---
tags: forge
title: Forge.AI ANvIL v06.30
---
# Forge.AI ANvIL v06.30
#### Table of Content
[TOC]
# Forge.AI Overview
Forge.AI is a cloud-based data and knowledge platform that powers the analytical, model driven organization. We create real time structured knowledge and data feeds out of the chaotic ocean of unstructured data that flows across the globe and throughout your organization. Our customers can explore, discover, monitor and model the knowledge and information captured in that unstructured data in fundamentally new and powerful ways enabling the rapid delivery of high-impact, data driven models that create a competitive advantage.
Forge.AI amplifies the ++quantity++ of data science your organization can conduct. We eliminate the time, expense and technology challenges associated with trying to create and sustain a data pipeline that incorporates the at scale transformation of unstructured data into algorithmically relevant structured data. We fundamentally accelerate the speed at which your data scientist can, explore hypothesis, iterate on and deploy models that deliver business value.
Forge.AI creates a new paradigm in terms of the ++quality++ and sophistication of data science your organization can conduct. Historically, data science conducted with unstructured data has been “shallow,” meaning model inputs tend to be simple (e.g. word counts) and model outputs paint with a broad brush (e.g. traditional sentiment analysis). Forge.AI brings unparalleled fidelity to the identification, extraction, resolution and semantic framing of the interaction between the entities, events and relationships expressed in unstructured data. This fidelity enables a new level of sophistication and time series modeling and analysis within your organization. See more. See faster. Predict better.
## Forge.AI Platform Abstract
Forge.AI’s cloud-based ANvIL platform collects publicly available information in real time and transforms it into an ever-growing always accessible library of structured, intelligent data that lends itself to times series analysis and other forms of advanced analytics.
ANvIL supports the analytical enterprise and is resource that: (i) generates enhanced data that is suitable for a wide assortment of machine learning and artificial intelligence applications and enhancing data science environments; (ii) improves automated decision making and reasoning processes and (iii) enhances internal knowledge bases. The data resources created by Forge.AI are made available to our customers in either a streaming format or addressable through a SQL enabled cloud data warehouse (Snowflake).
Our customers simply “plug into” the ANvIL’s data environment and immediately, transformed and enriched data begins to flow is available to your data scientists, analysts and algorithmic infrastructure..
To give a sense as to what is happening “under the hood,” a brief abstract of the Forge.AI ANvIL platform is detailed below:
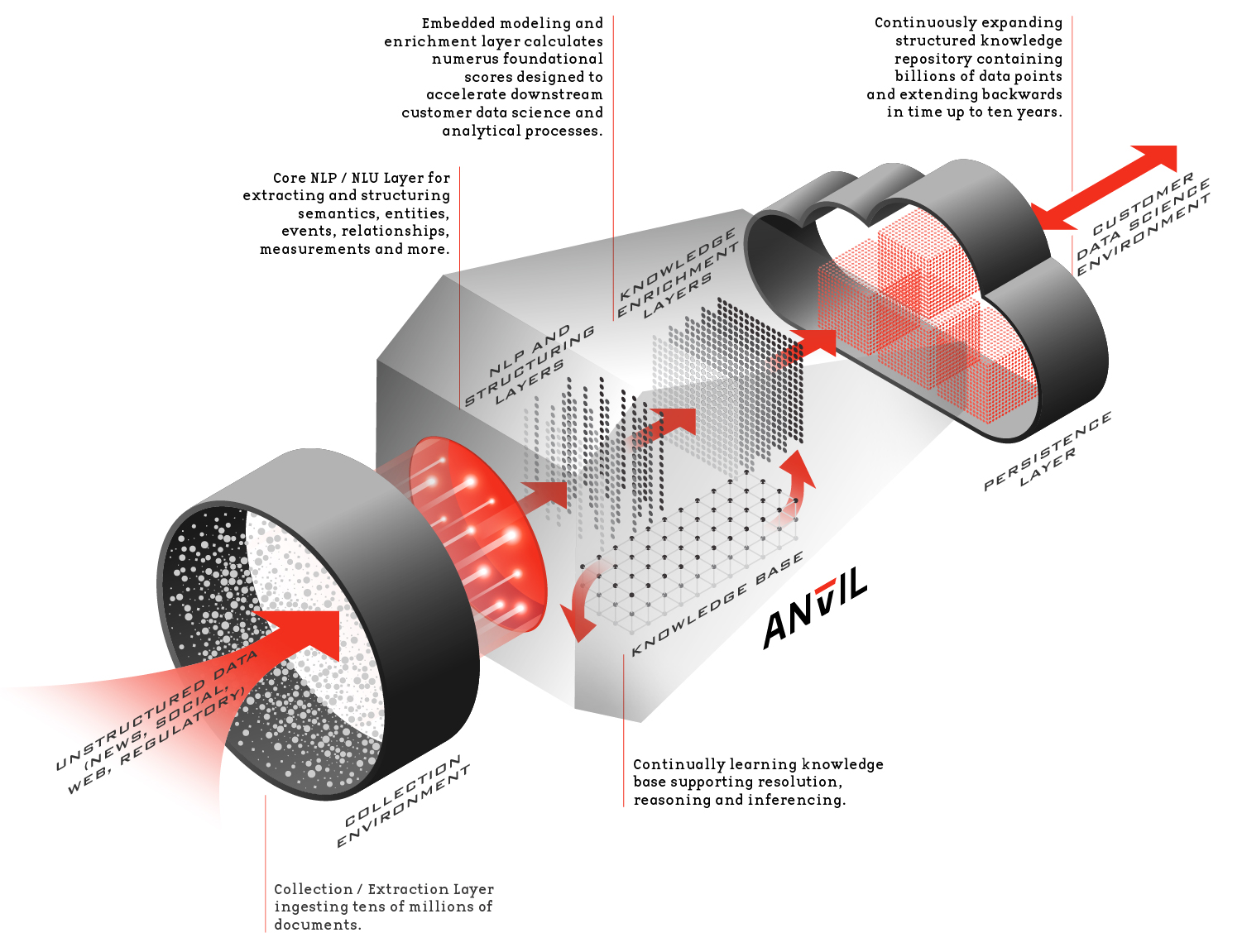
++**Collection**++: ANvIL’s collection and extraction environment operates in real time 7x24x365. Processing millions of documents monthly, ANvIL’s source information is collected from tens of thousands of national / international, local, and industry specific news sites, organizations web sites, different US and international sites (e.g. the SEC) and social media (in addition to private feeds and / or feeds that you provide directly to us). Specially designed algorithms continually learn and optimize the process by which we collect source information. We abide by all politeness clause and other requirements in our collection process. If there is a source of data or information, we are not collecting that is relevant to you we will work with you and that data source to incorporate it into our ecosystem.
++**NLP and Structuring Layer**++: Our proprietary natural language processing and natural language understanding environment extracts and structures relevant entities, events, relationships, measurements and relevant semantics. In addition, it extracts a host of meta information and generates AI informed “calculated data” derived from source documents directly and/or in conjunction with our knowledge base.
++**Knowledge Enrichment Layer**++: The Knowledge and Enrichment Layer calculates numerous foundational scores designed to accelerate downstream customer data science and analytical processes. Ranging from entity level sentiment through various momentum and saliency scores through various topic vectors, these foundational elements are immediately usable for various enhanced analytical processes that support various modeling tasks associated with risk engineering, trading, thematic exposure and the like.
++**Knowledge Base Layer**++: ANvIL’s semantic, temporal and probabilistic knowledge base works in concert with the other components of ANvIL to resolve all relevant data. Furthermore, in addition to supporting reasoning and inferencing tasks, ANvIL’s Knowledge Base is continually growing and learning as Forge is processing millions of documents monthly creating a source of real time compounding intelligence.
The knowledge base is also where Forge.AI maintains the various ontologies we support. An overview of the primary ontologies is listed below. It is worth noting that Forge.AI adds to the ontologies we support both organically and at the request of customers:
- Domain Specific Ontologies
- Corporate Structure
- People and Corporate Relationships
- Business Concepts
- Financial Concepts
- Marketing Concepts
- Risk (Operational Risk, Credit Risk, Market Risk)
- Science (Physics, Chemistry, Biology, etc.)
- Military and National Security
- Events
- Custom Ontologies / Ontologies as Requested
++**Persistence Layer**++: All knowledge and data processed by ANvIL persists in ANvIL’s expanding knowledge repository. This repository is predicated and built out of the tens of millions of documents ANvIL processes, is continually growing in real time and its footprint extends backwards in time up to ten years predicated on source.
++**Access to ANvIL and Data Output and Syndication**++: Data is syndicated to our customer environment in one of two ways.
- Option One: Customers connect with ANvIL’s real time cloud-based data warehouse. This data document which follows, describes how the data is managed in ANvIL’s cloud data warehouse. It is intended to orient the customer to nature of the data managed in the data warehouse, its structure, and how to query the data and integrate it into your operations.
- Option Two: Customers connect with our real-time streaming data environment. This environment is conceptually similar in structure our cloud-based data warehouse; however the representation is in XML or JSON and the delivery mechanism uses HTTPS 2.0 Push. Separate documentation is available which describes this environment.
The format of the data that is syndicated to our customers is extensively described below. There are three “classes” of data extracted and generated by Forge.AI:
- Direct data that corresponds directly with a published document (e.g. news story, SEC filing, tweet, etc.);
- Calculated information that is derived from a published document, such as an automated LDA topic vectors representing the source information;
- Aggregate information derived by looking at a large collection of the corpus of processed data.
## Connecting with the Forge.AI Platform
Connecting with the Forge.AI environment is simple, and an abstract is provided below. You simply choose to connect to our cloud-based data warehouse, or you choose to connect to our push API.

# Schema
`ARTICLES`/`ARTICLES_V0630`
: The `ARTICLES` schema contains all general articles since Oct-2018.
This schema adheres to version 06.30.
`DJN`/`DJN_V0630`
: The `DJN` schema contains all the Dow Jones news feed since 2008 (when applicable.)
This schema adheres to version 06.30.
`SEC_8K`/`SEC_10K`/`SEC_10Q`
: The `SEC_*` schema contain all the SEC forms 8K/10K/10Q filings since 2009.
These schemas adhere to version [06.20](https://hackmd.io/@nbrachet/SyUkXRDJB).
### ERD
<iframe width="100%" height="600" src='https://dbdiagram.io/embed/5d36280fced98361d6dce6d7'> </iframe>
## Documents
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | The UUID for this document. |
| parentUuid | CHAR(48) | ✔ | If the document has a parent document, this field will represent the id of the parent document. |
| url | VARCHAR(2048) | ✖ | The resolved URL for the document.<br/>This may be the same as the original URL if there was no redirection. |
| originalUrl | VARCHAR(2048) | ✔ | The source URL before any redirection. |
| docType | STRING | ✔ | The docType is used to determine how the document is published.<br/>Current types = `article` `secfiling` |
| title | STRING | ✔ | The title of the document (potentially translated into English.) |
| originalTitle | STRING | ✔ | The original title of the document (if not English.) |
| docDateTime | TIMESTAMP_NTZ | ✔ | The later of the document publish date and last update (UTC). |
| collectDateTime | TIMESTAMP_NTZ | ✔ | The UTC time the document was collected and processed. |
| summary | STRING | ✔ | Summary of the document text. |
##### Notes:
1. `docDateTime` and `collectDateTime` are stored in UTC.
1. `docDateTime` is `NULL` if no document date could be identified for the document.
1. `docDatetime` is the _acceptance date_ for SEC filings.
1. If the document is too small, `summary` will be the first 2 sentences.
1. `summary` is not computed for SEC filings.
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
parentUuid:
: af802d69-1d95-44f2-9096-1b15c1d6ad4d
url:
: http://www.tampabay.com/nation-world/two-nuns-stole-500000-for-trips-to-las-vegas-but-the-church-doesnt-want-them-prosecuted-20181210/
orginalUrl:
: NULL
docType:
: article
title:
: Two nuns stole $500,000 for trips to Las Vegas. But the church doesn't want them prosecuted.
originalTitle:
: NULL
docDatetime:
: 2018-12-10 13:50:20.000
collectDatetime:
: 2019-06-08 00:37:46.000
summary:
: Around the same time when Kreuper announced she was retiring earlier this year, a family at the school asked for a copy of an old check they had written to St. James. That was among the first clues that would unravel a vast fraud that was allegedly cond...
:::
### DocumentSource
The channel the document was collected through.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| sourceId | INTEGER | ✖ | The id for the source channel. This is an internal value. |
| parentId | INTEGER | ✖ | Logical grouping id. |
| name | STRING | ✖ | The name of the channel the document was collected from. Example include "The Wall Street Journal", and "Bloomberg". |
| type | STRING | ✔ | "RSS feed", "crawl", etc. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sourceId:
: 595
parentId:
: 2
name:
: St. Petersburg Times
type:
: SITE
:::
### DocumentMetadata
Relevant HTTP header information acquired during document collection.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| name | STRING | ✖ | |
| value | STRING | ✔ | |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
name:
: DESCRIPTION
value:
: The two women, reportedly best friends, are accused of pilfering funds on trips and casino visits.
:::
##### Additional metadata items for DJN
`forgeai:djAccessionNumber`:
: Dow Jones article _access number_
`forgeai:djSequenceNumber`:
: Dow Jones article _sequence number_
`forgeai:djBrandedHeadline`:
: Combination of the Dow Jones Brand Display along with the headline text
##### Additional metadata items for SEC 8-K/10-K/10-Q
`forgeai:company`:
: name of the filing company, e.g. `Guidewire Software, Inc.`
`forgeai:company-cik`:
: central index key for the filing company, e.g. `0001528396`
`forgeai:sec-accession-no`:
: accession number of the filing, e.g. `0001528396-19-000009`
`forgeai:sec-filing-type`:
: form type, e.g. `10-Q`
###### Trick
It can be useful to pivot the `DocumentMetadata` table:
```sql
WITH Meta AS (
SELECT docId,
MAX(CASE WHEN name = 'forgeai:company' THEN value END) AS company,
MAX(CASE WHEN name = 'forgeai:company-cik' THEN value::INT END) AS cik,
MAX(CASE WHEN name = 'forgeai:sec-accession-no' THEN value END) AS accession,
MAX(CASE WHEN name = 'forgeai:sec-filing-type' THEN value END) AS filing,
MAX(CASE WHEN name = 'forgeai:sec-filing-type' THEN REGEXP_REPLACE(value, '^([0-9]+-.).*$', '\\1') END) AS filing_short
FROM SEC.DocumentMetadata
GROUP BY 1
)
SELECT *
FROM SEC.Documents d
JOIN Meta m ON (m.docId = d.docId)
```
For performance reason however, only the relevant items should be pivoted, eg.
```sql
WITH Meta AS (
SELECT docId,
MAX(CASE WHEN name = 'forgeai:sec-filing-type' THEN REGEXP_REPLACE(value, '^([0-9]+-.).*$', '\\1') END) AS filing
FROM SEC.DocumentMetadata
GROUP BY 1
)
SELECT *
FROM SEC.Documents d
JOIN Meta m ON (m.docId = d.docId)
WHERE filing = '8-K'
```
### SimilarDocuments
A collection of references to documents that are closely identical to this document.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| similarDocId | CHAR(48) | ✖ | The UUID of the similar document. |
| score | FLOAT | ✔ | A score from 0.0-1.0 reflecting the similarity of the documents.<br/>A score of 1.0 indicates the documents are identical. |
##### Notes:
1. `similarDocId` may not be present in the `Documents` table.
##### Example:
:::info
docId:
: d445372b-f880-496f-86c1-cc496a39874c
similarDocId:
: 395ad38f-3239-4623-9c34-a6514f5a07c4
score:
: 0.949999988
:::
### DocumentScores
A set of scores for a document computed by different models.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| scoreType | STRING | ✖ | Category of the score. |
| modelName | STRING | ✖ | Instance of the type of score. |
| modelVersion | STRING | ✖ | Unique model version for the score. |
| score | STRING | ✖ | Value of the score. |
| confidence | FLOAT | ✔ | Confidence of the score. May not be computed for all scores. |
| index | INT | ✔ | For multi-dimensional scores, the dimension of the score value. |
#### Available Score Types
| score | ARTICLES | SEC |
|-------|:--------:|:---:|
| lexica | ✔ | ✖ |
| VADER | ✔ | ✖ |
lexica (`modelName = lexica-v0`)
: Measure, in logarithmic scale, of lexical-based stylistic divergence from a baseline.
`modelVersion`: current version `FunctionWordProbability.model-identifier-8b69522bbe583e38058a185e5fed6161a4472599-26402f3b687d41ba68b9596120a9292f23a7cc38`
`score`: float from `0` (identical to baseline) to `-Inf`
`confidence`: not computed
`index`: not applicable
VADER (`modelName = vader-v0`):
: Valence-based and word sense-aware sentiment analysis (http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf)
`modelVersion`: current version `VaderValance.train-2520d1b931dab7458a063a61c14c8ea411582936-2fdb6f68f4f976fe42d6febf9e37ed2ba8c6983c`
`confidence`: not applicable
`index 0` - combined score, float from `-1.0` (negative) to `+1.0` (positive)
`index 1` - positivity component, float from `0` to `+1.0`
`index 2` - negativity component, float from `0` to `+1.0`
`index 3` - neutrality component, float from `0` to `+1.0`
See also [DocumentSentiment](#DocumentSentiment).
### DocumentSentiments
Valence-based and word sense-aware sentiment analysis ([VADER](http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf))
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| modelName | STRING | ✖ | `vader-v0` |
| modelVersion | STRING | ✖ | `VaderValance.train-2520d1b931dab7458a063a61c14c8ea411582936-2fdb6f68f4f976fe42d6febf9e37ed2ba8c6983c` |
| combined | FLOAT | ✖ | combined document score, from `-1.0` (negative) to `+1.0` (positive) |
| positivity | FLOAT | ✖ | positivity component, from `0` to `+1.0` |
| negativity | FLOAT | ✖ | negativity component, from `0` to `+1.0` |
| neutrality | FLOAT | ✖ | neutrality component, float from `0` to `+1.0` |
## Sections
The collection of sections constituting the document.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| ++sectionId++ | INTEGER | ✖ | The document scope ID of the section. |
| parentId | INTEGER | ✔ | The parent section ID. Where appropriate this value is used to support representing an extracted document as a hierarchical collection of sections. |
| type | VARCHAR(1) | ✔ | An identifier for the type of information represented in the section.<br/>The possible types are: Text (`T`) |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sectionId:
: 1
parentId:
: 0
type:
: T
:::
### SectionMetadata
Any metadata associated with a section represented as name-value pairs.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Sections(docId, sectionId)` |
| sectionId | INTEGER | ✖ | Foreign key to `Sections(docId, sectionId)` |
| name | STRING | ✖ | |
| value | STRING | ✔ | |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sectionId:
: 1
name:
: date
value:
: Published December 10 2018
:::
##### Available metadata items for SEC 8-K/10-K/10-Q
`forgeai:sec-section-type`:
: section type of the filing: `1`, `1-A`, etc...
`forgeai:sec-section-title`:
: section type title, e.g. `Item 1. Financial Statements`
### SourceTexts
If the section is a text (`T`) section then this table will contain the source text.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Sections(docId, sectionId)` |
| ++sectionId++ | INTEGER | ✖ | Foreign key to `Sections(docId, sectionId)` |
| title | STRING | ✔ | The optional title for the section (translated if necessary.) |
| text | STRING | ✔ | The text for the section (translated if necessary.) |
| originalTitle | STRING | ✔ | Original text for the title (if not English.) |
| originalText | STRING | ✔ | Original text for the section (if not English.) |
| summary | STRING | ✔ | Summary of the section text. |
##### Notes:
1. `title` and `text` may be `NULL` because of licensing constraints.
2. If the text is too small `summary` will be the first 2 sentences.
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sectionId:
: 1
title:
: Two nuns stole $500,000 for trips to Las Vegas.
text:
: But the church doesn't want them prosecuted. An old check allegedly exposed decades of lies...
originalTitle:
: NULL
originalText:
: NULL
summary:
: Around the same time when Kreuper announced she was retiring earlier this year, a family at the school asked for a copy of an old check they had written to St. James. According to what Monsignor Michael Meyers explained to parents last Monday at the meeting, the church launched an independent financial investigation after the oddity regarding the old check was discovered. She allegedly endorsed the checks with a stamp saying, "St. James Convent," not "St. James School." The two nuns then tapped the funds for their personal use, Meyers said.
:::
### Sentences
The set of extracted sentences from the text section.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Sections(docId, sectionId)` |
| sectionId | INTEGER | ✖ | Foreign key to `Sections(docId, sectionId)` |
| ++sentenceId++ | INTEGER | ✖ | The document scope unique ID for the sentence. |
| text | STRING | ✔ | The sentence text. |
| startOffset | INTEGER | ✔ | Start offset in bytes into the section text for the sentence. |
| endOffset | INTEGER | ✔ | End offset in bytes into the section text for this sentence. |
##### Notes:
1. `text` may be `NULL` because of licensing constraints.
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sectionId:
: 1
text:
: Two nuns stole $500,000 for trips to Las Vegas.
sentenceId:
: 0
startOffset:
: 0
endOffset:
: 47
:::
### SectionScores
A set of scores for a section computed by different models.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| sectionId | INTEGER | ✖ | Foreign key to `Sections(docId, sectionId)` |
| scoreType | STRING | ✖ | Category of the score. |
| modelName | STRING | ✖ | Instance of the type of score. |
| modelVersion | STRING | ✖ | Unique model version for the score. |
| score | STRING | ✖ | Value of the score for the document. |
| confidence | FLOAT | ✔ | Confidence of the score. May not be computed for all scores. |
| index | INT | ✔ | For multi-dimensional scores, the dimension of the score value. |
#### Available Score Types
None at this time.
## Entities
The collection of entities discovered in the source document. An entity is named object or domain concept.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| ++entityId++ | INTEGER | ✖ | The document scope unique id for the entity. |
| type | VARCHAR(1) | ✖ | An attribute used to identify the entity type as a simple (`S`) or complex (`C`) entity.<br/>A complex entity is composed of a set of other entities (e.g. `CEO Sally Smith` is composed of a title and a person element) while a simple entity consists of just one entity type. |
| label | STRING | ✖ | The extracted text associated with the entity. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
entityId:
: 5
type:
: S
label:
: Las Vegas
:::
### EntityAliases
Alternate text from the document referring to the same entity (extracted text)
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INTEGER | ✖ | Foreign key to `Entities(docId, entityId)` |
| altLabel | String | ✖ | Alias |
##### Example:
:::info
docId:
: ba4c5be9-8658-4498-ab3d-2b17c5fbe6e0
entityId:
: 151 ("U.S. Supreme Court")
altLabel:
: Supreme Court
:::
### EntityComponents
The components are the constituent entities that collectively constitute the complex entity.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INTEGER | ✖ | Foreign key to `Entities(docId, entityId)` |
| componentId | INTEGER | ✖ | entity id into `Entities` of the component |
### EntityAssertions
The extracted entities are disambiguated/resolved using the ForgeAI semantic knowledge base.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INTEGER | ✖ | Foreign key to `Entities(docId, entityId)` |
| assertedClass | VARCHAR(2048) | ✖ | The URI for the asserted semantic type. |
| predicate | STRING | ✔ | The predicate for the assertion such as "isA", "ownerOf" etc. |
| confidence | FLOAT | ✔ | A value from 0.0-1.0 of the confidence in the assertion. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
entityId:
: 5
assertedClass:
: http://forge.ai/entity#Location
predicate:
: isA
confidence:
: 0.943267703
:::
### EntityProperties
Entity properties intrinsic to the entity. Examples include "latitude=42.0016", "CIK=320193", etc.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INTEGER | ✖ | Foreign key to `Entities(docId, entityId)` |
| name | STRING | ✖ | |
| value | STRING | ✔ | |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
entityId:
: 5
name:
: latitude
value:
: 36.17497
:::
### EntityLocation
The entity label's location into the document.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INTEGER | ✖ | Foreign key to `Entities(docId, entityId)` |
| sentenceId | INTEGER | ✖ | The ID of the document sentence that the entity is located in. |
| startOffset | INTEGER | ✖ | The offset in bytes into the sentence to the start of the entity label. |
| endOffset | INTEGER | ✖ | The offset in bytes into the sentence to the end of the entity label. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
entityId:
: 5
sentenceId:
: 0
startOffset:
: 37
endOffset:
: 46
:::
### EntityScores
A set of scores for an entity computed by different models.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INT | ✖ | Foreign key to `Entities(docId, entityId)` |
| scoreType | STRING | ✖ | Category of the score. |
| modelName | STRING | ✖ | Instance of the type of score. |
| modelVersion | STRING | ✖ | Unique model version for the score. |
| score | STRING | ✖ | Value of the score. |
| confidence | FLOAT | ✔ | Confidence of the score. May not be computed for all scores. |
| index | INT | ✔ | For multi-dimensional scores, the dimension of the score value. |
#### Available Score Types
| type | ARTICLES | SEC |
|-------|:--------:|:---:|
| entity-sentiment | ✔ | ✖ |
| entity-salience | ✔ | ✖ |
entity-salience (`modelName = entity-salience-v0`)
: A binary prediction of whether a document is about an entity.
`modelVersion`: current version `EntitySalience.model-identifier-499e567feadbc69d5b1cc8bf0375c6c4bbbcb5f4-48a201be48e3a132568c5e5f7627a3bc60d57ad8`
`score`: `0` (not salient) or `1` (salient)
`confidence`: float from `0.5` to `1.0` for the score.
`index`: not applicable.
It might be more intuitive to use saliency as a continuous variable in the range `[0, 1]` as follows:
```sql=
WITH EntitySaliencies AS (
SELECT docId, entityId, modelName, modelVersion,
IFF(score = 0, 1.0 - confidence, confidence) AS saliency
FROM EntityScores
WHERE scoreType = 'entity-salience'
)
...
```
entity-sentiment (`modelName = entity-sentiment-v0`)
: A numerical score which represents the polarity and intensity of a document's sentiment regarding an entity which takes into consideration verb dynamics.
`modelVersion`: current version
`EntitySentiment.train-29dfe6524d8148205d36ae4b08e33de4efd933b6-e087cef86c781c9aee955342219cbf11cf4f7be1`
`score`: `1` (high positive sentiment) to `-1` (low negative sentiment)
`confidence`: not computed.
`index`: not applicable.
### EntitySentiments
A convinience table for the `entity-sentiment` scores.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Entities(docId, entityId)` |
| entityId | INT | ✖ | Foreign key to `Entities(docId, entityId)` |
| modelName | STRING | ✖ | `entity-sentiment-v0` |
| modelVersion | STRING | ✖ | `EntitySentiment.train-29dfe6524d8148205d36ae4b08e33de4efd933b6-e087cef86c781c9aee955342219cbf11cf4f7be1` |
| sentiment | FLOAT | ✖ | entity score, from `-1.0` (negative) to `+1.0` (positive) |
Note: `entity-sentiment` is only calculated for the following NER types:
* `http://forge.ai/entity#Organization`
* `http://forge.ai/entity#People`
* `http://forge.ai/entity#GeopoliticalEntity`
## DocumentTopics
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| topicId | INT | ✔ | Unique topic id |
| name | STRING | ✖ | The topic name (e.g. "finance", "management", "physics", "sports", etc.) |
| parent | STRING | ✔ | If the topic represents a hierarchy, then the parent is the name of the direct ancestor topic. |
| score | FLOAT | ✔ | A measure from 0.0-1.0 indicating the topic strength. |
| startSentenceId | INT | ✔ | Sentence ID marking start of relevant topic information in section. |
| endSentenceId | INT | ✔ | Sentence ID marking end relevant topic information in section. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
topicId:
: 1
name:
: fraud
parent:
: NULL
score:
: 0.979394794
startSentenceId:
: NULL
endSentenceId:
: NULL
:::
### DocumentTopicWords
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId, topics)` |
| topicId | INT | ✔ | Foreign key to `DocumentTopics(docId, topics)` |
| word | STRING | ✖ | |
| value | FLOAT | ✔ | |
| count | INT | ✔ | |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
topicId:
: 1
word:
: investigation
value:
: 0.00999999978
count:
: NULL
:::
## DocumentTopicModelVectors
The topic models (LDA) generate fixed-length (100 elements) vectors of floating point numbers representing the topics encountered within the text.
The topic vector models introduced are appropriate for numerical calculations, such as distances or velocity, between the vectors from the same model. With distance computations we get clustering via the distance function. Furthermore, these vectors can serve as the low-level features atop a supervised learning algorithm (usually fused with user-supplied labels and any other co-variate information) for assessing document similarity, change detection, for instance.
Comparisons should not be made between topic vectors generated using different topic models. Applications may demand multiple topic models drawn from different corpora. The set of topic vectors allows for associating multiple topic vector calculations with a text section.
One property of the current topic vector models is that they do not represent absolute semantic concepts. A particular dimension having a value of 0.6 does not have a meaning outside of the values of that dimension compared across the other documents and alongside a user-labeling procedure to imbue the semantics over clusters of distance metrics.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| modelName | STRING | ✔ |
| modelVersion | STRING | ✔ |
| dimensionIndex | INTEGER | ✖ | Topic vector index (0...n-1) |
| dimensionValue | FLOAT | ✖ | The contribution (0.0-1.0) that this dimension has to the document. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
modelName:
: general
modelVersion:
: VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad
dimensionIndex:
: 3
dimensionValue:
: 0.410293996
:::
## TopicModelVectors
Section level topic model vectors (LDA).
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Sections(docId, sectionId)` |
| sectionId | INTEGER | ✖ | Foreign key to `Sections(docId, sectionId)` |
| modelName | STRING | ✔ |
| modelVersion | STRING | ✔ |
| dimensionIndex | INTEGER | ✖ | Topic vector index (0...n-1) |
| dimensionValue | FLOAT | ✖ | The contribution (0.0-1.0) that this dimension has to the section. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
sectionId:
: 1
modelName:
: general
modelVersion:
: VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad
dimensionIndex:
: 13
dimensionValue:
: 0.0602470003
:::
#### Available Section-Level Topic Model Vectors
general `modelName = general`:
: general model used for most sections and documents
`modelVersion = VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad
`
business `modelName = business-discussion`:
: The model used for the "business" discussion sections of SEC filings.
`modelVersion`:
: * `VocabularyLda.train-7e88246f08a48bb9a0eaaf928ab32a1969160424-a0f0f4c8da9aefa6ff594de804229b78839457f9`
management `modelName = management-discussion`:
: The model used for the "management" discussion sections of SEC filings.
`modelVersion`:
: * `VocabularyLda.train-7e88246f08a48bb9a0eaaf928ab32a1969160424-06092a01e977e851fb6f9fb94e4e158521c43104`
risk `modelName = risk-discussion`:
: The model used for the "risk" discussion sections of SEC filings.
* `VocabularyLda.train-7e88246f08a48bb9a0eaaf928ab32a1969160424-4062dab819e845468b13f84097cc47f54b556612`
| modelName | ARTICLES | SEC |
|-----------|:--------:|:---:|
| `general` | ✔ | ✔ |
| `business-discussion` | ✖ | 10-K section 1|
| `management-discussion` | ✖ | 10-K section 7 <br> 10-Q section 2 |
| `risk-discussion` | ✖ | 10-K section 1A <br> 10-Q section 1A |
#### In-Depth
Topic Vector Models In Depth
With the introduction of Topic Vector Models we introduce two new mathematical models: Latent Dirichlet Allocation (LDA) and Vocabulary LDA. The first model well documented in the machine learning literature so we will only briefly describe it here. We will follow with a description of our Vocabulary LDA model which builds upon the vanilla LDA.
##### LDA
In the Latent Dirichlet Allocation model, we take a sequence of words and try to represent them as a set of independent topic vectors. Each topic vector is a weight assigned to a topic (the element's index is the topic identifier). Each of the topics are treated as distributions over a set of vocabulary words. So, for the LDA model we take a sequence of words and treat them independently and together as a "bag of words". This bag of words is then factored into the weighting of each topic distribution (aka. each topic) by it's likelihood of coming from that distribution. The resulting topic weights are concatenated into a single vector resulting in our topic vector model result. Because the topics are distributions over a vocabulary, each different vocabulary and/or distribution will result in different topic vector that are not comparable. This is why we cannot compare the topic vector of different model versions: they are using completely different word distributions (and maybe even different word vocabularies)
##### Vocabulary
From the previous section we know that the vocabulary and distribution over the vocabulary words forms the essence of a topic in the LDA framework. It turns out that certain domains of language use certain vocabularies that are distinct and informative to the domain. For example: the phrase "fiduciary responsibility" is more often used in financial statements and analysis than twitter rants. To capture this intuitive domain-specific language constraint, we developed the Vocabulary LDA model(s).
While the original LDA formulation formed a "bag of words" by treating words independently, our new Vocabulary LDA will actually work on "bags of phrases". Using our core NLP engine, we extract informative, highly salient phrases that appear for distinct sections of documents. These phrasings are then used as the core "vocabulary" for our LDA. Instead of representing distributions of words, our topics now represent distributions over salient phrases.
We have built three specific Vocabulary LDA models,each one trained on salient phrasings from SEC document sections relating to business, management, and risk. These three models allow for a domain-specific phrase-aware topic vectors which can be used to compute domain-specific phrase-aware distances.
The following thought experiment should elucidate the need for and utility of the Vocabulary LDA model. Think of a collection of twitter newsfeed items alongside a group of SEC Form 10-K filings. It is clear that the words and language used in the twits is different from the 10-K language and so using the vanilla LDA approach you will see a large distance between the twitter documents and the SEC documents. However, the SEC documents themselves all look like "non-twitter" and the twitter document all look like "non-SEC"; there is not a lot of dynamic range in the distance between same-source documents here. Now, consider the Vocabulary LDA model. Under a Vocabulary LDA model trained for SEC vocabulary we will still see that twitter and SEC filings are different, but we will also have the resolution to judge distances between the SEC filings.
## Relationships
A semantic association based on the ForgeAI relationship ontology between two entities in the document.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| ++docId++ | CHAR(48) | ✖ | Foreign key to `Documents(docId)` |
| ++relationshipId++ | INTEGER | ✖ | The document scope unique id for the relationship. |
| subjectLabel | STRING | ✖ | The entity that is acting as the source in the directed relationship. In an undirected relationship, the source and object entities are interchangeable. |
| subjectEntityId | INTEGER | ✔ | The entity ID for this entity if found in the entities section. |
| predicateLabel | STRING | ✖ | The extracted entity that is acting as the predicate joining the subject and object entities. |
| objectLabel | STRING | ✖ | The entity that is acting as the object or destination in the directed relationship. In an undirected relationship the source and object entities are interchangeable. |
| objectEntityId | INTEGER | ✔ | The entity ID for this entity if found in the entities section. |
| confidence | FLOAT | ✖ | The calculated confidence of the extracted relationship. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
relationshipId:
: 1
subjectLabel:
: Mary Margaret Kreuper
subjectEntityId:
: NULL
predicateLabel:
: isA
objectLabel:
: Sister
objectEntityId:
: NULL
confidence:
: 0.96526194
:::
### RelationshipPredicateAssertions
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Relationships(docId, relationshipId)` |
| relationshipId | INTEGER | ✖ | Foreign key to `Relationships(docId, relationshipId)` |
| assertedClass | VARCHAR(2048) | ✖ | The URI for the asserted semantic type. |
| predicate | STRING | ✔ | The predicate for the assertion such as "isA", "ownerOf" etc. |
| confidence | FLOAT | ✔ | A value from 0.0-1.0 of the confidence in the assertion. |
### RelationshipSupportingSentences
Information identifying the locations in the document supporting the relationship assertion.
| NAME | TYPE | NULLABLE? | COMMENT |
|------|------|:---------:|---------|
| docId | CHAR(48) | ✖ | Foreign key to `Relationships(docId, relationshipId)` |
| relationshipId | INTEGER | ✖ | Foreign key to `Relationships(docId, relationshipId)` |
| sentenceId | INTEGER | ✖ | The document scope ID for the supporting sentence. |
##### Example:
:::info
docId:
: 03afceb2-8369-44b0-9909-3d50bb51e385
relationshipId:
: 1
sentenceId:
: 4
:::
# Sample Queries
## Number of documents collected by sites over the past week
```sql=
SELECT ANY_VALUE(name) AS name,
REGEXP_REPLACE(url, 'https?:\/\/(www\.)?([^\/]+).*', '\\2') AS site,
COUNT(*) AS cnt
FROM Documents d
JOIN DocumentSource s ON (s.docId = d.docId)
WHERE url LIKE 'http%'
AND collectDatetime >= DATEADD(DAY, -7, CURRENT_DATE())
GROUP BY site
ORDER BY cnt DESC
```
## Documents timeseries (by day)
```sql=
SELECT TO_DATE(IFF(docDatetime IS NULL OR docDatetime = '1970-01-01', collectDatetime, docDatetime)) AS date,
COUNT(*) AS documents
FROM Documents
WHERE date BETWEEN '2010-01-01' AND CURRENT_DATE()
GROUP BY 1
ORDER BY 1 DESC
```
## Documents mentioning a company of interest
### Using the company's CIK
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN EntityProperties p ON (p.docId = d.docId)
WHERE name = 'cik' AND value = '320193'
```
### Knowing the company's URI
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN EntityAssertions a ON (a.docId = d.docId)
WHERE assertedClass = 'http://forge.ai/company/apple_inc'
```
#### Finding a company's URI
```sql=
SELECT DISTINCT label, assertedClass
FROM Entities e
JOIN EntityAssertions a ON (a.docId = e.docId AND a.entityId = e.entityId)
WHERE label ILIKE 'apple%'
AND assertedClass LIKE 'http://forge.ai/company/%'
```
### Using the company's name
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN Entities e ON (e.docId = d.docId)
JOIN EntityAssertions a ON (a.docId = e.docId AND a.entityId = e.entityId)
WHERE label = 'WallaMe'
AND assertedClass = 'http://forge.ai/entity#Organization'
```
## Documents mentioning a company of interest within the past 7 days
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN EntityAssertions a ON (a.docId = d.docId)
WHERE assertedClass = 'http://forge.ai/company/apple_inc'
AND docDatetime >= DATEADD(DAY, -7, CURRENT_DATE())
```
### Number of documents per day mentioning a company of interest within the past 7 days
```sql=
SELECT TO_DATE(docDateTime) AS date, COUNT(*) AS cnt
FROM Documents d
JOIN EntityAssertions a ON (a.docId = d.docId)
WHERE assertedClass = 'http://forge.ai/company/apple_inc'
AND docDatetime >= DATEADD(DAY, -7, CURRENT_DATE())
GROUP BY 1
ORDER BY 1 ASC
```
## Documents mentioning a company of interest from a specific source
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN DocumentSource s ON (s.docId = d.docId)
JOIN EntityAssertions a ON (a.docId = d.docId)
WHERE assertedClass = 'http://forge.ai/company/apple_inc'
AND name = 'CNN'
```
## Documents mentioning 2 companies of interest
```sql=
SELECT DISTINCT d.docId, url, title
FROM Documents d
JOIN EntityAssertions a1 ON (a1.docId = d.docId)
JOIN EntityAssertions a2 ON (a2.docId.docId)
WHERE a1.assertedClass = 'http://forge.ai/company/apple_inc'
AND a2.assertedClass = 'http://forge.ai/company/alphabet_inc.'
```
Or
```sql=
SELECT DISTINCT d.docId, url, tile
FROM Documents d
JOIN EntityAssertions a1 ON (a1.docId = d.docId)
JOIN Entities e2 ON (e2.docId = d.docId)
JOIN EntityAssertions a2 ON (a2.docId = e2.docId AND a2.entityId = e2.entityId)
WHERE a1.assertedClass = 'http://forge.ai/company/apple_inc'
AND e2.label = 'WallaMe'
AND a2.assertedClass = 'http://forge.ai/entity#Organization'
```
## Document Sentiment over time for a company of interest
```sql=
SELECT TO_DATE(IFF(d.docDatetime IS NULL, d.collectDatetime, d.docDatetime)) AS date,
AVG(s.combined) AS sentiment
FROM Entities e
JOIN DocumentSentiments s ON (s.docId = e.docId AND s.modelVersion = 'VaderValance.train-2520d1b931dab7458a063a61c14c8ea411582936-2fdb6f68f4f976fe42d6febf9e37ed2ba8c6983c')
JOIN Documents d ON (d.docId = e.docId)
WHERE e.label ILIKE 'danske bank'
AND date IS NOT NULL
AND date > '2010-01-01'
GROUP BY 1
ORDER BY 1
```
## Intrinsinc Events for a company of interest
```sql=
WITH t AS (
SELECT e.docId, l.sentenceId
FROM Entities e
JOIN EntityLocations l ON (l.docId = e.docId AND l.entityId = e.entityId)
WHERE e.label ILIKE 'danske bank%'
)
SELECT TO_DATE(IFF(docDatetime IS NULL OR docDatetime = '1970-01-01', collectDatetime, docDatetime)) AS date,
UPPER(e.label) AS ievent,
COUNT(*) AS observations
FROM t
JOIN Entities e ON (e.docId = t.docId)
JOIN EntityLocations l ON (l.docId = e.docId AND l.entityId = e.entityId)
JOIN EntityAssertions a ON (a.docId = e.docId AND a.entityId = e.entityId)
JOIN Documents d ON (d.docId = e.docId)
WHERE l.sentenceId = t.sentenceId
AND a.assertedClass = 'http://forge.ai/entity#IntrinsicEvent'
AND a.confidence > 0.4
AND date IS NOT NULL
AND date > '2010-01-01'
GROUP BY 1,2
ORDER BY 1
```
## Documents classified with a topic of interest
```sql=
SELECT DISTINCT docId, url
FROM Documents d
JOIN DocumentTopics t ON (t.docId = d.docId)
WHERE name = 'bankruptcy'
```
## Companies (with their ticker symbol) mentioned in articles about Merger & Acquisitions
```sql=
SELECT SUBSTR(assertedClass, 25) AS company,
p.value AS ticker,
COUNT(DISTINCT docId)
FROM DocumentTopics t
JOIN EntityAssertions a ON (a.docId = t.docId)
LEFT JOIN EntityProperties p ON (p.docId = t.docId AND p.entityId = t.entityId)
WHERE t.name = 'Merger and Acquisition'
AND a.assertedClass LIKE 'http://forge.ai/company/%'
AND p.name = 'ticker'
GROUP BY 1, 2
```
## Topics for a company of interest
```sql=
SELECT t.name, COUNT(*) AS occurrences
FROM Entities e
JOIN DocumentTopics t ON (t.docId = e.docId)
WHERE e.label ILIKE 'danske bank'
GROUP BY 1
ORDER BY occurrences DESC
```
## Relationships from a person of interest
```sql=
SELECT LOWER(predicateLabel), LOWER(objectLabel), MAX(confidence) AS confidence, COUNT(*) AS COUNT
FROM Relationships
WHERE LOWER(subjectLabel) = 'tim cook'
GROUP BY 1,2
ORDER BY 4 DESC
```
## Relationships with a company of interest
```sql=
SET label = 'danske bank';
SELECT LOWER(subjectlabel) AS subject, UPPER(predicatelabel) AS relationship, LOWER(objectlabel) AS object,
COUNT(*) AS observed,
AVG(confidence) AS confidence,
MIN(NVL(d.docDatetime, d.collectDatetime)) AS t1,
MAX(NVL(d.docDatetime, d.collectDatetime)) AS t2
FROM Relationships r
JOIN Documents d ON (d.docId = r.docId)
WHERE (subjectlabel ILIKE $label OR objectlabel ILIKE $label)
GROUP BY 1,2,3
ORDER BY observed DESC
```
## Co-occurrences with a company of interest
```sql=
WITH E AS (
SELECT e.docId,
e.entityId,
LOWER(REGEXP_REPLACE(REGEXP_REPLACE(e.label, '[\\s\\W]+', ' '),
'^\\s*(\\S.*\\S)\\s*$', '\\1')) AS label,
a.assertedclass AS type,
l.sentenceId
FROM Entities e
JOIN EntityAssertions a ON ( a.docId = e.docId
AND a.entityId = e.entityId
AND a.assertedclass LIKE 'http://forge.ai/entity#%')
JOIN EntityLocations l ON ( l.docId = e.docId
AND l.entityId = e.entityId)
WHERE assertedclass IN ('http://forge.ai/entity#Person','http://forge.ai/entity#Title','http://forge.ai/entity#Nationality',
'http://forge.ai/entity#Organization',
'http://forge.ai/entity#GeopoliticalEntity','http://forge.ai/entity#Location',
'http://forge.ai/entity#IntrinsicEvent',
'http://forge.ai/entity#DomainTerm')
)
SELECT e1.label AS label1,
e1.type AS type1,
e2.label AS label2,
e2.type AS type2,
COUNT(DISTINCT e1.docId) AS cnt,
MIN(d.t) AS t0,
MAX(d.t) AS t1
FROM E e1
JOIN E e2 ON ( e2.docId = e1.docId
AND e2.entityId != e1.entityId
AND e2.label != e1.label)
JOIN (
SELECT docId, TO_DATE(IFF(docDatetime = '1970-01-01' OR docDatetime IS NULL, collectDatetime, docDatetime)) AS t
FROM Documents) d ON (d.docId = e1.docId)
WHERE e1.label IN ('danske bank', 'danske bank a s') AND e1.type = 'http://forge.ai/entity#Organization'
AND e2.sentenceId BETWEEN e1.sentenceId - 1 AND e1.sentenceId + 1
GROUP BY 1,2,3,4
ORDER BY cnt DESC, DATEDIFF(DAY, t0, t1) DESC
```
## Documents that cluster (in one dimension of the LDA space) around a company of interest
```sql=
WITH LDA AS (
-- The "VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad" LDA vector
SELECT *
FROM DocumentTopicModelVectors
WHERE modelVersion = 'VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad'
), Apple AS (
-- Apple's average LDA vector
SELECT dimensionindex, AVG(dimensionvalue) AS dimensionvalue
FROM LDA
WHERE EXISTS (SELECT 1
FROM EntityAssertions a
WHERE a.docId = LDA.docID
AND assertedClass = 'http://forge.ai/company/apple_inc')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1)
SELECT LDA.docId, url, title
FROM LDA
JOIN Apple ON (Apple.dimensionindex = LDA.dimensionindex
AND ABS(Apple.dimensionvalue - LDA.dimensionvalue) < 0.005)
JOIN Documents d ON (d.docId = LDA.docId)
WHERE NOT EXISTS (SELECT 1
FROM EntityAssertions a
WHERE a.docId = d.docId
AND assertedClass = 'http://forge.ai/company/apple_inc')
```
## Documents that cluster (in the LDA vector space) around a company of interest
```sql=
WITH LDA AS (
-- The "VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad" LDA vector
SELECT *
FROM DocumentTopicModelVectors
WHERE modelVersion = 'VanillaLda.model-identifier-979b20fdc5691083320d4a61c515e64e0b53ecf9-a6728cf46f462fc4e38b53e8420a386dbe5d75ad'
), Apple AS (
-- Apple's average LDA vector
SELECT dimensionindex, AVG(dimensionvalue) AS dimensionvalue
FROM LDA
WHERE EXISTS (SELECT 1
FROM EntityAssertions a
WHERE a.docId = LDA.docId
AND assertedClass = 'http://forge.ai/company/apple_inc')
GROUP BY 1)
SELECT docId, url, title, SUM(SQUARE(NVL(lda.dimensionvalue, 0) - NVL(Apple.dimensionvalue, 0))) AS d
FROM LDA
FULL OUTER JOIN Apple ON (Apple.dimensionindex = LDA.dimensionindex)
WHERE NOT EXISTS (SELECT 1
FROM EntityAssertions a
WHERE a.docId = LDA.docId
AND assertedClass = 'http://forge.ai/company/apple_inc')
GROUP BY 1
HAVING d < 0.01
```
## List all 8-K filings for Apple (CIK=320193) in 2018Q3
```sql=
SELECT d.docId, title, TO_DATE(docDatetime)
FROM SEC_8K.Documents d
JOIN SEC_8K.DocumentMetadata md ON (md.docId = d.docId)
WHERE name = 'forgeai:company-cik'
AND TRY_CAST(value AS INT) = 320193
AND YEAR(docDatetime) = 2018
AND QUARTER(docDatetime) = 3
```
## List all organizations mentioned in a Risk Factors section (1A) of a 10-K filing for Apple (CIK=320193)
```sql=
SELECT smd.docId, url, label
FROM SEC_10K.SectionMetadata smd
JOIN SEC_10K.Entities e ON (e.docId = smd.docId)
JOIN SEC_10K.EntityAssertions a ON (a.docId = e.docId AND a.entityId = e.entityId)
JOIN SEC_10K.EntityLocations l ON (l.docId = e.docId AND l.entityId = e.entityId)
JOIN SEC_10K.Sentences s ON (s.docId = smd.docId AND s.sectionId = smd.sectionId AND s.sentenceId = l.sentenceId)
JOIN SEC_10K.Documents d ON (d.docId = smd.docId)
WHERE name = 'forgeai:sec-section-type'
AND value = '1A'
AND EXISTS (SELECT 1
FROM SEC_10K.DocumentMetadata d
WHERE d.docId = smd.docId
AND name = 'forgeai:company-cik'
AND value::INT = 320193)
AND assertedClass = 'http://forge.ai/entity#Organization'
```
# Revision History
## 06.30
### New Tables
* [DocumentSentiments](#DocumentSentiments)
* [EntityScores](#EntityScores)
* [EntitySentiments](#EntitySentiments)
### New Scores
* [entity-sentiment](#EntitySentiments)
* [entity-saliency](#EntityScores)
### Removed Scores
* [Document dissonance](#DocumentScores) and [Section dissonance](#SectionScores)
* [Section lexica](#SectionScores) and [Section VADER](#SectionScores)
### Articles pipeline updates
* Extended historical coverage starting from Oct-2018.
* Full Dow Jones feed articles since 2008 in the `DJN` schema (when available)
## 06.20
### New Tables
* [DocumentScores](#DocumentScores)
* [EntityAliases](#EntityAliases)
* [SectionScores](#SectionScores)
### Changed Tables
* [DocumentTopics](#DocumentTopics)
* Added `topicId`
* Added `startSentenceId` and `endSentenceId`
* [DocumentTopicWords](#DocumentTopicWords)
* Added `topicId`
* Added `count`
* Removed `name` and `parent`.
Instead use [DocumentTopicWords.topicId](#DocumentTopics) to reference [DocumentTopics.name](#DocumentTopics) and [DocumentTopics.parent](#DocumentTopics).
### New Scores
* [VADER](#DocumentScores) -- aka sentiment
* [lexica](#DocumentScores)
* [dissonance](#DocumentScores)
### Articles pipeline updates
* Ontological Categorizer for more diverse and precise topics classification.
### SEC pipeline updates
* Split `SEC` schema into `SEC_8K`, `SEC_10K`, and `SEC_10Q`
* 10-yr historical: 2009 and up
* Improved extraction
* Entity resolution
* Re-trained jargon LDA models
* Relationships
* Removed `forgeai:sec-filing-year` and `forgeai:sec-filing-qtr` metadata.
Instead use `YEAR(docDatetime)` and `QUARTER(docDatetime)`.
# Useful links
* [Forge.AI Reference](https://reference.forge.ai)
* [Snowflake Documentation](https://docs.snowflake.net)
* [Connecting to Snowflake](https://docs.snowflake.net/manuals/user-guide-connecting.html)
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet