# Current `CommitToPoly` versus other three potential ones
I was looking if there were some potential improvements in our `CommitToPoly` implementations in https://github.com/crate-crypto/go-ipa, and found some interesting results.
Everything mentioned in this document, is based on a [draft PR in go-ipa](https://github.com/crate-crypto/go-ipa/pull/35). You don't need to read the code (but can) from that PR to understand this document.
## What is this PR about?
I wanted to test our current `CommitToPoly(...)` implementation against three other implementation ideas that I considered interesting:
- `pristine_gnark_(no_precomp_tables)`: In this implementation, I directly use `gnark` for MSM which doesn't use any kind of precomputing table.
- `(hybrid_(precomputed_or_gnark_depending_on_size)`: This implementation is a hybrid between our current one, and the `pristine_gnark_(no_precomp_tables)`. [It uses one or the other implementation depending on how big is the MSM size](https://github.com/crate-crypto/go-ipa/pull/35/files#diff-a3ff0e43196d8532ccfef3fa5598b1fc7e4c03e3dd8240ce7108e52f5f2c09ceR81-R85). You'll understand later why this is interesting, but the TL;DR now is that each implementation is faster than the other in different lengths.
- `precomputed_and_parallel`: is our current implementation using precomputed tables, but [doing work in parallel in multiple goroutines](https://github.com/crate-crypto/go-ipa/pull/35/files#diff-e0a7c8ce1e22702e9fe309e0691b2a93e4e683ff08c945f0becc084123b50ef8R108-R138) since the current implementation is sequential.
## OK, so we have 3 extra implementations apart from the current one; how sure we're they are all equivalent?
Good question. [I created a test that compares all four implementations to be sure they are equivalent](https://github.com/crate-crypto/go-ipa/pull/35/files#diff-f931619c1f07126599c84329691c69f82a03367f88c8f3c2d1b8078ba8c9e9bfR291-R318).
Obviously I did this to be sure the benchmarks are relevant.
## Benchmark results
So, we have now four different `CommitToPoly(...)` implementations (current + 3 new ones).
Now it's time to compare their performance. You can see the [benchmark here](https://github.com/crate-crypto/go-ipa/pull/35/files#diff-f931619c1f07126599c84329691c69f82a03367f88c8f3c2d1b8078ba8c9e9bfR245-R289). What this benchmark does is to compare the performance of each implementation for MSM lengths of 1, 2, 3, 8, 16, 32, 64, 128 and 256. The idea is to cover all ranges to see how each behave.
If you want to run the benchmark, pull that PR branch and do:
```
go test ./ipa -run=none -bench=BenchmarkCommitToPoly
```
The result is quite long and you can find it in the _Appendix_ section below. Since it's hard to interpret these things in text-form, I created a plot that helps to understand them.
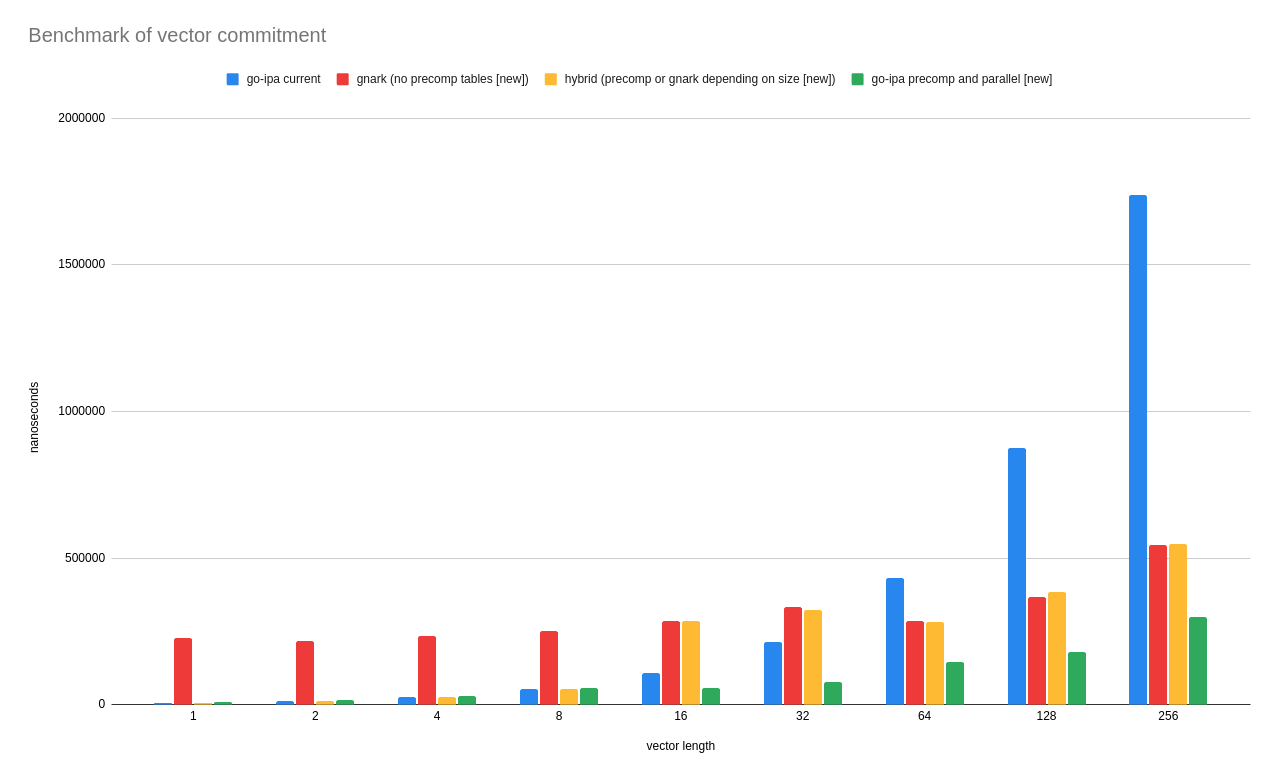
[Right-click and open in a new tab to see it better]
## What is that plot showing?
Let me help interpreting that plot. First, some clarifications about what is shown there:
- Blue: this is our current implementation using precomputed tables.
- Red: this is the alternative implementation that uses `gnark` MSM (no precomputed tables)
- Yellow: this is the alternative implementation which is a hybrid between our current implementation and the gnark one.
- Green: this is our current implementation, but parallelized.
What are some conclusions while looking at this chart:
- Blue (current impl): for lengths <64, it looks competitive with the rest but after that point it continues to scale linearly. That makes sense since the implementation is a for-loop doing lookups in a table, but it's way slower than the rest (which aren't single-threaded or have other implementations)
- Red (gnark MSM no-precomputes): while slower than our current implementation for lengths <=32, it scales better for longer ones.
- Yellow (hybrid (curent or gnark)): now it might seem obvious why I created this flavor. Since our current implementation and gnark MSM one behave better for different lengths, I use one or the other in the "optimal cutoff" point. So the "yellow" is the best case of "blue or red".
- Green: this is our current implementation but parallelized. Apparently, the best one.
I think all these results makes sense:
- Our current implementation (blue) is single-threaded compared to the others that use more than one core in different ways, so it makes sense that others will scale better than linearly.
- When I parallelized our current implementation, it was better than the `gnark` one which isn't single-threaded. That's good to hear, because a non-precomputed MSM can't be faster than precomputed-MSM .
To be able to use the gnark implementation, I had to do some extra work in the PR regarding point representations (projective/affine). Nothing entirely interesting, but you can see that [looking at the PR](https://github.com/crate-crypto/go-ipa/pull/35).
## What now?
I think it might be worth running these different implementations in our replay-benchmark, and see how this impact the most "real" benchmark that we have available. Maybe from there we can see how to move forward.
# Appendix
## Raw benchmark results shown in the plot
```
$ go test ./ipa -run=none -bench=BenchmarkCommitToPoly
...
BenchmarkCommitToPoly/vector_length_1_with_go-ipa_precomputed_table_(current)-16 170256 6702 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_1_with_pristine_gnark_(no_precomp_tables)-16 5598 228188 ns/op 15874 B/op 74 allocs/op
BenchmarkCommitToPoly/vector_length_1_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 168456 6802 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_1_with_go-ipa_(precomputed_and_parallel_[new])-16 119392 9564 ns/op 6256 B/op 3 allocs/op
BenchmarkCommitToPoly/vector_length_2_with_go-ipa_precomputed_table_(current)-16 83065 13334 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_2_with_pristine_gnark_(no_precomp_tables)-16 5154 215577 ns/op 15952 B/op 75 allocs/op
BenchmarkCommitToPoly/vector_length_2_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 84793 13329 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_2_with_go-ipa_(precomputed_and_parallel_[new])-16 71268 15778 ns/op 6256 B/op 3 allocs/op
BenchmarkCommitToPoly/vector_length_4_with_go-ipa_precomputed_table_(current)-16 43998 25862 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_4_with_pristine_gnark_(no_precomp_tables)-16 5235 235652 ns/op 16112 B/op 77 allocs/op
BenchmarkCommitToPoly/vector_length_4_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 44175 25813 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_4_with_go-ipa_(precomputed_and_parallel_[new])-16 38936 29898 ns/op 6256 B/op 3 allocs/op
BenchmarkCommitToPoly/vector_length_8_with_go-ipa_precomputed_table_(current)-16 22224 53443 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_8_with_pristine_gnark_(no_precomp_tables)-16 4026 251116 ns/op 16434 B/op 81 allocs/op
BenchmarkCommitToPoly/vector_length_8_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 23233 52897 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_8_with_go-ipa_(precomputed_and_parallel_[new])-16 23749 57075 ns/op 6352 B/op 4 allocs/op
BenchmarkCommitToPoly/vector_length_16_with_go-ipa_precomputed_table_(current)-16 11370 106842 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_16_with_pristine_gnark_(no_precomp_tables)-16 3645 284498 ns/op 17072 B/op 89 allocs/op
BenchmarkCommitToPoly/vector_length_16_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 4314 284103 ns/op 17072 B/op 89 allocs/op
BenchmarkCommitToPoly/vector_length_16_with_go-ipa_(precomputed_and_parallel_[new])-16 22188 57239 ns/op 6544 B/op 6 allocs/op
BenchmarkCommitToPoly/vector_length_32_with_go-ipa_precomputed_table_(current)-16 5588 213493 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_32_with_pristine_gnark_(no_precomp_tables)-16 3722 331816 ns/op 17584 B/op 89 allocs/op
BenchmarkCommitToPoly/vector_length_32_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 3552 322269 ns/op 17584 B/op 89 allocs/op
BenchmarkCommitToPoly/vector_length_32_with_go-ipa_(precomputed_and_parallel_[new])-16 15483 77705 ns/op 6928 B/op 10 allocs/op
BenchmarkCommitToPoly/vector_length_64_with_go-ipa_precomputed_table_(current)-16 2757 432723 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_64_with_pristine_gnark_(no_precomp_tables)-16 3915 285215 ns/op 20576 B/op 130 allocs/op
BenchmarkCommitToPoly/vector_length_64_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 4024 280801 ns/op 20576 B/op 130 allocs/op
BenchmarkCommitToPoly/vector_length_64_with_go-ipa_(precomputed_and_parallel_[new])-16 7119 144000 ns/op 7696 B/op 18 allocs/op
BenchmarkCommitToPoly/vector_length_128_with_go-ipa_precomputed_table_(current)-16 1334 875704 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_128_with_pristine_gnark_(no_precomp_tables)-16 3212 365988 ns/op 22624 B/op 130 allocs/op
BenchmarkCommitToPoly/vector_length_128_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 3188 385277 ns/op 22624 B/op 130 allocs/op
BenchmarkCommitToPoly/vector_length_128_with_go-ipa_(precomputed_and_parallel_[new])-16 6450 178239 ns/op 9232 B/op 34 allocs/op
BenchmarkCommitToPoly/vector_length_256_with_go-ipa_precomputed_table_(current)-16 663 1736523 ns/op 0 B/op 0 allocs/op
BenchmarkCommitToPoly/vector_length_256_with_pristine_gnark_(no_precomp_tables)-16 2173 543580 ns/op 23824 B/op 112 allocs/op
BenchmarkCommitToPoly/vector_length_256_with_go-ipa_(hybrid_(precomputed_or_gnark_depending_on_size_[new])-16 2186 546716 ns/op 23824 B/op 112 allocs/op
BenchmarkCommitToPoly/vector_length_256_with_go-ipa_(precomputed_and_parallel_[new])-16 3979 299751 ns/op 12304 B/op 66 allocs/op:w
```
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet