# zkVM 概述
> [原文地址](https://www.zkm.io/blog/zkvm-overview),DAOC DAO进行翻译整理
zkVM(零知识虚拟机)是一种利用零知识证明(ZKP)来确保计算的正确性、完整性和隐私性的虚拟机。
## 预备知识
### 概念
**零知识证明**:证明者向验证者证明某个陈述是真实的,但不透露该陈述真实性之外的任何信息的证明。它包括以下四个属性:
- 零知识
- 简洁
- 非互动性
- 透明度
**有效性证明**:用于证明状态转换的有效性。例如,zk-Rollups 使用有效性证明来证明状态转换到父链的合法性,通常与 SNARK 和 STARK 等证明系统结合使用。
**欺诈证明**:用于验证者质疑交易的有效性。
**可验证计算**:允许客户端将函数 F 的计算任务外包给不受信任的工作人员,并验证返回结果的正确性。
### 电路和门
编写ZKP应用程序涉及以下三个步骤:
#### 使用语言定义问题(约束满足问题)
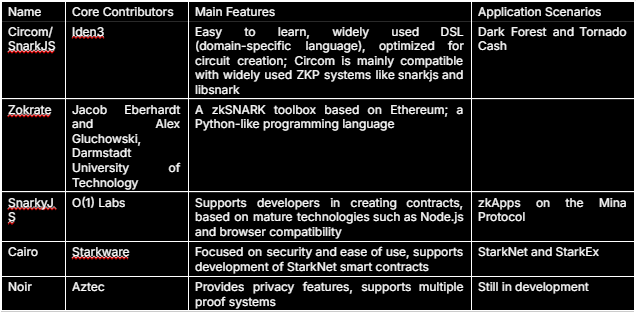
下面是如何使用 Circom 实现乘法器的示例。
```
pragma circom 2.0.0;
/* This circuit template checks if c is the product of a and b. */
template Multiplier2 () {
// Signal declarations
signal input a;
signal input b;
signal output c;
// Constraints
c <== a * b;
}
```
流程图如下:

算术化:将程序转换为一组多项式
**电路计算**:
这种方法将程序简化为门级概念。但是,这里的门不是处理器中的物理门,而是逻辑概念门。
**R1CS**:多项式最大次数为2,满足下列公式:
$$
\left(\sum_{k}A_{ik}Z_{k}\right)\left(\sum_{k}B_{ik}Z_{k}\right)-\left(\sum_{k}C_{ik}Z_{k}\right)=0
$$
此处$A_{ik'}, B_{ik'}, C_{ik}$是有限域$F$中的元素。例如,表达式$y = x^3$可以通过引入中间变量来表示如下:
$$
x \cdot x = w_1
w_1 \cdot w_1 = w
$$
中间变量可以是电路的私有或公共输入。需要注意的是,计算的 R1CS 表示并不是唯一的。例如,上述表达式也可以表示为:
$$
x \cdot x = w_1
w_1 \cdot x = w_2
w_2 \cdot x = w_3
$$
**Plonkish**:支持双输入门(两个扇入门),允许实现自定义门。
$$
q_{L}x_{a}+q_{R}x_{b}+q_{o}x_{c}+q_{M}x_{a}x_{b}+q_{c}=0
$$
此处$q_{L}, q_{R}, q_{O}, q_{M}, q_{C}$是选择操作的控制参数,用于表示R1CS操作。
**计算性计算**:
这种方法类似于计算机的工作方式,涉及一组寄存器和修改寄存器值的状态转换函数。
**AIR** and **PAIR**: 适用于统一计算。

CCS(可定制约束系统):CCS(可定制约束系统)是一种通用的约束表示方法,支持R1CS,Plonkish和AIR。
简单比较

#### 定义证明者实例、生成证明和验证者
#### 承诺阶段
## zkVM深度分析
### 概述

### 虚拟机VM
在计算领域,虚拟机 (VM) 是计算机系统的虚拟化或模拟。虚拟机基于[计算机架构](https://en.wikipedia.org/wiki/Computer_architecture),提供与物理计算机类似的功能。
计算机体系结构是指由 CPU、内存、ALU 等组件组成的计算机系统的结构。
#### 两种主要结构

#### RISC 指令集架构(ISA)
RISC(精简指令集计算机)旨在简化计算机执行任务时所使用的指令集。
下面是MIPS32中ADDI指令的一个示例,它允许选择一个源寄存器、一个目标寄存器,并包含一个小的常数。

在 zkVM 中,有三个主要的 RISC ISA:
- MIPS
- RISC V
- WASM
其中,RISC V类似于MIPS的简化版本。

### 实现一个简单的 zkVM:斐波那契执行器
#### 生成执行跟踪
基于现有的知识,我们可以实现一个简单的 zkVM,例如斐波那契执行器,用于计算斐波那契数列的第 n 项。
$$
f(n) = f(n-1) + f(n-2) \quad f(0) = f(1) = 1
$$
我们选择AIR(代数中间表示)作为代数化方法。
定义状态机$S$包含以下两个变量,并让$i$为域大小:
$$
S = (A_i, B_i) \quad S' = (A_{i+1}, B_{i+1})
$$
现在,状态机$S$可以按如下方式表示斐波那契执行器:
$$
A_{i+1} = B_i \quad B_{i+1} = A_i + B_i
$$
因此,对于所有$i$在域中,执行跟踪表如下,其中$n=6$:

#### 建立多项式方程
在虚拟机中,每个状态都由一个寄存器表示。
代表两个寄存器的多项式来自多项式集$F_p[X]$,其中系数是素域中的元素$F_p$和$p = 2^{64} - 2^{32} + 1$
因此,该域形成一个子群:
$$
H = \{\omega_0, \omega_1, \omega_2, ..., \omega_d = \omega_0\} \subset F_p^d
$$
定义两个多项式$P(X)$和$Q(X)$表示跟踪列 A 和 B:
$$
P(\omega^{i})=A_{i}Q(\omega^{i})=B_{i}
$$
显然:
$$
P(\omega^{i}\cdot\omega)=P(\omega^{i+1})=A_{i+1}
Q(\omega^{i}\cdot\omega)=Q(\omega^{i+1})=B_{i+1}
$$
利用拉格朗日插值,我们可以计算出系数形式$P$和$Q$。
现在,我们可以使用多项式约束来限制两个寄存器的状态转换:
$$
P(X \cdot \omega) = I_H Q(X)
Q(X \cdot \omega) = I_H P(X) + Q(X)
$$
#### 引入循环性
因为$H$是一个子群,我们有:
$$
P(\omega^{5}\cdot\omega)=I_{H}Q(\omega^{5})=13
P(\omega^{5}\cdot\omega)=P(\omega^{0})=1
$$
显然,最后一行的约束被打破了。
解决方案是引入另一个寄存器LAST来标记最后一行并为其分配一个向量值$[0, ..., 1]$. 跟踪表变为:
$$
P(X \cdot \omega) = I_H Q(X) \cdot (1 - \text{LAST}(X)) + \text{LAST}(X) \cdot P(\omega^0)
Q(X \cdot \omega) = I_H (P(X) + Q(X)) \cdot (1 - \text{LAST}(X)) + \text{LAST}(X)
$$
综上所述,状态机中有两种基本类型的约束:
1. 状态转换约束:对于寄存器$P$和$Q$。
2. 边界约束:对于像LAST这样的寄存器。
在实际的 zkVM 开发中,指令的类型非常多,比如算术、逻辑、分支/跳转、内存操作等,每条指令只需要很少的状态来表示,而一个程序可能需要上千种状态。
以下是 zkMIPS 实现的概述:


#### 多项式承诺
现在,上面提到的约束可以转化为多项式等式:
$$
P_0 = (1 - \text{LAST}(X)) \cdot (P(X \cdot \omega) - Q(X)) = 0
P_1 = (1 - \text{LAST}(X)) \cdot (Q(X \cdot \omega) - (P(X) + Q(X))) = 0
$$
基于多项式等式的证明系统利用了[Schwartz-Zippel引理](https://courses.cs.washington.edu/courses/cse521/17wi/521-lecture-7.pdf)的基本性质。
根据 Schwartz-Zippel 引理,证明者找到满足以下条件的假多项式 Q'(次数为 d)的概率:
$$
Q'(\alpha_j) = Q(\alpha_j) \quad \text{for all } j \in \{1, 2, ..., l\}
$$
随机挑战$\{\alpha_1, \alpha_2, ..., \alpha_i\}$来自验证者最多$\frac{d}{|S|}$,可以忽略不计。
定义$z_H(X)$作为消失多项式,并计算商多项式$q_i(X)$:
$$
P_0 = (1 - \text{LAST}(X)) \cdot (P(X \cdot \omega) - Q(X)) = z_H(X) \cdot q_i(X)
P_1 = (1 - \text{LAST}(X)) \cdot (Q(X \cdot \omega) - (P(X) + Q(X)))
$$
因此,我们可以使用多项式承诺方案(例如 FRI 或 KZG)来承诺迹和商多项式$R_i, q_i(X)$。
## 通用 zkVM 设计概念
一般来说,zkVM 主要有三种类型:

## 通用技术
### 主机和子机
在现代指令集架构(ISA)中,虚拟机由各种组件组成,例如 CPU、ALU、内存、I/O、总线和其他外围设备。
不同的组件处理不同的指令并通过总线进行通信。
以 zkMIPS 为例,我们实现了 62 条指令,并对其进行分类如下:
- 算术和算术立即数:例如 ADD、ADDI 等。
- 逻辑与逻辑立即数:如AND、ANDI等。
- Shift 和 Shift Immediate:例如 SLL、SLLV 等。
- 加载和存储:例如LB,SB等。
- 跳转/偏移跳转/分支:如 JUMP、JUMPI 等。
- 系统调用:例如读取、写入等。
因此,如果我们使用单个跟踪表并将所有状态变量放入其中,则该表将变得非常大且稀疏(即许多零值条目)。 这会导致以下问题:
- 列数非常多 ⇒ 需要求出许多迹多项式
- 行数非常多 ⇒ 域大小非常大,迹多项式的次数很高
-
这两点都导致多项式承诺方案(PCS)的计算负担很大。
一种常见的优化方法是将大表拆分成多个子表,如下所示:

这种拆分带来了额外的工程优势:
- 减少内存和 CPU 消耗
- 支持并行证明
- 模块化:不同的工程师可以专注于不同电路的实现和优化
### 查找方案
查找参数可以证明证明者提交的向量元素来自另一个(更大的)已提交表。此类方案通常用于实现 zkVM 中的通信总线。广义上讲,这些协议可用于证明以下形式的陈述:
> 给定一张表$T = \{t_i\}, \quad i = 0, ..., N-1$其中所有值都是不同的(称为“行”),
> 以及查找列表$F = \{f_j\}, \quad j = 0, ..., m-1$(其中值可能重复),
> 所有查找值都包含在表中,即$F \subseteq T$。
在此框架中,表格$T$通常被认为是公开的,并且查找列表$F$被视为私人证据。表格$T$可以理解为存储特定变量的所有有效值,而查找列表$F$包含程序执行期间生成的此变量的具体实例。已证明的语句断言在整个程序执行过程中,变量始终保持在其有效范围内。
在本讨论中,我们假设$m < N$并且通常$m \ll N$(除非另有说明)。我们将回顾查找协议的演变及其各种应用。
在深入研究查找方案之前,让我们首先使用多集相等性来检查排列参数:
$$
\prod_{i}(X-f_{i})=\prod_{j}(X-t_{j})
$$
此处$X$属于该域$F$我们可以选择一个随机数$\alpha \in F$并将上述多项式相等性的检验简化为一个总乘积。
此外,如果$F \subseteq T$,存在$m_j$例如:
$$
\prod_{i}(x-f_{i})=\prod_{j}(x-t_{j})^{m_{j}}
$$
尤其是,如果所有$m_j$为 1,那么我们就有了一个多集相等问题。这似乎可以解决问题,但计算复杂度与集合的大小有关$T$,可能会非常大。
现在让我们更深入地了解查找方案的历史。
### 查找参数方案
#### Plookup
Plookup 是最早的查找协议之一。证明者的计算复杂度为$O(N \log N)$域操作,并且该协议可以推广到支持多表和向量查找。该过程涉及按升序对向量 f 和表 t 的元素进行排序并定义:
$$
\{(s_{k'},s_{k+1})\}=\{(t_{i},t_{j+1})\}\cup\{(f_{i},f_{i+1})\}
$$
作为多重集,然后执行以下检查:
$$
\prod_{k}(X+s_{k}+Y\cdot s_{k+1})=\prod_{i}(X+f_{i}+Y\cdot f_{i+1})\prod_{j}(X+t_{j}+Y\cdot t_{j+1})
$$
此处$X$和$Y$属于该域$F$。
该协议可通过使用大数乘积(grand product)进一步简化。
#### Caulk
Caulk 使证明器的工作量取决于大小$m$的$C_{M}$而不是大小$C$的$N$. 证明者确定一个子集$C_{i}$(包含以下元素$C_{M}$)并使用 KZG 承诺来证明$C - C_i = Z_i(x) \cdot H_i(x)$。该协议具有亚线性效率,证明复杂度为$O(m \log N)$。
#### Caulk+
Caulk+ 是 Caulk 的改进版本,通过更高效的可分性检查进一步降低了证明者的计算复杂度。该协议证明$Z_i$可以划分$C - C_i$和$x^n - 1$通过计算多项式$Z_{I}$,$C_{I}$,和$U$。通过引入盲因子来保留零知识属性,证明者的复杂度降低到$O(m^2)$。
#### Baloo
Baloo 扩展了 Caulk+,以消失多项式的形式提交表格的子集,实现了子集大小的近线性时间复杂度。它引入了“提交并证明”协议,并使用通用 Sumcheck 协议将证明简化为内积参数。该协议非常高效,支持多列查找,在 zkEVM 等 SNARK 中具有广泛的适用性。
#### Flookup
Flookup 旨在高效地证明承诺多项式的值属于大型表。该协议利用配对来提取相关表子集的消失多项式,并引入了新的交互式证明系统 (IOP)。之后$O(N \log^2 N)$预处理,证明器以近乎线性的时间运行$O(m \log^2 m)$,比以前的二次复杂度有了显着的改进,特别是对于大域上的SNARK。
#### cq
cq 使用对数导数方法将成员资格证明简化为有理多项式相等性检查。通过预先计算商多项式的缓存商,该协议使表项计算更加高效。证明时间为$O(N \log N)$,证明大小为$O(N)$,在保持同态性质的同时,提供比Baloo和Flookup更好的效率。
#### LogUp
LogUp 有效地证明了一组见证值存在于布尔超立方体查找表中。通过使用对数导数,该方法将集合包含问题转化为有理函数相等性检查,只需要证明者提供一个多重性函数。LogUp 比多变量 Plookup 变体更高效,所需的 Oracle 承诺减少了 3-4 倍。对于大规模查找,其效率也超过了 Plookup 的有界多重性优化。该方法非常适合向量值查找,并且可扩展用于范围证明,在 SNARK(例如 PLONK 和 Aurora)以及 tinyRAM 和 zkEVM 等应用中发挥着至关重要的作用。
进一步阅读:查找[协议论文](https://github.com/ingonyama-zk/papers/blob/main/lookups.pdf)和[视频链接](https://www.youtube.com/watch?v=qv_5dF2_C4g)
### 证明聚合与递归
聚合是为每个区块生成单独证明并将它们组合成另一个证明的最简单方法。第一种证明验证“区块有效且在链上”,而第二种证明验证“所有这些区块证明均有效”。这种方法称为聚合。
在聚合方案中,第二个电路只有在所有区块证明准备就绪后才能开始聚合。但是,如果我们可以逐个处理区块会怎么样?这就是递归所实现的。
在递归方案中,每个区块证明都会验证两件事:当前区块有效,前一个证明有效。一个证明“包裹”了前一个证明,整体结构类似于链条。

### 延续机制
延续是一种将大型程序拆分为可独立执行和验证的较小段的机制。此机制具有以下优点:
- 并行证明生成
- 在 zkVM 中启用检查点功能
- 将内存需求限制为固定大小,无论程序大小如何
段:段是具有入口 PC 和镜像 ID 的一系列 MIPS 跟踪。
检查内存一致性
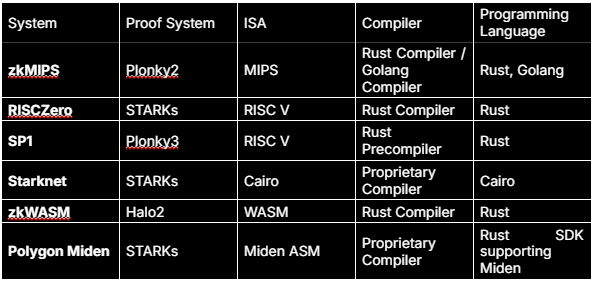
### zkVM 示例
### zkVM 评估
#### 效率
估计生成程序证明所需的时间$P$,我们需要考虑:
- 程序中的指令数$P$。
- 约束的复杂性。
并使用以下公式计算ISA效率:
$$
\text{#Instructions} \times \frac{\text{Constraint Complexity}}{\text{Per Instruction}} \times \frac{\text{Time}}{\text{Constraint Complexity}}
$$
来源:[视频连接](https://youtu.be/tWJZX-WmbeY?t=266)
**评估 zkVM 性能的方法**:
测试场景:SHA2、SHA3、Rust EVM、Rust Tendermint 等。
**指标**:
每秒检验周期数 (Hz)。
证明每单位气体的能源成本。
**开源框架**:
包括 RISCZero、zkMIPS、SP1 和 Jolt,基准测试可在[zkMIPS/zkvm-benchmarks](https://github.com/zkMIPS/zkvm-benchmarks)上找到。
##### 开发者工具链
zkVM 应该提供一个开发人员友好的工具链,允许开发人员构建、编译他们的程序并将验证器部署到区块链上。
**正确性**
VM 必须按预期执行程序。
证明系统必须满足其规定的安全属性,例如:
- 健全性
- 完整性
- 零知识
**简明**
zkVM 生成的证明应该可以在链上验证。
更小的证明尺寸、更短的验证时间和透明的设置是理想的特性。
### 应用场景
**混合汇总:Optimistic + ZK**
Metis
将 Optimistic Rollup 的灵活性和可组合性与 zkMIPS 的可扩展性相结合,形成统一的协议,将最终确认时间从 7 天缩短至不到 1 小时。
**比特币 L2**:
GOAT网络在zkMIPS的基础上实现了一个BitVM2协议,构建了一个真正安全的比特币L2。
**zk 身份(zkIdentity)**
**zk 机器学习 (zkML)**