示封包在IP網路經過的路由器的IP位址。
### 原理
程式是利用增加存活時間(TTL)值來實現其功能的。每當封包經過一個路由器,其存活時間就會減1。當其存活時間是0時,主機便取消封包,並傳送一個ICMP TTL封包給原封包的發出者。
程式發出的首3個封包TTL值是1,之後3個是2,如此類推,它便得到一連串封包路徑。注意IP不保證每個封包走的路徑都一樣。
### 實現
主叫方首先發出 TTL=1 的數據包,第一個路由器將 TTL 減1得0後就不再繼續轉發此數據包,而是返回一個 ICMP 逾時報文,主叫方從逾時報文中即可提取出數據包所經過的第一個閘道器位址。然後又發出一個 TTL=2 的 ICMP 數據包,可獲得第二個閘道器位址,依次遞增 TTL 便獲取了沿途所有閘道器位址。
需要注意的是,並不是所有閘道器都會如實返回 ICMP 超時報文。出於安全性考慮,大多數防火墻以及啓用了防火墻功能的路由器預設組態為不返回各種 ICMP 報文,其餘路由器或交換機也可被管理員主動修改組態變為不返回 ICMP 報文。因此 Traceroute 程式不一定能拿全所有的沿途閘道器位址。所以,當某個 TTL 值的數據包得不到響應時,並不能停止這一追蹤過程,程式仍然會把 TTL 遞增而發出下一個數據包。一直達到預設或用參數指定的追蹤限制(maximum_hops)才結束追蹤。
依據上述原理,利用了 UDP 數據包的 Traceroute 程式在數據包到達真正的目的主機時,就可能因為該主機沒有提供 UDP 服務而簡單將數據包拋棄,並不返回任何資訊。爲了解決這個問題,Traceroute 故意使用了一個大於 30000 的埠號,因 UDP 協定規定埠號必須小於 30000 ,所以目標主機收到數據包後唯一能做的事就是返回一個「埠不可達」的 ICMP 報文,於是主叫方就將埠不可達報文當作跟蹤結束的標誌。
除了使用 UDP 外,也有使用TCP代替的實現方法。
### 歷史
根據traceroute的man page:1987年,Steve Deering建議Van Jacobson寫一個這樣的程式。C. Philip Wood、Tim Seaver和Ken Adelman為這個程式提供一些意見或改動。
Windows NT系統有結合ping和traceroute的pathping工具。
## 資安鐵三角:CIA Triad
在資安的世界中,CIA Triad是安全架構的基石,也是被廣泛採納的,資安團隊可鑑於以下三原則制定相關策略或評估潛在的威脅與漏洞:
### 機密性(Confidentiality)
機密性旨在對數據進行保密,也就是限制未經授權的資料之訪問與修改權,除了確保隱密性,也降低機密資料陷入威脅的機率。
為了保護資訊的機密性,常見的對策包含:將數據分類或標籤化,甚至是對資料存取者進行身份驗證、對傳輸中的數據進行加密,也有公司提供相關課程提高員工資安意識。
### 完整性(Integrity)
資安的完整性,指的是數據沒有遭受未經授權者篡改,以確保資料在整個生命週期內的一致性與精確性。舉幾個簡單的例子,如:在電商平台購物的消費者,希望所有產品與定價的資訊是準確的,並且所有訂購資訊在下訂單後不會改變。
銀行需要確保銀行存戶的帳戶金額的準確性與即時性,無論是透過ATM、網銀轉帳,該餘額都無法被有心人士修改。
與機密性相同,完整性會因為篡改入侵檢測系統或修改系統日誌而直接受到損害,也可能是人為疏忽或編碼錯誤而造成資安的完整性受到威脅,常見的保護措施包含:電子文件導入數位簽章、獲取具公信力機構發行認證的安全性證書等。
### 可用性(Availability)
資安的可用性意味著已啟動或正在運行的程序,授權者能夠即時地訪問這些資源,假如某系統、應用程式或數據無法即時讓授權用戶進行使用時,那麼資訊就無法為企業產生最大化的價值。
許多情況都會危及可用性,包括軟硬體故障、電源故障、自然災害和人為疏失,電腦病毒也會直接衝擊可用性,常採取的應對策略包括:定期軟體修補與系統升級、備份等保護解決方案。
## 路由協定
**路由協定(英語:Routing protocol)**,是一種指定封包轉送方式的網路協定。Internet網路的主要節點裝置是路由器,路由器通過路由表來轉發接收到的資料。轉發策略可以是人工指定的(通過靜態路由、策略路由等方法)。在具有較小規模的網路中,人工指定轉發策略沒有任何問題。但是在具有較大規模的網路中(如跨國企業網路、ISP網路),如果通過人工指定轉發策略,將會給網路管理員帶來巨大的工作量,並且在管理、維護路由表上也變得十分困難。
為了解決這個問題,動態路由協定應運而生。動態路由協定可以讓路由器自動學習到其他路由器的網路,並且網路拓撲發生改變後自動更新路由表。網路管理員只需要組態動態路由協定即可,相比人工指定轉發策略,工作量大大減少。
常見的路由協定有RIP、IGRP(Cisco私有協定)、EIGRP(Cisco私有協定)、OSPF、IS-IS、BGP等。RIP、IGRP、EIGRP、OSPF、IS-IS是內部網路關協定(IGP),適用於單個ISP的統一路由協定的執行,一般由一個ISP運營的網路位於一個AS(自治系統)內,有統一的AS number(自治系統號)。BGP是自治系統間的路由協定,是一種外部閘道器協定,多用於不同ISP之間交換路由資訊,以及大型企業、政府等具有較大規模的私有網路。
### RIP
RIP很早就被用在Internet上,是最簡單的路由協定。它是「路由資訊協定(Route Information Protocol)」的簡寫,主要傳遞路由資訊,通過每隔30秒廣播一次路由表,維護相鄰路由器的位置關係,同時根據收到的路由表資訊計算自己的路由表資訊。RIP是一個距離向量路由協定,最大跳數為15跳,超過15跳的網路則認為目標網路不可達。此協定通常用在網路架構較為簡單的小型網路環境。現在分為RIPv1和RIPv2兩個版本,後者支援VLSM技術以及一系列技術上的改進。RIP的收斂速度較慢。
### OSPF
OSPF協定是「開放式最短路徑優先(Open Shortest Path First)」的縮寫,屬於鏈路狀態路由協定。OSPF提出了「區域(area)」的概念,每個區域中所有路由器維護著一個相同的鏈路狀態資料庫(LSDB)。區域又分為骨幹區域(骨幹區域的編號必須為0)和非骨幹區域(非0編號區域),如果一個執行OSPF的網路只存在單一區域,則該區域可以是骨幹區域或者非骨幹區域。如果該網路存在多個區域,那麼必須存在骨幹區域,並且所有非骨幹區域必須和骨幹區域直接相連。OSPF利用所維護的鏈路狀態資料庫,通過最短路徑優先演算法(SPF演算法)計算得到路由表。OSPF的收斂速度較快。由於其特有的開放性以及良好的擴充性,目前OSPF協定在各種網路中廣泛部署。
### IS-IS
IS-IS協定是Intermediate system to intermediate system(中間系統到中間系統)的縮寫,屬於鏈路狀態路由協定。標準IS-IS協定是由國際標準化組織制定的ISO/IEC 10589:2002所定義的,標準IS-IS不適合用於IP網路,因此IETF制定了適用於IP網路的整合化IS-IS協定(Integrated IS-IS)。和OSPF相同,IS-IS也使用了「區域」的概念,同樣也維護著一份鏈路狀態資料庫,通過最短生成樹演算法(SPF)計算出最佳路徑。IS-IS的收斂速度較快。整合化IS-IS協定是ISP骨幹網上最常用的IGP協定。
### IGRP
IGRP協定是「內部網路關路由協定(Interior Gateway Routing Protocol)」的縮寫,由Cisco於二十世紀八十年代獨立開發,屬於Cisco私有協定。IGRP和RIP一樣,同屬距離向量路由協定,因此在諸多方面有著相似點,如IGRP也是周期性的廣播路由表,也存在最大跳數(預設為100跳,達到或超過100跳則認為目標網路不可達)。IGRP最大的特點是使用了混合度量值,同時考慮了鏈路的頻寬、延遲、負載、MTU、可靠性5個方面來計算路由的度量值,而不像其他IGP協定單純的考慮某一個方面來計算度量值。目前IGRP已經被Cisco獨立開發的EIGRP協定所取代,版本號為12.3及其以上的Cisco IOS(Internetwork Operating System)已經不支援該協定,現在已經罕有執行IGRP協定的網路。
### EIGRP
由於IGRP協定的種種缺陷以及不足,Cisco開發了EIGRP協定(增強型內部網路關路由協定)來取代IGRP協定。EIGRP屬於進階距離向量路由協定(又稱混合型路由協定),繼承了IGRP的混合度量值,最大特點在於引入了非等價負載均衡技術,並擁有極快的收斂速度。EIGRP協定在Cisco裝置網路環境中廣泛部署。
### BGP
為了維護各個ISP的獨立利益,標準化組織制定了ISP間的路由協定BGP。BGP是「邊界閘道器協定(Border Gateway Protocol)」的縮寫,處理各ISP之間的路由傳遞。但是BGP執行在相對核心的地位,需要使用者對網路的結構有相當的了解,否則可能會造成較大損失。
## 資訊安全 (Information Security)
保護資訊之機密性、完整性與可用性;得增加諸如鑑別性、可歸責性、不可否認性與可靠性。
1. 機密性(Confidentiality):資料不得被未經授權之個人、實體或程序所取得或揭露的特性。
2. 完整性(Integrity):對資產之精確與完整安全保證的特性。
3. 可歸責性(Accountability):確保實體之行為可唯一追溯到該實體的特性。
1. 鑑別性(Authenticity):確保一主體或資源之識別就是其所聲明者的特性。
2. 鑑別性適用於如使用者、程序、系統與資訊等實體。
3. 不可否認性(Non-repudiation):對一已發生之行動或事件的證明,使該行動或事件往後不能被否認的能力。
4. 可用性(Availability):已授權實體在需要時可存取與使用之特性。
5. 可靠性(Reliability):始終如一預期之行為與結果的特性。