# 2022q1 final project seHTTPd
contributed by < `jim12312321` >
> [作業說明](https://hackmd.io/@sysprog/linux2022-sehttpd)
> [Github](https://github.com/jim12312321/sehttpd)
## 實驗環境
```shell
$ gcc --version
gcc (Ubuntu 11.2.0-7ubuntu2) 11.2.0
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 20
On-line CPU(s) list: 0-19
Thread(s) per core: 1
Core(s) per socket: 14
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 154
Model name: 12th Gen Intel(R) Core(TM) i7-12700H
Stepping: 3
CPU MHz: 2700.000
CPU max MHz: 6000.0000
CPU min MHz: 400.0000
BogoMIPS: 5376.00
Virtualization: VT-x
L1d cache: 336 KiB
L1i cache: 224 KiB
L2 cache: 8.8 MiB
NUMA node0 CPU(s): 0-19
```
## 自我檢查清單
- [x] 在 [高效 Web 伺服器開發](https://hackmd.io/@sysprog/fast-web-server) 提到 epoll 的兩種工作模式 (level trigger vs. edge trigger),對照 [seHTTPd](https://github.com/sysprog21/sehttpd) 原始程式碼,解釋 epoll 工作模式的設定和在 web 伺服器實作的考量點 $\to$ 搭配程式碼實驗並說明
> 提示: 參考實驗程式碼: [test_epoll_lt_and_et](https://github.com/Manistein/test_epoll_lt_and_et)
- [x] [seHTTPd](https://github.com/sysprog21/sehttpd) 內部為何有 timer,考量點和具體作用為何?timer 為何用到 priority queue 呢?能否在 Linux 核心原始程式碼找到類似的用法?
- [x] lock-free/lockless 的 thread pool 的效益為何?在高並行的應用場域 (如 web 伺服器),可以如何發揮 thread pool 的效益呢?
- [x] 解釋前述 `http-parse-sample.py` 運作機制,以及 eBPF 程式在 Linux 核心內部分析封包的優勢為何?
---
## level trigger vs. edge trigger
在 epoll 中的兩種工作模式 (level trigger vs. edge trigger)其名稱來自數位邏輯領域。
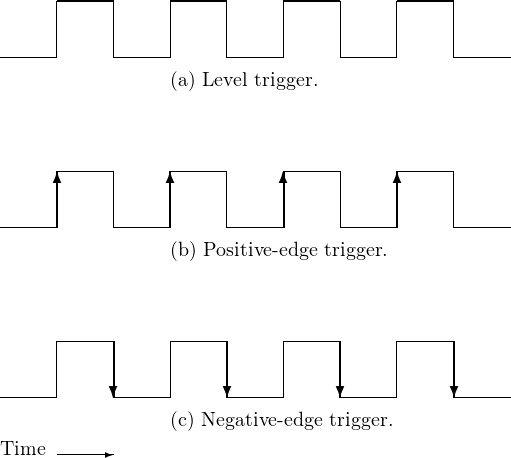
在 level trigger 時,當電路處於高電位時持續觸發訊號,而 edge trigger 則僅有在電位改變的瞬間觸發。在 epoll 中則借用這個概念表述何時該觸發 epoll。
- level trigger
當 file descriptor 持續有新資料就緒時,便會觸發 epoll,直到新資料全部從 buffer 中釋出才會停止 epoll 訊號。因此即使呼叫 epoll_wait 仍然會持續收到通知。
- edge trigger
當 file descriptor 新增資料的瞬間才觸發 epoll,此時若呼叫 epoll_wait 那沒讀完的資料不會繼續讀取,因此要配合像是持續 read 直到 EAGAIN 這樣的手段來輔助。
在 epoll 的 manual page 中有提到 level trigger 和 edge trigger 的適用情境。
>An application that employs the EPOLLET flag should use nonblocking file descriptors to
avoid having a blocking read or write starve a task that is handling multiple file descrip‐
tors. The suggested way to use epoll as an edge-triggered (EPOLLET) interface is as fol‐
lows:
a) with nonblocking file descriptors; and
b) by waiting for an event only after read(2) or write(2) return EAGAIN.
By contrast, when used as a level-triggered interface (the default, when EPOLLET is not
specified), epoll is simply a faster poll(2), and can be used wherever the latter is used
since it shares the same semantics.
而在 seHTTPd 中應該使用 edge trigger 使 epoll 只關注在 file descriptor 的改變並加以處理。
從寫程式面來說,設定 level trigger 或是 edge trigger 是由設定 epoll_event 中的 events 來控制。若有加上 `EPOLLET` 的 flag 則表示使用 edge trigger,沒有則表示使用 level trigger。
以下實驗使用 Apach Benchmark 做壓力測試。
```
$ ab -n 10000 -c 500 -k http://127.0.0.1:8081/
```
- level trigger 的結果(節錄片段)
```
Concurrency Level: 500
Time taken for tests: 0.252 seconds
Complete requests: 10000
Failed requests: 16
(Connect: 0, Receive: 0, Length: 16, Exceptions: 0)
Keep-Alive requests: 9984
Total transferred: 4173312 bytes
HTML transferred: 2406144 bytes
Requests per second: 39678.29 [#/sec] (mean)
Time per request: 12.601 [ms] (mean)
Time per request: 0.025 [ms] (mean, across all concurrent requests)
Transfer rate: 16170.89 [Kbytes/sec] received
```
- edge trigger 的結果(節錄片段)
```
Concurrency Level: 500
Time taken for tests: 0.380 seconds
Complete requests: 10000
Failed requests: 0
Keep-Alive requests: 10000
Total transferred: 4180000 bytes
HTML transferred: 2410000 bytes
Requests per second: 26296.27 [#/sec] (mean)
Time per request: 19.014 [ms] (mean)
Time per request: 0.038 [ms] (mean, across all concurrent requests)
Transfer rate: 10734.22 [Kbytes/sec] received
```
在使用 level trigger 時較使用 edge trigger 常發生 failed requests 的狀況,但在每秒可處理的 requests 中可以發現 level trigger 較 edge trigger 表現優秀。
---
## timer in seHTTPd
在 seHTTPd 中主要會用到 timer 的時機主要有兩點。
- 設定 epoll_wait 的 timeout
- 設定每個 request 處理的時間
在設定 epoll_wait 的 timeout 這點,當 timeout 越久,造成的 blocking 就會越久,不過如果單就設定 timeout 來說,我認為設定一個恰當的定值也可以達到不錯的效果,不一定要用 timer。
我認為真正引入 timer 的需求是第二點,設定每個 request 處理的時間。如同在[高效 Web 伺服器開發](https://hackmd.io/@sysprog/fast-web-server)中的`實作考量點`中提到,對於客戶端網路離線的情況需要引入 timer 機制,當重新開始 epoll_wait 迴圈時,若此時還有 request 沒處理但是已經超過當前時間,就視同客戶端斷線,將此 request 遺棄。
使用 priority queue 的原因也是為了因應以上需求,在 seHTTPd 中 timer 的 priority 就是 timer 的結束時間,seHTTPd 可以一次處理多個 request 請求,如果可以將超時或已完成的 request 及時移除,便可以先一步釋放資源。
---
## thread pool
在多執行緒程式中會希望將工作分配到不同的執行緒中並行處理以提升效率,而若每次需要執行緒時便新增一個執行緒會導致頻繁的建立新執行緒,不僅消耗系統資源同時也會花費額外時間成本。
因此 thread pool 的概念便是一開始就建立好固定數量的執行緒,並透過一條 Main thread 負責將任務加入 work queue 中提供給剩下在 pool 中的執行緒 (work threads) 去執行相應任務,藉此省去大量創建執行緒的成本。尤其在高並行的任務中,省下創建執行緒的成本所帶來的效益更大。

### thread pool vs. lock-free thread pool
lock-free 常用的實現方法是使用 atomic 指令執行 RMW (Read-Modify-Write) 操作,利用 atomic 的性質從而確保缺乏 lock 時容易出錯的操作能正確執行。在使用 lock 的多執行緒程式中,一旦某個執行緒獲取 lock 之後,其他執行緒便無法針對後續 critical section 中被保護的 shared memory 資料進行修改,從而保證資料正確性。但使用 lock 的痛點同時也產生,因為當一段程式被保護時,其他執行緒只能等待 lock 釋出之後,才能獲取從而造成時間消耗,因此通常使用 lock 的程式相較於 lock-free 的執行時間較長。
lock-free thread pool 的設計上也沿襲了 lock-free 程式設計的優點,能帶來更快的執行效率。
但 lock-free 程式可能會產生額外的競爭問題,如 [ABA problem](https://en.wikipedia.org/wiki/ABA_problem) ,因此設計上為了避免 work threads 競爭 work queue 中的資料因此為每個 work thread 都提供各自的 work queue。

---
## eBPF in seHTTPd
### [http-parse-sample.py](https://github.com/jim12312321/sehttpd/tree/master/ebpf) 運作機制
先上示意圖:

在 [http-parse-sample.py](https://github.com/jim12312321/sehttpd/tree/master/ebpf/http-parse-sample.py) 中利用事先寫好要植入 eBPF 中的程式 [http-parse-sample.c](https://github.com/jim12312321/sehttpd/tree/master/ebpf/http-parse-sample.c) 中的函式 `http_filter` 對 web server 進行過濾特定訊息的作用,並透過與 [http-parse-sample.c](https://github.com/jim12312321/sehttpd/tree/master/ebpf/http-parse-sample.c) 建立的 socket 與 eBPF 持續的以非侵入式的方式動態追蹤 [http-parse-sample.c](https://github.com/jim12312321/sehttpd/tree/master/ebpf/http-parse-sample.c) 在 web server 上的行為,除此之外也可以透過讀取 raw socket 上的訊息,分析 TCP/IP header 進一步知道封包資訊。
### eBPF 在 linux 中分析封包優勢
eBPF 是直接內建在 linux kernel 中用以進行動態/靜態追蹤核心/使用者行為的虛擬機,由於 eBPF 是直接內建的,因此執行封包分析的速度上會比其他在使用者層級的監控程式更加快速,同時進行 eBPF 時會將結果以 MAP (key-value) 的形式儲存全域變數並允許 kernel 和 user 取用進而提升效率。
---
## 以 sendfile 系統呼叫改寫 src/http.c 裡頭傳遞檔案內容的實作
在 [以 sendfile 和 splice 系統呼叫達到 Zero-Copy](https://hackmd.io/@sysprog/linux2020-zerocopy) 一文中有針對以 sendfile 系統呼叫實施傳遞檔案的好處。在原本 [src/http.c](https://github.com/sysprog21/sehttpd/blob/master/src/http.c) 中傳遞檔案內容的方法是採用 mmap+write 這個組合,以下會針對 [以 sendfile 和 splice 系統呼叫達到 Zero-Copy](https://hackmd.io/@sysprog/linux2020-zerocopy) 中提到使用 mmap + write 與 sendfile 各自的優缺進行整理。
- mmap + write

使用 mmap 取代 read 最直接的好處是可以減少一次資料複製的成本,但這不總是能帶來效率提升,面對小檔案操作時,使用 mmap 會造成空間上的浪費
>A file is mapped in multiples of the page size. For a file that is not a multiple of the
page size, the remaining bytes in the partial page at the end of the mapping are zeroed
when mapped, and modifications to that region are not written out to the file.
-- man page of mmap
由於每次 mmap 都是以 page size 的整數倍進行映射,因此當檔案大小並不是 page size 的整數倍時,便會造成空間浪費。
另外由於 mmap 僅是替代 read 的方法,後續還是得加上 write 完成檔案讀寫操作,因此免不了還是會需要至少 3 次 context switch 的成本。
- sendfile

sendfile 的目的在於直接於核心內進行兩個 fd 之間的檔案複製,由於都在核心內進行,比起無論是 read + write 或 mmap + read 的組合都會少了對應到 user buffer 的過程,同時也會少 1 次 context switch 的成本,因此能進行更有效率的檔案內容傳遞。不過使用 sendfile 自然也有其限制(以下內容皆節錄自 man page of sendfile)︰
> The in_fd argument must correspond to a file which supports mmap(2)-like operations (i.e., it cannot be a socket).
然而在 `out_fd` (fd for writing) 則沒有這個限制。
> In Linux kernels before 2.6.33, out_fd must refer to a socket. Since Linux 2.6.33 it can be any file. If it is a regular file, then sendfile() changes the file offset appropriately.
此外若要使用 sendfile 傳遞 TCP header 的話, man page 中也建議要調整 TCP 設定以減少 packet 的數量。
> If you plan to use sendfile() for sending files to a TCP socket, but need to send some header data in front of the file contents, you will find it useful to employ the TCP_CORK option, described in tcp(7), to minimize the number of packets and to tune performance.
因此本次實作的修改僅將檔案內容傳遞改為 sendfile 而 header 的傳送則維持用 `writen` 函式實作。
### 實作結果
- mmap + write
```
Concurrency Level: 500
Time taken for tests: 0.314 seconds
Complete requests: 10000
Failed requests: 5
(Connect: 0, Receive: 0, Length: 5, Exceptions: 0)
Keep-Alive requests: 9995
Total transferred: 4177910 bytes
HTML transferred: 2408795 bytes
Requests per second: 31874.85 [#/sec] (mean)
Time per request: 15.686 [ms] (mean)
Time per request: 0.031 [ms] (mean, across all concurrent requests)
Transfer rate: 13004.91 [Kbytes/sec] received
```
- sendfile
```
Concurrency Level: 500
Time taken for tests: 0.191 seconds
Complete requests: 10000
Failed requests: 39
(Connect: 0, Receive: 0, Length: 39, Exceptions: 0)
Keep-Alive requests: 9961
Total transferred: 4163698 bytes
HTML transferred: 2400601 bytes
Requests per second: 52256.71 [#/sec] (mean)
Time per request: 9.568 [ms] (mean)
Time per request: 0.019 [ms] (mean, across all concurrent requests)
Transfer rate: 21248.16 [Kbytes/sec] received
```
可以很直觀的發現在使用 sendfile 取代 mmap + write 後,在 request per second 帶來約 1.6 倍的增長。程式碼請見 [Github: http.c](https://github.com/jim12312321/sehttpd/blob/master/src/http.c) 。
---