# Image Processing Note
## Overview
https://medium.com/@vad710/computer-vision-for-busy-developers-6a7320222da
## Feature Descriptors
- https://medium.com/@vad710/cv-for-busy-developers-describing-features-49530f372fbb
- Feature Descriptors are like Feature Points on steriods.
- They consider the data immediately around a Feature Point in otder to improve the robustness of matching descriptors across different images.
### So What's Feature Points?
- A Feature point is a small area in an image(sometimes as small as a pixel) which has some measurable property of the image or object.
### Simple Descriptor
- A simple descriptor of a Feature Descriptor would be to look at the pixels within a box surrounding the Feature.
- Much like when we are working with templates, this simplistic descriptor approach has some issues.
- Mainly, if the descriptors change in scale or orientation, our chances of successful matches are going to be low.
## Feature Extraction
- https://medium.com/hackernoon/image-feature-extraction-local-binary-patterns-with-cython-b31171ad5dc9
- The common goal of feature extraction is to represent the raw data as a reduced set of features that better describe their main feature and attributes.
### Hough Transform
https://en.wikipedia.org/wiki/Hough_transform
https://medium.com/@bob800530/hough-transform-cf6cb8337eac
- The purpose of the technique is to find imperfect instances of objects within a certain class of shapes by a voting procedure.
- This voting procedure is carried out in a parameter space, from which object candidates are obtained as local maxima in a so-called accumulator space that is explicitly constructed by the algorithm for computing the Hough transform.
### LBP
- https://medium.com/hackernoon/image-feature-extraction-local-binary-patterns-with-cython-b31171ad5dc9
### SIFT
- https://medium.com/@vad710/cv-for-busy-developers-describing-features-49530f372fbb
- Scale-invariant feature transform
- based on the Difference of Gaussian detector.
- It's also orientation-invariant.
- SIFT starts from with feature points detected through Difference of Gaussian.
- In order to make it orientation-inveriant, SIFT then considers a large patch of pixels surrounding the feature points and orients the feature based on the dominant orientation of the surrounding pixel **gradients**.
- The data around the the feature point is then summarized in various **histograms of gradients** and included as part of the feature descriptor.
- Lastly, the magnitude of the histograms are normalized to make the descriptor invariant to linear changes in brightness or contrast.
## Application
### Corner detection
- https://medium.com/analytics-vidhya/corner-detection-using-opencv-13998a679f76
- Harris
- goodFeaturesToTrack
### Automating Background Color Removal with Python and OpenCV
- https://medium.com/better-programming/automating-white-or-any-other-color-background-removal-with-python-and-opencv-4be4addb6c99
### Understand The Computer Vision Landscape before the end of 2019
- https://towardsdatascience.com/understand-the-computer-vision-landscape-before-the-end-of-2019-fa866c03db53
- This post tells the history of computer vision especially feature extraction.
### Object Detection : Simplified
- https://towardsdatascience.com/object-detection-simplified-e07aa3830954
#### What is Object Detection?
- A common vision problem dealing with identifying and locating object of certain classes in the image.
- Interpreting the object localisation can be done in various ways, including creating a bounding box around the object or marking every pixel in the image which contains the object (called segmentation).
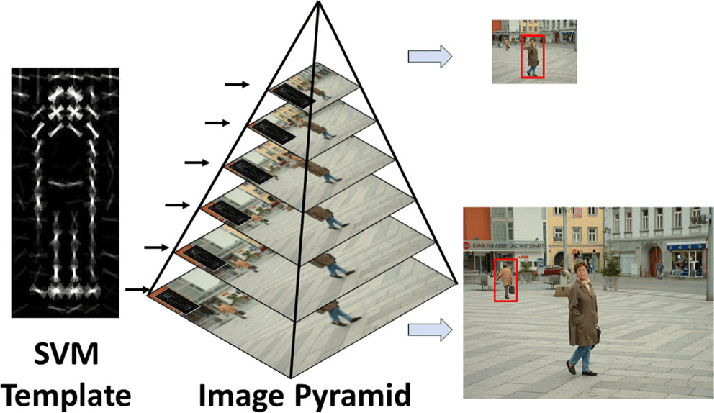
#### Back in the old days
- Object detection before Deep Learning was a several step process, starting with edge detection and feature extraction using techniques like SIFT, HOG, etc.
- These images were then compared with existing object templates, usually at multi scale levels, to detect and localize objects present in the image.
#### Understanding the Metrics
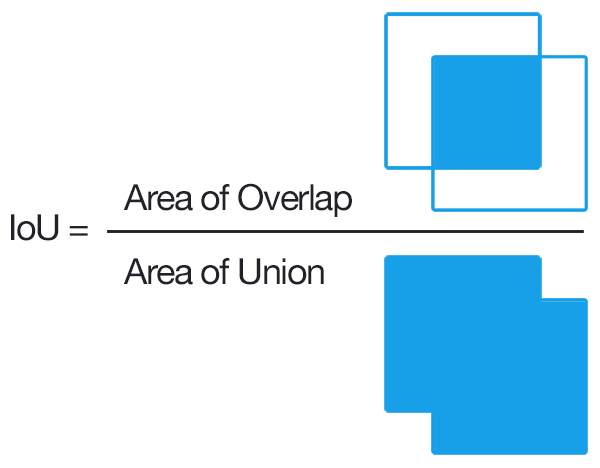
- **IoU (Intersection over Union)**
- Bounding box prediction cannot be expected to be precise on the pixel level, and thus a metric needs to be defined for the extend of overlap between 2 bounding boxes.
- IoU *does exactly what it says*.
- It takes the area of intersection of the 2 bounding boxes involved and divide it with the area of their union.
- This provides a score, between 0 and 1, representing the quality of overlap between the 2 boxes.
- **Average Precision and Average Recall**
- Precision meditates how accurate are our predictions.
- Recall accounts for whether we are able to detect all objects present in the image or not.
- Average Precision (AP) and Average Recall (AR) are two common metrics used for object detection.
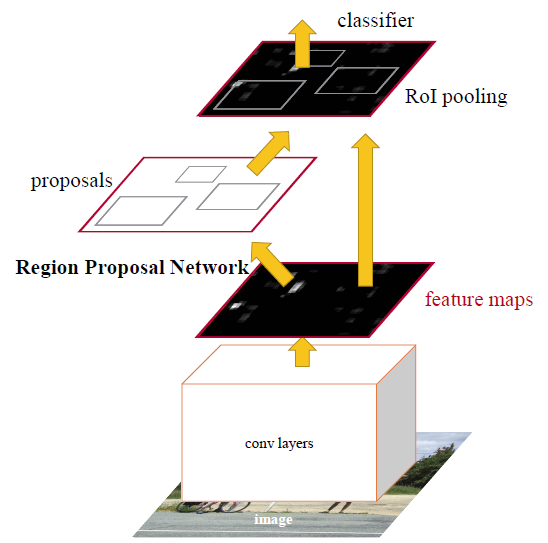
#### Two-Step Object Detection
- Two-Step Object Detection involves algorithms that first identify bounding boxes which may potentially contain objects and then classify each bounding box seperately.
- The first step requires a *Region Proposal Network*, providing a number of regions which are then passed to common DL based classification architectures.
- A lot of different methods and variations have been provided to these region proposal networks (RPNs) *such as*:
- hierarchical grouping algorithm in RCNNs (which are extremely slow)
- ROI pooling in Fast RCNN
- anchors in Faster RCNN (thus speeding up the pipeline and training end-to-end)
- These algorithms are known to perform better than their one-step object detection counterparts, but are slower in comparison.
- With various improvements suggested over the years, the current bottleneck in the latency of Two-Step Object Detection networks is the RPN step.
#### One-Step Object Detection
- With the need of real time object detection, many one-step object detection architectures have been proposed, like YOLO, YOLOv2, YOLOv3, SSD, RetinaNet, etc.
- They try to combine the detection and classification step.
- One of the major accomplishments of these algorithms have been introducing the idea of 'regression' the bounding box predictions.
- When every bounding box is represented easily with a few values (for example, xmin, xmax, ymin, and ymax), it becomes easier to combine the detection and classification step and dramatically speed up the pipeline.
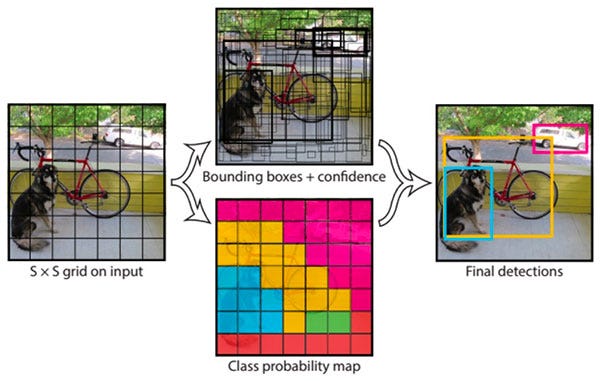
For example, YOLO divided the entire image into smaller grid boxes, For each grid cell, it predicts the class probabilities and the x and y coordinates of every bounding box which passes through that grid cell. *kinda like the image based captcha where you select all smaller grids which contain the object!!!*
- These modifications allow one-step detectors to run faster and also work on a global level.
- However, since they do not work on every bounding box separately, this can cause them to perform worse in case of smaller objects or similar object in close vicinity.
- There have been multiple new architectures introduced to give more importance to lower level features too, thus trying to provide a balance.
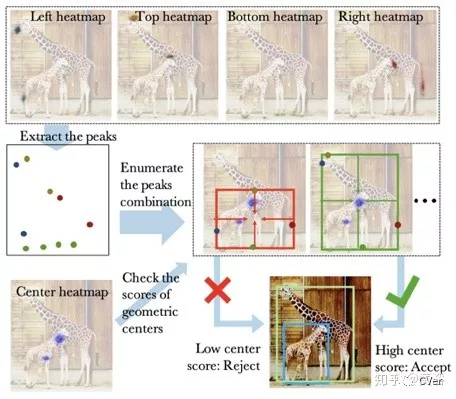
#### Heatmap-based Object Detection
- Heatmap-based Object Detection can be, in some sense, considered an extention of one-shot based Object Detection.
- While one-shot based object detection algorithms try to directly regress the bounding box coordinates (or offsets), heatmap-based object detection provides probability distribution of bounding box corners/center.
- Based on the positioning of these corner/center peaks in the heatmaps, resulting bounding boxes are predicted.
- Since a different heatmap can be created for every class, this method also combines detection and classification.
- While heatmap-based object detection is currently leading new research, it is still not as fast as conventional one-shot object detection algorithms.
- This is due to the fact that these algorithms require more complex backbone architectures (CNNs) to get respectable accuracy.
#### What's Next?
- While object detection is a growing field which has seen various improvements over the years, the problem is clearly not yet completely solved.
- With so much variety available in terms of different approaches to object detection, all of them with their own pros and cons.
- One can always choose the method that suits their requirements best and thus no one algorithm currently rules the field.
### Facial Recognition
https://medium.com/@SeoJaeDuk/facial-recognition-technologies-in-the-wild-a-call-for-a-federal-office-afa8d466578f
### Automated Driving
https://thomasfermi.github.io/Algorithms-for-Automated-Driving/Introduction/intro.html
### Satellite images
#### Why can't I directly use satellite images?
https://medium.com/nerd-for-tech/atmospheric-correction-of-satellite-images-using-python-42128504afc3
- The reason is the atmospher influence.
- Two sources of influences:
- directly reflected sunlight
- diffused skylight
## Tools
### Image Kernel Visualization
https://setosa.io/ev/image-kernels/
### OpenImageDebugger
https://github.com/OpenImageDebugger/OpenImageDebugger
### Computer Vision Tools And Libraries
https://medium.com/the-research-nest/computer-vision-tools-and-libraries-52bb34023bdf
## References
### 艾蒂學院blog
http://blog.ittraining.com.tw/search/label/%E5%BD%B1%E5%83%8F%E8%99%95%E7%90%86
### Maxkit blog
https://blog.maxkit.com.tw/
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet