# Теормин по ML
<style>
#doc .toc {display: none;}
#doc .toc.in {display: block !important;}
#doc.markdown-body {max-width: 900px;}
#doc.markdown-body ul, #doc.markdown-body ol {padding-left: 20px !important;margin-left: 20px !important;}
.markdown-body h4 {font-size: 1.2em;}
</style>
[TOC]
### 1. Сильный искусственный интеллект; слабый искусственный интеллект; анализ данных.
- **Cильный искусственный интеллект**
предполагает, что есть "универсальная" модель, решающая широкий спектр задач.
- **Слабый искусственный интеллект**
модель хорошо решает узкую, хорошо поставленную задачу.
**Тест Тьюринга** в данном случае очень помогает общему пониманию:
> «Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор».
Сильный интеллект может пройти тест Тьюринга. Слабый -- нет.
- **Анализ данных**
область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности.
### 2. Обучение с учителем; обучение без учителя; частичное обучение; обучение с подкреплением; активное обучение; онлайн обучение.
- **Обучение с учителем** (*Supervised learning*)
Тренировочные данные доступны все сразу и размечены (известны ответы для поставленной задачи).
- Классификация
- Регрессия
- Ранжирование
- Прогнозирование
- **Обучение без учителя** (*Unsupervised learning*)
Тренировочные данные доступны все сразу, но не размечены (ответы для поставленной задачи неизвестны).
- Кластеризация
- Поиск ассоциативных правил
- Выдача рекомендаций
- Уменьшение размерности
- **Обучение с частичным привлечением учителя** (*Semi-supervised learning*)
Тренировочные данные доступны все сразу, но размечено мало, либо малоинформативная часть. Применяется в случаях, когда разметка всех тренировочных данных требует больших затрат времени и ресурсов.
- **Обучение с подкреплением** (*Reinforcement learning*)
Метод машинного обучения, при котором происходит обучение модели, которая не имеет сведений о системе, но имеет возможность производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение, которое, вообще говоря, не сводится к правильному ответу.
- **Активное обучение** (*Active learning*)
Частный случай *обучения с частичным привлечением учителя*, в котором алгоритм интерактивно запрашивает разметку тех данных, информация о которых может повысить точность работы. Основная задача минимизировать количество запросов при максимизации качества работы итоговой модели.
- **Обучение в реальном времени** (*Online learning*)
Тренировочные данные поступают последовательно с течением времени, с каждым шагом улучшая точность работы.
Пример: предсказание курса валют
### 3. Классификация; регрессия; ранжирование; прогнозирование; метод обучения; функция потерь; эмпирический риск; метод минимизации эмпирического риска; гиперпараметры алгоритма.
- **Классификация**
- Бинарная: $Y = \{-1, +1\}$
- Непересекающиеся классы: $Y = \{1,\ \ldots,\ M\}$
- Пересекающиеся классы: $Y = \{0, 1\}^M$
- **Ранжирование**
* $Y$ — конечное (частично) упорядоченное множество
- **Регрессия**
* $Y = \mathbb{R}$ или $Y = \mathbb{R}^m$
- **Прогноз**
это процесс или результат предсказания тех или иных фактов, событий, явлений, величин, которые станут известны лишь в будущем по отношению к моменту времени, в котором создается прогноз. Под прогнозом также иногда понимают модель будущего события, явления и т. п.
- **Прогнозирование**
это процесс (часто основанный на научном исследовании) по расчету прогноза или разработке прогнозной модели.
- **Метод обучения**
отображение $\mu: (X \times Y)^m \to A$, которое по обучающей выборке данных $T^m = \{(x_i, y_i)\}$ строит алгоритм $a \in A$, восстанавливающий неизвестную зависимость ответов от объектов.
- **Функция потерь** $L(a, x)$
величина ошибки алгоритма $a$ на объекте $x$.
Для задачи классификации: $L(a, x) = [a(x) \neq y(x)]$
Для задачи регрессии: $L(a, x) = d(a(x) - y(x))$
Обычно применяется квадратичная функция потерь: $L(a, x) = (a(x) - y(x))^2$
- **Эмпирический риск**
средняя ошибка, мера качества алгоритма $a$ на обучающей выборке $T^m$
$Q(a, T^m) = \frac1{m}\sum\limits_{i = 1}^{m}L(a, x_i)$
- **Метод минимизации эмпирического риска**
заключается в том, чтобы в заданной модели алгоритмов $A = \{a: X \to Y\}$ найти алгоритм, минимизирующий среднюю ошибку на обучающей выборке:
$a = \mathrm{arg}\min\limits_{a \in A} Q(a, T^m)$
Тем самым задача обучения сводится к оптимизации и может быть решена численными методами.
- **Гиперпараметры модели**
это параметры, значения которых задается до начала обучения модели и не изменяется в процессе обучения. У модели может не быть гиперпараметров.
### 4. Переобучение; валидация; кросс-валидация; leave-one-out; регуляризация
- **Переобучение (Overfitting)** — нежелательное явление, при котором вероятность ошибки обученного алгоритма на новых объектах оказывается существенно выше, чем средняя ошибка на обучающей выборке.
- **Валидация**
процедура эмпирического оценивания обобщающей способности алгоритмов, обучаемых по прецедентам.
- **кросс-валидация (cross-validation, CV)**
фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
- **leave-one-out**
Является частным случаем полного скользящего контроля при k=1, соотвественно, N=L. Это, пожалуй, самый распространённый вариант скользящего контроля.
Преимущества LOO в том, что каждый объект ровно один раз участвует в контроле, а длина обучающих подвыборок лишь на единицу меньше длины полной выборки.
Недостатком LOO является большая ресурсоёмкость, так как обучаться приходится L раз. Некоторые методы обучения позволяют достаточно быстро перенастраивать внутренние параметры алгоритма при замене одного обучающего объекта другим. В этих случаях вычисление LOO удаётся заметно ускорить.
- Часто **регуляризация** представляет собой просто некоторую добавку R(w) (где w — параметры модели) к функции потерь L(f(x,w),y) так что задача приобретает вид:
$\min\limits_{w}\sum_{i=1}^NL(f(x_i,w),y_i))+λR(w)$
Часто используемые R(w):
- L2 регуляризация — $R(w)=||w||_2^2=\sum_{i = 1}^d w_i^2$
- L1 регуляризация — $R(w)=||w||_1=\sum_{i = 1}^d |w_i|$
- ElasticNet регуляризация — $R(w)=λ_1||w||_2^2+λ_2||w||_1$
Hадо понимать, что эта добавка нужна, чтобы добавить как-то оцениваемую сложность модели в минимизируемый функционал
### 5. Точность; полнота; accuracy; F-мера; true positive; false positive; ROC-кривая; среднеквадратическое отклонение
- **Accuracy**
$\frac{TP + TN}{TP + TN + FP + FN}$
- **Precision (точность)**
$\frac{TP}{TP+FP}$
- **Recall (полнота)**
$\frac{TP}{TP + FN}$
- **F-мера**
$(1 + \beta^2)\frac{precision*recall}{\beta^2*precision + recall}$
- **True positive**
Правильно выбранные результаты
- **False positive**
Неправильно выбранные результаты
- **ROC-кривая**
Кривая ошибок или ROC-кривая – графичекая характеристика качества бинарного классификатора, зависимость доли верных положительных классификаций от доли ложных положительных классификаций при варьировании порога решающего правила. На графике будет не больше точек, чем объектов в обучающей выборке. По факту строится по числу различающих точки значений порога (то есть если все значения равны, будут ровно две точки). Порог решающего правила в качестве аргумента принимает любым образом выраженную степень уверенности классификатора в ответе.
- **среднеквадратическое отклонение**
<!-- $\frac1{2n}(\vec{y} - X \vec{w})^T (\vec{y} - X \vec{w})$ -->
Корень из дисперсии случайной величины. При отсутствии настоящей дисперcии может считаться как $\sqrt{\frac{1}{n}\sum(x_{среднее}-x_i)^2}$
### 6. Метод ближайших соседей
Простейший метрический классификатор, основанный на оценивании сходства объектов. Для объекта берется k ближайших (по выбранной метрике) соседей. Среди соседей берут максимальную по включению метку класса. Эта метка и будет классом объекта.
Иначе говоря:
$a(u, T^l) = \mathrm{arg}\max\limits_{y \in Y}\sum_{i=1}^k [y_{i} = y]$, где $y_{i}$ отсортированы по расстоянию $x_{i}$ от u.
### 7. Метод непараметрической регрессии
**Задача восстановления регрессии**
Пространство объектов $X$, множество возможных ответов - $Y$. Существует неизвестная целевая зависимость $y^* : X \rightarrow Y$, значения которой известны на объектах обучающей выборки. Требуется построить алгоритм $a : X \rightarrow Y$, аппроксимирующий $y^*$.
**Непараметрическая регрессия**
Значение $a(x)$ вычисляется для каждого объекта $x$ по нескольким ближайшим к нему объектам обучающей выборки (на $X$ должна быть задана функция расстояния $\rho(x,x')$). Минимизируем следующую функцию:
$$Q(\alpha;X^l)=\sum_{i=1}^l w_i(x)(\alpha - y_i)^2 \rightarrow \min_{\alpha \in \mathbb{R}}$$
Зададим веса так, чтобы они убывали по мере увеличения расстояния от $x$. Для этого используем ядро - невозрастающую, гладкую, ограниченную функцию $K : [0,\infty) \rightarrow [0, \infty)$.
$$w_i(x)=K\left(\frac{\rho(x, x_i)}{h}\right)$$
**Формула Надарая-Ватсона**
Если приравнять нулю $\frac{\partial Q}{\partial \alpha}$, получается формула:
$$\alpha_h(x;X^l)=\frac{\sum_{i=1}^l y_i w_i(x)}{\sum_{i=1}^l w_i(x)} = \frac{\sum_{i=1}^l y_i K\left(\frac{\rho(x, x_i)}{h}\right)}{\sum_{i=1}^l K\left(\frac{\rho(x, x_i)}{h}\right)}$$
### 8. Метод стохастического градиентного спуска
Стохастический градиентный спуск относится к оптимизационным алгоритмам и нередко используется для настройки параметров модели машинного обучения.
При стандартном (или «пакетном», «batch») градиентном спуске для корректировки параметров модели используется градиент. Градиент обычно считается как сумма градиентов, вызванных каждым элементом обучения. Вектор параметров изменяется в направлении антиградиента с заданным шагом. Поэтому стандартному градиентному спуску требуется один проход по обучающим данным до того, как он сможет менять параметры.
При стохастическом (или «оперативном») градиентном спуске значение градиента аппроксимируются градиентом функции стоимости, вычисленном только на одном элементе обучения. Затем параметры изменяются пропорционально приближенному градиенту. Таким образом параметры модели изменяются после каждого объекта обучения. Для больших массивов данных стохастический градиентный спуск может дать значительное преимущество в скорости по сравнению со стандартным градиентным спуском.
Между этими двумя видами градиентного спуска существует компромисс, называемый иногда «mini-batch». В этом случае градиент аппроксимируется суммой для небольшого количества обучающих образцов.
Стохастический градиентный спуск является одной из форм стохастического приближения. Теория стохастических приближений даёт условия сходимости метода стохастического градиентного спуска.
Одними из самых популярных алгоритмов стохастического градиентного спуска являются адаптивный фильтр наименьшей среднеквадратичной ошибки и алгоритм обратного распространения ошибок.
### 9. Метод линейной регрессии; гребневая регрессия; лассо Тибширани
**Линейная регрессия** — метод восстановления зависимости между двумя переменными.
Для заданного множества из m пар $(x_i, y_i)_{i=1\ldots m}$, значений свободной и зависимой переменной требуется построить зависимость. Назначена линейная модель
$y_i= f(\mathbf{w},x_i) + \varepsilon_i$
---
Ридж-регрессия или **гребневая регрессия** (англ. ridge regression) - это один из методов понижения размерности. Часто его применяют для борьбы с переизбыточностью данных, когда независимые переменные коррелируют друг с другом (т.е. имеет место мультиколлинеарность). Следствием этого является плохая обусловленность матрицы $X^T X$ и неустойчивость оценок коэффициентов регрессии. Оценки, например, могут иметь неправильный знак или значения, которые намного превосходят те, которые приемлемы из физических или практических соображений.
Применение гребневой регрессии нередко оправдывают тем, что это практический приём, с помощью которого при желании можно получить меньшее значение среднего квадрата ошибки.
Метод стоит использовать, если:
- сильная обусловленность;
- сильно различаются собственные значения или некоторые из них близки к нулю;
- в матрице X есть почти линейно зависимые столбцы.
---
**Лассо-регрессия** (*Лассо Тибширани*) метод понижения размерности, минимизирует RSS при условии, что сумма абсолютных значений коэффициентов меньше константы. Из-за природы этих ограничений некоторые коэффициенты получаются равными нулю.
Постановка задачи:
$||y-X\theta ||^2+\tau\sum_{j=1}^{k}|\theta_j|\to \min_{\theta}$
Переформулируем её в таком виде.
\begin{cases}||y-X\theta||^2\to\min_{\theta},\\ \sum_{j=1}^{k}|\theta_j|< \varkappa \end{cases}
Если уменьшается $\varkappa$, то устойчивость увеличивается и количество ненулевых коэффициентов уменьшается, т.е. происходит отбор признаков.
### 10. Метод сингулярного векторного разложения
Произвольная матрица $l\times n$ представима в виде сингулярного разложения (singular value decomposition, SVD):
\begin{align*}
F = VDU^T
\end{align*}
Основные свойства:
* $l\times n$-матрица $V = (v_1, \ldots, v_n)$ ортогональна, $V^TV=I_n$, столбцы $v_j$ -- собственные векторы $FF^T$;
* $n\times n$-матрица $U = (u_1,\ldots,u_n)$ ортогональна, $U^TU = I_n$, стобцы $u_j$ -- собственные векторы $F^TF$;
* $n\times n$-матрица $D$ диагональна, $D = diag(\sqrt{\lambda_1},\ldots,\sqrt{\lambda_n})$, $\lambda_j \geqslant 0$ -- собственные значения матриц $F^TF$ и $FF^T$.
$\sqrt{\lambda_j}$ -- сингулярные числа матрицы $F$.
Имея сингулярное разложение, можно выписать решение задачи наименьших квадратов в явном виде, не прибегая к трудоёмкому обращению матриц:
$F^+=(UDV^тVDU^т)^{−1}UDV^т=(DU^т)^{−1}(UD)^{−1}(UD)V^т=UD^{−1}V^т$. Обращение диагональной матрицы тривиально: $D^{−1}= diag(1/√λ_1,\ldots,1/√λ_n)$. Теперь легко выписать вектор МНК-решения: $α∗=F^+y=U D^{−1}V^Ty$, и МНК-аппроксимацию целевого вектора $y$:
\begin{align*}
Fα^∗=P_Fy=(VDU^т)UD^{−1}V^тy=V V^тy= \sum_{j=1}^n v_j(v_j^тy)
\end{align*} Эта формула означает, что МНК-аппроксимация $Fα^∗$ есть проекция целевого вектора $y$ на линейную оболочку собственных векторов матрицы $FF^т$.
### 11. Метод опорных векторов (общая идея)
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора. Штрафуются объекты, попавшие между гиперплоскостями или оказавшиеся не со "своей" стороны от гиперплоскости. Они и называются опорными, и расстояние именно до них в итоге используется для классификации новых объектов.
### 12. Ядро; ядерный трюк для метода опорных векторов
Суть в том, что у нас в нашем исходном пространстве мы не всегда сможем разделить наши объекты линией. И поэтому давайте перейдем в пространство выше размерностью, где мы сможем разделить объекты гиперплоскостью.
Пусть X – некоторое пространство. Тогда отображение $K:\ X \times X \to \mathbb R$ называется ядром или kernel function, если оно представимо в виде:
$K \left(x,x^{\prime} \right) = \left< \psi(x), \psi (x^{\prime}) \right>_H , где\ \psi\ –\ некоторое\ отображение\ \psi:\ X \to H$
### 13. Вероятностная постановка задачи классификации; правдоподобие класса; метод максимальной апостериорной вероятности; оптимальный байесовский классификатор
Пусть $X$ — множество объектов, $Y$ — конечное множество классов, $X \times Y$ - вероятностное пространство с плотностью распределения $p(x, y) = P(y)p(x|y)$.
$P_y = P(y)$ - *априорные* вероятности класса. Плотности распределения $p_y(x) = p(x|y)$ - *функции правдоподобия* классов.
**Вероятностная постановка задачи классификации:**
1. По простой выборке $X^l = (x_i, y_i)_{i = 1}^l$ из неизвестного распределения $p(x, y) = P_yp_y(x)$ оценить $P_y$ и $p_y(x)$ для каждого из классов $y ∈ Y$.
2. По известным $p_y(x)$ и $P_y$ всех классов $y ∈ Y$ построить алгоритм $a(x)$, минимизирующий вероятность ошибочной классификации.
**Функционал среднего риска**
$A_s = \{x ∈ X | a(x) = s\}$
$λ_{ys}$ - величина потери при отнесении объекта класса $y$ к классу $s$.
$P_yP(A_s|y)$ - вероятность того, что появится объект класса $y$ и алгоритм $a$ отнесёт его к классу $s$.
$R(a) = \sum\nolimits_{y ∈ Y}\sum\nolimits_{s ∈ Y}λ_{ys}P_yP(A_s|y)$ - функционал среднего риска
**Оптимальный байесовский классификатор**
Если известны априорные вероятности $P_y$ и функции правдоподобия $p_y(x)$, то минимум среднего риска $R(a)$ достигается алгоритмом:
$a(x) = \mathrm{arg}\min\limits_{s \in Y} \sum\nolimits_{y ∈ Y}λ_{ys}P_yp_y(x)$.
Или, если величина потери при неправильной классификации const $λ_{ys} = λ_{y}$ и $λ_{yy} = 0$, то средний риск совпадает с вероятностью ошибки и
$a(x) = \mathrm{arg}\max\limits_{y \in Y} λ_{y}P_yp_y(x)$ - *байесовское решающее правило*
**Метод максимальной апостериорной вероятности**
$P(y|x) = \frac{p(x,y)}{p(x)} = \frac{P_yp_y(x)}{\sum\nolimits_{s ∈ Y}p_s(x)P_s}$ - *апостериорная вероятность* класса $y$ для объекта $x$
Перепишем оптимальный байесовский классификатор через апостериорные вероятности:
$a(x) = \mathrm{arg}\max\limits_{y \in Y} λ_{y}P(y|x)$ - принцип максимума апостериорной вероятности.
### 14. Метод оценки Парзена-Розенблатта; наивный байесовский классификатор
Метод Парзена-Розенблатта - это способ оценки плотности случайной величины.
Пусть $(x_1, x_2, \dots, x_n)$ является одномерной выборкой независимых одинаково распределённых величин, извлечённых из некоторого распределения с неизвестной плотностью $ƒ$. Наша задача заключается в оценке формы функции $ƒ$. Её ядерный оценщик плотности равен: $\hat{f}_h(x)=\frac{1}{n}\sum_{i=1}^n K_h (x - x_i)=\frac{1}{nh} \sum_{i=1}^n K\Big(\frac{x-x_i}{h}\Big),$
где $K$ является ядром, т.е. неотрицательной функцией, а $h>0$ является сглаживающим параметром, называемым шириной полосы. Ядро с индексом h называется взвешенным ядром и определяется как $K_h(x)=\frac{1}{h} K(\frac{x}{h})$. Интуитивно стараются выбрать h как можно меньше, насколько данные это позволяют.
###### Выбор h
**h** стремится к нулю - плотность концентрируется вблизи точек выборки. h стремится в бесконечность - вырождение в константу.
Базовая стратегия выбора **h**: чем более плотное распределение объектов, тем меньше должно быть **h**.
**Пример:** $h=\frac{1}{N}*\sum_{i=1}^Nd_{ik}$ - здесь $d_{ik}$ это расстояние от $x_i$ до К-того ближайшего соседа (К можно выбрать методами кросс-валидации)
---
**Наи́вный ба́йесовский классифика́тор** — простой вероятностный классификатор, основанный на применении теоремы Байеса со строгими (наивными) предположениями о независимости.
В зависимости от точной природы вероятностной модели, наивные байесовские классификаторы могут обучаться очень эффективно. Во многих практических приложениях для оценки параметров для наивных байесовых моделей используют метод максимального правдоподобия; другими словами, можно работать с наивной байесовской моделью, не веря в байесовскую вероятность и не используя байесовские методы.
> [name=Andrey Filchenkov]
> Тут очень неплохо понимать, что предполагается условная независимость между признаками при известном классе, то есть большую плотность вероятности можно расписать как произведение плотностей по каждому из признаков.
### 15. Задача параметрической оценки плотности; принцип максимального правдоподобия
В параметрическом подходе предполагается, что плотность распределения выборки $X_m = \{x_1,\ldots, x_m\}$ известна с точностью до параметра, $p(x) = ϕ(x, θ)$, где $ϕ$ — фиксированная функция. Вектор параметров $θ$ оценивается по выборке $X_m$ с помощью *принципа максимума правдоподобия*.
**Принцип максимума правдоподобия**
Пусть задано множество объектов $X_m = \{x_1,\ldots, x_m\}$, выбранных независимо друг от друга из вероятностного распределения с плотностью $ϕ(x, θ)$. *Функцией правдоподобия* называется совместная плотность распределения всех объектов выборки:
$p(X_m; θ) = p(x_1,\ldots, x_m; θ) = \prod\limits_{i = 1}^{m}ϕ(x_i, θ)$.
Значение параметра $θ$, при котором выборка максимально правдоподобна,
то есть функция $p(X_m, θ)$ принимает максимальное значение, называется *оценкой максимума правдоподобия*.
### 16. Метод логистической регрессии; сигмоида
https://www.coursera.org/lecture/vvedenie-mashinnoe-obuchenie/loghistichieskaia-rieghriessiia-8G3Xu
**Логистическая регрессия** применяется для прогнозирования вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная ${\displaystyle y}$ принимающая лишь одно из двух значений — как правило, это числа 0 (событие не произошло) и 1 (событие произошло), и множество независимых переменных (также называемых признаками, предикторами или регрессорами) — вещественных ${\displaystyle x_{1},x_{2},\ldots,x_{n}}$, на основе значений которых требуется вычислить вероятность принятия того или иного значения зависимой переменной. Как и в случае линейной регрессии, для простоты записи вводится фиктивный признак $x_{0}=1$.



**Сигмо́ида** — это гладкая монотонная возрастающая нелинейная функция, имеющая форму буквы «S», которая часто применяется для «сглаживания» значений некоторой величины.
Часто под сигмоидой понимают логистическую функцию
$σ(x) = \frac {1}{1+e^{-x}}$
### 17. Понятие (concept), правильно (rule)
**Понятие** - произвольный предикат на множестве объектов $X$:
$φ:𝑋 → \{0,1\}$.
Говорят, что понятие **покрывает** объект $x$, если $φ(x) = 1$.
**Правило** - логический предикат, который, во-первых, покрывает много объектов из одного класса и мало объектов из других, во-вторых, легко может быть объяснён (interpreted).
Понятие **может быть объяснено (can be interpreted)**, если
1) Оно сформулировано естественным языком;
2) Зависит от малого количества признаков (1-7).
Понятие $φ$ **информативно** для класса $c$, если
$p(φ) = |\{x_i|φ(x_i) = 1, y_i = c\}| \rightarrow max$;
$n(φ) = |\{x_i|φ(x_i) = 1, y_i \neq c\}| \rightarrow min$.
Можно переформулировать:
$p(φ)$ - True Positive;
$n(φ)$ - False Positive;
$p(φ) + n(φ)$ - coverage.
### 18. Дерево принятия решений; подрезка
**Дерево принятия решений** -- логический алгоритм классификации. В роли вершин функция перехода. Например, фича и условное значение, определяющее, в какого ребенка следует пойти далее. В листьях записан ожидаемый класс объекта.
**Подрезка** (*pruning*) -- дерево принятия решений строится целиком, а затем запускается процесс объединения листов. Класс определяется по принципу максимума в поддереве. Объединяются вершины в случае, если их объединение улучшает точность распознавания на контрольной выборке. Помогает избежать переобучения.
### 19. Бустинг алгоритмов; метод градиентного бустинга
**Бустинг** (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов. Бустинг представляет собой жадный алгоритм построения композиции алгоритмов
----
http://www.machinelearning.ru/wiki/index.php?title=AnyBoost
**Алгоритм AnyBoost** - класс алгоритмов, представляющих бустинг как процесс градиентного спуска. В основе алгоритма лежит последовательное уточнение функции, представляющей собой линейную комбинацию базовых классификаторов, с тем чтобы минимизировать функцию потерь. В класс AnyBoost входят практически все алгоритмы бустинга как частные случаи.
### 20. Метод AdaBoost
http://neerc.ifmo.ru/wiki/index.php?title=%D0%91%D1%83%D1%81%D1%82%D0%B8%D0%BD%D0%B3,_AdaBoost
Алгоритм усиливает классификаторы, объединяя их в «комитет». AdaBoost является адаптивным в том смысле, что каждый следующий комитет классификаторов строится по объектам, неверно классифицированным предыдущими комитетами. AdaBoost чувствителен к шуму в данных и выбросам. Однако он менее подвержен переобучению по сравнению с другими алгоритмами машинного обучения.
AdaBoost вызывает слабые классификаторы в цикле ${\displaystyle t=1,\ldots ,T}$. После каждого вызова обновляется распределение весов ${\displaystyle D_{t}}$, которые отвечают важности каждого из объектов обучающего множества для классификации. На каждой итерации веса каждого неверно классифицированного объекта возрастают, таким образом новый комитет классификаторов «фокусирует своё внимание» на этих объектах.
### 21. Бустрап; случайный лес; стэкинг
https://dyakonov.org/2017/03/10/c%D1%82%D0%B5%D0%BA%D0%B8%D0%BD%D0%B3-stacking-%D0%B8-%D0%B1%D0%BB%D0%B5%D0%BD%D0%B4%D0%B8%D0%BD%D0%B3-blending/#more-4558
**Бутстрап** -- выбор подмножества с возвратом объектов. На первом шаге построения случайного леса используется бутстрап. Бэггинг — это построение деревьев бустрапом и random subspace методом. На втором шаге фичи выбираются каждый раз независимо.
**Бэггинг** (от англ. ***B**ootstrap* **agg**regat**ing**) – технология классификации, где в отличие от бустинга все элементарные классификаторы обучаются и работают параллельно (независимо друг от друга). Идея заключается в том, что классификаторы не исправляют ошибки друг друга, а компенсируют их при голосовании. Базовые классификаторы должны быть независимыми, это могут быть классификаторы основанные на разных группах методов или же обученные на случайных подвыборках данных. Во втором случае можно использовать один и тот же метод классификации.
**Random subspace** – обучение классификаторов на случайных подмножествах признаков и объединение аналогично бэггингу.
**Случайный лес.** Имеется обучающая выборка $T^l = \{x_i,y_i\}^l_{i=1}$ размерность пространства признаков равна $n$.
1) Сгенерируем случайную подвыборку с повторениями размером $l$ методом бэггинга.
2) Построим для неё решающее дерево, для каждой вершины выберем $n'$ (обычно $n' = \sqrt{n}$) случайных признаков.
3) Дерево строится до полного исчерпания подвыборки и не подвергается отсечению ветвей.
Процедуру можно выполнить любое количество раз.
Классификация объектов проводится путём голосования: каждое дерево комитета относит классифицируемый объект к одному из классов, и побеждает класс, за который проголосовало наибольшее число деревьев.
Оптимальное число деревьев подбирается таким образом, чтобы минимизировать ошибку классификатора на тестовой выборке. В случае её отсутствия минимизируется оценка ошибки тех образцов, которые не попали в обучающую подвыборку за счёт повторений.
**Стэкинг.** Вместо комбинирования алгоритмов их предсказания используются как новые признаки для обучения модели. Эта идея может быть обобщена до использования результатов классификации в качестве новых признаков объектов.
http://www.levvu.narod.ru/Machine_Learning_LTU_7.pdf
### 22. Нейрон; перцептрон.
https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D1%86%D0%B5%D0%BF%D1%82%D1%80%D0%BE%D0%BD
Перцептрон Розенблатта:
$$a_w(x,T^l)=\sigma(\sum_{i=1}^n w_ix^i-w_0)$$
Обобщенный нейрон Маккалока-Питтса:
$$a_w(x,T^l)=\sigma(\sum_{i=1}^n w_i x^i-w_0)$$
### 23. Многослойная нейронная сеть; метод обратного распространения ошибок
Один слой в нейронных сетях - это мало, невозможно даже реализовать xor.
Однако для обучения нейронных сетей, нам необходимо как-то менять веса на всех слоях. Делаем это при помощи градиентного спуска. Возникает вопрос, как считать градиент нашей функции потерь от веса на каком-то произвольном слое. Решение очень простое - давайте идти с конца.
Пусть:
$H$ - количество слоев
$K$ - количество нейронов на слое (не умаляя общности оно везде одинаковое)
$u_i^k$ - выход из i-го нейрона k-слоя
$a_i=u_i^K$ - выходы выходного слоя
$x_i=u_i^0$ - входы
Замена выходов и входов на u нужна просто для удобства
$w_{i,j}^k$ - веса из i-го нейрона k-слоя в j-й нейрон k-слоя
$\frac{\partial L}{\partial w_{i,j}^k}$ - надо найти
Для начала найдем частные производные по выходам $u_i^k$
Пусть $eps_i^k = \frac{\partial L}{\partial u_i^k}$ - назовем это ошибкой на слое k
Выведем рекурентную формулу:
Так как $u_i^{k + 1} = \sigma(\sum_{l=1}^H u_l^k * w_{l,i}^k)$
$$\epsilon_i^k = \frac{\partial L}{\partial u_i^k} = \sum_{j = 1}^H \frac{\partial L}{\partial u_j^{k + 1}} * \frac{\partial u_j^{k + 1}}{\partial u_i^k} = \sum_{j = 1}^H \epsilon_i^{k + 1} * \sigma'(.) * w_{i,j}^k$$
Базу рекурсии возьмем за последний шаг:
$$\frac{\partial L}{\partial a_{i}^{k}} = \epsilon_{i}^K$$
Что считается в зависимости от конкретной функции потерь
Как теперь найти конкретную $\frac{\partial L}{\partial w_{i,j}^k}$?
$$\frac{\partial L}{\partial w_{i,j}^k} = \frac{\partial L}{\partial u_{j}^k} * \frac{\partial u_{j}^k}{\partial w_{i,j}^k} = \epsilon_j^k * u_i^{k - 1} * \sigma'(.) $$
Итого мы спокойно можем использовать градиентный спуск. Итак, алгоритм **backProp** - инициализируем веса, идем вперед по нашей сети, далее идем назад и считаем ошибки. По этим данным находим градиент от весов и пересчитываем веса. Так пока не сойдемся.
Имеет все недостатки градиентного спуска.
### 24. --
### 25. Аугментация данных; дропаут; ReLU
**Аугментация данных** - метод предотвращения переобучения. Искуственно увеличиваем датасет используя любые преобразования к имеющимся данным, не меняющие класс объекта.
**Дропаут** - метод регуляризации нейронной сети для предотвращения переобучения.
Этап обучения: отключаем нейрон на слое $k$ с вероятностью $p_k$ $u_i^{k + 1} = \epsilon^k \sigma(\sum_{l=1}^H u_l^k * w_{l,i}^k)$, где $\epsilon^k = 0$ с вероятностью $p_k$
Этап применения: включаем все нейроны, но с поправкой $u_i^{k + 1} = (1 - p_k) \sigma(\sum_{l=1}^H u_l^k * w_{l,i}^k)$
Нейроны перестают подстраиваться под компенсацию ошибок друг друга -> сокращаем переобучение
**ReLU** - самая популярная функция активации $a = max(0, x)$, намного быстрее считать ее и ее градиент \begin{equation} \frac{\partial a}{\partial x}=\begin{cases}1, & \text{if $x>0$}.\\ 0, & \text{otherwise}. \end{cases} \end{equation}
### 26. Метод Ньютона-Рафсона; метод Ньютона-Гаусса
http://www.machinelearning.ru/wiki/images/6/6d/Voron-ML-1.pdf
##### **Метод Ньютона-Рафсона**
**Что?** Есть функция действительного переменного $f(x)$. Требуется найти корни уравнения $f(x) = 0$
**Как?** Улучшение метода Ньютона. Основное отличие заключается в том, что на очередной итерации каким-либо из методов одномерной оптимизации выбирается оптимальный шаг: $\vec{x}^{[j+1]}=\vec{x}^{[j]}-\lambda_j H^{-1}(\vec{x}^{[j]})\nabla f(\vec{x}^{[j]})$
где $\lambda_j=\arg\min_\lambda f(\vec{x}^{[j]}-\lambda H^{-1}(\vec{x}^{[j]})\nabla f(\vec{x}^{[j]}))$
где H - Гессиан = $H(x) = \sum_{i=1}^n \sum_{j=1}^n a_{ij} x_i x_j$, где $a_{ij}=\partial^2 f/\partial x_i \partial x_j$
> **Рофл** В слайдах предлагается вместо вычисления лямбды использовать шаг пруф: https://i.imgur.com/wxt5VDu.png
##### **Метод Ньютона-Гаусса**
Главная идея это линеризация.
$$f(x_i,w) \approx f(x_i,w^{(t)}) + \sum_{j=1}^p (w_j - w_j^{(t)})\frac{\partial f(x_j,w_j^{(t)})}{\partial w_j} + o(w_j - w_j^{(t)})$$
$$w^{(t+1)}=w^{(t)} - h_t(F_t^TF_t)^{-1}F_t(f^{(t)}-y)$$
где $F_t=F_t=(\frac {\partial {f_i}}{\partial \Theta_j}(x_j,w^{(t)}))^{j=1..p}_{j=1..l}$ - матрица первых производных
$f_t=(f(x_j,w{(t)}))_{i=1..l}$ - вектор значений f
Заменяем $\beta = (F_t^TF_t)^-1F_t(f^{(t)}-y)$ которая является решение задачи $$||F_t\beta - (f^{(t)} - y)||^2 \rightarrow min_{\beta}$$
Что является задачами линейной регрессии.
### 27. Декорреляция; метод Xavier; метод He
https://logic.pdmi.ras.ru/~sergey/teaching/dl2017/DLNikolenko-Beeline-03.pdf
**Метод инициализации Завьера (Xavier)** (иногда — метод Glorot’а). Основная идея этого метода — упростить прохождение сигнала через слой во время как прямого, так и обратного распространения ошибки для линейной функции активации (этот метод также хорошо работает для сигмоидной функции, так как участок, где она ненасыщена, также имеет линейный характер). При вычислении весов этот метод опирается на вероятностное распределение (равномерное или нормальное) с дисперсией, равной $\mathrm{Var}(W) = {2 \over{n_{in} + n_{out}}}$, где $n_{in}$ и $n_{out}$ — количества нейронов в предыдущем и последующем слоях соответственно. Это уменьшает изменение дисперсии при переходе к следующему слою.
**Метод инициализации Ге (He)** — это вариация метода Завьера, больше подходящая функции активации ReLU, компенсирующая тот факт, что эта функция возвращает нуль для половины области определения. А именно, в этом случае $\mathrm{Var}(W) = {2 \over{n_{in}}}$
> [name=Andrey ]
> Тут не хватает, собственно, указания того, что это метод инициализации весов в сетке, при котором ожидается, что их средние будут в нуле, а дисперсии равны.
### 28. --
### 29. --
### 30. Метод Adam
http://mechanoid.kiev.ua/neural-net-backprop2.html
https://blog.paperspace.com/intro-to-optimization-momentum-rmsprop-adam/
> Надо сказать про скользящее усреднение покоординатных градиентов и квадратов градиентов с последующей поправкой.
Сама по себе идея методов с накоплением импульса до очевидности проста: «Если мы некоторое время движемся в определённом направлении, то, вероятно, нам следует туда двигаться некоторое время и в будущем». Для этого нужно уметь обращаться к недавней истории изменений каждого параметра.
Если задать нулевое начальное значение, то они будут долго накапливаться, особенно при большом окне накопления , а какие-то изначальные значения — это ещё два гиперпараметра. Никто не хочет ещё два гиперпараметра, так что мы искусственно увеличиваем m_t и v_t на первых шагах
### 31. Метод батчевой нормализации
https://towardsdatascience.com/batch-normalization-theory-and-how-to-use-it-with-tensorflow-1892ca0173ad
https://www.youtube.com/watch?v=BZh1ltr5Rkg
Обычно в нейронных сетях нормализуют входные данные, но в скрытых слоях вход может быть разбалансирован. Сделаем балансировку для входа скрытых слоёв и назовём это **батчевой нормализацией**. Это будет отдельный слой сети, который добавляется до или после функции активации.
1. Посчитать среднее значение и дисперсию входных данных внутреннего слоя. 
2. Нормализация входных данных слоя, используя прошлую подсчитанную батчевую статистику.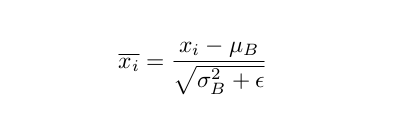
3. Масштаб и сдвиг для результата слоя. Параметры β и γ изменяются во время обучения сети.

Итак, если в каждом батче содержится m элементов, тогда каждые j батчей: 
### 32. Свертка; паддинг; пулинг; страйд; тензор
**Свертка** - линейное преобразование
$x$ - исходные признаки, матрица $n \times m$
$w$ - ядро свертки, матрица $(2A+1) \times (2B+1)$.
Итог - матрица размера $(n-A) \times (m-b)$
$(x * w)[i,j] = \sum_{a=-A}^A \sum_{b=-B}^B w[a, b]x[i+a, j+b]$

**Паддинг** - искуственно увеличиваем размерность матрицы, добавляя края (обычно нулевые). Потому что хотим чтобы при свертке выходной размер равнялся входному и краевые пиксели тоже умножались на центр ядра
**Пулинг** - преобразование, уменьшающее размерность матрицы. Ужимаем непересекающиеся прямоугольники в один пиксель, применяя к ним нелинейные преобразования (обычно максимум). Перебираем прямоугольники с шагом страйда.
**Страйд** - шаг свертки, сдвиг применения ядра (обычно 1).
**Тензор** - кажется, имеется ввиду тензор матрицы свертки.
>Те́нзор (от лат. tensus, «напряженный») — объект линейной алгебры, линейно преобразующий элементы одного линейного пространства в элементы другого. Частными случаями тензоров являются скаляры, векторы, билинейные формы и т. п.
### 33. Сверточная нейронная сеть
https://github.com/vdumoulin/conv_arithmetic
> Тут нужно хотя бы немного понимать про то, что изображение представляется не матрицей, а тензором размерности три (добавляются каналы, например, цвета); тензором же являются и группы сверток, правда, уже размерности 4.
**Cвёрточная нейронная сеть** (англ. convolutional neural network, CNN) — специальная архитектура искусственных нейронных сетей, нацеленная на эффективное распознавание изображений, входит в состав технологий глубокого обучения (англ. deep learning). Использует некоторые особенности зрительной коры, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея свёрточных нейронных сетей заключается в чередовании свёрточных слоёв (англ. convolution layers) и субдискретизирующих слоёв (англ. subsampling layers или англ. pooling layers, слоёв подвыборки). Структура сети — однонаправленная (без обратных связей), принципиально многослойная. Для обучения используются стандартные методы, чаще всего метод обратного распространения ошибки. Функция активации нейронов (передаточная функция) — любая, по выбору исследователя.
Название архитектура сети получила из-за наличия операции свёртки, суть которой в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения.
### 34. Задача семантической сегментации; задача детекции объектов
**Семантическая сегментация** — разделение изображения на отдельные группы пикселей, области, соответствующие одному объекту с одновременным определением типа объекта в каждой области.
**Детекция объектов** — определение местоположения объектов искомых типов на изображении (обычно, прямоугольная граница, в которой находится объект).
### 35. Рекуррентная нейронная сеть
> Не уверен, что из этого определения можно понять, что в РНН связи от нейронов идут не только в нейроны следующего слоя, но могут идти в себя, в предыдущие слои и т.д., образуя циклы.
**Рекуррентные нейронные сети** (РНС, англ. Recurrent neural network; RNN) — вид нейронных сетей, где связи между элементами образуют направленную последовательность. Благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки. В отличие от многослойных перцептронов, рекуррентные сети могут использовать свою внутреннюю память для обработки последовательностей произвольной длины. Поэтому сети RNN применимы в таких задачах, где нечто целостное разбито на части, например: распознавание рукописного текста или распознавание речи. Было предложено много различных архитектурных решений для рекуррентных сетей от простых до сложных. В последнее время наибольшее распространение получили сеть с долговременной и кратковременной памятью (LSTM) и управляемый рекуррентный блок (GRU).
### 36. Модуль памяти в рекуррентных сетях
https://habr.com/ru/company/wunderfund/blog/331310/
Модуль памяти в **LSTM** (сети с долгой краткосрочной памятью) состоит из четырех взаимодействующих слоев нейронной сети. Основная идея $-$ у модуля памяти есть свое состояние, которое может меняться.
Первый слой $-$ сигмоидальный. Применяя сигмоидную функцию к результату предыдущего слоя и входному значению решается, какую информацию надо забыть, а какую оставить.
Далее на следующем слое сигмоидальная функция, примененная к входным данным решает, какую информацию стоит обновить, а tanh-слой строит вектор новых данных, которые можно добавить в состояние ячейки. Здесь мы обновляем состояние ячейки, забывая то, что решили забыть на первом слое и обновляя состояние.
Наконец, нужно решить, какую информацию мы хотим получать на выходе. Выходные данные будут основаны на нашем состоянии ячейки, к ним будут применены некоторые фильтры. Сначала мы применяем сигмоидальный слой, который решает, какую информацию из состояния ячейки мы будем выводить. Затем значения состояния ячейки проходят через tanh-слой, чтобы получить на выходе значения из диапазона от -1 до 1, и перемножаются с выходными значениями сигмоидального слоя, что позволяет выводить только требуемую информацию.
### 37. Двунаправленная рекуррентная сеть; Seq-2-Seq сеть
https://neurohive.io/ru/osnovy-data-science/rekurrentnye-nejronnye-seti/
Базовая sequence-to-sequence модель, как было представлено Cho et al., 2014 (pdf), состоит из двух рекуррентных нейронных сетей (RNN): encoder (кодер), которая обрабатывает входные данные, и decoder (декодер), которая генерирует данные вывода.
### 38. Механизм внимания в рекуррентных сетях
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
> Но, хм, все эти подробности несколько избыточны для теормина. То есть формулы не нужны. Нужно понимать, что это дополнительный слой, состоящий из векторов, которые обучаются учитывать значимость входа.
Классическая RNN читает вход и складывает что-то в своё состояние (фиксированного размера). Однако зачастую на каждом этапе генерации вывода нас гораздо больше интересует некоторая часть входа больше, чем другая. Собственно, мы хотим "обратить внимание" на некоторые состояния (на разных этапах разные).
**Как**
Генерируем матрицу внимания A (n×m). Каждый элемент матрицы α~ij~ является коэффицентом, с которым учитывается состояние на i-том входе для j-того выхода (по сути мы подаём преобразованное состояние как вход).
**Но как её генерить?**
Сумма всех α~sj~ (по всем s) должна быть равна 1.
\begin{equation}α_{ij} = \frac{exp(score(h_t, h_s))}{Σ_{s'}(exp(score(h_t, h_{s'})))}\end{equation} где h~s~ — состояние после s-ого входа, h~t~ — состояние на генерации t-того выхода, score — некая волшебная функция. `(В другом источнике предлагается в скор пихать вместо состояния после s-ого входа значение на этом входе).`
То, что мы подаём на вход при генерации — context vector — считается как $C(t)=Σ_{s}α_{st}h_s$.
В презентации предлагается вбрасывать на вход не сам context vector, а attention vector $a(t)=tgh(W_c[c_h;h_t])$. (что такое W — непонятно)
<!-- Есть RNN, она читает последовательности и по тихому складывает их в стейт. Отлично. Но всё хуйня собачья, если нам надо поиметь влияние от более важных частей. Так, например, при машинном переводе при помощи RNN первое слово успешно проёбывается в **очень** длинных предложениях. Хорошо, можно поюзать память. Чуть более интересен общий случай — нас интересует то, о чём идёт речь, и что об этом хотели сказать; это можно находить. Собственно весь механизм внимания работает как некий набор коэффицентов для всей истории скрытого состояния. У нас есть __специально обученная штука__ (например, ещё одна маленькая нейросеть, вообще не важно), которая превращает предыдущий стейт и текущий токен в некий "вес". Отлично; дочитываем данные и начинаем выдавать ответ. Однако вместо унылого разворачивания маленького скрытого состояния мы ебашим серию (все при мягкой модели, самые топовые при жёсткой) старых состояний, сложенных с весами. Таким образом, правильная расстановка акцентов позволяет игнорировать всякий мусор и внимательно следить за важными вещами.
Важно понимать, что веса генерятся каждый ход, т.е. матрица весов будет размера n×m, где n — длина входа, m — выхода.
Как?-->
### 39. Векторные представления слов; Word2Vec; skip-gram; CBOW
**Векторное представление** — общее название для различных подходов к моделированию языка и обучению представлений в обработке естественного языка, направленных на сопоставление словам (и, возможно, фразам) из некоторого словаря векторов из значительно меньшего количества слов в словаре. Для этого используют нейронные сети , методы понижения размерности в применении к матрицам совместных упоминаний слов (word co-occurrence matrices) и явные представления, обучающиеся на контекстах упоминаний слов (explicit representations).
**Word2vec** принимает большой текстовый корпус в качестве входных данных и сопоставляет каждому слову вектор, выдавая координаты слов на выходе. Сначала он создает словарь, «обучаясь» на входных текстовых данных, а затем вычисляет векторное представление слов. Векторное представление основывается на контекстной близости: слова, встречающиеся в тексте рядом с одинаковыми словами (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты векторов-слов. В word2vec существуют два основных алгоритма обучения : CBOW (Continuous Bag of Words) и Skip-gram. Пользователь word2vec имеет возможность переключаться и выбирать между алгоритмами. Порядок слов контекста не оказывает влияния на результат ни в одном из этих алгоритмов.
**CBOW** («непрерывный мешок со словами») -- модельная архитектура, которая предсказывает текущее слово, исходя из окружающего его контекста. Модель набора слов с учётом четырёх ближайших соседей термина (два предыдущих и два последующих слова) без учёта порядка следования.
Архитектура типа **Skip-gram** действует иначе: она использует текущее слово, чтобы предугадывать окружающие его слова. k-skip-n-gram — это последовательность длиной n, где элементы находятся на расстоянии не более, чем k друг от друга. Например, дано предложение *Я твой дом труба шатал*. Для этого предложения 1-skip-2-gram будет выглядеть, как набор биграмм («Я твой», «твой дом», «дом труба», «труба шатал») плюс следующие последовательности: *Я дом, твой труба, дом шатал* — то есть, пропускаем одно (1-skip) слово, а из оставшихся справа и слева от пропущенного делаем биграмм (2-gram).
Полученные векторы-слова могут быть использованы для обработки естественного языка и машинного обучения. Получаемые на выходе координатные представления векторов-слов позволяют вычислять «семантическое расстояние» между словами.
### 40. Задача кластеризации; внешние меры оценки; внутренние меры оценки
> [name=Andrey Filchenkov] Тут не хватило внешних мер. Внешние меры — меры оценки качества кластеризации по дополнительной информации (чаще всего, известные метки классов). То есть в случае внутренних мы выкатываем какой-то функционал, в случае внешних — сверяемся с какими-то известными ответами.
>
> А вот знать про то, какие бывают внутренние меры, конечно, полезно, но формулки точно не нужны, достаточно помнить, что мы хотим, чтобы объекты внутри кластера были друг на друга похожи, а сами кластеры друг на друга не похожи, и эти идеи можно комбинировать между собой.
**Задача кластеризации** - задача обучения без учителя
Дано:
$X$ - пространство объектов
$X^l = \{x_1..x_l\}$ - обучающая выборка
$\rho: X \times X \rightarrow [0,\inf)$ - функция расстояния
Найти:
$а: X \rightarrow Y$ - алгоритм кластеризации
такие, что каждый кластер состоит из близких объектов, объекты разных кластеров существенно различны
#### Метрическое пространство:
Среднее внутреннее расстояние $F_0 = \frac{\sum_{i<j}[y_i=y_j]\rho(x_i,x_j)}{\sum_{i<j}[y_i=y_j]} \rightarrow min$
Среднее внешнее расстояние $F_1 = \frac{\sum_{i<j}[y_i\neq y_j]\rho(x_i,x_j)}{\sum_{i<j}[y_i\neq y_j]} \rightarrow max$
#### Векторное пространство:
Среднее внутреннее расстояние $\Phi _0 =\sum_{y\in Y}\frac{1}{|K_y|}\sum_{i:y_i=y}\rho ^2(x_i, c_y) \rightarrow min$
Сумма внешних расстояний $\Phi _1 =\sum_{y\in Y}\rho ^2(c_y, c) \rightarrow max$
### 41. Графовые методы кластеризации
Суть подхода. Объекты принимаются за вершины, а расстояния между ними за ребра. На полученном графе запускается графовый алгоритм.
Дальше примеры алгоритмов.
**Алгоритм выделения графовых компонент**
Выбирается число $R$, удаляются все ребра длины больше $R$. Необходимо подобрать такое $R$ при котором останется несколько связных компонент - они и будут кластерами.
Ограниченная применимость - наиболее подходит для кластеров вида сгущений или лент.
Плохая управляемость числом кластеров - выбрать число кластеров можно только если решить задачу для разных R и выбрать подходящее решение.
**Алгоритм кратчайшего незамкнутого пути (минимальное остовное дерево)**
Строится дерево из $l-1$ ребер. Затем из него убираются $K-1$ самых длинных ребер. Выборка распадается на $K$ кластеров.
Ограниченная применимость.
Высокая трудоемкость - $O(l^3)$ на построение остовного дерева (наверное можно быстрее).
**Алгоритм FOREL (FORmal ELement)**
Выбирается точка - центр тяжести кластера, все точки на расстоянии до $R$ добавляются в кластер, центром кластера становится центр тяжести точек кластера. Эта процедура повторяется пока центр тяжести кластера не перестанет смещаться. Центр кластера называется формальным элементом, так как скорее всего не является элементом выборки.
Чувствителен к выбору начального положения - запустить несколько раз.
### 42. Иерархические методы кластеризации
К иерархическим методам кластеризации относятся методы, направленные на создание древовидной иерархии (дендрограммы) вложенных кластеров. Выделяют два класса методов иерархической кластеризации:
Агломеративный — новые, более крупные кластеры, образуются путем объединения более мелких кластеров;
Дивизивный — новые кластеры образуются путем деления старых, более крупных кластеров;
Как правило новые кластеры выбираются жадно. Для агломеративного метода по матрице сходства выбираются два ближайших кластера. Для построения матрицы сходства выбирается один из методов определения расстояния $d$:
* Метод ближайшего соседа (одиночной связи): $d(R, S)=min_{r\in R, s\in S}d(r,s)$;
* Метод полной связи: $d(R, S)=max_{r\in R, s\in S}d(r,s)$;
* Метод средней связи: $d(R, S)=\frac{1}{|R||S|}\sum_{r\in R}\sum_{s\in S}{d(r,s)}$;
* Центроидный метод — расстояния между кластерами полагаются равными расстояниям между центроидами;
* Метод Уорда — выбираются два таких кластера, которые приводят к минимальному увеличению дисперсии: $\Delta=\sum_i(x_i-c)^2-\sum_{x_i \in R}(x_i-r)^2-\sum_{x_i \in S}(x_i-s)^2$.
### 43. k-means. c-means
**k-means** -- наиболее простой, но в то же время достаточно неточный метод кластеризации в классической реализации. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k. Действие алгоритма таково, что он стремится минимизировать среднеквадратичное отклонение на точках каждого кластера. Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике. Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров.
**с-means** -- вместо однозначного ответа на вопрос к какому кластеру относится объект, он определяет вероятность того, что объект принадлежит к тому или иному кластеру. Таким образом, утверждение «объект А принадлежит к кластеру 1 с вероятностью 90%, к кластеру 2 — 10%» верно и более удобно.
### 44. Алгоритм DBSCAN
https://habr.com/ru/post/322034/
Основанная на плотности пространственная кластеризация для приложений с шумами (англ. Density-based spatial clustering of applications with noise, DBSCAN) — это алгоритм кластеризации данных, основанной на плотности. Если дан набор точек в некотором пространстве, алгоритм группирует вместе точки, которые тесно расположены (точки со многими близкими соседями), помечая как выбросы точки, которые находятся одиноко в областях с малой плотностью (ближайшие соседи которых лежат далеко).
Алгоритм DBSCAN может быть разложен на следующие шаги:
- Находим точки в $\varepsilon$-окрестности каждой точки и выделяем основные точки с более чем $minPts$ соседями.
- Находим связные компоненты основных точек на графе соседей, игнорируя все неосновные точки.
- Назначаем каждую неосновную ближайшему кластеру, если кластер является $\varepsilon$-соседним, в противном случае считаем точку шумом.
Наивная реализация алгоритма требует запоминания соседей на шаге 1, так что требует существенной памяти. Оригинальный алгоритм DBSCAN не требует этого за счёт того, что выполняет эти шаги для одной точки за раз.
### 45. Уменьшение размерности; синтез признаков; выбор признаков; алгоритмы фильтрации
> [name=Andrey Filchenkov]
>
> Надо знать, чем уменьшение размерности (как задача) отличается от выбора признаков (как задача).
Первое — мы выбираем какое-то представление исходных данных меньшей размерности, которое при этом теряет меньше всего информации о данных. Во втором случае мы делаем то же самое, но ограничены тем, что новое пространство должно быть подпространством исходного.
В первом случае мы обычно получаем более хорошее представление, во втором делаем это значительно быстрее.
>
>На деле, надо знать, чем синтез признаков (как задача) отличается от выбора признаков (как задача).
Первое — мы выбираем какое-то представление исходных данных меньшей размерности, которое при этом теряет меньше всего информации о данных. Во втором случае мы делаем то же самое, но ограничены тем, что новое пространство должно быть подпространством исходного.
В первом случае мы обычно получаем более хорошее представление, во втором делаем это значительно быстрее.
>
>И синтез признаков, и выбор признаков — это уменьшение размерности. Оно нужно, чтобы бороться с шумом, ускорить работу последующих прогностических алгоритмов и уменьшить объем хранимой информации.
>
>Алгоритмы фильтрации отбирают признаки согласно введенной мере качества признаков или их подмножеств.
**Уменьшение размерности:**
* PCA
* t-SNE
* Автоэнкодер
**Выбор признаков:**
* *Алгоритмы фильтрации*:
* Отсечение (низковариативных) признаков со значением дисперсии ниже оперделенного значения.
* Отсечение признаков по значимости (степени корреляции значения признака со значением целевой переменной). Меры корреляции:
* Chi-square
* Коэффициент корреляции Спирмена
* $IG(Y | X) = H(Y) - H(Y | X)$, где $H(Y)$ - исходная энтропия значений, $H(Y | X)$. Показывает насколько более упорядоченной становятся значения целевой переменной $Y$, если известны значения фичи $X$
* *Алгоритмы-обертки*
* Классификатор запускается на разных подмножествах фич исходного тренировочного сета. После чего выбирается подмножество фич с наилучшими параметрами на обучающей выборке. (e.g recursive feature elimination - фичи постепенно исключаются из начального множества.)
* *Embedded methods* (не разделяют процесс отбора фич и обучения классификатора)
* Регуляризация
### 46. Алгоритмы-обертки; встроенные методы выбора признаков
**Алгоритмы-обертки**. Суть: тренируемся на сете фичей и добавляем или удаляем фичи.
Пример - SVM-RFE:
1. Выбрали количество фичей которое должно остаться.
2. Тренируем SVM.
3. Ранжируем фичи.
4. Выкидываем плохие.
5. Повторяем пока не осталось нужное количество фич.
**Встроенные методы** называются встроенными, потому что этап отбора фичей происходит прямо во время обучения классификатора.
Примеры: L1-регуляризация и дерево решений.
### 47. Алгоритм PCA
page90: http://www.machinelearning.ru/wiki/images/6/6d/Voron-ML-1.pdf
**Задача:**
есть $n$ исходных числовых признаков $f_1(x),\ldots ,f_n(x)$ и нам нужно получить $m\leqslant n$ новых числовых признаков $g_1(x),\ldots , g_m(x)$, которые будут содержать всю информацию о старых признаках. Старые признаки должны восстанавливаться из новых. Метод главных компонент подразумевает, что старые признаки линейно восстанавливаются по новым:
\begin{align*}
\stackrel{\wedge}{f}_j(x) = \sum\limits_{s=1}^m g_s(x)u_{js}, j = 1,\ldots,n, \forall x \in X
\end{align*}
**Для удобства решения** задачи рассмотрим ее в матричном виде. $F$ и $G$ -- матрицы "объекты-признаки".
Нам нужна матрица линейного преобразования новых признаков в старые: $\stackrel{\wedge}{F} = GU^T$ и чтобы $\stackrel{\wedge}{F}\approx F$.
Для того чтобы получить это, нужно решить задачу наименьших квадратов.
### 48. Алгоритм t-SNE
https://www.coursera.org/lecture/unsupervised-learning/mietod-t-sne-Bn22S
Алгоритм t-SNE состоит из двух главных шагов. Сначала t-SNE создаёт распределение вероятностей по парам объектов высокой размерности таким образом, что похожие объекты будут выбраны с большой вероятностью, в то время как вероятность выбора непохожих точек будет мала. Затем t-SNE определяет похожее распределение вероятностей по точкам в пространстве малой размерности и минимизирует дивергенцию Кульбака — Лейблера между двумя распределениями с учётом положения точек. Заметим, что исходный алгоритм использует евклидово расстояние между объектами как базу измерения похожести, это может быть изменено сообразно обстоятельствам.
Алгоритм t-SNE использовался для визуализации.
В то время как t-SNE отображения часто используются для показа кластеров, на визуальные кластеры могут оказывать сильная выбранная параметризация, а потому необходимо хорошее понимание параметров алгоритма t-SNE. Такие «кластеры» могут быть показаны даже в некластеризованных данных а потому могут быть ошибочные «заключения».
### 49. Автокодировщик
**Автокодировщик** -- специальная архитектура искусственных нейронных сетей, позволяющая применять обучение без учителя при использовании метода обратного распространения ошибки. Простейшая архитектура автокодировщика — сеть прямого распространения, без обратных связей, наиболее схожая с перцептроном и содержащая входной слой, промежуточный слой и выходной слой. В отличие от перцептрона, выходной слой автокодировщика должен содержать столько же нейронов, сколько и входной слой.
Основной принцип работы и обучения сети автокодировщика — получить на выходном слое отклик, наиболее близкий к входному. Чтобы решение не оказалось тривиальным, на промежуточный слой автокодировщика накладывают ограничения: промежуточный слой должен быть или меньшей размерности, чем входной и выходной слои, или искусственно ограничивается количество одновременно активных нейронов промежуточного слоя — разрежённая активация. Эти ограничения заставляют нейросеть искать обобщения и корреляцию в поступающих на вход данных, выполнять их сжатие. Таким образом, нейросеть автоматически обучается выделять из входных данных общие признаки, которые кодируются в значениях весов искусственной нейронной сети. Так, при обучении сети на наборе различных входных изображений, нейросеть может самостоятельно обучиться распознавать линии и полосы под различными углами.
### 50. Алгоритм EM
https://www.coursera.org/lecture/unsupervised-learning/expectation-maximization-em-alghoritm-2jhbI
page32: http://www.machinelearning.ru/wiki/images/6/6d/Voron-ML-1.pdf
**EM** (англ. Expectation-maximization (EM) algorithm) — алгоритм, используемый в математической статистике для нахождения оценок максимального правдоподобия параметров вероятностных моделей, в случае, когда модель зависит от некоторых скрытых переменных. Каждая итерация алгоритма состоит из двух шагов.
- На E-шаге (expectation) вычисляется ожидаемое значение функции правдоподобия, при этом скрытые переменные рассматриваются как наблюдаемые.
- На M-шаге (maximization) вычисляется оценка максимального правдоподобия, таким образом увеличивается ожидаемое правдоподобие, вычисляемое на E-шаге. Затем это значение используется для E-шага на следующей итерации.
Алгоритм выполняется до сходимости.
Часто EM-алгоритм используют для разделения смеси гауссиан.
### 51. Частичное обучение. Алгоритм S3VM (Semi-Supervised Support Vector Machines)
Частичное обучение (semi-supervised lerning) — один из методов машинного обучения, использующий при обучении как размеченные, так и неразмеченные данные. Обычно используется небольшое количество размеченных и значительный объём неразмеченных данных.
---
**Алгоритм S3VM (Semi-Supervised Support Vector Machines)**
http://neerc.ifmo.ru/wiki/index.php?title=%D0%9E%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D1%87%D0%B0%D1%81%D1%82%D0%B8%D1%87%D0%BD%D1%8B%D0%BC_%D0%BF%D1%80%D0%B8%D0%B2%D0%BB%D0%B5%D1%87%D0%B5%D0%BD%D0%B8%D0%B5%D0%BC_%D1%83%D1%87%D0%B8%D1%82%D0%B5%D0%BB%D1%8F
`*Не проверено*`
На размеченных данных строим разбиение обычным SVM, при этом учитываем неразмеченные данные для максимизации пустой полосы между классами.
### 52. Активное обучение. Метод uncertainty sampling
Активное обучение — это вид частичного машинного обучения, в котором также есть оракул, способный размечать точки. Так как вопросы оракулу считаются дорогими, целью активного обучения является достижение качественной модели при минимизации числа обращений к оракулу.
Три подхода:
1) Сконструировать объект и спросить, какой он
2) Читать поток объектов, и либо запрашивать информацию, либо пропускать
3) Выбирать объекты для запроса из ограниченного набора объектов
---
page19: https://www.cs.cmu.edu/~tom/10701_sp11/recitations/Recitation_13.pdf
**Метод uncertainty sampling**
`*Не проверено*`
На каждом шаге для дозапроса берем элемент с наибольшей неопределенностью. После получения вердикта пересчитываем функцию неопределенности для всех элементов.
Как измерять неопределённость:
- Максимальная энтропия
- Минимальный отступ
### 53. Сэмплирование; алгоритм SMOTE
**Сэмплирование** бывает двух видов:
- Подвыборка (subsampling)
- Надвыборка (upsampling)
Стратегии подвыборки:
- Выбрать случайно
- Выбрать систематически - например каждый третий объект
- Выбрать на основе статистики - если объектов класса $A$ было в два раза больше объектов класса $B$, то и в подвыборке их отношение сохранится
- Выбирать кластерами - множество объектов делится на кластеры (как-то ручками) и затем выбираются случайные кластеры
**Алгоритм SMOTE**
https://basegroup.ru/community/articles/imbalance-datasets
Алгоритм осуществляет надвыборку.
Эта стратегия основана на идее генерации некоторого количества искусственных примеров, которые были бы «похожи» на имеющиеся в миноритарном классе, но при этом не дублировали их. Для создания новой записи находят разность $d=X_b–X_a$, где $X_a,X_b$ – векторы признаков «соседних» примеров $a$ и $b$ из миноритарного класса. Их находят, используя алгоритм ближайшего соседа (KNN). В данном случае необходимо и достаточно для примера $b$ получить набор из $k$ соседей, из которого в дальнейшем будет выбрана запись $b$. Остальные шаги алгоритма KNN не требуются.
Далее из $d$ путем умножения каждого его элемента на случайное число в интервале (0, 1) получают $d^*$. Вектор признаков нового примера вычисляется путем сложения $X_a$ и $d^*$. Алгоритм SMOTE позволяет задавать количество записей, которое необходимо искусственно сгенерировать. Степень сходства примеров a и b можно регулировать путем изменения значения k (числа ближайших соседей).
Данный подход имеет недостаток в том, что «вслепую» увеличивает плотность примерами в области слабо представленного класса. В случае, если миноритарные примеры равномерно распределены среди мажоритарных и имеют низкую плотность, алгоритм SMOTE только сильнее перемешает классы.
В качестве решения данной проблемы был предложен алгоритм адаптивного искусственного увеличения числа примеров миноритарного класса ASMO (Adaptive Synthetic Minority Oversampling).
### 54. Обучение с первого взгляда; сиамская сеть
https://www.youtube.com/watch?v=6jfw8MuKwpI
**Обучение с первого взгляда.** Суть в обучении системы, позволяющей легко добавлять новые классы без переобучения всех параметров. Обучение с первого взгляда основано на расстояниях: добавление одного центроида не вынуждает пересчитывать все остальные.
**Сиамская сеть.** Представляет из себя две ОДИНАКОВЫЕ (да, веса изменяются одинаково, shared-веса между двумя сетями) сети, которые принимают два входных объекта и должны решить, принадлежат ли они одному классу. Для обучения используются тройки объектов: основной (anchor); позитивный, максимально похожий на основной; негативный, максимально отличающийся от основного. Для каждой тройки вычисляется функция потерь: $L = max(dist(a,p) - dist(a,n) + ε)$ и используется градиентный спуск.
При использовании для каждого класса (центроида) хранится по одному объекту, и каждый новый объект сравнивается с каждым цетроидом. Для увеличения количества классов просто добавляются соответствующие центроиды.
https://www.youtube.com/watch?v=6jfw8MuKwpI
### 55. Аномалии; шумы
**Аномалия** — это наблюдение, не характерное для наблюдаемых данных.
**Шум** — это любые выбросы в значениях, ошибки в данных, искажения в сигналах.
Разница между аномалией и шумом обычно функциональная: аномалии это то, что мы пытаемся обнаружить, потому что они значимы (например, поломка), тогда как шумы — это то, что мы пытаемся отсеять, потому что они мешают найти зависимость.
### 56. Задача генерации объектов
Задача генерации объектов - решается без привлечения учителя. Необходимо выделить внутреннюю структуру объектов тренировочной выборки, найти распределение вероятности на них и затем взять новый объект из этого распределения.
**Расстояние Кульбака - Лейблера** - метрика между распределениями случайных величин. Используется, чтобы получать распределение, близкое к заданному (например, гауссову).
Два подхода:
- Явный
- Неявный
В явном мы явно задаем какую-то вероятностную модель, описывающую объекты, в неявном мы говорим "ну, она есть. но давайте мы не будем писать формулы, а будем обучать сеточки, и в итоге все равно получим какое-то распределение, хоть и неявно".
### 57. GANs
Генеративно-состязательная сеть (англ. Generative adversarial network, сокращённо GAN)— алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых (сеть G) генерирует образцы (см. Генеративная модель[en]),а другая (сеть D) старается отличить правильные («подлинные») образцы от неправильных (см. Дискриминативная модель[en]). Так как сети G и D имеют противоположные цели — создать образцы и отбраковать образцы — между ними возникает Антагонистическая игра.
### 58. CGANs
**CGAN** (англ. Conditional Generative Adversarial Nets) − это модифицированная версия алгоритма GAN, которая позволяет генерировать объекты с дополнительными условиями y. y может быть любой дополнительной информацией, например, меткой класса или данными из других моделей. Добавление данных условий в существующую архитектуру осуществляется с помощью расширения вектором y входных данных генератора и дискриминатора.
Условие добавляется на вход и генератору, и дискриминатору (хотя с дискриминатором бывает сложнее). Обучается так же, как и GAN, просто у нас объединяются ошибки на понимание того, что объект фейк и что он не соответствует контексту.
**DCGAN** (англ. Deep Convolutional Generative Adversarial Nets) -- модификация алгоритма GAN, основными архитектурными изменениями которой являются:
* Замена всех пулинговых слоев на страйдинговые свертки (strided convolutions) в дискриминаторе и частично-страйдинговые свертки (fractional-strided convolutions) в генераторе;
* Использование батчевой нормализации для генератора и дискриминатора;
* Удаление всех полносвязных скрытых уровней для более глубоких архитектур;
* Использование ReLU в качестве функции активации в генераторе для всех слоев, кроме последнего, где используется tanh;
* Использование LeakyReLU в качестве функции активации в дискриминаторе для всех слоев.
### 59. Вариационный автокодировщик
http://kvfrans.com/variational-autoencoders-explained
https://www.youtube.com/watch?v=9zKuYvjFFS8
 Sign in with Wallet
Connect another wallet
Sign in with Wallet
Connect another wallet