# HRank-Filter-Pruning-using-High-Rank-Feature-Map_Report - [背景介紹](#背景介紹) - [Abstract](#Abstract) - [Introdction](#Introdction) - [Method](#Method) - [Experiment](#Experiment) - [Conclusion](#Conclusion) - [Reference](#Reference) - --- ### 背景介紹   至今深度學習已經開枝散葉,不管是任何領域,大多數模型都越來越深,(ResNet50,GPT-2,BERT),計算量過大、對硬體需求極高的門檻倒置應用難以落地,因此模型壓縮和簡化由於是軟體方面的方法,成本相較於設計一個專用的NPU更為節省,壓縮簡化完後也方便作為後續的處理。 --- ### Abstract   HRank是一個基於單個filter生成的feature maps的mean rank大同小異,且batch size對其的影響並不大,論文主要以數學角度去證明:Low-rank avg. filter產生的feature maps訊息量較少,並且可以捨去以達到加速和壓縮之目的。      ######   上圖為本篇的概念,中圖為通過一個超參數進行rank的分配,紅色為需要被裁減的low-rank,綠色和藍色則保留      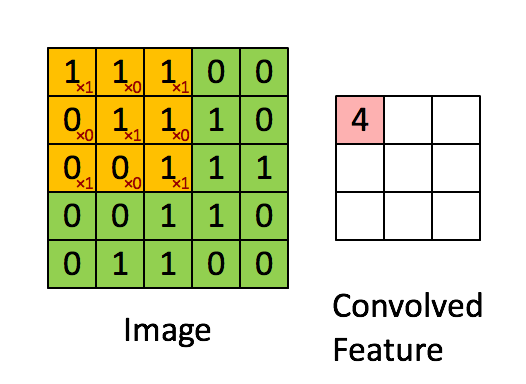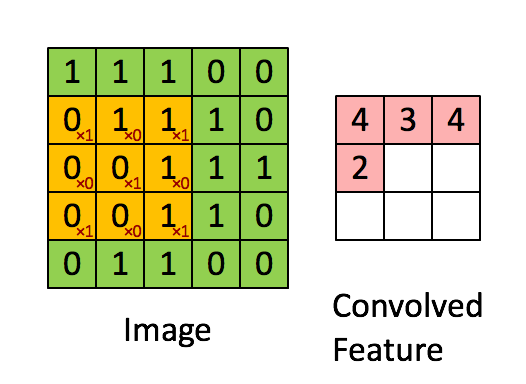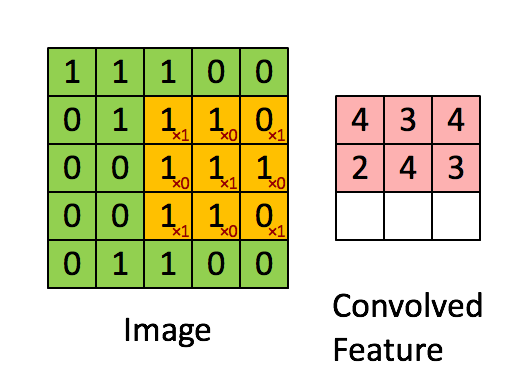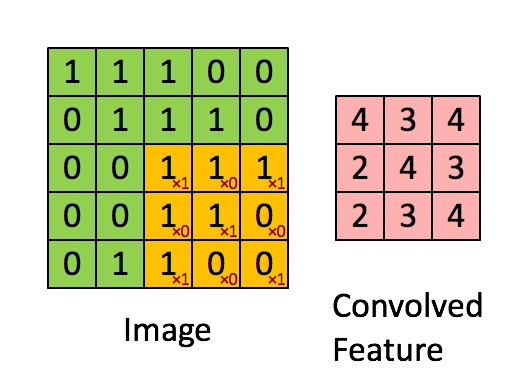 ######     上圖綠色為一個CNN輸入的Image(Input),經過橘色filter(單通道時等同於kernel),產生紅色的feature map --- ### Introdction 在濾波器剪枝中(filter pruning)設計和訓練方式主要可以分為下面兩項: - 屬性重要性 (Property Imoprtance) 藉由CNN內部的固有屬性對filter進行裁剪,例如:稀疏偵測、基於L1-norms距離的偵測以及本篇的基於rank。 優點:時間複雜度低,並且不需要更動loss function,可以使用pretrained model 缺點:加速不明顯以及壓縮比率較低。 - 適應性重要性 (Adaptive Importance) 需要與整個model一起訓練,藉由加入裁剪損失來探求最佳的裁剪方法,例如在Batch Normalization中引入稀疏結構參數進行學習。 優點:加速效果較好,壓縮比率高。 缺點:無法泛用,且重新訓練成本較高。 ---   本篇論文基於屬性重要性 (Property Imoprtance),但使用rank對特徵圖進行篩選,且因前面提到batch大小不影響rank的變化,因此可以從少量的batch去推導,從而決定該filter是否應該被剪裁,與現今的SOTA技術相比(06/2020),能夠在保持屬性重要性的優點上,壓縮和加速比皆勝適應性重要性的方法。            ######   上圖為在ImageNet的物件偵測任務上以ResNet50和現今SOTA技術的相比,可以看到在犧牲Top-5 1%左右的準確度上能夠將參數壓縮2倍左右和FLOPs(Floating-point operations per second 每秒浮點運算)上壓縮3倍左右。  ######   上圖x軸為feature map的index,y軸為batch數量,顏色深淺為rank高低,可以觀察到batch對rank幾乎沒有,此圖為作者使用matplotlid將filter輸出的feature maps之rank可視化的結果。 --- ### Method   此段落主要講解作者裁減的過程,以及filter產生的feature maps裁減如何演化成基於Rank方面的裁減,這段落作者主要參考的是2016的論文 **Network trimming: A data-driven neuron pruning approach towards efficient deep architectures.[1]** 裡面的APOZ (Average percentage of Zero)主要是計算feature map含0的百分比,論文中也多次提及,作者通過大量觀察後發現能夠以rank來簡化並用來做pruning。 首先先介紹相關參數: ---  ---   首先,我們有一個3D的濾波器集合$W_{C^i}$,其中第$w_j^i$個filter產生的output特徵圖為一個集合$O^i$,$g$是input圖像的解析度,$h_i$,$w_i$ 則分別是特徵圖的長寬。 接著我們可以把$O^i$拆成兩個group $I_{C^i}$ → 為important group,高Rank feature map的集合,需要進行**保留** $U_{C^i}$ → 為unimportant group,低Rank feature map的集合,需要進行**裁減** 而數量分別是$n_{i1}$ , $n_{i2}$ 我們可以些定義 $\delta_{ij}$:                去判斷$w_j^i$是屬於$I_{C^i}$或$U_{C^i}$ 接著本篇主要公式:目的是剪掉$u_{C^i}$內的filter,定義下列式子:                其中我們需要找到一個使式(1)去判斷$w_j^i$是屬於$I_{C^i}$或$U_{C^i}$,配合$\delta_{ij}$的定義,該式成立(在$C^i$中移除$n_{i2}$個最不重要的濾波器)。 最後 $I_{C^i}$ 與 $U_{C^i}$和其個數之間的關係:                  本論文中在特徵圖上定義理由在於特徵圖是可以同時反映這兩個方面的中間步驟。除此之外,根據**Revisiting the importance of individual units in cnns via ablation.[2]**(一篇深度學習可解釋性的論文)表示不同的特徵圖,即使來自同的Layer,它們也在任務中也有不同的角色,再者,它們還能夠捕獲輸入圖片如何轉換到每一層,直到預測的標籤層。為了更好的表示,可以將式(1)改寫成重要性抽樣(Important Sampling):                $\mathbb E$為重要性采樣,$I$為輸入圖片,是從分布函數$P(I)$採樣的,$\hat L(·)$與$L(·)$呈正相關,包含的資訊越多即filter更加重要。 以下是蒙地卡羅方法(Monte Carlo Methods)的簡單介紹: 本質上就是積分近似:             以下是classfication的動圖(可以加入本篇論文想像成重要與不重要的分類問題)                  但是,蒙地卡羅近似方法最大的問題就是需要足夠的輸入,我們CNN的filter極多,顯然是個很大的負擔,且依賴於輸入的分布,可能不同filter的結果需要不同的設計,因此我們需要將問題再次簡化。   我們已經將問題轉換成一種期望分布函數,又在基於[1],相當於計算矩陣零元素的分布並刪除,但此方法可以說是一種資料驅動的方法(Data Driven)對於$P(I)$的分布很敏感,計算十分複雜,雖然可以透過蒙特卡洛近似(MonteCarlo approximation)來近似求解,但也需要相當大量的input images([1]表示需要超過萬個左右的input)。   為了避免這種大量的計算且需要與$P(I)$分布不敏感的方式,作者提出使用Rank的判別方式,我們可以得出下列式子:                $Rank(·)$是Input $I$的feature map的Rank,我們可以使用SVD分解來計算$o^i_j(I,:,:)$:              其中 $r > r '. \sigma_i,\mu_i,v_i$ 分別是top-i個的奇異值、左奇異向量跟右奇異向量。 我們在這邊就能分別分出high rank $r$ 和 low rank $r'$,而high rank的特徵映射具有更多的信息。 而Rank是否能夠作為特徵分類的依據,已經由上面的圖(Rank-Batch顏色關係分布圖)實驗證實。   現在的問題是我們是否能夠再次縮小$r$的取樣範圍,雖然不同images可能有不同的Rank,但他們的標準差可以說是微不足道的,因此我們能夠取前幾個High Rank(本篇論文HRank的標題來源)做為參考即可,這邊作者設置$g=500$來當作input的image數量,用於計算平均的Rank,之後放入$I_{C^i}$ or $U_{C^i}$。 隨後我們就可以把採樣函數修正成:                我們最後的式子就成為:                整理一下,整體步驟如下:  簡單解釋一下:計算$o_{ij}$產生的feature maps的平均Rank,放入$R^i$排序成$\hat R^i$,定義$n_{i1}$,$n_{i2}$,得到兩個集合$I_{C^i}$ & $U_{C^i}$,其中$w^i_{I_{ij}}$對應$r^i_{I_{ij}}$,一個avg. rank對應,並依照$n_{i1}$,$n_{i2}$,判斷是否該被剪裁。 --- ### Experiments 作者使用 CIFAR-10 和 ImageNet 分別為小和大的資料庫來做評估,並選擇最常用的幾個model,主要以減少FLOPs和參數量為評判標準。     消融實驗 (第二個Top-1%為Baseline) * Baseline: 基準 * Edge: 取中間段(low & high rank filter both be pruned) * Random: 隨機取 * Reverse: 反著取 --- ### Conclustion 1. 對於ReLU Layer依賴,需要有經過filter為0 2. 對於feature map的rank變化不明顯的特例,代表high rank將沒有足夠的資訊量,不適用於此方法。 3. 作者對於每個model有特別做調整,猜測ResNet之類的有特殊結構需要處理或者跳過。 4. 能夠省略大約2倍的參數,3倍的FLOPs,成績十分優異。 --- ### Reference [[1]Network trimming: A data-driven neuron pruning approach towards efficient deep architectures.](https://arxiv.org/abs/1607.03250) [[2]Revisiting the importance of individual units in cnns via ablation.](https://arxiv.org/abs/1806.02891) [[3]HRank: Filter Pruning using High-Rank Feature Map](https://arxiv.org/abs/2002.10179) [[4]HRank:Filter Pruning using High-Rank知呼(by spzhuang)](https://zhuanlan.zhihu.com/p/114609086) [[5]卷积核(kernel)和过滤器(filter)的区别](https://medlen.blog.csdn.net/article/details/109906338?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control)
×
Sign in
Email
Password
Forgot password
or
Sign in via Google
Sign in via Facebook
Sign in via X(Twitter)
Sign in via GitHub
Sign in via Dropbox
Sign in with Wallet
Wallet (
)
Connect another wallet
Continue with a different method
New to HackMD?
Sign up
By signing in, you agree to our
terms of service
.