<h1 class="r-fit-text">台灣語言的網路應用</h1>
[江豪文](https://howard-haowen.rohan.tw/)
課程:台大自然語言處理與網路應用
2022-11-26
---
# 大綱
- 我的背景
- Streamlit App (full-stack Python)
- AI模型輔助語言學習
- 台灣南島語-華語句庫資料集
- React App (JavaScript, TypeScript)
- 台灣語言Wordle遊戲
---
# 我的背景
----
## 教育

----
## 學界經驗
- 東吳大學、台北科技大學英文講師
- 北京大學博雅博士後

----
## 業界經驗
- 哈瑪星科技、港商慧科訊業AI工程師

----
- 現職:新光人壽數據分析襄理

---
<h1 class="r-fit-text">AI模型輔助語言學習</h1>
[點我開啟APP](https://share.streamlit.io/howard-haowen/spacy-streamlit/app.py)
----
## Stacks
- NLP模型: [spaCy](https://spacy.io/)
- 前端: [Streamlit](https://streamlit.io/)
- 部署: [Streamlit Cloud](https://streamlit.io/cloud)
- 程式與資料倉儲: [GitHub](https://github.com)
----
## 開發環境
- 拋棄式
- [開啟Binder](https://mybinder.org/v2/gh/howard-haowen/spacy-streamlit/HEAD)
- 永久式
- Fork [my repo](https://github.com/howard-haowen/spacy-streamlit)
- Connect [VS Code for the Web](https://vscode.dev/) to your forked repo
- Create an account on [Streamlit Cloud](https://streamlit.io/cloud)
- Create an APP using your forked repo
----
## 檔案架構
```txt=
README.md
app.py
jieba
models.json
pages
|-- 01_\360\237\215\212Mandarin.py"
|-- 02_\360\237\215\243Japanese.py"
|-- 03_\360\237\215\224English.py"
requirements.txt
tocfl_wordlist.csv
```
----
## Streamlit Cloud[依賴設定](https://docs.streamlit.io/streamlit-cloud/get-started/deploy-an-app/app-dependencies)
- pip: `requirements.txt`
- conda: `environment.yml`
- pipenv: `Pipfile`
- poetry: `project.toml`
----
## `requirements.txt`
```txt=
# ja_ginza is a Japanese model with a lemmatizer and a morphologizer more fine-grained than the default one in spaCy
ginza
ja_ginza
# ja_ginza depends on spacy>=3.2.0,<3.3.0
spacy>=3.2.0,<3.3.0
spacy-streamlit>=1.0.0rc1,<1.1.0
spacy-wordnet
# spacy-wordnet depends on nltk
nltk
# sapCy models
https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.2.0/zh_core_web_sm-3.2.0.tar.gz#egg=zh_core_web_sm
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.2.0/en_core_web_sm-3.2.0.tar.gz#egg=en_core_web_sm
# conversion between hanzi and transcriptions
dragonmapper
# Jisho online Japanese dictionary
jisho_api
# YAKE keyword extraction
spacy-ke
# interactive plotting
plotly
```
----
## app.py
- 程式進入點
```python=
import streamlit as st
st.markdown("""
# AI模型輔助語言學習
## Language Learning Assisted by AI Models
- 開啟左側選單可選擇語言,目前支援華語、日語和英語。
- Select a language from the sidebar. Supported languages include Mandarin, Japanese, and English.
- 選單自動隱藏時,點選左上角 > 符號以開啟選單。
- If the sidebar is hidden, click on the > symbol in the upper left corner to open it.
""")
```
----
## pages/01_:tangerine:Mandarin.py
- 選擇斷詞模型
```python=130
selected_tokenizer = st.radio("請選擇斷詞模型", ["jieba-TW", "spaCy"])
if selected_tokenizer == "jieba-TW":
nlp.tokenizer = JiebaTokenizer(nlp.vocab)
```
----
## pages/01_:tangerine:Mandarin.py
- 用[jieba-tw](https://github.com/APCLab/jieba-tw)取代spaCy內建斷詞模型
```python=49
class JiebaTokenizer:
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = jieba.cut(text) # returns a generator
tokens = list(words) # convert the genetator to a list
spaces = [False] * len(tokens)
doc = Doc(self.vocab, words=tokens, spaces=spaces)
return doc
```
----
## pages/01_:tangerine:Mandarin.py
- 使用[spaCy Token API](https://spacy.io/api/token)過濾tokens
```python=61
def filter_tokens(doc):
clean_tokens = [tok for tok in doc if tok.pos_ not in PUNCT_SYM]
clean_tokens = (
[tok for tok in clean_tokens if
not tok.like_email and
not tok.like_num and
not tok.like_url and
not tok.is_space]
)
return clean_tokens
```
----
## pages/01_:tangerine:Mandarin.py
- 選擇各種輔助功能
```python=141
st.info("請勾選以下至少一項功能")
# keywords_extraction = st.sidebar.checkbox("關鍵詞分析", False) # YAKE doesn't work for Chinese texts
analyzed_text = st.checkbox("增強文本", True)
defs_examples = st.checkbox("單詞解析", True)
# morphology = st.sidebar.checkbox("詞形變化", True)
freq_count = st.checkbox("詞頻統計", True)
ner_viz = st.checkbox("命名實體", True)
tok_table = st.checkbox("斷詞特徵", False)
```
----
## pages/01_:tangerine:Mandarin.py
- 命名實體視覺化跟斷詞特徵都是spaCy內建功能
```python=204
if ner_viz:
ner_labels = nlp.get_pipe("ner").labels
visualize_ner(doc, labels=ner_labels, show_table=False, title="命名實體")
if tok_table:
visualize_tokens(doc, attrs=["text", "pos_", "tag_", "dep_", "head"], title="斷詞特徵")
```
----
## pages/01_:tangerine:Mandarin.py
- 增強文本依賴套件[dragonmapper](https://pypi.org/project/dragonmapper/)
```python=150
if analyzed_text:
st.markdown("## 增強文本")
pronunciation = st.radio("請選擇輔助發音類型", ["漢語拼音", "注音符號", "國際音標"])
for idx, sent in enumerate(doc.sents):
tokens_text = [tok.text for tok in sent if tok.pos_ not in PUNCT_SYM]
pinyins = [hanzi.to_pinyin(word) for word in tokens_text]
sounds = pinyins
if pronunciation == "注音符號":
zhuyins = [transcriptions.pinyin_to_zhuyin(word) for word in pinyins]
sounds = zhuyins
elif pronunciation == "國際音標":
ipas = [transcriptions.pinyin_to_ipa(word) for word in pinyins]
sounds = ipas
```
----
## pages/01_:tangerine:Mandarin.py
- 單詞解析依賴[萌典API](https://github.com/g0v/moedict-webkit)
```python=22
def moedict_caller(word):
st.write(f"### {word}")
req = requests.get(f"https://www.moedict.tw/uni/{word}.json")
try:
definitions = req.json().get('heteronyms')[0].get('definitions')
df = pd.DataFrame(definitions)
df.fillna("---", inplace=True)
if 'example' not in df.columns:
df['example'] = '---'
if 'synonyms' not in df.columns:
df['synonyms'] = '---'
if 'antonyms' not in df.columns:
df['antonyms'] = '---'
cols = ['def', 'example', 'synonyms', 'antonyms']
df = df[cols]
df.rename(columns={
'def': '解釋',
'example': '例句',
'synonyms': '同義詞',
'antonyms': '反義詞',
}, inplace=True)
with st.expander("點擊 + 查看結果"):
st.table(df)
except:
st.write("查無結果")
```
----
## pages/01_:tangerine:Mandarin.py
- `單詞解析`附加功能: 根據[華語八千詞](http://huayutools.mtc.ntnu.edu.tw/ts/TextSegmentation.aspx)詞彙分級統計比例
```python=99
def get_level_pie(tocfl_result):
level = tocfl_result['詞條分級'].value_counts()
fig = px.pie(tocfl_result,
values=level.values,
names=level.index,
title='詞彙分級圓餅圖')
return fig
```
---
<h1 class="r-fit-text">台灣南島語-華語句庫資料集</h1>
[點我開啟APP](http://howard-haowen.rohan.tw/Formosan-languages/)
----
## Stacks
- 前端: [Streamlit](https://streamlit.io/)
- 部署: [Streamlit Cloud](https://streamlit.io/cloud)
- 程式與資料倉儲: [GitHub](https://github.com)
----
## 開發環境
- 拋棄式
- [開啟Binder](https://mybinder.org/v2/gh/howard-haowen/Formosan-languages/HEAD)
- 永久式
- Fork [my repo](https://github.com/howard-haowen/Formosan-languages)
- Connect [VS Code for the Web](https://vscode.dev/) to your forked repo
- Create an account on [Streamlit Cloud](https://streamlit.io/cloud)
- Create an APP using your forked repo
----
## 檔案架構
```txt=
README.md
app.py
requirements.txt
Formosan-Mandarin_sent_pairs_139023entries.pkl
```
----
## `requirements.txt`
```txt=
streamlit
pandas
pandas_profiling
jupyterlab-git
```
----
## app.py
- 緩存資料庫
```python=129
@st.cache #import streamlit as st
def get_data():
df = pd.read_pickle('Formosan-Mandarin_sent_pairs_139023entries.pkl')
df = df.astype(str, errors='ignore')
df = df.applymap(lambda x: x[1:] if x.startswith(".") else x)
df = df.applymap(lambda x: x.strip())
filt = df.Ch.apply(len) < 5
df = df[~filt]
return df
```
----
## app.py
- 緩存資料彙整報告
```python=140
def get_report(): #from pandas_profiling import ProfileReport
df = get_data()
report = ProfileReport(df, title='Report', minimal=True).to_html()
return report
```
----
## app.py
- 依據用戶提供條件過濾資料庫
- `資料來源`
```python=52
sources = st.sidebar.multiselect(
"請選擇資料來源",
options=source_set,
default='詞典',)
```
```python=66
s_filt = df['來源'].isin(sources)
```
----
## app.py
- 依據用戶提供條件過濾資料庫
- 資料來源
- `查詢對象語言別`
```python=56
langs = st.sidebar.selectbox(
"請選擇語言",
options=['布農','阿美','撒奇萊雅','噶瑪蘭','魯凱','排灣','卑南',
'泰雅','賽德克','太魯閣','鄒','拉阿魯哇','卡那卡那富',
'邵','賽夏','達悟'],)
```
```python=69
if langs == "噶瑪蘭":
l_filt = df['Language'] == "Kavalan"
elif langs == "阿美":
l_filt = df['Language'] == "Amis"
```
----
## app.py
- 依據用戶提供條件過濾資料庫
- 資料來源
- 查詢對象語言別
- `關鍵詞查詢語言別`
```python=61
texts = st.sidebar.radio(
"請選擇關鍵詞查詢文字類別",
options=['華語','族語'],)
```
```python=103
text_box = st.sidebar.text_input('在下方輸入華語或族語,按下ENTER後便會自動更新查詢結果')
# search for keywords in Mandarin or Formosan
t_filt = df[texts].str.contains(text_box, flags=re.IGNORECASE)
```
----
## app.py
- 依據用戶提供條件過濾資料庫
- 資料來源
- 查詢對象語言別
- 關鍵詞查詢語言別
```python=109
filt_df = df[(s_filt)&(l_filt)&(t_filt)]
```
---
<h1 class="r-fit-text">台灣語言Wordle遊戲</h1>
- 原始遊戲: [英語Wordle](https://www.nytimes.com/games/wordle/index.html)
- 靈感來源: [AnyLanguage-Wordle](https://github.com/roedoejet/AnyLanguage-Wordle)
- 台灣語言Wordle
- [台灣閩南語](https://howard-haowen.github.io/tsm-wordle/)
- [排灣語](https://howard-haowen.github.io/paiwan-wordle/)
- [阿美語](https://howard-haowen.github.io/amis-wordle/)
----
## Stacks
- 前端: [React](https://reactjs.org/)
- 部署: [GitHub Pages](https://pages.github.com/)
- CI/CD: [GitHub Actions](https://github.com/features/actions)
- 程式與資料倉儲: [GitHub](https://github.com)
- [台灣閩南語](https://github.com/howard-haowen/tsm-wordle)
- [排灣語](https://github.com/howard-haowen/paiwan-wordle)
- [阿美語](https://github.com/howard-haowen/amis-wordle)
----
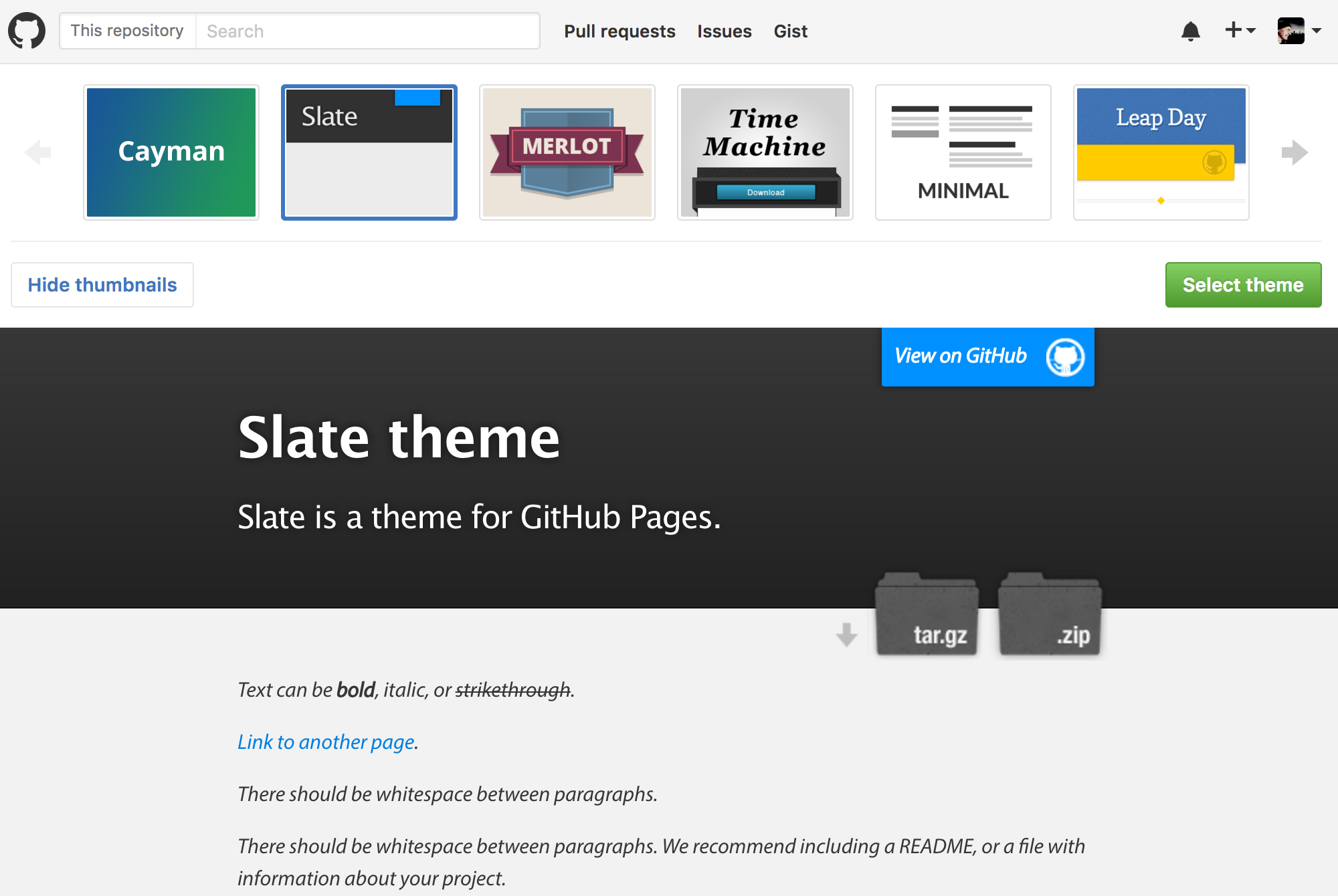
## GitHub Pages
- 免費部署靜態網頁([範例](https://howard-haowen.rohan.tw/))
----
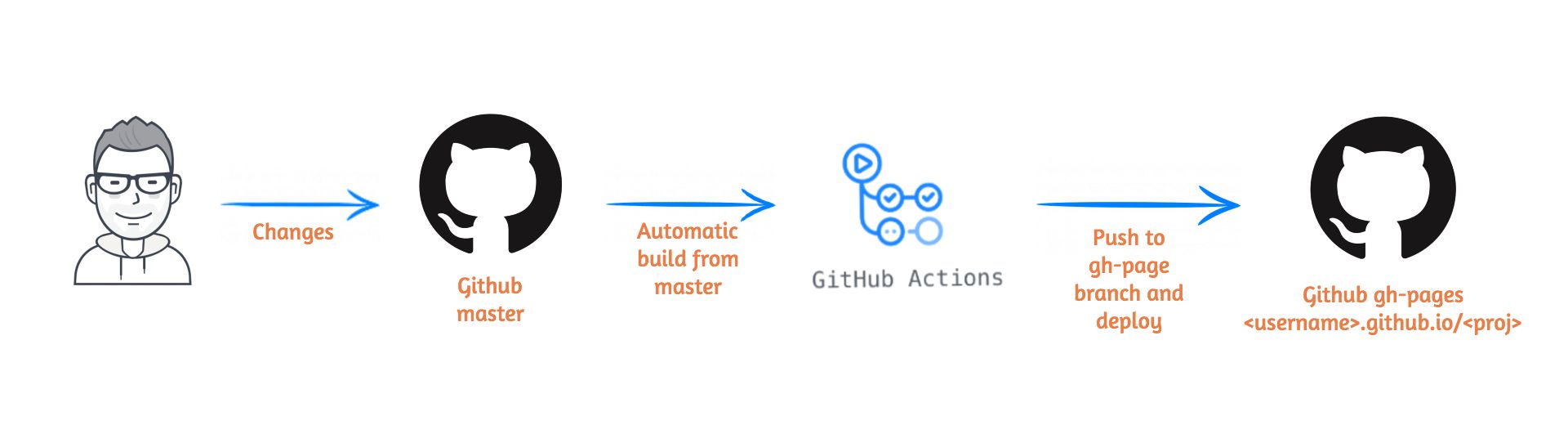
## GitHub Actions
- 免費自動化測試與部署
----
## [排灣語Wordle](https://github.com/howard-haowen/paiwan-wordle)檔案架構
```txt=
.env
.github
|-- workflows
| |-- publish.yml
.gitignore
.husky
|-- .gitignore
|-- pre-commit
.prettierrc
.vscode
|-- settings.json
Dockerfile
LICENSE
README.md
index.html
package-lock.json
package.json
postcss.config.js
public
|-- favicon.ico
|-- index.html
|-- locales
| |-- en
| | |-- translation.json
| |-- es
| | |-- translation.json
| |-- zh
| | |-- translation.json
|-- logo192.png
|-- logo512.png
|-- manifest.json
|-- robots.txt
src
|-- App.css
|-- App.test.tsx
|-- App.tsx
|-- components
| |-- alerts
| | |-- Alert.tsx
| |-- grid
| | |-- Cell.tsx
| | |-- CompletedRow.tsx
| | |-- CurrentRow.tsx
| | |-- EmptyRow.tsx
| | |-- Grid.tsx
| |-- keyboard
| | |-- Key.tsx
| | |-- Keyboard.tsx
| |-- mini-grid
| | |-- MiniCell.tsx
| | |-- MiniCompletedRow.tsx
| | |-- MiniGrid.tsx
| |-- modals
| | |-- AboutModal.tsx
| | |-- BaseModal.tsx
| | |-- InfoModal.tsx
| | |-- StatsModal.tsx
| | |-- TranslateModal.tsx
| |-- stats
| | |-- Histogram.tsx
| | |-- Progress.tsx
| | |-- StatBar.tsx
|-- constants
| |-- config.ts
| |-- orthography.ts
| |-- validGuesses.ts
| |-- wordlist.ts
|-- i18n.ts
|-- index.css
|-- index.tsx
|-- lib
| |-- keyboard.ts
| |-- localStorage.ts
| |-- share.ts
| |-- stats.ts
| |-- statuses.ts
| |-- tokenizer.ts
| |-- words.ts
|-- logo.svg
|-- react-app-env.d.ts
|-- reportWebVitals.ts
|-- setupTests.ts
tailwind.config.js
tsconfig.json
update_log.md
```
----
- 需要客製化修改的部分
```txt=
.github
|-- workflows
| |-- publish.yml
package.json
public
|-- locales
| |-- en
| | |-- translation.json
| |-- es
| | |-- translation.json
| |-- zh
| | |-- translation.json
src
|-- constants
| |-- config.ts
| |-- orthography.ts
| |-- validGuesses.ts
| |-- wordlist.ts
```
----
## 資料來源
- 台灣南島語: [台灣南島語-華語句庫資料集](https://github.com/howard-haowen/Formosan-languages)
- 台灣閩南語: [教育部臺灣閩南語常用詞辭典](https://github.com/g0v/moedict-data-twblg)
----
## 資料準備
- 書寫單位表 `src/constants/orthography.ts`
```typescript=
import { CONFIG } from './config'
export const ORTHOGRAPHY = [
'a',
'b',
'c',
'd',
'dj',
'dr',
'e',
'g',
'h',
'i',
'j',
'k',
'l',
'lj',
'm',
'n',
'ng',
'o',
'p',
'q',
'r',
's',
't',
'tj',
'u',
'v',
'w',
'y',
'z',
]
if (CONFIG.normalization) {
ORTHOGRAPHY.forEach(
(val, i) => (ORTHOGRAPHY[i] = val.normalize(CONFIG.normalization))
)
}
```
----
- 合法詞詞表`src/constants/validGuesses.ts`
```typescript
import { CONFIG } from './config'
export const VALIDGUESSES = [
'timadju',
'aravac',
'nimadju',
'caucau',
'mareka',
]
if (CONFIG.normalization) {
VALIDGUESSES.forEach(
(val, i) => (VALIDGUESSES[i] = val.normalize(CONFIG.normalization))
)
}
```
----
- 謎底詞詞表`src/constants/wordlist.ts`
```typescript
import { CONFIG } from './config'
export const WORDS = [
'timadju',
'aravac',
'nimadju',
'caucau',
'mareka',
]
if (CONFIG.normalization) {
WORDS.forEach((val, i) => (WORDS[i] = val.normalize(CONFIG.normalization)))
}
function shuffle(array: any[]) {
for (let i = array.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1))
;[array[i], array[j]] = [array[j], array[i]]
}
}
if (CONFIG.shuffle) {
shuffle(WORDS)
}
```
----
## 設定參數
- App設定檔`src/constants/config.ts`
```typescript
export const CONFIG = {
tries: 6, // This changes how many tries you get to finish the wordle
language: 'Paiwan', // This changes the display name for your language
wordLength: 6, // This sets how long each word is based on how many characters (as defined in orthography.ts) are in each word
author: 'Haowen Jiang', // Put your name here so people know who made this Wordle!
authorWebsite: 'https://howard-haowen.github.io/', // Put a link to your website or social media here
wordListSource: 'Dataset of Formosan-Mandarin sentence pairs', // Describe the source material for your words here
wordListSourceLink: 'https://share.streamlit.io/howard-haowen/formosan-languages/main/app.py', // Put a link to the source material for your words here
//
// THESE NEXT SETTINGS ARE FOR ADVANCED USERS
//
googleAnalytics: '', // You can use this if you use Google Analytics
shuffle: false, // whether to shuffle the words in the wordlist each time you load the app (note: you will lose the 'word of the day' functionality if this is true)
normalization: 'NFC', // whether to apply Unicode normalization to words and orthography - options: 'NFC', 'NFD', 'NKFC', 'NKFD', false
startDate: 'March 1, 2022 00:00:00', // what date and time to start your game from
defaultLang: 'zh', // the default interface language
availableLangs: ['en', 'zh'], // the options available to the user for translation languages
}
```
----
- App介面語言配對檔`locales/zh/translation.json`
```json=
{
"about": "關於本遊戲",
"gameName": "Pinaiwanan, 排灣語",
"enterKey": "輸入",
"deleteKey": "刪除",
"notEnoughLetters": "字母數不足,請填滿方塊",
"wordNotFound": "查無此單詞",
"solution": "正解為 {{solution}}",
"gameCopied": "已將您的輝煌戰績複製至剪貼簿,開始分享吧!",
"howToPlay": "遊戲規則",
"instructions": "您總共有 {{tries}} 次猜測單詞的機會。輸入的詞必須填滿所有方塊。每輸入一個單詞,方塊將會改變顏色,透過顏色的變化您將能推測正解。",
"pickYourLanguage": "選擇語言",
"correctSpotInstructions": "字母 T 出現在正解當中,並且在正確的位置。",
"wrongSpotInstructions": "字母 Y 出現在正解當中,但不在正確的位置。",
"notInWordInstructions": "字母 U 不在正解當中。",
"guessDistribution": "猜詞分佈",
"statistics": "統計",
"totalTries": "總猜測次數",
"successRate": "成功率",
"currentStreak": "當前連續獲勝次數",
"bestStreak": "最佳連續獲勝次數",
"newWordCountdown": "距離下個新單詞出現還有",
"share": "分享",
"winMessages": [
"太棒了!",
"完美!",
"做得好!"
],
"firstExampleWord": [{
"letter": "T",
"highlight": true
},
{
"letter": "I",
"highlight": false
},
{
"letter": "M",
"highlight": false
},
{
"letter": "A",
"highlight": false
},
{
"letter": "DJ",
"highlight": false
},
{
"letter": "U",
"highlight": false
}
],
"secondExampleWord": [{
"letter": "P",
"highlight": false
},
{
"letter": "A",
"highlight": false
},
{
"letter": "Y",
"highlight": true
},
{
"letter": "U",
"highlight": false
},
{
"letter": "A",
"highlight": false
},
{
"letter": "N",
"highlight": false
}
],
"thirdExampleWord": [{
"letter": "TJ",
"highlight": false
},
{
"letter": "U",
"highlight": false
},
{
"letter": "R",
"highlight": false
},
{
"letter": "U",
"highlight": false
},
{
"letter": "V",
"highlight": false
},
{
"letter": "U",
"highlight": true
}
],
"aboutAuthorSentence": "本遊戲源自 Wordle 開源專案,由<3>{{author}}</3>改編為排灣語版本。",
"aboutCodeSentence": "原專案作者為<3>Hannah Park</3>,原始碼在<1>the original code</1>。本遊戲的開發依據為<5>Aidan Pine's fork</5>。",
"aboutDataSentence": "本遊戲的單詞來源為 <1>{{wordListSource}}</1>。",
"aboutOriginalSentence": "您也可以前往 <1>here</1> 玩一玩原版的 Wordle 喔!",
"languages": {
"zh": "中文",
"en": "English"
}
}
```
----
## 自動化測試與部署
- Yaml設定檔名稱沒有限制`publish.yml`
- 但設定檔路徑一定要在`.github/workflows/`之下
- npm套件安裝依據專案目錄下的`package.json`
```yaml=
name: Deploy
on:
pull_request:
push:
branches:
- main
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Install
run: |
npm install
- name: Test
run: |
npm run test
- name: Build
run: |
npm run-script build
- name: Deploy 🚀
uses: JamesIves/github-pages-deploy-action@v4.2.3
with:
branch: gh-pages # The branch the action should deploy to.
folder: build # The folder the action should deploy.
```
---
# 作業
- 任選一項
- Fork[AI模型輔助語言學習APP](https://github.com/howard-haowen/spacy-streamlit),新增一個語言後([spaCy模型所支援的語言](https://spacy.io/models)),發出pull request
- 仿照台灣南島語-華語句庫資料集,製作一個文本類型的資料庫APP,文本來源自選
- 新增一個台灣語言Wordle遊戲(排除台灣南島語、排灣語、阿美語)
{"metaMigratedAt":"2023-06-17T13:48:00.214Z","metaMigratedFrom":"YAML","title":"台灣語言的網路應用","breaks":true,"slideOptions":"{\"theme\":\"league\",\"margin\":0.1,\"transition\":\"convex\",\"transitionSpeed\":\"default\",\"backgroundTransition\":\"none\",\"progress\":true,\"slideNumber\":true,\"keyboard\":true,\"parallaxBackgroundImage\":\"https://s3.amazonaws.com/hakim-static/reveal-js/reveal-parallax-1.jpg\",\"spotlight\":{\"enabled\":false}}","contributors":"[{\"id\":\"03b5a868-6e13-4235-865b-93b8daff827d\",\"add\":26091,\"del\":6075}]"}