<style>
.cols{
display: flex;
}
.col {
flex: 1;
}
</style>
# Practical Time Series Analysis
---
<!-- [TOC]
--- -->
## What are Time Series?
- Data points indexed in time order
- Time introduces a unique set of problems

Note:
- Most of our data are time series
- Why is it difficult? Time importance, speed, shift, amplitude...
- How long, and how many data points in the past? Is it changing?
---
## Time Series Tasks
- Forecasting
- Anomaly detection
- Clustering
- Classification
Note:
- What is the most important step in the analysis?
---
## Data Preparation
<div class="cols">
<div class="col">
- Longest & the most important step
- Garbage in = garbage out!
- Try to gather some domain knowledge
- It is always application specific
</div>
<div class="col">
<img style="float: right;" src="https://www.oreilly.com/api/v2/epubs/9781788838535/files/assets/2f80aca9-1de1-420d-8633-eb6f7e987398.jpg">
</div>
</div>
Note:
- Well-trained monkey can run fit & predict
- Be aware of what is your goal
- Scaling - mean, median, didn't I just lose some information?
- Arcsinh
- Many times way harder than other steps...
---
### Feature Extraction
- Constructing combinations of the variables to get around time
- We can combine them with TS data

Note:
- Many times this is the best approach as we "know" the features
- Usually creating heterogeneous data
- Combination with TS is difficult
- Usage of NN to extract features (transformers, etc.)
---
## Machine Learning Tasks
- Occam's razor
- Proper definition is key
- Start simple and advance gradually
- Try multiple ML families - there is no single best model
Note:
- People tend to blindly follow Internet guides
- heterogeneous vs homogeneous data
---
## Anomaly Detection
<div class="cols">
<div class="col">
- What are anomalies?
- Time series anomalies
- Point outliers
- Sequence outliers
- Shape/behavior Anomaly
<sub>https://arxiv.org/pdf/2002.04236.pdf</sub>
</div>
<div class="col">


</div>
</div>
Note:
- It's hard as there are not many anomalies
- Recall-precision trade-off
- Usually, noone can tell you if it's an anomaly
- Try to gather some "human" data
---
### Anomaly Detection Methods
- STL decomposition
- Tree & density approaches (Isolation Forest, LODA)
- Neural Networks (Auto-Encoders)
- Forecasting

Note:
- STL - Robust, simple, well studied, Changes like Corona
- Tree and density - not really for time series
- Auto Encoders - NN problems (more on that later)
- Forecasting - error cumulation, is my forecast really good?
---
### Isolation Forest
<div class="cols">
<div class="col">
- Binary tree
- Anomalies are "easy" to isolate
- Random orthogonal boundaries
- Scale invariance
</div>
<div class="col">


</div>
</div>
---
### LODA: Lightweight On-line Detector of Anomalies
<div class="cols">
<div class="col">
- Random projections and histograms ([1])
- Very fast and scalable
- Randomness adds robustness
- Anomaly explanation
</div>
<div class="col">

</div>
</div>
[1]: http://agents.fel.cvut.cz/stegodata/pdfs/Pev15-Loda.pdf
---
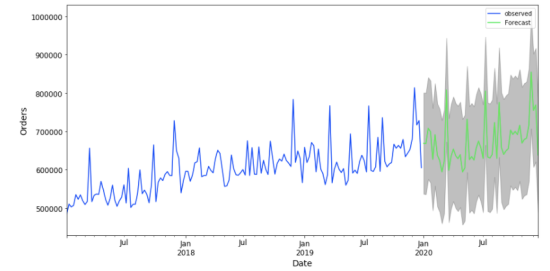
## Forecasting
- Predicting the future from historic values
- Good error metric is essential!
- Can we predict a "random" series?
Note:
- Practical things
- Why do we want to forecast?
- Chaotic and random time series
- Do we have all the data
- Does our time series depend
- Good error metric is essential!
- We don't need a good prediction when nothing is happening
---
### Model Validation
- Don't use the future to predict the future!
- Notice big changes in data (change points)
- Cross-validation & moving window

---
### Forecasting Approaches
- STL decomposition
- Auto ARIMA
- Facebook Prophet
- Classic ML
- Time Frame Shifting
- Neural Networks
- Recurrent NN and LSTM
- CNN (SCINet)
- Decomposition (N-BEATS)
- Transformers (LTSF-Linear, Informer, etc.)
Note:
- Stability
- Cost vs effectiveness
- Always fact-check with a simple model
- heterogeneous vs homogeneous data
- Don't use a tank to kill a fly
- NN practical problems - Number of parameters (LSTM)
---
### Facebook Prophet
- Decomposing TS as $y(t) = g(t) + s(t) + h(t) + et$

Note:
- Start with Auto-Arima
- Simple and automatic holiday support
- Kinda slow
---
### N-BEATS

Note:
- Quite simple NN
- We can check output of every layer
- Still, we need to scale our data
---
## Clasification & Clustering
- DTW, shape-based approaches, Hidden Markov Model
- Other ML approaches using DTW as metric or using DTW distance matrix

Note:
- 1NN DTW - surprisingly good and simple
- Time & Space complexity
- Not a metric nor derivable!
- sDTW - usage with NN
- HMM - complexity
---
## Interesting Links
- Feature Extraction - [tsfresh](https://github.com/blue-yonder/tsfresh)
- Forecasting:
- [Sktime](https://github.com/sktime/sktime) & [tslearn](https://tslearn.readthedocs.io/en/stable/)
- Nixtla repositories
- [Stats Forecast](https://github.com/Nixtla/statsforecast)
- [Neural Forecast](https://github.com/Nixtla/neuralforecast)
- Auto Arima - [pmdarima](https://alkaline-ml.com/pmdarima/)
---
Thank you for your attention!
Questions?
{"metaMigratedAt":"2023-06-18T01:43:53.802Z","metaMigratedFrom":"YAML","title":"Practical Time Series Analysis","breaks":false,"slideOptions":"{\"theme\":\"white\",\"transition\":\"fade\",\"allottedMinutes\":45}","contributors":"[{\"id\":\"6d7a4e51-d421-4102-8827-f7baefb76f0e\",\"add\":10378,\"del\":10387}]"}