# Working Effectively with Legacy Code (Chapter 1 ~ Chapter 6)
> [name=謝朋諺]
> [time=Fri, Feb 16, 2024 9:51 PM]
---
> [TOC]
---
# Chapter 1 修改軟體
## 1.1 修改軟體的四個起因
### 1.1.1 添加特性和修正 bug
:::success
:book: 軟體原先以某種方式運作,現在用戶提出需求希望這個系統能夠做其他事情。
:book: 軟體原本行為有問題,導致需要修正或移除。
:::
### 1.1.2 改善設計
:::success
:book: 在不改變軟體行為的前提下,改善其設計的舉動稱之為重構 (Refactoring)
:::
重構時並不只是做低危險性的工作(如重整程式碼的格式),或侵入性的危險工作(如重寫)程式碼區塊。
### 1.1.3 最佳化
:::success
:book: 與重構相同的地方是都會保持功能不變。
:book: 與重構不同的地方是最佳化專指對某些東西所用的資源優化,例如時間或記憶體。
:::
### 1.1.4 綜合起來
| | 添加特性 | 修正 bug | 重構 | 最佳化 |
| -------- |:--------:|:--------:|:----:|:------:|
| 結構 | 改變 | 改變 | 改變 | - |
| 新功能 | 改變 | - | - | - |
| 功能 | - | 改變 | - | - |
| 資源使用 | - | - | - | 改變 |
## 1.2 危險的修改
為了減少風險,先考慮以下三個問題:
1. 我們要進行哪些修改?
2. 我們如何得知已經正確地完成了修改?
3. 我們如何得知沒有破壞任何(既有的)東西?
- 什麼樣風險是可以承擔的?
- 一直避免變動反而會導致生疏,因此應該更努力地去修改。
---
# Chapter 2 帶著回饋工作
系統變動有兩種:
- 編輯並祈禱(edit and pray)
- 覆蓋並修改(cover and modify)覆蓋並修改(cover and modify)
透過回歸測試 (regression testing) 週期性地執行測試來檢驗已知的良好行為,以便確診軟體是否還像以前那樣工作。
:::info
:bulb: **軟體夾鉗(Software Vise)**
當要動手進行變動的區域由測試包圍時,這些測試的作用就好比一把「軟體夾鉗」,透過這個軟體夾鉗就可以固定住軟體的大部分行為,只變動真正想變動的地方。
:::
## 2.1 什麼是單元測試
在單元測試這個領域,通常最關心的是一個最為「原子」的行為單位,在程式碼中指的就是「函數」,在物件導向的程式碼中指的就是類別。
大型測試有一些缺點:
- **錯誤定位**:測試離測試對象越遠,就越難確定測試失敗究竟意味著什麼。
- **執行時間**:大型測試往往需要更長時間來執行。
- **覆蓋**:在大型測試中,往往難以看出某段程式碼,與用來測試他的值之間的聯繫。
好的單元測試應有以下品質:
- **執行快**
- **能幫助我們定位問題所在**
:::warning
:fire: 一個需要耗時 **0.1 sec** 才能執行完的單元測試,已經算是一個慢的單元測試。
:::
:::danger
:scream: 有些測試容易跟單元測試混肴,例如以下就不是單元測試:
1. 與資料庫有互動
2. 進行了網路通訊
3. 接觸到檔案系統
4. 需要你對環境做特定的準備(如編輯設定檔案)才能夠執行。
以上這些測試也很重要,通常也會在單元測試控制工具來編寫他們。
但將他們跟真正的單元測試拆開來很重要,這樣就可以知道哪些測試是可以快速執行的!
:::
## 2.2 高層測試
覆蓋了應用程式的場景與互動的測試。
## 2.3 測試覆蓋
:::warning
:fire: 依賴性是軟體開發中最為關鍵的問題之一。在處理遺留程式碼的過程中有很大一部份工作都是圍繞著「解除依賴性以便使修改變得更容易」這個目標來進行的。
:::
:::warning
**遺留程式碼的困境**
我們在修改程式碼時,應當有測試在周圍「護」著。而為了將這些測試安置妥當,我們往往又得去修改程式碼。
:::
:::success
:computer: 當在遺留程式碼中解依賴時,你常常不得不暫時將自己的審美觀放在一旁。就像在動手術一樣總要有一個刀口,切完就會有一個疤痕。
但如果未來可以用測試覆蓋疤痕四周(即當初解依賴的點),你就可以將疤痕抹去了。
:::
## 2.4 遺留程式碼修改演算法
以下演算法可以對遺留 code base 進行修改
1. 確定變動點
2. 找出測試點
3. 解依賴
4. 編寫測試
5. 修改、重構
後續章節會針對這幾個步驟做更詳細的技法介紹,這邊主要都介紹心法為主。
### 2.4.1 確定修改點
你所要進行修改的地點與程式碼的架構聯繫很緊密,前者敏感地依賴後者。
### 2.4.2 找出測試點
對於遺留程式碼來說找出測試點並不容易。
### 2.4.3 解依賴
**依賴往往是進行測試最明顯的障礙。**
1. 難以在測試控制工具中實例化目標物件。
2. 難以在測試控制工具中執行的方法
### 2.4.4 編寫測試
為遺留程式碼寫測試與為新程式寫測試是不同的事情。
### 2.4.5 變動和重構
作者提倡使用測試驅動 TDD 方式來替遺留程式碼添加特性。
---
# Chapter 3 感測和分離
有時候我們必須偽裝一些被影響的類別,來直接感測到他所受到的影響。
通常我們想要測試安置到位,有兩個理由去進行解依賴:感測和分離。
1. 感測:當我們無法存取到程式碼計算出的值時,需要透過解依賴來「感測」這些值。
2. 分離:當我們無法將一部份程式碼放入測試控制工具中去執行時,就需要解依賴將這塊程式碼「分離」出來。
## 3.1 偽裝成合作者 (Fake Collaborators)
:::success
:bulb: 用另外的程式碼來取代被依賴的類別並透過它來進行測試的話,就可以放手進行測試。
:::
### 3.1.1 偽物件 (Fake Object)
Sale Class
```java=
public class Sale
{
private Display display;
public Sale(Display display) {
this.display = display;
}
public void scan(String barcode) {
...
String itemLine = item.name()
+ " " + item.price().asDisplayText();
display.showLine(itemLine);
...
}
}
```
Interface:
```java=
// Java
public interface Display
{
void showLine(String line);
}
```
Fake Display 的實作
```java=
// Java
public class FakeDisplay implements Display
{
private String lastLine = "";
public void showLine(String line) {
lastLine = line;
}
public String getLastLine() {
return lastLine;
}
}
```
測試
```java=
// Java
import junit.framework.*;
public class SaleTest extends TestCase
{
public void testDisplayAnItem() {
FakeDisplay display = new FakeDisplay();
Sale sale = new Sale(display);
sale.scan("1");
assertEquals("Milk $3.99", display.getLastLine());
}
}
```
**Python 版本**
Sale Class
```python=
# python
class Sale:
def __init__(self, display: father):
self.display = display
def scan(self, barcode):
...
item = Item()
item_line = f'{item.name()} {item.price().as_display_text()}'
self.display.show_line(item_line)
...
```
ABC
```python=
# python
from abc import ABC, abstractmethod
class Display(ABC):
@abstractmethod
def show_line(self, line: str):
pass
```
Fake Display 的實作
```python=
# python
class FakeDisplay(Display):
def __init__(self):
self.last_line = ''
def show_line(self, line: str):
self.last_line = line
def get_last_line(self) -> str:
return self.last_line
```
測試
```python=
# python
import unittest
class SaleTest(unittest.TestCase):
def test_display_an_item(self):
display = FakeDisplay()
sale = Sale(display)
sale.scan('1')
self.assertEqual('Milk $3.99', display.get_last_line())
if __name__ == '__main__':
unittest.main()
```
### 3.1.2 偽物件的兩面性
1. 一個是原本 interface 或是 abc 就有的 function `show_line`,而 `get_last_line` 則是為了我們測試寫的。
2. 對於 `Sale` 類別只知道 `showLine`,而且他會把 FakeDisplay 視為一個 `Display`。
### 3.1.3 偽物件手法的核心理念
在物件導向語言中就可以透過定義簡單的類別來實作;而非物件導向語言中,則可以定義一個替代函數來達到偽裝的目的。
### 3.1.4 仿物件(mock object)
:::success
:notebook: 仿物件就是內部進行斷言檢查的偽物件。
:::
製造一個假的 mock class
**Java 版本**
```java=
// java
import junit.framework.*;
public class SaleTest extends TestCase
{
public void testDisplayAnItem() {
MockDisplay display = new MockDisplay();
display.setExpectation("showLine", "Milk $3.99");
Sale sale = new Sale(display);
sale.scan("1");
display.verify();
}
}
```
**Python 版本**
```python=
# python
import unittest
from unittest.mock import Mock
class SaleTest(unittest.TestCase):
def test_display_an_item(self):
display = Mock()
display.show_line.return_value = 'Milk $3.99'
sale = Sale(display)
sale.scan('1')
display.show_line.assert_called_once_with('Milk $3.99')
if __name__ == '__main__':
unittest.main()
```
Mock 會直接告訴測試他期待的結果會是什麼,有點像是直接跳過 `display` 的測試,我們直接寫結果給他丟到 `Sale` 去做測試。
:::warning
:bulb: 偽物件和仿物件的語意有著極細微的差別。前者是「偽裝」成目標物件,目的是欺騙被測試者,讓他以為使用的是真正的目標物件。而後者雖說也是「假」貨,然而其目的卻在於盡量模仿真實的目標物件的行為,被測試者可以(從行為上)把它看作一個真正的目標物件來使用。
:::
# Chapter 4 接縫模型
一般而言程式設計語言對測試的支援不太好,要想最終得到易於測試的程式只有兩條路:
1. 一條路是邊開發邊寫測試
2. 另一條路是在前期花時間,試著將易測試性納入整體的設計考量。
人們對於第一種方案的期望甚高,不過若是以業界大量程式碼的驗證來看,第二種方法在過去並沒有取得多大的成功。
下面會介紹一些作者的怪癖給大家看。
## 4.1 一大段文字
作者小時候跑程式會算錢,所以會習慣把程式碼印出來確認沒問題再下去跑,就很像是在看一大串很長的文字。
另外他也提到:人們常說寫程式最好的方式是,將一小段可重用的程式組件組合再一起。但問題是這些組件被單獨重用的頻率並不算高。
## 4.2 接縫(seam)
:::info
:bulb: 接縫是指程式中的一些特殊點,在這些點上你無需做任何修改就可以達到變動程式行為的目的。
:::
**C++版本**
```cpp=
// C++
bool CAsyncSslRec::Init()
{
if (m_bSslInitialized) {
return true;
}
m_smutex.Unlock();
m_nSslRefCount++;
m_bSslInitialized = true;
FreeLibrary(m_hSslDll1);
m_hSslDll1 = 0;
FreeLibrary(m_hSslDll2);
m_hSslDll2 = 0;
if (!m_bFailureSent) {
m_bFailureSent = TRUE;
PostReceiveError(SOCKETCALLBACK, SSL_FAILURE);
}
CreateLibrary(m_hSslDll1, "syncesel1.dll");
CreateLibrary(m_hSslDll2, "syncesel2.dll");
m_hSslDll1->Init();
m_hSslDll2->Init();
return true;
}
```
如果我想測試這段 code 但不想測到 `PostReceiveError` 這個函式,又不能更改程式碼的話可以透過增加一個間接層,來特別處理。
```cpp=
// C++
class CAsyncSslRec::PostReceiveError(UINT type. UINT errorcode)
{
::PostReceiveError(type. errorcode);
};
```
上面這段只是引入一個小小的間接層,但最終還是呼叫同樣的函數。
```cpp=
class TestingAsyncSslRec : public CAsyncSslRec
{
virtual void PostReceiveError(UINT type. UINT errorcode)
{
}
};
```
如果將 `CAsyncSslRec` 子類別化並覆寫 `PostReceiveError` 就可以改成上面這樣,這樣便可以跳過測試全域的 `PostReceiveError`。
**Python 版本**
```python=
# Python
class CAsyncSslRec:
def __init__(self):
self.m_bSslInitialized = False
self.m_smutex = Smutex() # Assuming Smutex is a class for mutex
self.m_nSslRefCount = 0
self.m_hSslDll1 = None
self.m_hSslDll2 = None
self.m_bFailureSent = False
def Init(self):
if self.m_bSslInitialized:
return True
self.m_smutex.Unlock()
self.m_nSslRefCount += 1
self.m_bSslInitialized = True
FreeLibrary(self.m_hSslDll1)
self.m_hSslDll1 = 0
FreeLibrary(self.m_hSslDll2)
self.m_hSslDll2 = 0
if not self.m_bFailureSent:
self.m_bFailureSent = True
PostReceiveError(SOCKETCALLBACK, SSL_FAILURE)
CreateLibrary(self.m_hSslDll1, "syncesel1.dll")
CreateLibrary(self.m_hSslDll2, "syncesel2.dll")
self.m_hSslDll1.Init()
self.m_hSslDll2.Init()
return True
```
Python 的話需要寫一個 monkey patching 蓋過他就可以
```python=
# python
import unittest
from unittest.mock import patch
class TestCAsyncSslRec(unittest.TestCase):
@patch('main.PostReceiveError')
def test_Init_no_PostReceiveError(self, mock_PostReceiveError):
from main import CAsyncSslRec
# 創建CAsyncSslRec實例
ssl_rec = CAsyncSslRec()
# 調用Init方法
result = ssl_rec.Init()
# 驗證是否成功初始化,並且未調用PostReceiveError
self.assertTrue(result)
self.assertFalse(mock_PostReceiveError.called)
if __name__ == '__main__':
unittest.main()
```
## 4.3 接縫類型
### 4.3.1 預處理期接縫
- 有些程式語言可以透過編譯前做一些預處理,例如 C, C++,可以先由巨集預處理器進行預處理。
- 過度使用預處理並不是一個好主意,因為它會降低程式碼的清晰度,條件編譯指令(`#ifdef`, `#ifndef`, `#if`) 幾乎等於是在強迫你在同一份原始碼中維護多個不同的程式。
- 遇到一個接縫,就意味著我們可以改變其行為,我們也不能僅僅為了測試就修改程式碼,應該讓原始碼在產品階段和測試階段是完全一樣的。
- 每個接縫還有一個致能點(enabling point)。
:::info
:bulb: 致能點(enabling point)
每個接縫都有一個致能點,在這些點上你可以決定使用哪種行為。
:::
### 4.3.2 連接期接縫
- 連接期接縫有點像是 Java 的 import 會讓編譯器在幕後負責進行連接程序,當一個 Java 原始檔包含了 import 語句時就會檢查 import 的類別是否已被編譯,如果沒有,就先對其編譯,然後再檢查所有呼叫是否都能在執行期正確決議。
假設我們有一段 CAD 應用程式:
```java=
// java
void CrossPlaneFigure::rerender()
{
//draw the label
drawText(m_nX, m_nY, m_pchLabel, getClipLen());
drawText(m_nX, m_nY, m_nX + getClipLen(), m_nY);
drawText(m_nX, m_nY, m_nX, m_nY + getClipLen());
if(!m_bShadowBox) {
drawLine(m_nX + getClipLen(), m_nY,
m_nX + getClipLen(), m_nY + getDropLen());
drawLine(m_nX, m_nY + getClipLen(),
m_nX + getClipLen(), m_nY + getDropLen());
}
//draw the figure
for (int n = 0; n < edge.size(); n++) {
...
}
...
}
```
假設我們想要測試這段,並且不想因為繪圖函式庫導致的問題來做測試,為了要取代所有的繪圖函式,就必須自己建立一個 `stub` 版本,用來連接這個應用程式的其他剩餘部分,這個 `stub` 裡面就可以全放上相應的空函數:
:::info
:bulb: **stub** 在程式設計師口中是指「一小段(可能是由某種工具自動生成的)程式碼(可能是二進制的)」用來佔據某個位置,以達到某個特定目的(如轉發,或這裡的行為消除等)
:::
```java=
// java
void drawText(int x, int y, char *text, int textLength)
{
}
void drawLine(int firstX, int firstY, int secodX, int secondY)
{
}
```
遇到帶有返回值的函數,你則需要在相應的 `stub` 函數裡面返回某些東西,通常可以返為一個代表成功的值,例如:
```java=
// java
int getStatus()
{
return FLAG_OKAY;
}
```
第一種的方式是比較簡單的,但當需要回傳值的時候通常預設的回傳值在測試時都是不正確的,當然也可以直接用額外的資料結構實作額外的感測,例如:
```java=
// java
std::queue<GraphicsAction> actions;
void drawLine(int firstX, int firstY, int secondX, int secondY)
{
actions.push_back(GraphicsAction(LINE_DRAW, firstX, firstY, secondX, secondY))
}
```
不過一般要做到額外的感測會導致事情變得更複雜,最好一開始就就選比較簡單的方案。
:::success
:notebook: 連接期接縫的致能點,始終都是位於程式碼之外!例如有時是在建構或部署腳本中,這就使得連接期接縫的使用,顯得不那麼醒目。
:::
### 4.3.3 物件接縫
透過物件導向方式來做接縫,以下是一個反例:
```java=
// java
// 現在有三個類別,其中 Cell 是父類別,另外兩個都是繼承它,
// 且三個都有實作 Recalculate() 這個 function
class Cell
class ValueCell extends Cell
class FormulaCell extends Cell
```
```java=
// java
public class CustomSpreadsheet extends Spreadsheet
{
public Spreadsheet buildMartSheet() {
...
Cell cell = new FormulaCell(this, "A1", "=A2+A3");
...
cell.Recalculate(); // 這樣我們測試時就沒辦法把這邊當物件接縫,因為已經被第 6 行給定義住了。
}
}
```
但我們可以改成這樣:
```java=
public class CustomSpreadsheet extends Spreadsheet
{
public Spreadsheet buildMartSheet(Cell cell) {
...
cell.Recalculate(); // 這樣就可以透過參數來決定是用誰來做 Recalculate()
...
}
}
```
這樣上面就是一個物件接縫,而他的致能點就是 `buildMartSheet` 的參數列表。
另一個靜態案例:
```java=
public class CustomSpreadsheet extends Spreadsheet
{
public Spreadsheet buildMartSheet(Cell cell) {
...
Recalculate(cell); // 這樣就可以透過參數來決定是用誰來做 Recalculate()
...
}
private static void Recalculate(Cell cell) {
...
}
...
}
```
這邊 Recalculate 因為有 `static` 導致不能被繼承、不能被覆蓋;另外 `private` 也會導致無法繼承,因此可以改寫成這樣:
```java=
public class CustomSpreadsheet extends Spreadsheet
{
public Spreadsheet buildMartSheet(Cell cell) {
...
Recalculate(cell); // 這樣就可以透過參數來決定是用誰來做 Recalculate()
...
}
protected void Recalculate(Cell cell) {
...
}
...
}
// 寫測試的時候就可以改寫
public class TestingCustomSpreadsheet extends CustomSpreadsheet
{
protected void Recalculate(Cell cell) {
...
}
...
}
```
:::success
:fire: 一般來說,如果你用的是物件導向語言,則**物件接縫**是最佳選擇。
- **預處理期接縫**以及**連接期接縫**某些時候是有用的,但他們沒有**物件接縫**那麼清楚明顯。
- 另外依賴另外兩種接縫可能會導致難以維護。
- 但如果程式到處瀰漫著依賴性,而且沒有更好的方案時,那可能更傾向於保留**預處理期接縫**和**連接期接縫**。
:::
# Chapter 5 工具
## 5.1 自動化重構工具
:::info
:bulb: 重構(Refactoring)
名詞。對軟體內部結構的一種調整,目的是在不改變軟體外在行為的前提下,提高其可理解性、降低其修改成本。
:::
慎選自動化重構工具,本書提出了幾點特徵可以拿來當作標準:
1. function 在同類別同名時,該重構工具是否能檢測出來?
2. 重構工具有沒有保留行為,沒有的話千萬不要用。
:::danger
:bomb: 如果一個工具它能替你完成重構,那麼我們會傾向於認為無須未待重構的程式碼編寫測試,但事情常常並非如此,以下就是個案例:
```java=
public class A {
private int alpha = 0;
private int getValue() {
alpha++;
return 12;
}
public void doSomething(){
int v = getValue();
int total = 0;
for (int n = 0; n < 10; n++) {
total += v;
}
}
}
```
而在重構工具自動化重構後,變成下面這樣:
```java=
public class A {
private int alpha = 0;
private int getValue() {
alpha++;
return 12;
}
public void doSomething(){
int total = 0;
for (int n = 0; n < 10; n++) {
total += getValue();
}
}
}
```
**這邊的變數雖被移除了,卻把 alpha 值遞增了十次,而原先只是一次!** 這個變動明顯不能保留行為。
所以在自動化重構之前,先編寫必要的測試是有好處的。
當然也可以在沒有測試的時候做自動化重構,但就要先弄清楚你的工具會進行和不進行哪些檢查。
:::
## 5.2 仿物件
仿物件有很多免費套件可以使用,大部分可以透過 www.mockobjects.com 找到。(現在變成博弈網站了 XD,可以不用點他)
## 5.3 單元測試控制工具
- 作者極推 xUnit,但這好像是 .NET framework 的測試工具,包含 C#, F#, VB.NET 等語言所用。
- Java 的話則大推 JUnit。
- C++ 作者推薦自己寫的 CppUnitLite,他沒有瞧不起 CppUnit 原作者的意思,因為他就是 CppUnit 的作者 :sweat_smile:
### 5.3.1 JUnit
介紹,略
### 5.3.2 CppUnitLie
介紹,略
### 5.3.3 NUnit
NUmit 是 .NET 語言的測試框架之一,略
### 5.3.4 其他 xUnit 框架
略
## 5.4 一般測試控制工具
### 5.4.1 整合測試框架(FIT)
介紹 FIT 框架,主要是做整合測試,當你為你的系統編寫檔案,並在其中嵌入描述系統輸入和輸出的表格,並且可將這些檔案存成 HTML 的話,就可以將他們視為測試來執行。
http://fit.c2.com/
### 5.4.2 Fitness
另一個整合測試框架,是基於 Wiki 為宿主的 FIT,作者曾經也是其中開發的一員。
## 🧑💻 主委加碼:Python 的重構工具
### Bowler
Bowler 是一款用於在語法樹層級操作 Python 的重構工具。 它可以安全地大規模修改程式碼,同時確保產生的程式碼可以編譯和運行。 它提供了簡單的命令列介面和流暢的 Python API,可在程式碼中產生複雜的程式碼修改。
```python=
query = (
Query([<file paths>])
# rename class Foo to Bar
.select_class("Foo")
.rename("Bar")
# change method buzz(x) to buzzard(x: int)
.select_method("buzz")
.rename("buzzard")
.modify_argument("x", type_annotation="int")
)
query.diff() # generate unified diff on stdout
query.write() # write changes directly to files
```
### Sourcery
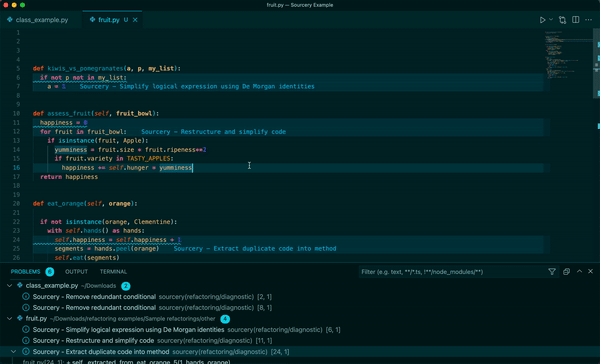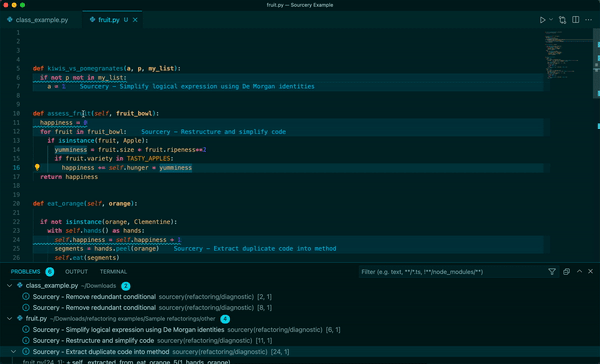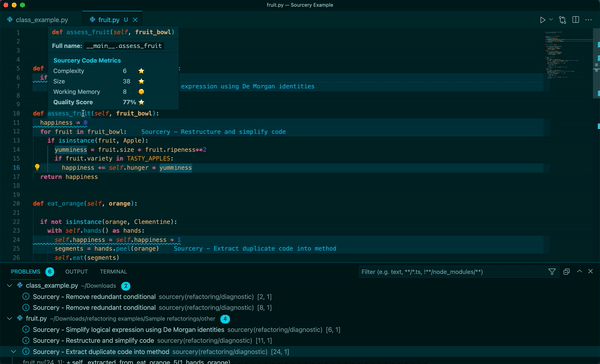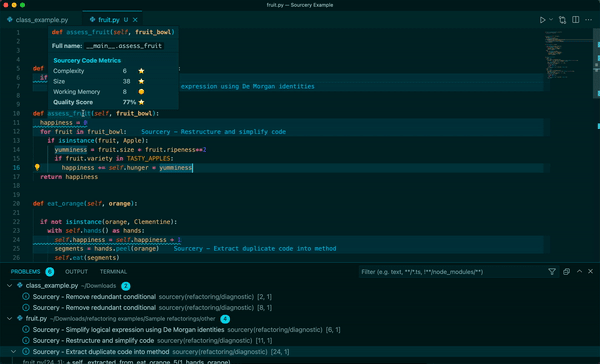
Sourcery 是一個自動程式碼審查程式,它將審查任何語言的任何拉取請求,以提供有關建議更改的即時回饋。每次審核都將包括變更摘要、高級回饋以及逐行建議/評論(如果相關)。
我們使用 ==OpenAI LLM== 進行程式碼審查。因此,我們需要向他們發送程式碼的各個部分(通常是 PR 的差異)。
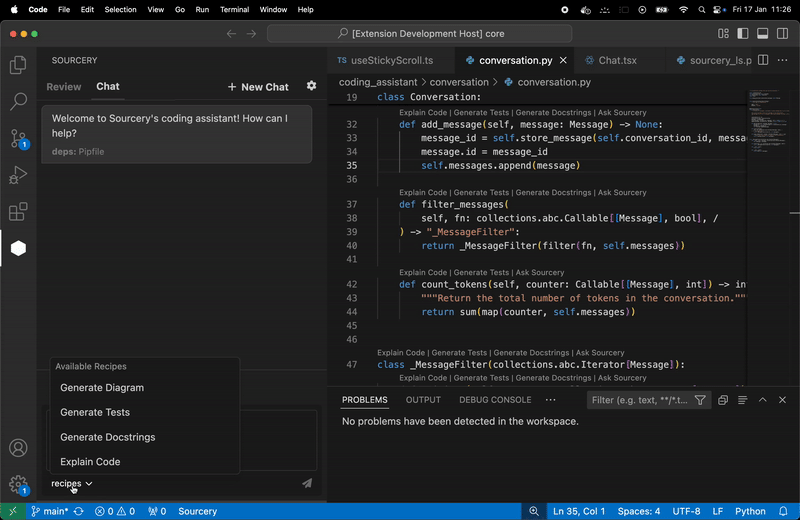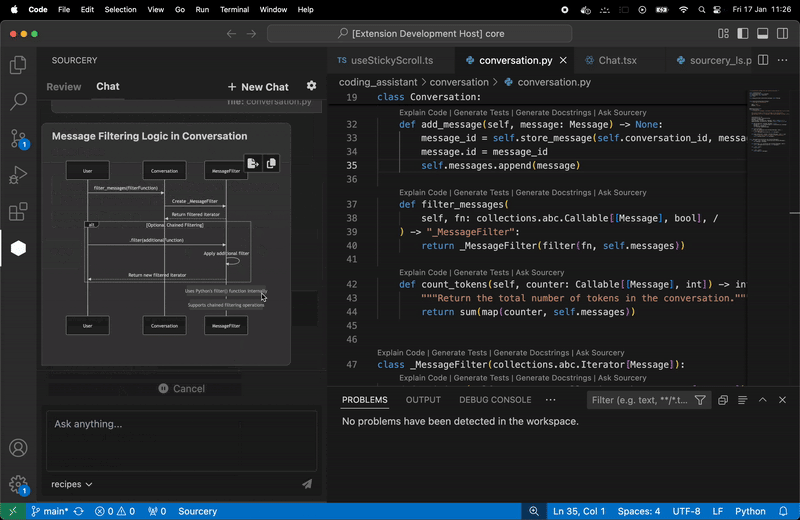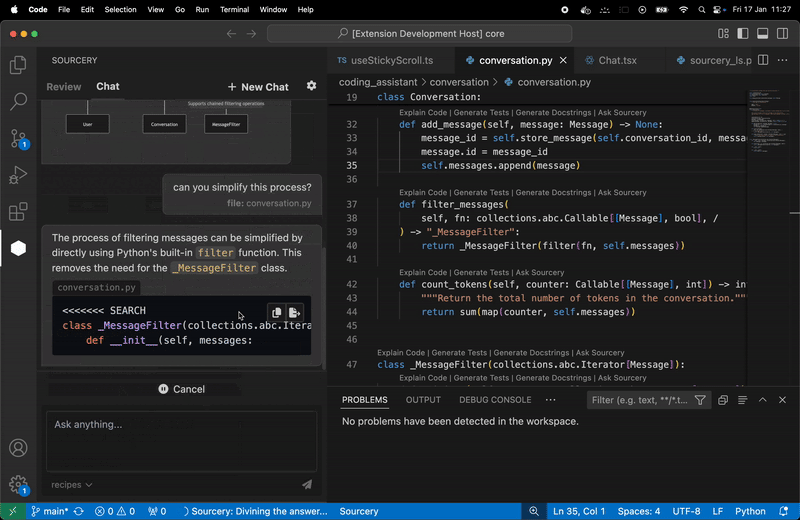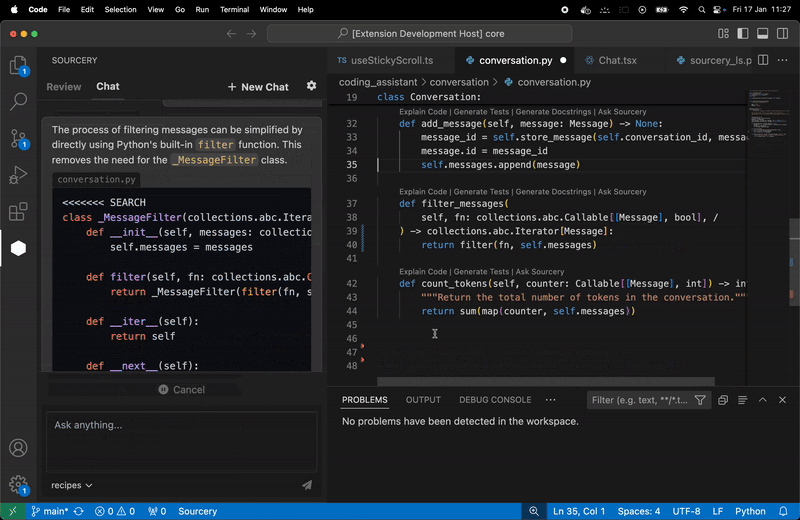
**Real-time refactoring suggestions**
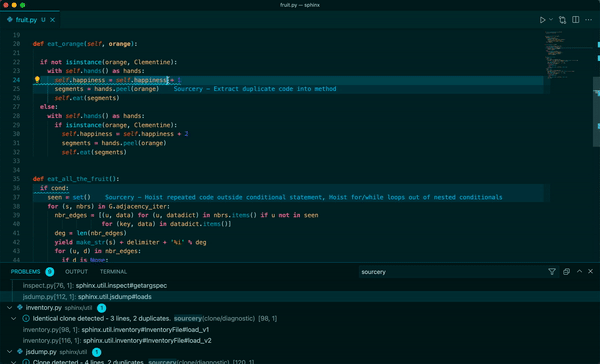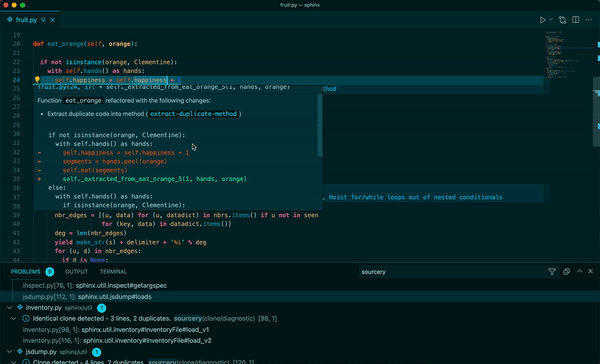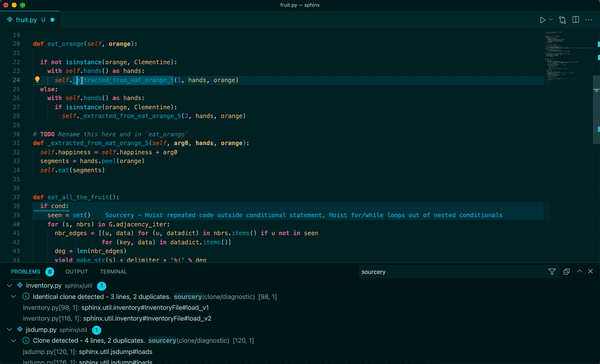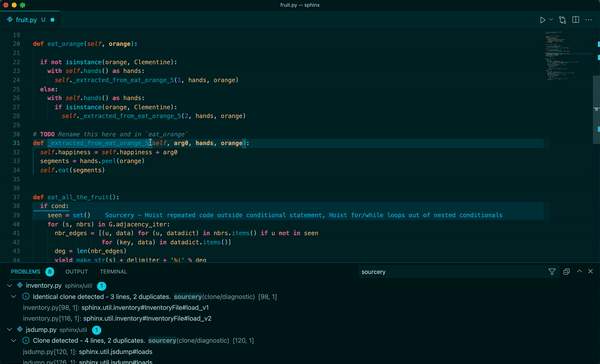
**Continuous code quality feedback**
# Chapter 6 時間緊迫,但必須修改
## 6.2 新生方法 (Sprout Method)
- 簡單來說就是用 function 取代原本寫在 code 裡面的判斷,以防止新添加的與原有的老程式碼之間,並沒有任何分界。
- 以下是將 ==日期發送== 跟 ==重複項目檢查== 混在一起的案例:
```python=
# 只有日期發送
class TransactionGate:
def postEntries(self, entries):
for entry in entries:
entry.postDate()
transactionBundle.getListManager().add(entries)
...
```
```python=
from collections import deque
class TransactionGate:
def postEntries(self, entries):
entriesToAdd = deque()
for entry in entries:
# 把判斷重複部分也寫進來了
if not transactionBundle.getListManager().hasEntry(entry):
entry.postDate()
entriesToAdd.append(entry)
transactionBundle.getListManager().add(entries)
...
```
- 這邊件事把移除重複項目視為一個完全獨立的操作,類似測試驅動開發法建立一個新的 function `uniqueEntries`:
```python=
class TransactionGate:
def uniqueEntries(self, entries):
result = []
for entry in entries:
if not transactionBundle.getListManager().hasEntry(entry):
result.append(entry)
return result
...
```
再來原本的程式碼就只要呼叫他就好:
```python=
class TransactionGate:
...
def postEntries(self, entries):
entriesToAdd = self.uniqueEntries(entries) # 呼叫判斷 function
for entry in entries:
entry.postDate()
transactionBundle.getListManager().add(entriesToAdd)
```
- Sprout Method 步驟如下:
1. 確定修改點。
2. 如果你的修改可以在一個方法中的某一處,以單一連續序列語句出現,那麼在修改點插入一個方法呼叫,而被呼叫的就是我們下面要編寫的、用於完成有關工作的新方法,作者習慣先把這個呼叫先註解掉。
3. 確定你需要原方法中的哪些局部變數,並將它們做為參數傳給新方法呼叫。
4. 確定新訪法是否需要返回什麼值給原方法,如果需要的話就得相應修改對他的呼叫,使用一個變數來接收其返回值。
5. 使用測試驅動的開發方法來開發新的方法。
6. 使原方法中被註解掉的呼叫重新生效。
### 6.1.1 優點和缺點
- 缺點:
- 使用它時,效果上等同於暫時放棄了原方法以及他所屬的類別,也就是你暫時不打算將他們置於測試之下和改善他們。
- 程式碼會處於一個很尷尬的狀態,原方法可能包含了大量複雜的程式碼以及一個新生方法,為什麼這點小功能需要放到其他地方。
- 優點:
- 新舊程式碼被清楚地隔開。
- 即使沒辦法將舊程式碼置於測試之下,至少還能關注所要做的變動,並在新舊的程式碼之間建立清晰的介面。
## 6.2 新生類別
下面是新生類別的範例,主要功能是想透過 python 產出 html table 的報表:
```python=
class QuarterlyReportGenerator:
def generate(self):
results = database.queryResults(beginData, endData)
pageText = "<html><head><title>Quarterly Report</title></head><body>\n"
if len(results) != 0:
for result in results:
pageText += "<tr>"
pageText += "<td>" + result.department + "</td>"
pageText += "<td>" + result.manager + "</td>"
pageText += "<td>" + str(result.netProfit // 100) + "</td>"
pageText += "</tr>"
else:
pageText += "<p>No results for this period</p>"
pageText += "</table></body></html>\n"
return pageText
```
如果想要在 table 上面再加一個 header,就可以多寫一個 class:
```python=
class QuarterlyReportTableHeaderProducer:
def makeHeader(self):
return "<tr><td>Department</td><td>Manager</td>" \
"<td>Profit</td><td>Expenses</td></tr>"
```
這樣就可以寫一個公共的介面(父類別),讓這兩個 class 去繼承他:
```python=
class HTMLGenerator(ABC):
@abstractmethod
def generate(self):
pass
class QuarterlyReportTableHeaderGenerator(HTMLGenerator):
def generate(self):
# 实现 QuarterlyReportTableHeaderGenerator 的 generate 方法
pass
class QuarterlyReportGenerator(HTMLGenerator):
def generate(self):
# 实现 QuarterlyReportGenerator 的 generate 方法
pass
```
- 一般有兩種情況會使用 Sprout Class:
1. 所要進行的修改迫使你為某個類別添加一個全新的職責
2. 想要添加的只是一個小小功能,可以把它放到原有的類別,但問題是無法將這個類別放入測試工具,所以只好另寫一個新的類別。
- Sprout Class 技術的步驟如下:
1. 確定修改點。
2. 如果你的修改可以在一個方法中的某一處,以單一連續序列語句出現,那麼在修改點插入一個類別來完成這些工作,並為這個類別取一個恰當的名字。然後在修改點插入程式碼,建立該類別的物件,並呼叫他的方法,然後將剛插入的這幾行程式碼註解掉。
3. 確定你需要原方法中的哪些局部變數,並將它們做為參數傳給新類別的建構子。
4. 確定新生類別是否需要返回什麼值給原方法,如果需要,則在該類別中提供一個相應的方法,並在原方法中插入對他的呼叫來獲得其返回值。
5. 使用測試驅動的開發方法,來開發新類別。
6. 使原方法中被註解掉的呼叫重新生效。
### 6.2.1 優點和缺點
- 優點:
- 讓你在進行侵入性較強的修改時,有更大的自信去繼續進行自己的工作。
- 在 C++ 中有額外的好處,可以不用調整任何已有得標頭檔。
- 缺點:
- 系統中的概念複雜化,使用新生類別會破壞他的抽象化。
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet