---
tags: 機器學習基石下:方法篇
---
Ch9 Linear Regression
===
## Content
[TOC]
## [Slides & Videos](https://www.csie.ntu.edu.tw/~htlin/mooc/)
## 授課大綱: 機器學習基石下:方法篇
How Can Machines Learn? [機器可以怎麼樣學習]
* 第九講:Linear Regression [線性迴歸]
* 第十講:'Soft' Classification [軟性分類]
* 十一講:Multiclass Classification [多類別分類]
* 十二講:Nonlinear Transformation [非線性轉換] (公布作業三)
How Can Machines Learn Better? [機器可以怎麼樣學得更好]
* 十三講:Hazard of Overfitting [過度訓練的危險]
* 十四講:Regularization [探制調適]
* 十五講:Validation [自我檢測]
* 十六講:Three Learning Principles [三個機器學習的重要原則] (公布作業四)
## [Linear Regression Problem](https://www.youtube.com/watch?v=qGzjYrLV-4Y&list=PLXVfgk9fNX2I7tB6oIINGBmW50rrmFTqf&index=34)
### Illustration of Linear Regression

- residual 在這邊就是 linear regression 的 error (紅色的線)
- 一維的 x:(在2D平面上) 找到一條直線使得 residual 最小
- 二維的 x:(在3D空間中) 找到一個平面使得 residual 最小
### The Error Measure
<!--  -->

- 我們可以把 $E_{in}(h)$ 替換成 $E_{in}(w)$ 來表示,因為一個 $w$ 就對應到一個 $h$
- $E_{out}(w)$ 同理
- 記得我們現在切換到了一個**有 noise 的 setting,即 $y$ 其實也是從一個 distribution sample 出來的,因此我們有 $(x,y)$ 的 joint distribution**
## [Linear Regression Algorithm](https://www.youtube.com/watch?v=2LfdSCdcg1g&list=PLXVfgk9fNX2I7tB6oIINGBmW50rrmFTqf&index=35)
### Matrix Form of $E_{in}(w)$
<!--  -->

- $x_n$ 的維度 $(d+1)\times 1$
- 向量內積 有交換律 $w^Tx_n=w\cdot x_n=x_n\cdot w=x_n^Tw$
- 要把它矩陣化,「連加某東西的平方」可以視為某個向量的長度的平方
- 此時 $E_{in}(w)$ 可以化簡成 $\frac{1}{N}||Xw-y||^2$
<!--  -->

- 此時變數只有 $w$, 因為 $X$ 和 $y$ 皆已知
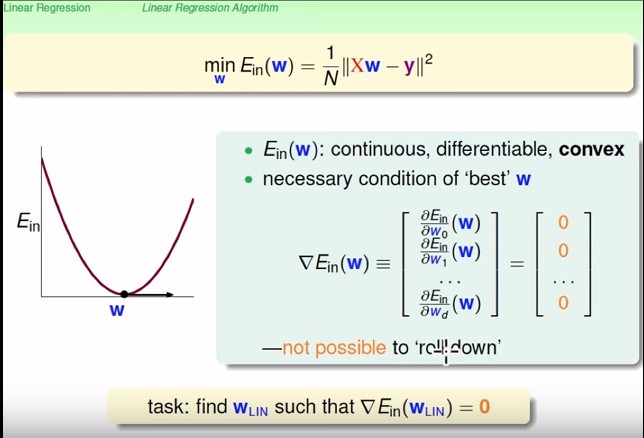
- 可以證明這個 $E_{in}$ 是
- continuous
- differentiable
- **convex**
- convex 代表如果我已經找到能讓 $E_{in}$ 最小的 $w$,則我在 $w$ 往任何方向走都沒辦法往下滾,即任何方向的梯度都會是 0
- 因此想要找到最小的 $E_{in}$,就等同於: **找到 $\nabla E_{in}(w_{Lin}) = 0$**
- $w_{LIN}$:解 linear regression 最後得到的 $w$。後面有點懶得加 LIN 上去
- 註: [nabla運算子 $\nabla$](https://zh.wikipedia.org/wiki/Nabla%E7%AE%97%E5%AD%90)
### The Gradient $\nabla E_{in}(w)$
<!--  -->

- 把 $E_{in}$ 展開使得求 gradient 較容易解讀
- 向量平方即自己的內積 $a^2=a^Ta$
- 且向量運算 $\|a-b\|^2=a^2-2a\cdot b + b^2$
- 又 $Xw$ 和 $y$ 都是一個向量,因此
- $\|Xw-y\|^2\\=(Xw)^2-2(Xw)\cdot y+y^2\\=(Xw)^TXw-2(Xw)^Ty+y^Ty\\=w^TX^TXw-2w^TX^Ty+y^Ty$
- 若把 $X^TX$ 寫作 $A$;把 $X^Ty$ 寫作 $b$;把 $y^Ty$ 寫作 constant $c$,則 $E_{in}(w)$ 可以寫成 $\frac 1 N (w^TAw-2w^Tb+c)$
- 對 $w$ 向量微分其實和只有一個變數時很像,微分後結果為 $\nabla E_{in}(w) = \frac 1 N(2Aw-2b)=\frac{2}{N}(X^TXw-X^Ty)$
### Optimal Linear Regression Weights
<!--  -->

- 接下來我們只要找到 $w$ 使得 $\nabla E_{in}(w)=0$ 就可以了!
- $X$ 的維度:$N\times (d+1)$
- $X^TX$ 的維度: $(d+1) \times (d+1)$
- $N$ 通常比 $d$ 大,因此 $X^TX$ 就有足夠的自由度,因此大部分情況下的 $X^TX$ 都是可逆的。
- 建議使用支援 pseudo-inverse 的平台,因為若不可逆,或者接近不可逆的矩陣(計算 inverse 會不穩定)
- 計算 $w = X^\dagger y$
- $X^\dagger=(X^TX)^{-1}X^T$
- $X^\dagger$ 就是 $X$ 的 pseudo-inverse
### Summary - Linear Regression Algorithm

### Fun Time: Linear Regression $w_{LIN}$
<!--  -->

- $y=Xw$,結案
<!-- - 記得使用 $w_{Lin}$時, $\hat y = Xw_{Lin}$ -->
## [Generalization Issue](https://www.youtube.com/watch?v=lj2jK1FSwgo&list=PLXVfgk9fNX2I7tB6oIINGBmW50rrmFTqf&index=36)
### Is Linear Regresion a 'Learning Algorithm'?

- 你可能會覺得 linear regression 不是一個 learning algorithm
- 它是 analytic solution / closed-form solution / instantaneous
- 可以瞬間就算出結果
- 它的解可以寫成一個公式
- 它看起來好像不是 iterative 算出來的,$E_{in}$ 似乎沒有在進步
- 但它其實可以被視為一個 learning algorithm
- 有好的 $E_{in}$
- 有限的 VC dimension
- 其實在解 inverse 或 pseudo-inverse 的時候是 iterative 的
- 其實,只要 $E_{out}$ 是好的,就可以說它已經是在 learning 了
### Benefit of Analytic Solution: 'Simpler-than-VC' Guarantee
<!--  -->

- VC 可以幫助我們解釋 $E_{out}$ 可以很小,而我們現在要用另一種角度解釋為什麼 $E_{out}$ 可能很小,我們從 $E_{in}$ 出發。
- 我們要看的是 $E_{in}$ 的平均,跟 VC 不一樣,VC 是去看個別的 $E_{in}$
- 為什麼看 $E_{in}$ 的平均? 因為 linear regression 可以輕易寫出矩陣的 analytical solution,所以我們可以對 $E_{in}$ 的平均還有 $E_{out}$ 的平均做一些分析。
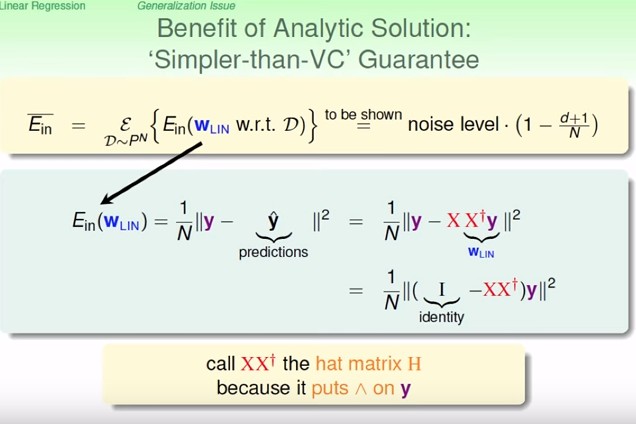
- $\overline{E_{in}}$:$E_{in}$ 的平均,也就是我們每次從母體 sample 出一把資料計算 $E_{in}$,sample 很多次,計算很多次 $E_{in}$ 的平均
- $E_{in}(w)$ 可以寫成 $\dfrac 1 N \|(I-XX^\dagger)y\|^2$
- 另外 $XX^\dagger$ 又稱 hat matrix $H$,因為 $XX^\dagger y=\hat y$
- **我們之後會證明說 $\overline{E_{in}}=\text{noise level}\cdot(1-\dfrac{d+1}{N})$**
- 這是什麼意思? 意思是我們平均來說所得到的 $E_{in}$ 會比雜訊來得小一點,小多少? 小 $\dfrac{d+1}{N}$。
### Geometric View of Hat Matrix

- $\hat y=Xw\in\mathbb R^N$ 是一個 $N$ 維向量
- 補充:$X\in\mathbb R^{N\times (d+1)}$
- 回顧線性代數,$\hat y$ 其實就是 $X$ 的 columns 的 linear combination,也就是 $\hat y$ 會落在 $X$ 的 columns 的 Span 裡面!
- 補充:$X$ 的 columns 的 span,就是 $X$ 的 column space,投影片以紅色的 span 表示
- 那麼 linear regression 希望 $y$ 跟 $\hat y$ 的差別可以最小,其實就是希望可以讓 $y-\hat y$ 是**垂直於 $X$ 的 columns 的 span,即 $y-\hat y\perp Col(X)$**
- 若把 hat matrix 以 $H$ 表示,則 $\hat y = XX^\dagger y=Hy$
- $H$ 就是在把 $y$ 投影到 $X$ 的 column space
- **$I-H$ 就是把 $y$ 投影到 $y-\hat y$ (會垂直於 span)**
- 其實 $\text{trace}(I-H)=N-(d+1)$
- trace 就是對角線相加,$d+1$ 就是有多少個 $w$ 變數
- 可以把 trace 看成自由度,或者是能量
- 這個式子的物理意義
- 本來 $y$ 有 $N$ 的自由度
- 我們把它投影到 $\hat y\in Col(X)$ 就只剩下 $d+1$ 的自由度
- 因此 $y-\hat y$ 就只剩下 $N-(d+1)$ 的自由度了
- 這個 slide 其實只是在複習 linear algebra
### An Illustrative 'Proof'

- 假設我們最理想的 target function $f(X)$ (以紅色箭頭表示) 的確就落在 $X$ 的 span
- 那麼我們所看到的 label $y$ 就可以視為 $f(X)$ 加上 noise (黑色虛線箭頭)
- 回顧上個 slide,$I-H$ 可以視為把向量投影到 $y-\hat y$ 方向上的 transformation
- 我們若把 $\text{noise}$ 向量做餘數的轉換 ($I-H$),其實也可以得到 $y-\hat y$ (綠色虛線箭頭)
- 也就是說我們的 $y-\hat y$ 就是把 $I-H$ 用在我們的雜訊上。
- 注意 $y-\hat y$ 是一個 $N$ 維向量,每個 element 是第 $i$ 筆資料的 $y^{(i)}-\hat y^{(i)}$,而且 $E_{in}$ 是 $\frac 1 N \sum_i(y^{(i)}-\hat y^{(i)})^2$,,所以$E_{in}(w_{LIN})=\frac 1 N \|(I-H)\text{noise}\|^2$
- 這裡 $\sigma^2$ 就是 noise level
- > Q: (noise level 好像就是 noise 的向量長度除以 $N$ 嗎???)
- ***結論 (not sure why)***
- $\overline{E_{in}}=\text{noise level}\cdot(1-\frac{d+1}{N})$
- > Q: 可是怎麼導出 $\overline{E_{in}}=\frac 1 N(N-(d+1))\sigma^2$ 的??? 而且上面籃框框又說是 $E_{in}$,好亂RRRR
- $\overline{E_{out}}=\text{noise level}\cdot(1+\frac{d+1}{N})$
- 注意這裡的 noise level 是把各種亂亂的 noise 再做平均
- 可以用類似算 $E_{in}$ 的方式來算出這個結果,但稍微複雜一些
- 這邊就可以看出 $\overline{E_{in}}$ 和 $\overline{E_{out}}$ 有個正負號不同,可以思考它的物理意義,不多贅述。
### The Learning Curve

- 圖重要
- $\overline{E_{in}}$ 和 $\overline{E_{out}}$ 隨著 data 數量增加,最後都會收斂到 $\sigma^2$ 也就是 noise 的平方
- 推導不是很重要,先不講了
- $\overline{E_{in}}$ 和 $\overline{E_{out}}$ 會差多少? 平均來說,會差 $\frac{2(d+1)}{N}$
- VC 說的是最壞的情況
- 我們這邊是說平均的情況
- 但兩種保證很類似
### Fun Time: Hat Matrix

## [Linear Regression for Binary Classification](https://www.coursera.org/learn/ntumlone-algorithmicfoundations/lecture/dYtXU/linear-regression-for-binary-classification)

- 看起來 linear regression 好像可以解 binary classification 的問題耶,正1負1都是實數啊,當 label 給 linear regression 不是好解多了嗎? closed-form solution 耶!
- 那這在數學上有道理嗎?
### Relation of Two Errors

- 兩者最大差別就在 error function
- 從圖中我們可以發現不論 $w^Tx$ 是什麼值,squared error 一定會大於 0/1 error
### Linear Regression for Binary Classification

- 回想之前證明的 VC bound,$E_{in}$ 加上 很複雜根號那一項(model complexity) 可以 bound 住 $E_{out}$
- 然後剛剛說 regression 的 $E_{in}$ 又永遠比 0/1 error 的 $E_{in}$ 更大,所以紅色的 $E_{in}$ 可以 bound 住上面藍色的式子
- 所以我們用力地把 regression 的 $E_{in}$ 做好,也是把藍色那項做好的一種方法,也就可以保證我們的 $E_{out}$ 是好的
- > Q: 好玄 @@
- **以 noise & error 那一堂課的話來講的話,就是我們把 squared error 當成 $\widehat{err}$**
- 我們換成寬鬆一點的 bound,使得演算法比較有效率地找到好的 solution。
- 也就是說我用 linear regression 算出一個 $w$,它還是可以給 classification 來用,表現不會太差
- 如果表現不差,但覺得不夠好,也可拿來當成 pocket 或 PLA 的 $w_0$,可能加速 PLA 或 pocket 的過程。
### Fun Time: Upper Bound for 0/1 Error

- 可以把圖畫出來,會發現每個都是 0/1 error 的 upper bound
- 我自己是用分開討論的方式
- $y$ 和 $w^Tx$ 同號,0/1 error 只會等於 0,這三個函數明顯都會大於等於 0
- $y$ 和 $w^Tx$ 異號的情況,$y=+1$ 會怎樣? $y=-1$ 又會怎樣? 很快就知道答案。
- **這三個函數其實都對應到很重要的 machine learning 演算法**,往後會一一說明。
### Summary
