# [WIP] GT4Py Architecture
###### tags: `architecture` `functional`
## Context
The GT4Py framework transforms any input which can be translated to Iterator IR or *ITIR* (a declarative representation of stencil computations encoded in a minimal custom LISP-like dialect) and generates actual implementations for different computing platforms. To reach this goal, it is needed to design extensible mechanisms for the generation of ITIR representations from different user-facing higher-level Python-like syntactic specifications (_frontend_), and for the generation of the high-performance implementations for different platforms (_backend_).
## Requirements (from *shaping*)
- General infrastructure
+ Fast fingerprinting of DSL sources (decoupled from frontend parsing).
+ Efficient caching of already generated binaries:
+ Configurable
+ Shareable between multiple users/nodes running in the same cluster (multi-layered?)
+ Efficient mechanism to load generated Python extensions (if running in Python mode)
+ Optionally, investigate if modern Python versions have added module unloading capabilities or other alternatives like using stubs (e.g. DaCe?)
+ Configuration system for the toolchain accessible from:
+ Environment variables
+ Configuration files (INI? YAML? JSON? NestedText?)
+ Python API
+ CLI-friendly: support for programatic access of the infrastructure functionality decouple from the user API.
- Analysis and code-generation toolchain
+ Support for multiple frontend parsers, considering as a _frontend_ any text string which can be lowered to a valid Iterator IR program.
+ Support for multiple code-generation backends, considering as a _backend_, a specific hardware platform + software API (e.g. CUDA GPU + GridTools C++, Intel CPU + OpenMP, ...).
+ A flexible mechanism to build analysis and lowering pipelines from a combination of transformation/verification passes.
+ Support for automatic generation of bindings to multiple languages (not only Python)
- Compatible with the new _no-storages_ design for memory allocation (basically, only provide allocation functions, not _Storage_ objects)
- Compatible with running in purely embedded mode without using the toolchain
## Architecture overview
The following design for GT4Py splits the implementation in separate subsystems interacting to each other through simple interfaces. This modular design should allow the composition of arbitrary implementations of each component without affecting other subsystems.
### Approximate workflow
```mermaid
flowchart TB
User--"Definition"-->Frontend
subgraph compiler["Compiler"]
Frontend--"DefinitionId"-->SourceCache
SourceCache--"Itir"-->Transformation1
Frontend--"Itir"-->Transformation1
SourceCache--"ProjectId"-->ProjectCache
subgraph pipe["Pipeline"]
subgraph transformations[Transformations]
T["..."]
Transformation1-->T
T-->TransformationN
end
TransformationN-->Backend
end
Backend--"Project"-->ProjectTransformer1
Backend--"ProjectId,Project"-->ProjectCache
subgraph ptransformers[ProjectTransformers]
PT["..."]
ProjectTransformer1-->PT
PT-->ProjectTransformerN
end
ProjectTransformerN--"ProjectId,Project"-->ProjectCache
end
ProjectCache--"Project"-->Output
```
## Subsystems
### Compiler
The compiler subsystem encapsulates all the different functionality provided by other subsystems in a single component with the entry points for user/client.
```mermaid
classDiagram
direction LR
class Compiler {
frontend: Frontend
pipeline: Pipeline
post_generators: List[ProjectTransformer]
source_cache: SourceCache
project_cache: ProjectCache
compile(definition) Project
}
Compiler o--> Frontend
Compiler o--> Pipeline
Compiler o--> "*"ProjectTransformer
Compiler o--> ItirCache
Compiler o--> ProjectCache
Compiler ..> Project
User --> Compiler
User --> Project
class Frontend {
transform(Definition) ItirModule
fingerprint(Definition) DefinitionId
}
```
#### `Compiler`
A `Compiler` contains a `Frontend` element to transform input sources in `ItirModule`s, a `Pipeline` of transformations passes with a `Backend` at the end to emit an output `Project`, and a Project
#### `Frontend`
A component that accepts some well-defined input (usually source code) and transforms it into Iterator IR. It is also responsible to _fingerprint_ the input data such that all inputs with the same fingerprint generate exactly the same Iterator IR representation.
#### `User`
A `User` is any interface provided to the user to interact with the compiler (e.g., CLI, Python decorators).
### Pipeline: IR transformations
This subsystem deals with the creation and application of a pipeline of analysis and transformation passes transforming Iterator IR modules. A `Pipeline` is a sequence of `Transformation` passes with a `Backend` at the end for the generation of the output code. `Transformation` passes transform the input IR representation to a equivalent IR representation better suited as input for the the code generation `Backend`.
```mermaid
classDiagram
direction BT
class PipelineHook {
name: str
description: str
__call__(Pipeline, ItirModule, PipelinePass | None)
}
Timer ..|> PipelineHook
IRPrinter ..|> PipelineHook
class PipelineEvent {
<<Enum>>
START_PIPELINE
END_PIPELINE
START_TRANSFORMATIONS
END_TRANSFORMATIONS
START_ANALYSIS
END_ANALYSIS
}
class Pipeline {
<<Identifiable>>
name: str
description: str
tranformations: List[Tranformations]
backend: Backend
log_points: Mapping[str, LogPoint]
hooks: Mapping[PipelineEvent, PipelineHook]
results: Dict[str, Result]
generate(ItirModule) Project
}
Pipeline o--> Transformation
Pipeline o--> Backend
Pipeline --> PipelineHook
Pipeline --> PipelineEvent
Pipeline ..> ItirModule
class PipelinePass {
<<Interface>>
name: str
description: str`
log_points: List[LogPoint]
}
PipelinePass o--> LogPoint
class Analysis {
requirements: List[Analysis]
apply(ItirModule) Result
}
Analysis --|> PipelinePass
Analysis o--> Analysis
class Transformation {
requirements: List[Analysis]
apply(ItirModule) ItirModule
}
Transformation --|> PipelinePass
Transformation o--> Analysis
Transformation ..> ItirModule
Analysis ..> ItirModule
class LogValue {
vale: str | Number | List[InfoValue] | Dict[str, InfoValue]
}
class LogPoint {
<<Abstract>>
name: str
description: str
value: LogValue
}
LogPoint --> LogValue
```
#### `Pipeline`
...
#### `Transformation`
...
#### `Analysis`
...
#### `PipelineHook`
...
#### `LogPoint`
...
### Backend: code and bindings generation
A `Backend` is the final component of the compiler pipeline and is in charge of the generation of code `Project` for Iterator IR modules. A `Project` is a self-contained bundle of source code files, headers and build scripts. A `ProjectTransformer` adds extra components to a `Project` like bindings to other languages and validation wrappers.
```mermaid
classDiagram
direction BT
class Backend {
<<Abstract, Identifiable>>
name: str
description: str
device: str
data_layout: Layout
log_points: List[LogPoint]
__init__(**kwargs)
emit(itir: ItirModule) Project
}
Backend --> Project
class Project {
<<Abstract, Serializable>>
project_id: ProjectId
components: List[Components]
status: Property[Status]
device: str
data_layout: Layout
metadata: Mapping[Tag, Any]
build(Path root, **kwargs) Future~Project~
}
Project o--> Component
Project --> Status
CMakeProject ..|> Project
AnyToolProject ..|> Project
class CompositeProject {
__init__(*Projects)
}
CompositeProject ..|> Project
class ProjectTransformer {
<<Protocol>>
transform(Project) Project
}
ProjectTransformer <--> Project
class BindingGenerator {
}
BindingGenerator ..|> ProjectTransformer
class Component {
<<frozen>>
path: Path
API: List[FuctionPrototype]
inputs: List[SourceFile]
options: List[Option]
status: Property[Status]
metadata: Mapping[Tag, Any]
}
Component o--> SourceFile
Component --> Status
class SourceFile {
<<frozen>>
path: Path
content: str | bytes
metadata: Mapping[Tag, Any]
}
class Status {
<<Abstract>>
}
Defined ..|> Status
InProgress ..|> Status
Ready ..|> Status
Error ..|> Status
```
#### `Backend`
A `Backend` is any regular instantiable class implementing the `Backend` interface to emit `Project`s from ITIR modules. Since the `Backend` instance will be passed directly to the compiler pipeline, backend configuration is not a responsibility of the pipeline. Actual `Backend` classes should document its configuration settings and provide a way to specify them, typically at initialization (but other means can be offered too).
#### `Project`
A `Project` is a collection of `Component`s source code and specifications bundled together with a method to build the binary components (if any) using a compiler or other external tools. The expected implementation strategy is to use a standard build tool under the hood (e.g. CMake) to compile `Component`s, and not implementing an *ad-hoc* build system from scratch. `Project`s can be modified by `ProjectTransformer`s classes, typically to add new `Component`s (e.g. bindings to other languages) or to bundle several projects together in a kind of _composite_ `Project`. To make projects relocatable, all paths in `Component`s and `SourceFile`s are relative paths from the (unspecified) project root folder.
#### `ProjectTransformer`
A component to derive new `Project`s from existing ones. The main use case is to add additional `Components` which are orthogonal to the actual ITIR implementation `Component`s provided by the `Backend`, like bindings to other programming languages, or wrappers with extra debugging or logging logic.
#### `Component`
Represents a target text/binary file. After building the project, it is expected that the final component file exists at the (relative) `path`.
#### `SourceFile`
Represents the contents of a source file used to build a `Component`. After building the project, it is expected that a file with the `content` exists at the (relative) `path`.
### Cache: fingerprinting and serialization of generated artifacts
```mermaid
classDiagram
direction RL
class DefinitionId {
<<Tuple[src_hash, symbols_hash]>>
}
DefinitionId ..|> Identifiable
class ProjectId {
<<Tuple[DefinitionId, PipelineId]>>
}
ProjectId ..|> Identifiable
class SaltedId {
<<Tuple[str, Identifiable]>>
}
SaltedId ..|> Identifiable
class Cache~IdentifiableT, SerializableT~ {
<<Abstract, Mapping[IdentifiableT, SerializableT]>>
__get_item__(IdentifiableT) SerializableT
__set_item__(IdentifiableT, SerializableT)
}
Cache ..> Identifiable
Cache ..> Serializable
class ValidatedCache~IdentifiableT, SerializableT~ {
<<Abstract, Mapping[IdentifiableT, SerializableT]>>
salt: str | bytes
}
ValidatedCache --|> Cache
class ChainCache~IdentifiableT, SerializableT~ {
<<Abstract, Mapping[IdentifiableT, SerializableT]>>
caches: List[Cache~IdentifiableT, SerializableT~]
}
ChainCache --|> Cache
class ProjectCache {
<<Abstract, Cache[ProjectId,Project]>>
root: Path
add(Project, *, build=True) Future[Project]
load(ProjectId) Project %
}
ProjectCache ..|> Cache
class SourceCache {
<<Abstract,Cache[DefinitionId,(ItirModule,[ProjectId])]>>
}
SourceCache ..|> Cache
```
#### `Cache`
...
### Config: central configuration facilities
All configurable parameters of the framework are accessible here in a nested *namespace*-like structure. The values of the configuration settings should be easily serializable as strings, which means that only native simple types (`bool`, `int`, `float`, `str`) or native sequence containers (`list`, `tuple`) are allowed as values.
Configuration data can be loaded from hierachical `Mapping[str, Value]`containers, like JSON/YAML mappings or flat containers like `os.environ`using some name-mapping convention for nested keys.
```mermaid
classDiagram
direction BT
class Value {
<<bool | int | float | str | list[Value] | tuple[Value, ...]>>
}
class NestedNamespace {
__getattr__(str) Value
}
NestedNamespace ..> Value
class config {
<<module>>
NestedNamespace: class
registry: NestedNamespace
from_dict(Mapping[str, Value], *, renamer: Mapping[str, str] | Callable[[str], str] = None, merge: bool = True)
to_dict() NestedDict~StrToValue~
get_schema() NestedDict~StrToType~
}
config --> NestedNamespace
```
### Eve: basic concepts and utilities
```mermaid
classDiagram
direction BT
class Tag {
parts: CachedProperty[List[str]]}
Tag --|> str
class Option {
<<frozen>>
name: Tag
value: Any
}
Option --> Tag
ContentHash --|> str16
class Identifiable {
<<Protocol>>
__gt_content_hash__() ContentHash
}
Identifiable --> ContentHash
class Serializable {
<<Protocol>>
__gt_serialize_data_() bytes
__gt_deserialize_data_(bytes) Serializable
__reduce__()
}
```
#### `Identifiable`
...
#### `Serializable`
...
__reduce__() %% Optional, for pickle compatibility: https://blog.dask.org/2018/07/23/protocols-pickle https://github.com/pytorch/pytorch/pull/9184
}
## Packages
[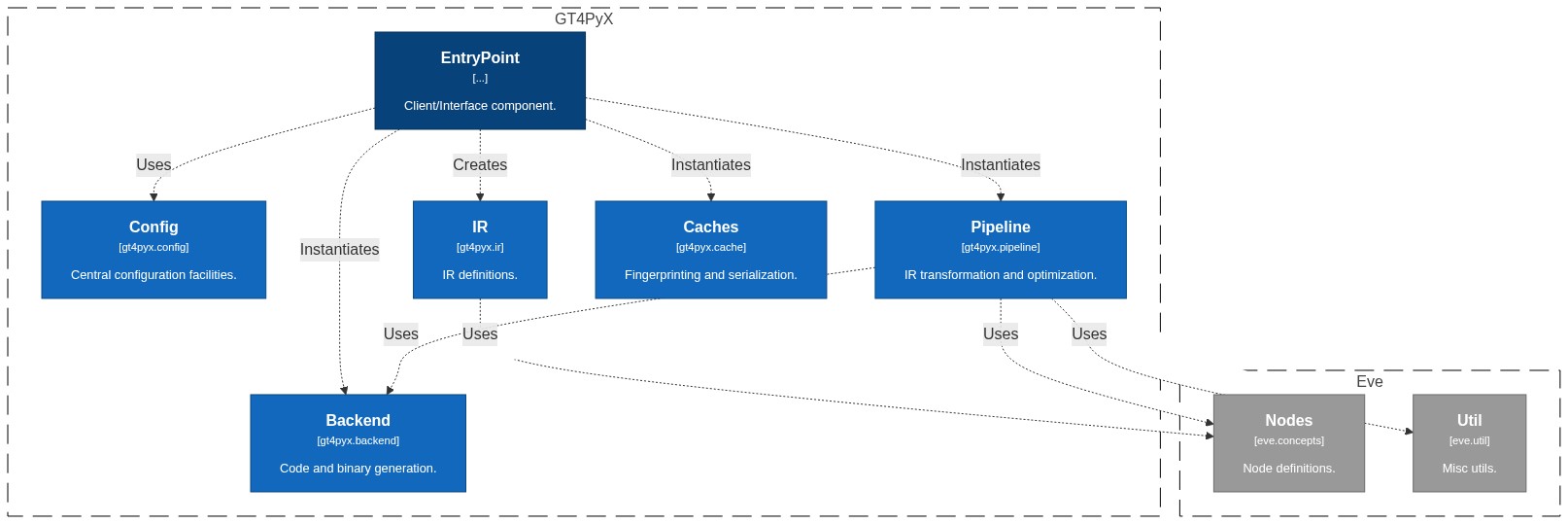](https://mermaid.live/edit/#pako:eNqtVstO4zAU_RUrI9RNG1pUoBOYLijMqIsZoQLSSA0LJ7lpLRI7sp0OAfHvc51HS1oeQamzae1zj32u78PPli8CsBxrIWmyJLcXLickYvzhRmcRkABCmkaahCyKnG9hPgzi4IAo0OtljhxE5RZakI7KlIbYj6hSHRIKSXzBV8AZcB-Mdb5yCeEW_WBwMvKCrtJSPIDzre8NR6Nh1xeRkNXeZ8TlNYZUgcz_lBz90fDo1NtwHB_B8ckWR43g1Vm_cIwaBTzqXZbv-ViznHjm22Gp8aCXNGW8LqiAbk6Tj4pnmI9ysRdQtaRS0swhR30y6Jf8KvWKy4UVkPnVCu7NLCnvy0y23qkgROo_GAhq7lrFBCHnAVsVG_3ohCiv9w_YYqkd4oko6Ixz-PkhgsbvWij2BA457R-ckZjKBeM9LRKH9JPHzniOp7fRbT4kWt03IhptEQ1yInMQE42MM80EV_ZrLte6dxynfstrxXeaRc0FG3RbvSlytNH6mymfGJJmKoEHW3G00MMkeyTzX7fD6-xvLZrKpT0FFB6qcDPXMrsWjOvmnt7YtPG3bdttXD2JsObpwynXIEPqA6Z4nAiOc2-4fl3KCncTMhE8ZIvmkgt8G7nF9ZmMQqJWwlGipBEpmFJJTVYRdAGLMMFgJ_IqydNZc7nT2R6kMtlG5nT2UdGoRF2zBLClQnNplcUeBCYlVUuZeJtcYSuPi5ukPCAi0SxmT_nEe9In1F9-pSEU-H2EsCFqo_kn4wuQicQCgr9ywZifjEafKL6g_gOWzOaSS4M9aPYKplZ5a_qg0eoxTmVGFoDPkQ_1buos6dm4cKdAuRaxe-Oyfr0Nm3KlKbqW6jW8CvrGBkWwNIaXjn4bP5HwCjqdbQrSjqzqmbOd3jvA2obvojZ0n8HM48HlZT8uPqtrxYBJyQJ8wj8bCtfSS4jBtRz8Wb6vTSy-IDRNAhR5FTAtpOWENFLQtWiqxU3GfcvRMoUKdMkoNvu4RL38B0QU9bw)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet