---
tags: AML
title: HMM
---
## Hidden Markov Models for POS Tagging
Let us define the HMM model for assigning POS tags. Let's assume that we observe the words in a sentence. The emission of words is governed by a hidden Markov process that explains the transition between PSO tags. This HMM model can be described with the following graph
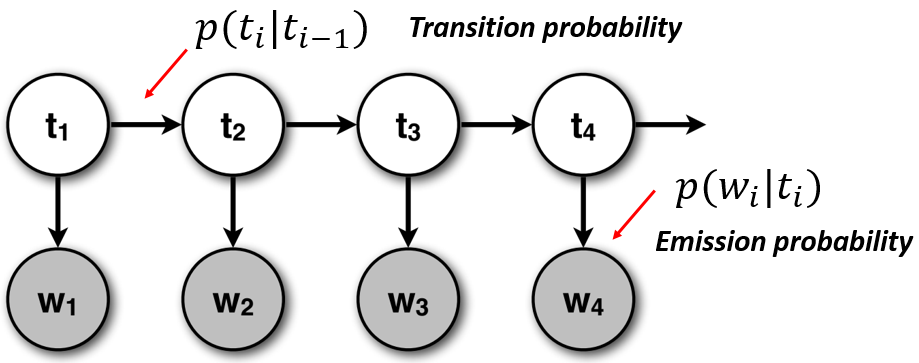
where $t_i$ is a tag at position $i$ and $w_i$ is a word at position $i$.
The joint probability of words and tags can be factorized in the following way
$$
\begin{aligned}
p(w_1,...,w_N,t_1,...,t_N) &= \prod_{i=1}^N p(w_i|t_i)p(t_i|t_{i-1}) \\
&= \prod_{i=1}^N \frac{p(t_i|w_i)p(w_i)}{p(t_i)} p(t_i|t_{i-1}) \\
&= \prod_{k=1}^N p(w_k) \prod_{i=1}^N \frac{p(t_i|w_i)}{p(t_i)} p(t_i|t_{i-1})
\end{aligned}
$$
assume $p(t_1|t_0) = p(t_1)$ for the simplicity of notation. We took the probability of each word in the sequence out of the product because, as we will see later, we can ignore them during the optimization.
:::warning
Do not work with probabilities directly
:::
Making your calculations with probabilities directly is bad for two reasons:
1. When multiplying a lot of probabilities, you will face the problem of floating point underflow
2. Multiplication operation is slow. You will have much higher performance if you calculate log of probability and then add log probabilities together
$$
\log p(w_1,..,w_N,t_1,..,t_N) = \sum_{k=1}^N \log p(w_k) + \sum_{i=1}^N \left[ \log p(t_i|w_i) - \log p(t_i) + \log p(t_i|t_{i-1}) \right]
$$
## [Viterbi Algorithm](https://web.stanford.edu/~jurafsky/slp3/8.pdf)
In the problem of POS tagging, we want to maximize the joint probability of assigning the tags to the input words. Thus, the problem can be solved with a maximization objective
$$
\hat{t_1},..,\hat{t_N} = \underset{t_1,..,t_N}{argmax} \left( \sum_{i=1}^N \log p(t_i|w_i) - \log p(t_i) + \log p(t_i|t_{i-1}) \right)
$$
The additive term $\sum_{k=1}^N \log p(w_k)$ does not influence the result of summation, and therefore can be omitted.
Now, we want to solve this problem optimally, meaning given the same input, and the same probability distributions, you find the best possible answer. This can be done using the Viterbi algorithm.
Assume that you have an HMM where the hidden states are $s={s_1, s_2, s_3}$, and the possible values of the observed variable $c={c_1,c_2,c_3,c_4,c_5,c_6,c_7}$. Given the observed sequence $\mathbf{y}=[c_1,c_3,c_4,c_6]$, the Viterbi algorithm will tries to estimate the most likely transitions $\mathbf{z}=[z_1,z_2,z_3,z_4], z_i\in c$, and store the path of the best possible sequence at every step.
Define
$$
\delta_t(j) = \underset{z_1,..,z_{t-1}}{max}{p(\mathbf{z}_{1:t-1}, z_t=j | y_{1:t})}
$$
This is the probability of ending up in state $j$ at time $t$, given that we take the most probable path. The key insight is that the most probable path to state $j$ at time $t$ must consist of the most probable path to some other state $i$ at time $t − 1$, followed by a transition from $i$ to $j$. Hence
$$
\delta_t(j) = \underset{i}{max}\ \delta_t(i) p(s_j|s_i) p(y_t|s_j)
$$
We also keep track of the most likely previous state, for each possible state that we end up in:
$$
a_t(j) = \underset{i}{argmax}\ \delta_t(i) p(s_j|s_i) p(y_t|s_j)
$$
That is, $a_t(j)$ tells us the most likely previous state on the most probable path to $z_t = s_j$. We initialize by setting
$$
\delta_1(j) = \pi_j p(y_1|z_j)
$$
where $\pi_j$ is a prior probability of a state. If we do not have this available, we can use the best unbiased guess - uniform distribution. The Viterbi algorithm will create two tables, that will store the following values
Probabilities:
|State | t=1, $y_1=c_1$ | t=2 $y_2=c_3$ | t=3 $y_3=c_4$ | t=4 $y_4=c_6$ |
|----- | ----| ----- | ------ | ------ |
|$s_1$ | 0.5 | 0.045 | 0.0 | 0.0 |
|$s_2$ | 0.0 | 0.07 | 0.0441 | 0.0 |
|$s_3$ | 0.0 | 0.0 | 0.0007 | 0.0022 |
Best previous state:
|State | t=1, $y_1=c_1$ | t=2 $y_2=c_3$ | t=3 $y_3=c_4$ | t=4 $y_4=c_6$ |
|----- | --- | --- | --- | --- |
|$s_1$ | - | 1 | 1 | 1 |
|$s_2$ | - | 1 | 2 | 2 |
|$s_3$ | - | - | 2 | 2 |
The solution can be visualized as follows

*Source: Machine Learning Probabilistic Perspective, Chapter 17.4.4*
For more thorough overview of Viterbi algorithm, refer [here](https://web.stanford.edu/~jurafsky/slp3/8.pdf)
## Estimating Word Tags
The Viterbi algorithm requires you to estimate probabilities of tags for words $p(t|w)$. We suggest using a time-tested convolutional architecture for sequence classification, inspired by the paper *[A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning](http://ronan.collobert.com/pub/matos/2008_nlp_icml.pdf) (Check References for more reading)*.
### Method
The main problem with tag classification for words is that the length of words varies, and it is unclear which features are useful for POS classification. It the best practice of Deep Learning, we create a model that learns useful features on its own.
The idea of the classification model is the following.
1. Represent a word as a sequence of characters
2. Use a projection layer to embed each character in a sequence. Each character will be represented with a real vector $v_c \in \mathcal{R}^d$, where $d$ is the embedding vector length.
3. Apply convolutional layer with a non-linearity to extract higher level features from letters. The convolutional window has a size ($d$, $d_{win}$), where $d$ is the embedding length, and $d_{win}$ is the width of the convolutional window. Typically set to 3 or 5. Pass over the letter embeddings without with stride of 1. The number of filters should be equal to $h_{hidden}$.
4. After applying the convolutional layer, you will have a series of embeddings of size $h_{hidden}$. At this step, we want to flatten the input to make it independent of the sequence length. Do this by performing maxpool operation over the sequence length. As a result, you will get a word embedding of fixed size. During training, You are going to enforce morphological features captured in this embedding.
5. Apply a regular NN layer to the word embedding and use softmax to estimate a probability distribution over tags.

*Source: [Named Entity Recognition with Bidirectional LSTM-CNNs](https://arxiv.org/pdf/1511.08308.pdf)*
### Recurrent Neural Network Implementation
Unfortunately, it is not efficient to model sequences of variable length. For this reason, we are going to fix the length of a word to a maximal sequence length the same way as when using RNN.
Convolutional layer can be created with `torch.nn.Conv2d(...)`. You will need to specify the input, kernel shape, and the number of filters. The number of filters should be equal to $h_{hidden}$. The output shape of the convolutional layer should be `(None, max_word_len, 1, h_hidden)`.
Now you need to apply maxpool operation. The output of maxpool should be of shape `(None, h_hidden)`. use reshape before maxpool if necessary.
The final NN layer should have the number of output units equal to the number of POS tags.
With this method, after training for two epochs, we have obtained the following per-word-accuracy score
```
loss 0.2043, acc 0.9323
```
and the following confusion matrix

Read more about confusion matrix [here](https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html).
## Dataset Description
You are going to use a modified conll2000 dataset to train your HMM tagger. The dataset has the following format
```
word1_s1 pos_tag1_s1
word2_s1 pos_tag2_s1
word1_s2 pos_tag1_s2
word2_s2 pos_tag2_s2
word3_s2 pos_tag3_s2
word1_s3 pos_tag1_s3
...
wordK_s3 pos_tagK_s3
...
...
...
wordM_sN pos_tagM_sN
```
Where `s*` corresponds to different sentences. Every line contains an entry for a single word. Sentences are separated from each other by an empty line.
## Task
1. Calculate the transition probability and emission matrices (First step towards viterbi)
2. Implement Recurrent Neural Network for POS tagging task.
3. Implement Viterbi algorithm for POS tagging task.
## References
- [A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning](http://ronan.collobert.com/pub/matos/2008_nlp_icml.pdf)
- [Convolutional Neural Networks for Sentence Classification](https://www.aclweb.org/anthology/D14-1181)
- [Improving Word Embeddings with Convolutional Feature Learning and Subword Information](https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/download/14724/14187)
- [A Primer on Neural Network Models for Natural Language Processing](https://arxiv.org/abs/1510.00726)
- [HMM for POS tagging](https://web.stanford.edu/~jurafsky/slp3/8.pdf)
*[POS]: part of speech
*[HMM]: Hidden Markov Model
*[MLE]: maximum likelihood
*[UD]: Universal Dependencies
*[TSV]: Tab Separated Value
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet