# AI 影像辨識

----
* Pre-Deep Learning Era
* Computer Vision methods
* Deep Learning Era
* two-stage learning
* one-stage learning
----
## Pre-Deep Learning Era
<div style="text-align: left;">
在深度學習(Deep Learning)普及之前,影像辨識主要依賴手動設計的特徵,如SIFT(Scale-Invariant Feature Transform)和HOG(Histograms of Oriented Gradients)等。
</div>
----
## Deep Learning Era
[PaperWithCode](https://paperswithcode.com/sota/object-detection-on-coco)

----
## 介紹一些影像辨識常用的方法
* FPN
* Region Proposal
* Anchor
* NMS
----
## Feature Pyramid Network(FPN)
**特徵金字塔**是一種用於多尺度目標檢測的方法。它通過在不同層級的特徵圖上建立金字塔結構,從而實現在不同尺度上進行目標檢測和分類。FPN的目標是解決不同尺度目標的檢測問題,提高檢測的準確性。
----
## Region Proposal
使用特殊方法找出物件候選框的這個過程
* selective search
* Region proposal network
----
### Selective search
<div style="text-align: left;">
根據圖像中的像素相似性和空間鄰近性,將相似的區域進行合併,形成具有不同尺度和形狀的候選區域。這樣的合併過程可以將圖像中可能包含目標物體的區域聚合到一起
優點是能夠生成多尺度、多形狀的候選區域,不需要預先定義的錨框,可以靈活地適應不同的目標和場景
缺點是計算量較大,因為它需要對圖像中的大量區域進行計算和合併
</div>
----
### Region proposal network
<div style="text-align: left;">
主要目標是在圖像中生成一組可能包含目標的區域提議,這些提議將作為後續目標檢測的輸入
RPN通常作為一個獨立的子網絡嵌入在目標檢測模型中,例如Faster R-CNN
</div>
----
## Anchor
<div style="text-align: left;">
錨框(anchors)是具有不同長寬比和尺度的矩形框,它們覆蓋了可能出現目標的各種形狀和大小
在訓練過程中,模型會在可能的物件位置放置一組預先定義好的錨框,並預測每個錨框內是否包含目標以及目標的位置偏移量
</div>
----
## Anchor-free
<div style="text-align: left;">
Anchor-free 方法不使用預先定義的錨框(anchors),而是直接預測目標的位置和類別
通過深度學習模型直接預測目標的位置和類別。這樣可以減少設計和調整錨框的工作量,同時適應不同形狀和尺度的目標
</div>
----
## Non-Maximum Suppression(NMS)
<div style="text-align: left;">
非極大值抑制是目標檢測中常用的一種後處理技術。
在目標檢測任務中,模型通常會生成多個候選區域或檢測框,這些框可能重疊或者檢測到同一個目標。NMS的目的是選擇最具代表性的檢測框,去除重疊的框,以達到減少重複檢測並保留最佳檢測結果的效果。
</div>
----
### NMS 成果

---
# Two-stage learning

----
## What is two-stage learning
<div style="text-align: left;">
學習過程被分為兩個或多個階段,每個階段執行不同的任務。
常見的作法分成兩階段
1. 候選區域生成(Region Proposal Generation)
2. 候選區域分類和定位(Region Classification and Localization)
知名網路有RCNN、Faster-RCNN、Mask-RCNN
</div>
----
## Pros
* 在提出時大大提高了物件偵測的精確度
* 可以更好地組織學習過程,將複雜的任務分解為多個子任務。
## Cons
* 增加了系統的複雜性
* 計算效率低,需要對每個找到的區域,單獨作特徵萃取
----
例如這麼多物件出現的時候就會很慢

----
### RCNN

----
### Faster RCNN

----
### Mask RCNN

---
# One-stage learning

----
## What is one-stage learning
<div style="text-align: left;">
模型直接從原始數據中學習預測結果,無需額外的中間步驟或子模型。一階段學習的目標可能是分類、回歸或其他機器學習任務。
知名網路有SSD、YOLO系列、U-Net、FCOS、DETR
</div>
----
## Pros
* 簡單且高效,適合快速訓練和實時預測
* 不需要額外的步驟或模型,它具有較低的計算成本和更快的推理速度
## Cons
* 部份場景準確度較低,對類別不平衡和重疊目標的處理較為困難
----
### SSD(Single Shot MultiBox Detector)

----
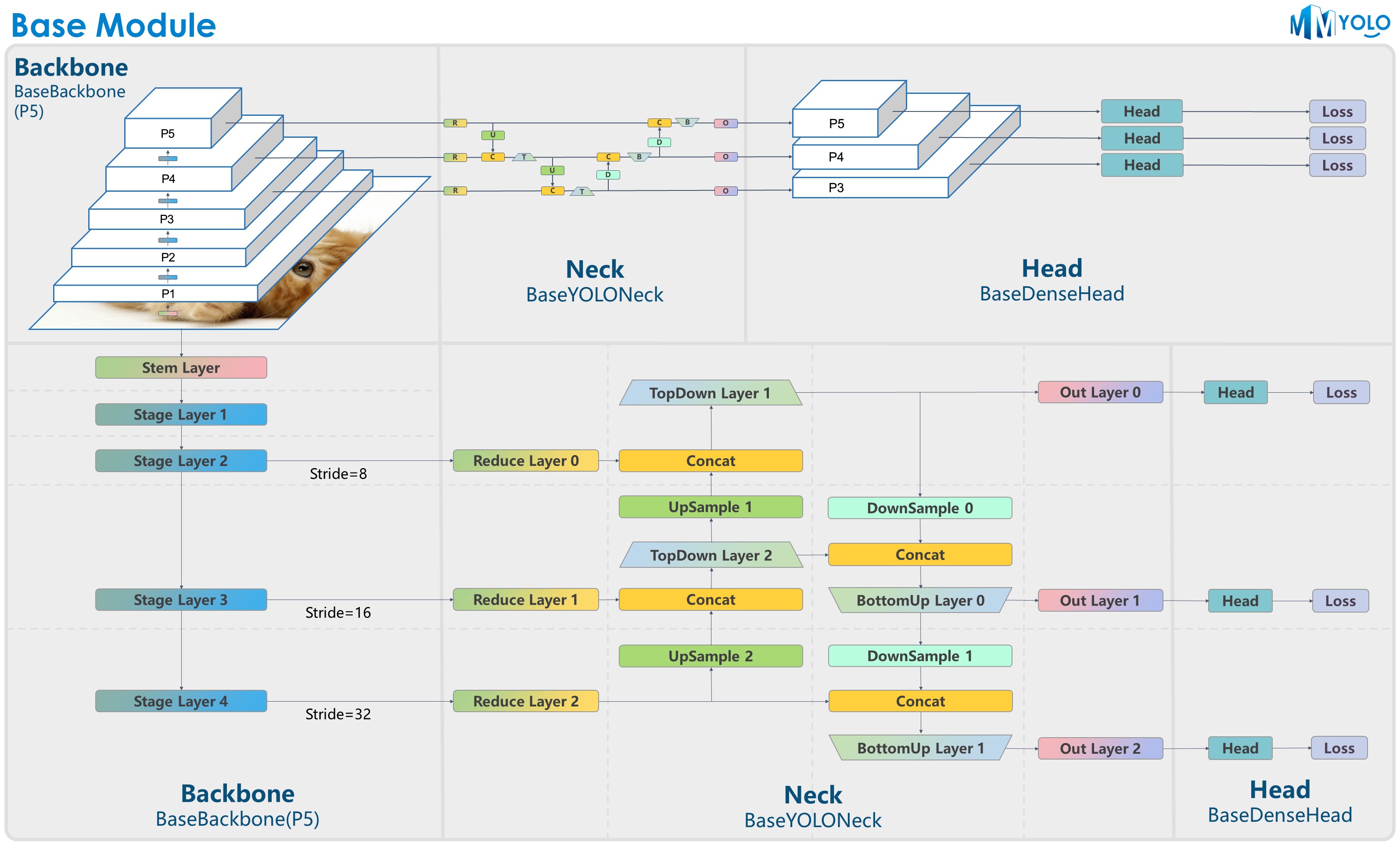
### YOLO系列(You only look once)

----
#### YOLO basic
----
### Fully Convolutional One-Stage Object Detection(FCOS)

----
### U-Net

---
### DETR(Detection with Transformer)

----
1. 影像會先透過傳統的CNN (比如說ResNet) 抽出feature
2. feature送到以Transformer組成的auto-encoder網路中
3. 輸出一組N個set prediction,每個set包含box center、scale與object class。
----
{"metaMigratedAt":"2023-06-18T06:49:39.006Z","metaMigratedFrom":"YAML","title":"Week 13 - AI影像辨識","breaks":true,"description":"地獄貓旅行團第 19 週心得分享","slideOptions":"{\"theme\":\"dark\",\"transition\":\"fade\",\"previewLinks\":true}","contributors":"[{\"id\":\"8563c208-7f7f-4bea-90b4-ccf166190995\",\"add\":6669,\"del\":2870}]"}